
(3)机器学习_逻辑模型_决策树
文章目录1、什么是决策树2、决策树的学习过程:3、决策树是如何生成的3.1 ID3算法(基于信息增益)3.2 C4.5算法(基于信息增益率)3.3 CART算法(基于基尼系数)4、决策树实现的简单例子5、参考文献1、什么是决策树决策树(Decision Tree)是机器学习的一种算法,决策树的决策过程和一颗倒过来的树相似,所以称作决策树。2、决策树的学习过程:特征选择:选择哪些属性作为树的节点。生
·
文章目录
1、什么是决策树
决策树(Decision Tree)是机器学习的一种算法,决策树的决策过程和一颗倒过来的树相似,所以称作决策树。
2、决策树的学习过程:
- 特征选择:选择哪些属性作为树的节点。
- 生成决策树:生成树形结构。
- 决策树剪枝:优化决策树,减少计算量,防止过拟合。
- 预剪枝:在生成决策树的过程中进行剪枝,导致欠拟合。
- 后剪枝:决策树生成之后再剪枝,计算量可能会大。
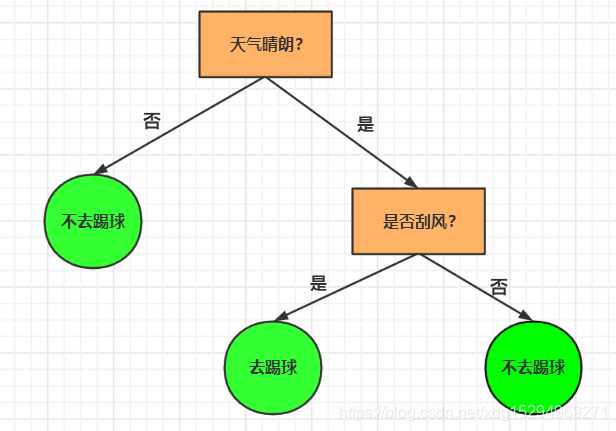
3、决策树是如何生成的
-
3.1 ID3算法(基于信息增益)
首先根据target计算出整体的信息熵,寻找信息增益最大的特征值作为切分点(我的上一篇文章有讲到信息增益的计算)。但那是ID3有个缺点,一般特征值的选择越多(如:特征为性别,那么性别特征有两种,特征为年龄,那么特征有很多很多种,年龄作为切分点的可能性就会增大,类别越多熵越大),信息增益就越大,为了解决ID3算法的缺点,C4.5算法就诞生了。 -
3.2 C4.5算法(基于信息增益率)
- C4.5引入的是信息增益率,而不是信息增益(信息增益率也在我刚才说的文章中有讲),避免切分点选择取值多的特征。
- 加入剪枝技术,防止过拟合
- 对连续的树形进行离散化处理,使得C4.5算法可以处理连续属性的情况,而ID3只能处理离散型数据
- 处理缺失值,C4.5也可以针对数据集不完整的情况进行处理
C4.5算法改善了ID3的缺点,但是缺增加了很多计算开支,因此算法效率较低,为了减小运算量,CART算法也就诞生了
-
3.3 CART算法(基于基尼系数)
- CART算法全称为分类回归树 ,基于基尼系数(刚才提到的文章有讲)
- 支持分类和回归两种决策树。
- 分类时使用基尼系数来选择最好的数据分割特征,基尼系数越小越好
- 回归时比较不同分裂方法的均方差作为分裂依据。
4、决策树实现的简单例子
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import tree
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, Y_train, Y_test = train_test_split(X,y, random_state=0)
clf = DecisionTreeClassifier(max_depth = 2, random_state = 0)
clf.fit(X_train, Y_train)
fn=['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']
cn=['setose', 'versicolor', 'virginica']
fig, axes = plt.subplots(figsize = (4,4), dpi=300)
tree.plot_tree(clf,
feature_names = fn,
class_names=cn,
filled = True);
fig.savefig('imagename2.png')
5、参考文献
https://scikit-learn.org/0.24/modules/generated/sklearn.tree.plot_tree.html
https://www.cnblogs.com/codeshell/p/13984334.html
https://blog.csdn.net/LUAOHAN/article/details/109609460

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)