
深度学习笔记:从零开始的“炼丹”之旅
本文为零基础读者定制深度学习入门指南。首先拆解神经网络三层结构,结合猫狗分类案例,用Keras代码演示CNN模型搭建(卷积层+池化层+全连接层),并解析关键参数(如输入尺寸28x28、激活函数ReLU)。训练环节聚焦数据集划分(8:1:1)与fit()参数调优(epochs/batch_size),同步给出三大常见问题解决方案:过拟合用Dropout+正则化,梯度异常用ReLU+BatchNorm
Hello,大家好,先做一个简单的自我介绍,我是[AI妈妈],一位35+并且在软件开发领域摸爬滚打十余年的技术人,见证了技术迭代如何改变行业生态。如今,在平衡家庭与工作的间隙,我开启了人工智能领域的学习之旅——从Python基础到机器学习算法,从数据预处理到模型调优,我坚持用业余时间啃下每一块硬骨头,现在我想把学习到的经验总结分享给大家,希望能与大家共同成长,一起加油吧~~
今天,我要带大家走进深度学习的奇妙世界,用最通俗易懂的方式,手把手开启这场“炼丹”之旅(深度学习模型训练常被戏称为“炼丹”)。话不多说,我们开始吧!
一、深度学习是什么“神仙”?
想象一下,你面前有一大堆杂乱无章的积木,要从中找出能搭成特定形状的组合,这可不是一件容易的事。传统机器学习就像你拿着说明书,按照既定的规则去挑选积木,但说明书上的规则可能无法涵盖所有情况。而深度学习呢,它就像一个超级聪明的小朋友,自己观察积木的特点,不断尝试各种组合,最终找到最合适的搭法。
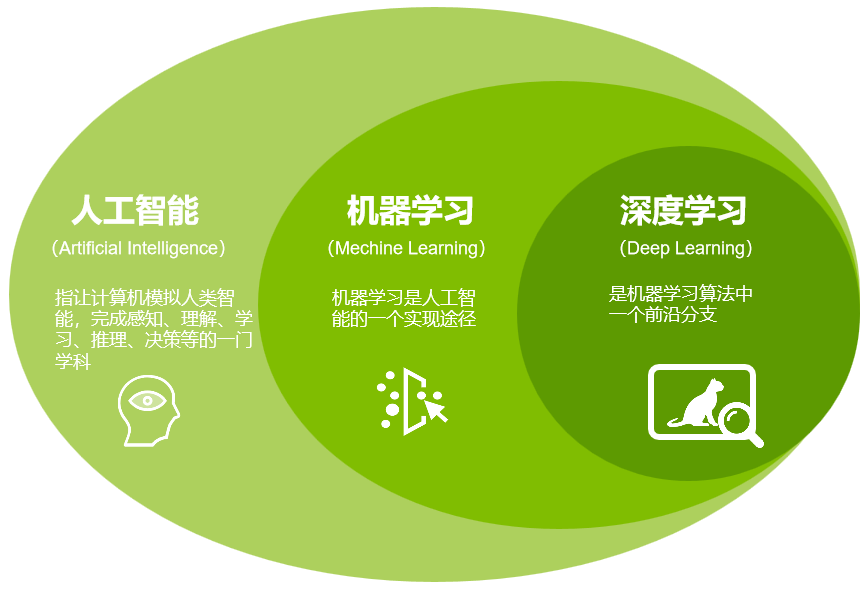
简单来说,深度学习是机器学习的一个分支,它基于人工神经网络,通过构建多层的网络结构,从大量的数据中自动学习特征和规律,就像给机器装上了一个超级大脑,让它能像人一样思考和决策。下图为:人工智能、机器学习、深度学习三者关系。
二、深度学习的“秘密武器”——神经网络
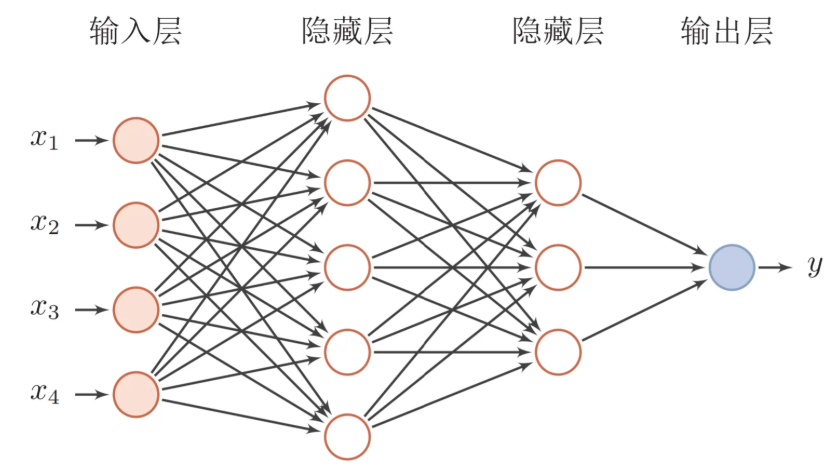
神经网络是深度学习的核心,它由大量的神经元组成,就像我们大脑里的神经细胞一样。这些神经元分层排列,每一层都对输入的数据进行不同的处理。
1. 输入层
这是神经网络的“入口”,负责接收原始数据。比如,我们要识别一张图片是猫还是狗,输入层就会接收这张图片的像素信息。
2. 隐藏层
隐藏层是神经网络的“大脑”,由多个神经元组成。每个神经元都会对输入的数据进行计算和转换,然后将结果传递给下一层。隐藏层可以有多层,层数越多,网络的学习能力就越强,但同时也需要更多的数据和计算资源。
3. 输出层
输出层是神经网络的“嘴巴”,它会给出最终的预测结果。在图片分类任务中,输出层可能会给出图片属于不同类别的概率。
下面是一个简单的神经网络结构示意图:
三、深度学习的“炼丹炉”——训练过程
深度学习模型的训练就像炼丹,需要不断地调整参数,才能炼出“仙丹”(高性能模型)。
1. 数据准备
“巧妇难为无米之炊”,数据就是深度学习的“米”。我们需要收集大量的数据,并对数据进行清洗、标注等预处理工作。比如,在训练一个识别猫狗图片的模型时,我们需要收集大量的猫狗图片,并给每张图片打上“猫”或“狗”的标签。
2. 模型选择与搭建
根据任务需求选择合适的深度学习模型。对于图像分类任务,卷积神经网络(CNN)是首选;对于自然语言处理任务,循环神经网络(RNN)及其变体LSTM、GRU等更合适。
以CNN为例,我们可以用Python的Keras库快速搭建一个简单的CNN模型:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)) # 假设输入是28x28的灰度图像
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax')) # 假设是10分类任务
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])代码解析
- 模型结构:包含卷积层(提取特征)、池化层(降维)、全连接层(分类输出)。
- 编译设置:使用Adam优化器,交叉熵损失函数,评估指标为准确率。
三、训练模型:让“丹炉”开始运转
训练模型就像炼丹,需要精心调整“火候”(超参数)和“丹方”(模型结构)。
1. 数据准备
将数据分为训练集、验证集和测试集。比如,80%数据用于训练,10%用于验证,10%用于测试。
2. 模型训练
使用训练集数据喂给模型,让模型不断调整参数以拟合数据。例如,用Keras的model.fit()方法进行训练:
model.fit(x_train, y_train, epochs=10, batch_size=32) # 示例参数关键参数说明
epochs:训练轮数,轮数太少模型学不好,太多可能过拟合。batch_size:每次输入模型的数据量,影响训练速度和稳定性。
四、常见问题与“避坑指南”
1. 过拟合
表现:模型在训练集上表现很好,但在测试集上表现差。
解决:增加数据量、使用正则化(如L1、L2正则化)、采用Dropout技术(随机丢弃部分神经元,防止模型过度依赖某些特征)。
2. 梯度消失/爆炸
表现:模型在训练过程中,梯度变得非常小(消失)或非常大(爆炸),导致训练无法收敛。
解决:使用合适的激活函数(如ReLU替代Sigmoid)、采用批量归一化(Batch Normalization)技术,加速训练并稳定梯度。
3. 计算资源不足
表现:训练大型模型时,计算资源不足导致训练时间过长或无法训练。
解决炼丹CNN:采用模型压缩技术(如剪枝、量化)、使用分布式训练框架(如TensorFlow的分布式策略)或选择轻量级模型(如MobileNet)。
🚀延伸阅读:
1、深度学习笔记:超萌玩转卷积神经网络(CNN)(炼丹续篇)
2、深度学习数据集探秘:从炼丹到实战的进阶之路(与CNN的奇妙联动)
3、深度学习“炼丹”实战:用LeNet驯服MNIST“神兽”
深度学习就像一场充满挑战与惊喜的探险,虽然途中会遇到各种“妖魔鬼怪”(如过拟合、梯度消失),但只要掌握方法,就能炼出“金丹”(高性能模型)。希望这篇笔记能成为你深度学习之路的“地图”,后续我会分享更多实战案例(如用CNN识别猫狗图片),记得关注我,一起解锁更多技术技能!
如果对某个环节有疑问,欢迎在评论区留言,我们共同探讨~ 🚀

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)