
大数据最新计算机视觉项目实战-目标检测与识别_utils_paths,2024年最新刚从阿里、头条面试回来
blob = cv2.dnn.blobFromImages(images, 1, (224, 224), (104, 117, 123))#均值。习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
for (rootDir, dirNames, filenames) in os.walk(basePath):
# 循环遍历当前目录的中文名
for filename in filenames:
# 如果包含字符串不是none,并且文件名不包含提供的字符串,则忽略该文件
if contains is not None and filename.find(contains) == -1:
continue
# 确定当前文件的文件扩展名
ext = filename[filename.rfind("."):].lower()
# 检查该文件是否为图像,是否应该进行处理
if validExts is None or ext.endswith(validExts):
# 构造到图像的路径并生成它
imagePath = os.path.join(rootDir, filename)
yield imagePath
首先这个模块定义了照片的类型,都可以是什么格式的其中包括jpg、png等等。
`os.walk(path)`是一个目录的迭代器。其中返回三个参数。
1. root就是本身的地址。
2. dirs就是该文件夹下的子文件夹目录。
3. filenames是path路径下文件。
我们这个模块的目标就是要拿到照片的路径。并且yield回主程序当中。yield表示一个一个返回,返回一个然后处理,然后在返回去一个,直到结束。然后这里面判断了一下照片的拓展名,然后进行了判断看文件的拓展名和我们设置的那几个一致不一致。如果一致,就可以进行路径提取了~
rows = open(“synset_words.txt”).read().strip().split(“\n”)
classes = [r[r.find(" “) + 1:].split(”,")[0] for r in rows]
我们先要对标签文件进行处理!那么这里`strip()`表示消除空格。`split("\n")`这里就是以空格为分隔符。也就是说我们要一行一行的处理。我们截取一部分来看一下。

遍历每一行,然后从第二个元素开始找,并且以`,`为分隔符来看分类标签都是什么。这里就把分类标签弄好了。
这里我们用到了深度学习当中的`caffe`,导入的是所需要的配置文件。
net = cv2.dnn.readNetFromCaffe(“bvlc_googlenet.prototxt”,
“bvlc_googlenet.caffemodel”)
`cv2.dnn.readNetFromCaffe`用于读取已经训练好的caffe模型。我们截取配置文件的其中一部分来看一下。

我们可以看到就是做了卷积,池化等操作。同深度学习中的卷积神经网络的做法较为相似,只不过这个`caffe`网络做的较深。光网络结构这个就有2000行左右。我们在这里进行了导入。
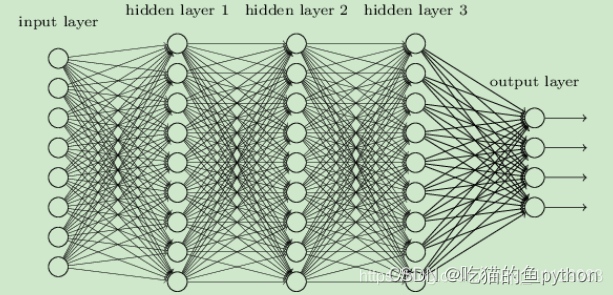
DNN神经网络的组成:
1. 输入层:神经网络的第一层,原始的样本数据
2. 隐藏层:除了输入层,输出层,中间的都是隐藏层
3. 输出层:神经网络的最后一层,最终的计算结果
神经网络的特点:
1. 每个连接都有个权值
2. 同一层神经元之间没有连接
3. 最后的输出结果对应的层也称之为全连接层
imagePaths = sorted(list(utils_paths.list_images(“images/”)))
然后从`utils_paths`模块中拿到图片路径!
image = cv2.imread(imagePaths[0])
resized = cv2.resize(image, (224, 224))
image scalefactor size mean swapRB
blob = cv2.dnn.blobFromImage(resized, 1, (224, 224), (104, 117, 123))
print(“First Blob: {}”.format(blob.shape))
这里读入了照片,然后做了一次resize操作,resize成(224,224)的图片。然后我们使用了`cv2.dnn.blobFromImage`这个函数,我们在这里介绍一下。
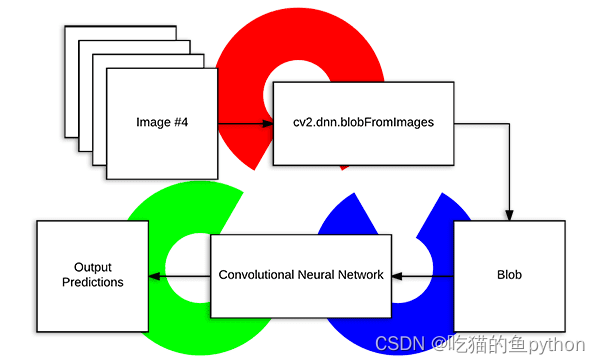
`cv2.dnn.blobFromImage`就是得到预测结果。我们来细致的讲一下这里:
在深度学习和图像分类领域,预处理任务通常包括了三类。
1. 减均值操作。
2. 按照比例缩放。
3. 通道交换。
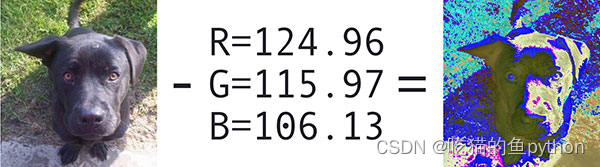
Opencv提供两个函数用来促进图像预处理,用于深度学习分类。
**减去均值帮助我们对抗输入图像的亮度变化,所以我们将减去均值作为作为一个技术用来帮助我们的卷积神经网络,通常三个通道,R均值,G均值,B均值。然后我们也有一个比例因子,需要加上一个标准化。**
需要注意的一点就是:不是所有的深度学习架构执行减去均值和缩放。
blob=cv2.dnn.blobFromImage(image,scalefactor=1.0,size,mean,swapRB=True,crop=False,ddepth=CV_32F)
net.setInput(blob)
preds = net.forward()
然后我们做了一次前向传播。就可以得到结果了。
idx = np.argsort(preds[0])[::-1][0]
text = “Label: {}, {:.2f}%”.format(classes[idx],
preds[0][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
cv2.imshow(“Image”, image)
cv2.waitKey(0)
然后我们取分值最大的,然后再图片上添加上标题。就ok了!然后展示出来。
for p in imagePaths[1:]:
image = cv2.imread§
image = cv2.resize(image, (224, 224))
images.append(image)
blobFromImages函数,注意有s
blob = cv2.dnn.blobFromImages(images, 1, (224, 224), (104, 117, 123))#均值
print(“Second Blob: {}”.format(blob.shape))
获取预测结果
net.setInput(blob)
preds = net.forward()
for (i, p) in enumerate(imagePaths[1:]):
image = cv2.imread§
idx = np.argsort(preds[i])[::-1][0]
text = “Label: {}, {:.2f}%”.format(classes[idx],
preds[i][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
cv2.imshow(“Image”, image)
cv2.waitKey(0)
同样对于后面的图片路径也做出一个相同的操作。然后我们试了一下结果。




这里面做出来的一些展示。左上角都已经进行了识别出来了!
### 🌟完整代码
导入工具包
import utils_paths
import numpy as np
import cv2
标签文件处理
rows = open(“synset_words.txt”).read().strip().split(“\n”)
classes = [r[r.find(" “) + 1:].split(”,")[0] for r in rows]
Caffe所需配置文件
net = cv2.dnn.readNetFromCaffe(“bvlc_googlenet.prototxt”,
“bvlc_googlenet.caffemodel”)
图像路径
imagePaths = sorted(list(utils_paths.list_images(“images/”)))
图像数据预处理
image = cv2.imread(imagePaths[0])
resized = cv2.resize(image, (224, 224))
image scalefactor size mean swapRB
blob = cv2.dnn.blobFromImage(resized, 1, (224, 224), (104, 117, 123))
print(“First Blob: {}”.format(blob.shape))
得到预测结果
net.setInput(blob)
preds = net.forward()
排序,取分类可能性最大的
idx = np.argsort(preds[0])[::-1][0]
text = “Label: {}, {:.2f}%”.format(classes[idx],
preds[0][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)