
TCMChat:一种用于传统中医药的生成式AI大模型 - 浙大&天津中医药大学等
在阅读理解测试中,TCMChat的BLEU、Meteor、ROUGE-1、ROUGE-2、ROUGE-L和BertScore分别为0.584、0.737、0.771、0.734、0.766和0.886,均优于其他模型。在ADMET预测测试中,TCMChat在回归任务中的MAE为2.73,RMSE为10.26,在分类任务中的准确率为0.818,ROC-AUC为0.830,显著优于其他模型。TCMCh

TCMChat: A generative large language model for
Traditional Chinese Medicine
摘要
在医学领域,结合突破性的大型语言模型(LLMs)和对话系统的应用逐渐普及。尽管最近提出了几种中医药大型语言模型,但它们在中医药领域的专业知识仍然有限。本文介绍了TCMChat中药知识聊天机器人(https://xomics.com.cn/tcmchat),一种通过预训练(PT)和监督微调(SFT)在大规模精选的中医学文本知识和中文问答(QA)数据集上进行训练的生成式大型语言模型。具体来说,我们首先通过文本挖掘和人工验证,汇编了一个包含六种中医场景的自定义训练集,涉及中医药知识库、选择题、阅读理解、实体提取、医案诊断以及草药或方剂推荐。接下来,我们使用百川2-7B-Chat作为基础模型,对模型进行预训练和监督微调。基准数据集和案例研究进一步展示了中药知识聊天机器人在与现有模型比较中的卓越性能。我们的代码、数据和模型已在GitHub(https://github.com/ZJUFanLab/TCMChat )和HuggingFace(https://huggingface.co/ZJUFanLab )上公开发布,为中医药现代化研究提供了一个高质量的数据库和一个用户友好的对话式网络工具。
https://www.sciencedirect.com/science/article/pii/S1043661824004754

引言
近年来,预训练和微调范式作为一种常见策略,在众多自然语言处理(NLP)任务中越来越受欢迎[1,2]。最初,像Bert[3]、Roberta[4]和GPT1-2[5,6]这样的预训练语言模型采用了具有多个注意力机制的Transformer架构[7]。这些预训练模型能够捕捉上下文信息,以提高各种NLP应用的性能[8]。近期,以ChatGPT为代表的大型语言模型受到了越来越多的关注。它基于GPT-3引入了更先进的技术,如指令微调和基于人类反馈的强化学习(RLHF)[10]。在常识和推理问题、未知领域以及敏感话题方面,ChatGPT表现出显著的进步。尽管ChatGPT不对公众开放,但像LLaMA[11]、Bloom[12]、Falcon[13]等开源大型语言模型的出现引起了研究人员的兴趣。其中,像百川[14]和LLaMA-中文[15]这样的中文大型语言模型提供了强大的语言处理能力,并促进了研究人员之间的合作与学术交流,从而推动了整个自然语言处理领域的发展。
在传统中医领域,也涌现出了一些杰出的大型语言模型。BenTso[16]基于知识图谱构建指令数据集,然后在中文-LLaMA上进行微调。 BianQue[17]模拟医生咨询的过程,它通过一千万条中文医疗问答指令和多轮提问对话数据集进行训练。华佗GPT[18]采用真实的中医咨询数据集,通过预训练、奖励和强化学习的四个完整阶段来训练医疗对话模型。CMLM-钟京[19]使用专业表单数据,严格设定特定的提示模板,为15个场景生成指令数据,微调后的模型具备中医药处方数据和诊断思维逻辑的推理能力。TCM-GPT[20]的开发使用了两种类型的任务指令数据:检查和诊断,并采用了低秩适应(LoRA)[21]方法进行预训练和微调。启博[22]构建了中医领域的专业语料库,使模型具备特定于中医理论的专门知识,并实现了从预训练到监督微调的完整训练过程。尽管这些模型展现了出色的功能和令人印象深刻的结果,但不可否认的是它们仍面临一些明显的限制。首先,BenTaso、BianQue和HuatuoGPT专注于模拟医学领域数据,而中医语料库在这方面似乎相对稀缺。其次,尽管CMLM-中景通过ChatGPT API收集并构建了对齐的数据集,但以这种方式获得的数据源存在一些准确性问题,其评估相对主观,需要客观且多元的评估方法。此外,这些模型无法提供外部可访问且用户友好的网站工具,以便非程序员更直观地理解和评估模型的性能。
在本研究中,我们介绍了TCMChat,一个专为中医调整的生成式大型语言模型。TCMChat融入了丰富的中医知识,旨在显著提高AI在中医领域的应用效率。该系统不仅理解并回应关于草药、其医疗特性及有效性的询问,还根据患者的需求提供量身定制的中医推荐。我们最初专注于创建丰富的教学数据,以保证模型在传统中医方面的专业性和正确性。这些数据是使用经典书籍和权威的中药开源数据库中的知识生成的。通过文本挖掘和人工验证,我们收集了超过60万个高质量的教学数据,这为模型的受监督微调提供了坚实的基础。中医聊天(TCMChat)的开发始于利用开源的百川2-7B-Chat基础模型,该模型因其强大的通用智能能力和可扩展性而被选中。之后,我们采用基于中医知识的收集到的指导数据进行预训练和微调。这使得模型能够深刻理解中医知识,并有效应用。在此过程中,中医聊天不仅展现了基础模型的卓越性能,还在中医领域展现了显著的专业性和精确度。
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是如何利用大型语言模型(LLMs)在传统中医药(TCM)领域的应用,尽管现有的TCM LLMs存在专业知识有限的问题。
- 研究难点:该问题的研究难点包括:TCM领域数据相对稀缺,现有模型的准确性和客观性不足,缺乏用户友好的在线工具。
- 相关工作:该问题的研究相关工作包括BenTso、BianQue、HuatuoGPT、CMLM-ZhongJing、TCM-GPT、Qibo等模型,这些模型在医疗领域取得了一定的进展,但在TCM领域的表现仍有待提高。
研究方法
这篇论文提出了TCMChat,一种针对TCM领域进行预训练和监督微调的大型语言模型。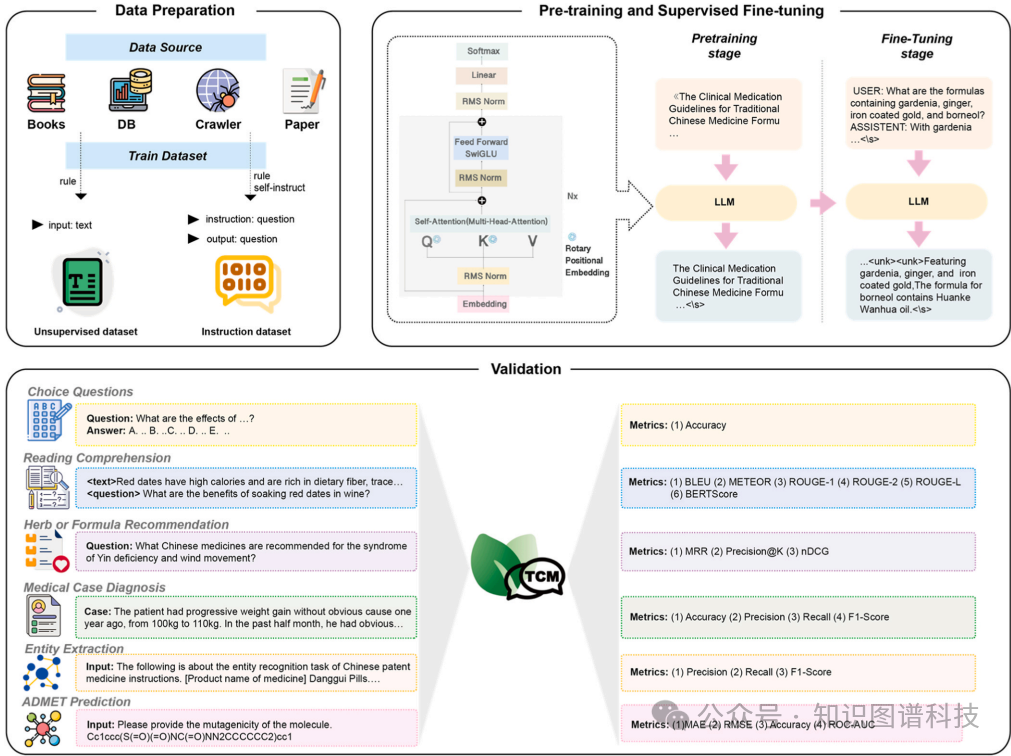 具体来说,
具体来说,
- 数据收集与处理
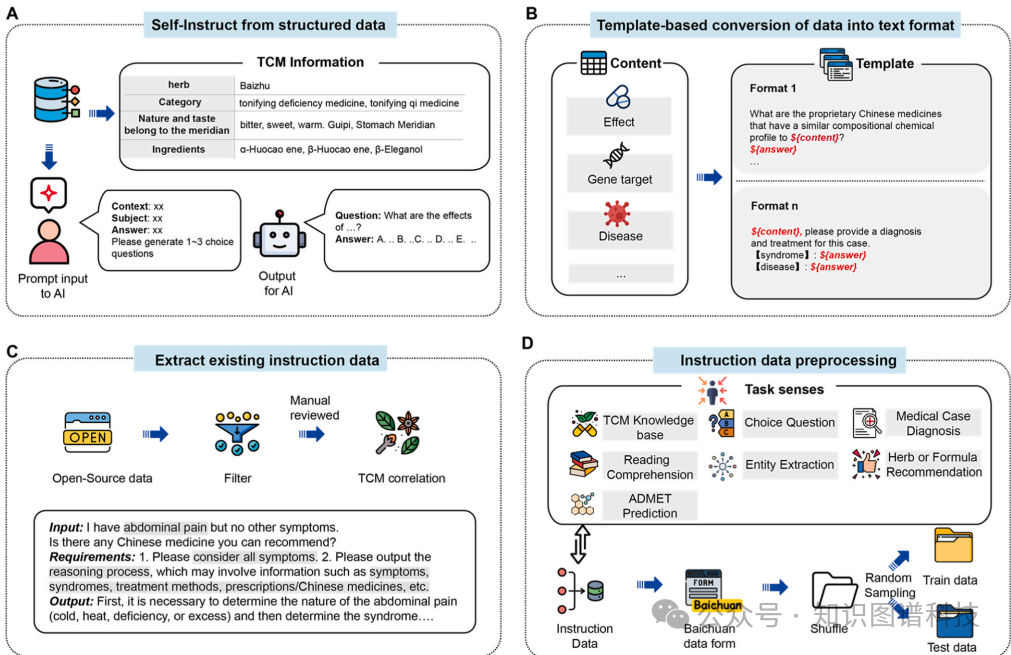
:首先,通过文本挖掘和手动验证,编译了一个包含六个场景(中药知识库、选择题、阅读理解、实体提取、医案诊断和中药或方剂推荐)的自定义训练集。数据来源包括书籍、网络爬虫信息、文献和开源数据集。
- 预训练
:使用Baichuan2-7B-Chat作为基础模型,采用因果语言模型(CLM)方法进行预训练。
- 监督微调
:在预训练的基础上,使用监督学习进行微调,损失函数与预训练相同。问答文本被拼接成一个长序列,并添加特殊分隔符以标记问答边界。
- 模型优化
:在预训练和微调阶段,使用Deepspeed进行并行计算,支持数据并行、模型并行和管道并行。优化器采用AdamW,并指定权重衰减1e-4以防止过拟合。
实验设计
- 数据集构建
:从书籍、网络爬虫、文献和开源数据集中提取和整合信息,构建了约1G的无监督数据集和约600000个问答的对监督数据集。
- 模型选择
:在四个候选模型(Llama-2-7B-Chat、Bloom-7B1、Baichuan2-7B-Chat和Qwen1.5-7B-Chat)中进行综合评估,最终选择Baichuan2-7B-Chat作为基础模型。
- 训练过程
:预训练阶段的学习率为2e-4,批处理大小为32,最大上下文长度为1024;微调阶段的学习率为2e-5,批处理大小为16,最大上下文长度为1024。使用8个NVIDIA A100 GPU进行训练,并采用DeepSpeed ZeRO2方法优化内存使用和加速训练。
结果与分析
-
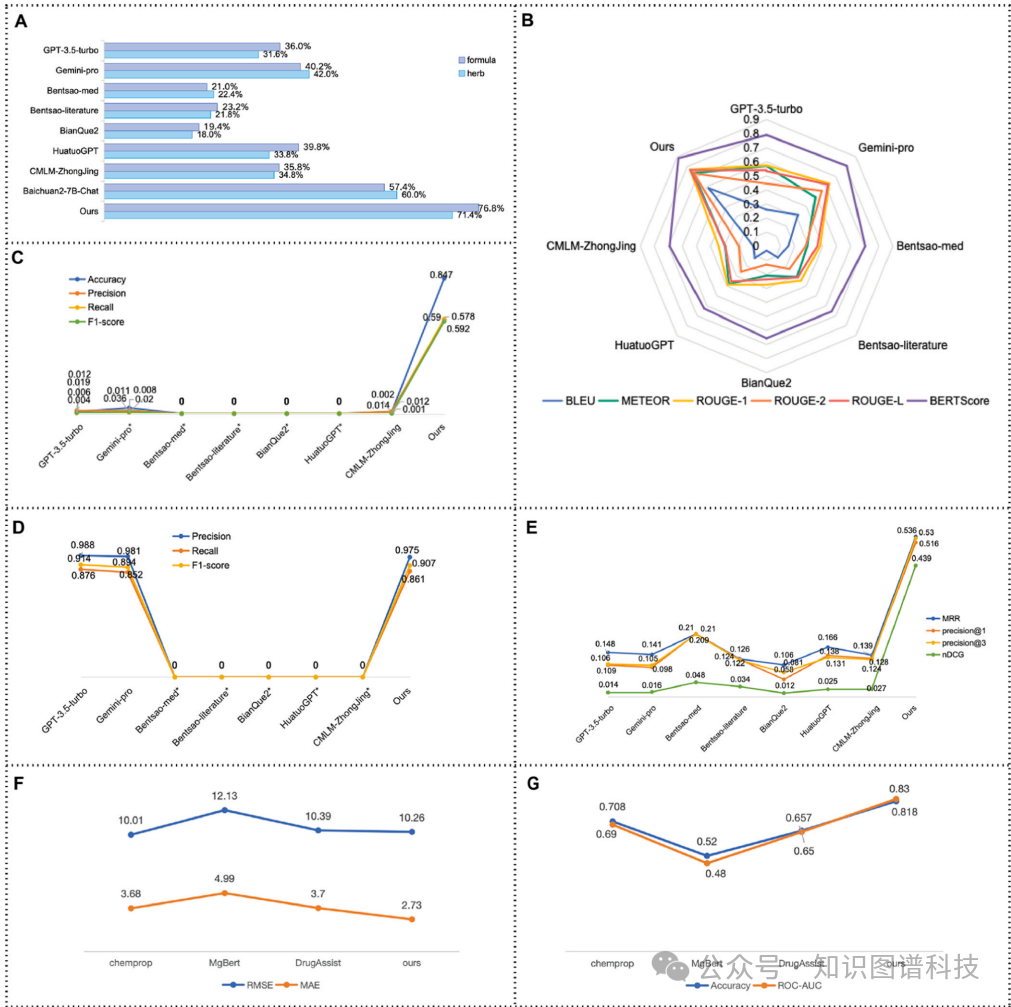
选择题测试:TCMChat在中药和方剂的选择题测试中分别取得了71.6%和76.8%的准确率,显著优于其他模型。
-
阅读理解测试:TCMChat在阅读理解测试中的BLEU、Meteor、ROUGE-1、ROUGE-2、ROUGE-L和BertScore分别为0.584、0.737、0.771、0.734、0.766和0.886,均优于其他模型。

-
医案诊断测试:TCMChat在医案诊断测试中的准确率为0.847,精确率为0.52,召回率为0.592,F1值为0.578,显著优于其他模型。


-
实体提取测试:TCMChat在实体提取测试中的精确率为0.975,召回率为0.861,F1值为0.907,接近GPT-3.5-turbo和Gemini-pro的表现。
-
中药或方剂推荐测试:TCMChat在中药或方剂推荐测试中的MRR为0.536,precision@1为0.280,precision@3为0.516,nDCG为0.439,显著优于其他模型。
-
ADMET预测测试:TCMChat在回归任务中的MAE为2.73,RMSE为10.26,在分类任务中的准确率为0.818,ROC-AUC为0.830,显著优于其他模型。
总体结论
TCMChat通过预训练和监督微调的方法,显著提高了在传统中医药领域的应用性能。该模型在选择题、阅读理解、医案诊断、实体提取、中药或方剂推荐和ADMET预测等多个场景中均表现出色。TCMChat的开发和应用为传统中医药的现代化提供了高质量的知识和用户友好的对话工具,推动了中医药领域的技术创新和发展。
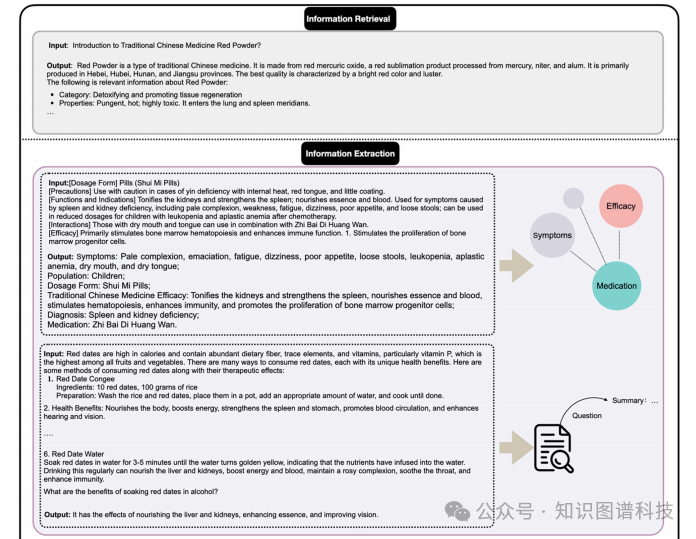

论文评价
优点与创新
- 数据集构建
:通过文本挖掘和手动验证,构建了包含六种场景的中文医学知识库、选择题、阅读理解、实体提取、医案诊断和中药或方剂推荐的高质量训练数据集,共计超过60万条数据。
- 模型优化
:在预训练阶段采用了因果语言模型(CLM)方法,并在微调阶段使用了与预训练相同的损失函数,增强了模型的适应性和泛化能力。
- 技术改进
:对基础模型Baichuan2-7B-Chat进行了多项改进,包括替换归一化层、绝对位置编码和激活函数,提升了模型性能。
- 高效训练
:使用Deepspeed进行并行计算,支持数据并行、模型并行和管道并行,显著节省了图形内存使用,提高了训练效率。
- 多场景应用
:TCMChat模型在不同场景下表现出色,包括选择题、阅读理解、实体提取、医案诊断和中药或方剂推荐等。
- 用户友好工具
:开发了TCMChat Web工具,提供了一个用户友好的对话界面,方便非程序员直观地理解和评估模型性能。
- 公开数据与代码
:模型、数据和代码均在GitHub和HuggingFace上公开,为中医药现代化研究提供了高质量的知识库。
不足与反思
- 知识体系复杂性
:中医药领域的知识体系非常复杂,TCMChat模型目前不包含所有中医药知识,如病理、组成等,这可能限制了模型的全球适用性。
- 未来工作
:未来将继续深入研究中医药领域的知识和数据,持续改进和优化TCMChat模型的性能和应用场景。
- 合作伙伴
:期待与更多合作伙伴合作,推动中医药与现代AI的结合,为中医药的传承和发展做出更大贡献。
关键问题及回答
问题1:TCMChat在数据收集和处理方面是如何进行的?
TCMChat的数据收集和处理涉及多个步骤。首先,通过文本挖掘和手动验证,编译了一个包含六个场景(中药知识库、选择题、阅读理解、实体提取、医案诊断和中药或方剂推荐)的自定义训练集。数据来源包括书籍、网络爬虫信息、文献和开源数据集。具体来说,书籍部分来自国家标准、医学教材和医学案例;网络爬虫信息来自中国国家医学信息平台(TCM-DaYi)和百度百科(BaiduBaike);文献部分通过关键词搜索下载了近500000篇文档的摘要数据;开源数据集包括阿里天池平台(Alibaba Tianchi)上的中药阅读理解数据和中药实体识别数据。此外,还使用了ShenNong_TCM_Dataset和Herb2.0等大规模开源数据集来增强模型的推荐能力。
问题2:TCMChat在模型优化方面采取了哪些措施?
TCMChat在模型优化方面采取了多项措施。首先,在预训练和微调阶段,使用Deepspeed进行并行计算,支持数据并行、模型并行和管道并行,以显著提高训练效率。其次,优化器采用AdamW,并指定权重衰减1e-4以防止过拟合。此外,为了确保训练的稳定性,减少了梯度爆炸和衰减学习率的问题,通过将损失减少一半来缓解这些问题。最终,经过27小时的预训练和微调,模型损失函数逐渐稳定并达到收敛。
问题3:TCMChat在不同场景下的性能如何?与其他模型相比有何优势?
TCMChat在不同场景下均表现出色。在选择题测试中,TCMChat在中药和方剂的选择题测试中分别取得了71.6%和76.8%的准确率,显著优于其他模型。在阅读理解测试中,TCMChat的BLEU、Meteor、ROUGE-1、ROUGE-2、ROUGE-L和BertScore分别为0.584、0.737、0.771、0.734、0.766和0.886,均优于其他模型。在医案诊断测试中,TCMChat的准确率为0.847,精确率为0.52,召回率为0.592,F1值为0.578,显著优于其他模型。在实体提取测试中,TCMChat的精确率为0.975,召回率为0.861,F1值为0.907,接近GPT-3.5-turbo和Gemini-pro的表现。在中药或方剂推荐测试中,TCMChat的MRR为0.536,precision@1为0.280,precision@3为0.516,nDCG为0.439,显著优于其他模型。在ADMET预测测试中,TCMChat在回归任务中的MAE为2.73,RMSE为10.26,在分类任务中的准确率为0.818,ROC-AUC为0.830,显著优于其他模型。总体而言,TCMChat在不同场景下均表现出显著的优势,显著提高了在传统中医药领域的应用性能。
参考文献:
-
PatientSeek: 海外首个基于Deepseek R1的"KG+LLM"结合的开源医学法律推理模型 - WhyHow.AI
-
AIPatient:基于EHR和知识增强大模型智能体工作流的模拟患者-密歇根、斯坦福、哈佛医学院、山大、港大、医科院、北大六院等
-
AIPatient:基于EHR和知识增强大模型智能体工作流的模拟患者-密歇根、斯坦福、哈佛医学院、山大、港大、医科院、北大六院等
高颜值免费 SCI 在线绘图(点击图片直达)
最全植物基因组数据库IMP (点击图片直达)

往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|































技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)