
【ollama】ollama配置本地大模型并运行
ollama的Github链接ollama官网链接打开后点击下载下载完成后进行安装,安装完毕后在终端输入以下,代表安装成功ollama在ollama官网的模型库中找到需要的模型,这里使用阿里最新开源的qwen2.5复制这里的命令代码然后在终端中输入这行命令,等待模型下载完毕,然后可以开始对话ollama的模型默认安装位置ollama本地运行状态在浏览器中输入以上链接,出现以下则代表ollama运行
·
ollama的Github链接
https://github.com/ollama/ollama
ollama官网链接
https://ollama.com/
打开后点击下载
下载完成后进行安装,安装完毕后在终端输入以下,代表安装成功
ollama

在ollama官网的模型库中找到需要的模型,这里使用阿里最新开源的qwen2.5
复制这里的命令代码
ollama run qwen2.5

然后在终端中输入这行命令,等待模型下载完毕,然后可以开始对话
额外信息
ollama的模型默认安装位置
C:\Users\xudawu\.ollama

ollama本地运行状态
http://127.0.0.1:11434
在浏览器中输入以上链接,出现以下则代表ollama运行模型成功
ollama官方api接口
docker配置的时候需要此接口
https://github.com/ollama/ollama/blob/main/docs/api.md#generate-a-completion

输入以下查看已安装的模型
ollama list

使用docker配置ollama
Ollama
拉取命令
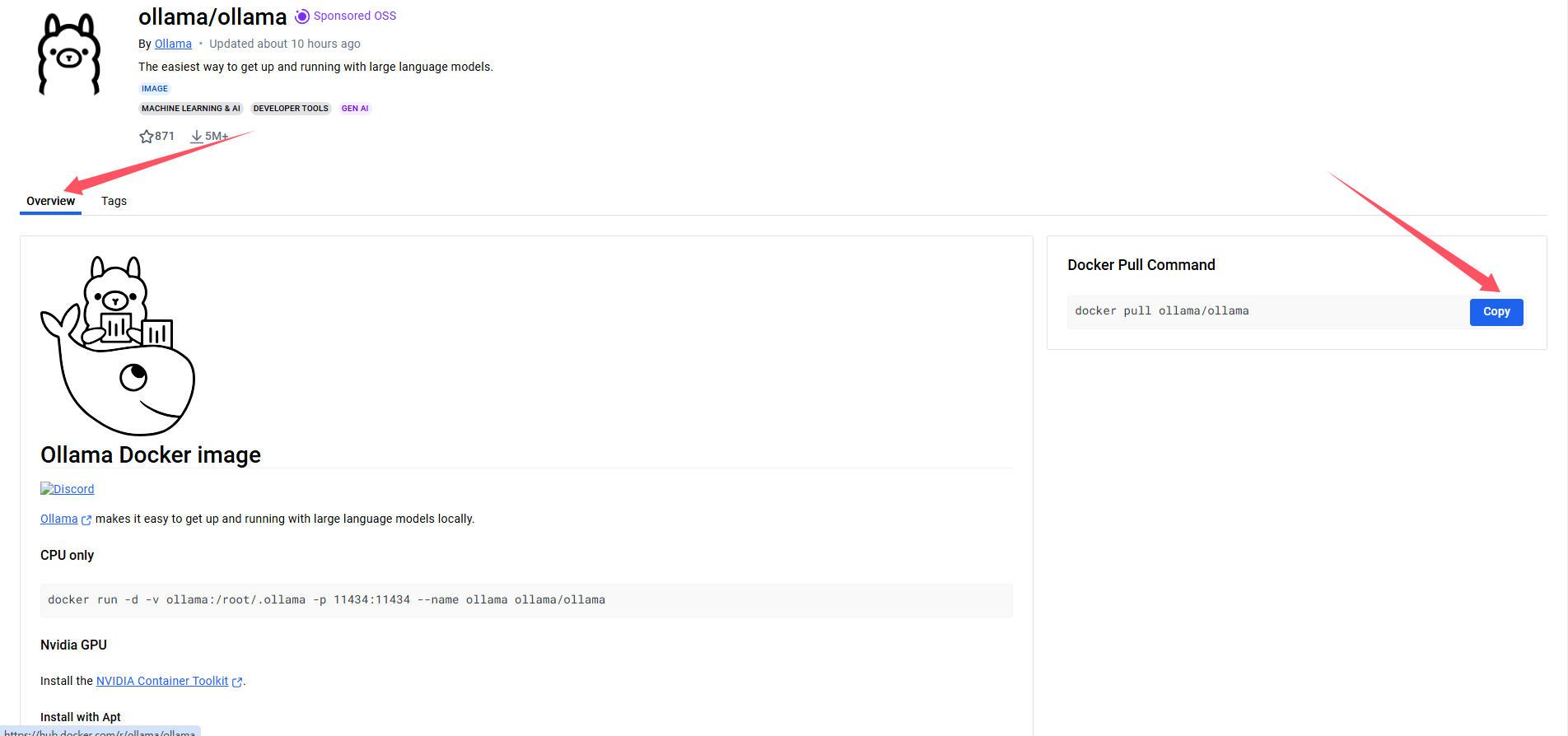
在以下dockerhub仓库找到ollama的拉取命令
https://hub.docker.com/r/ollama/ollama/tags
如以下,也可以在Tags里找到安装指定版本的拉取命令
docker pull ollama/ollama
在终端输入命令
docker pull ollama/ollama:latest
等待下载完成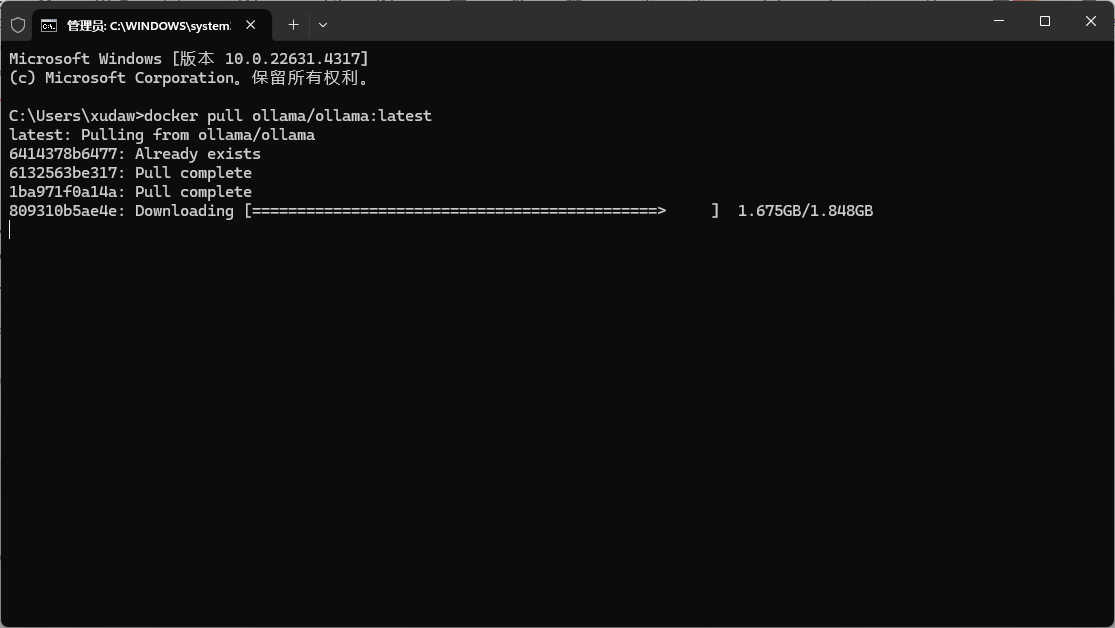
启动ollama
使用以下命令运行镜像为容器
CPU only
docker run --name ollama_container0.4.3 -v C:\xudawu\DockerData2024_09_29\ollama_2024_11_21:/root/.ollama -p 11434:11434 -d ollama/ollama
NVIDIA GPU
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
来源,我这里的命令修改了容器名字和挂载的路径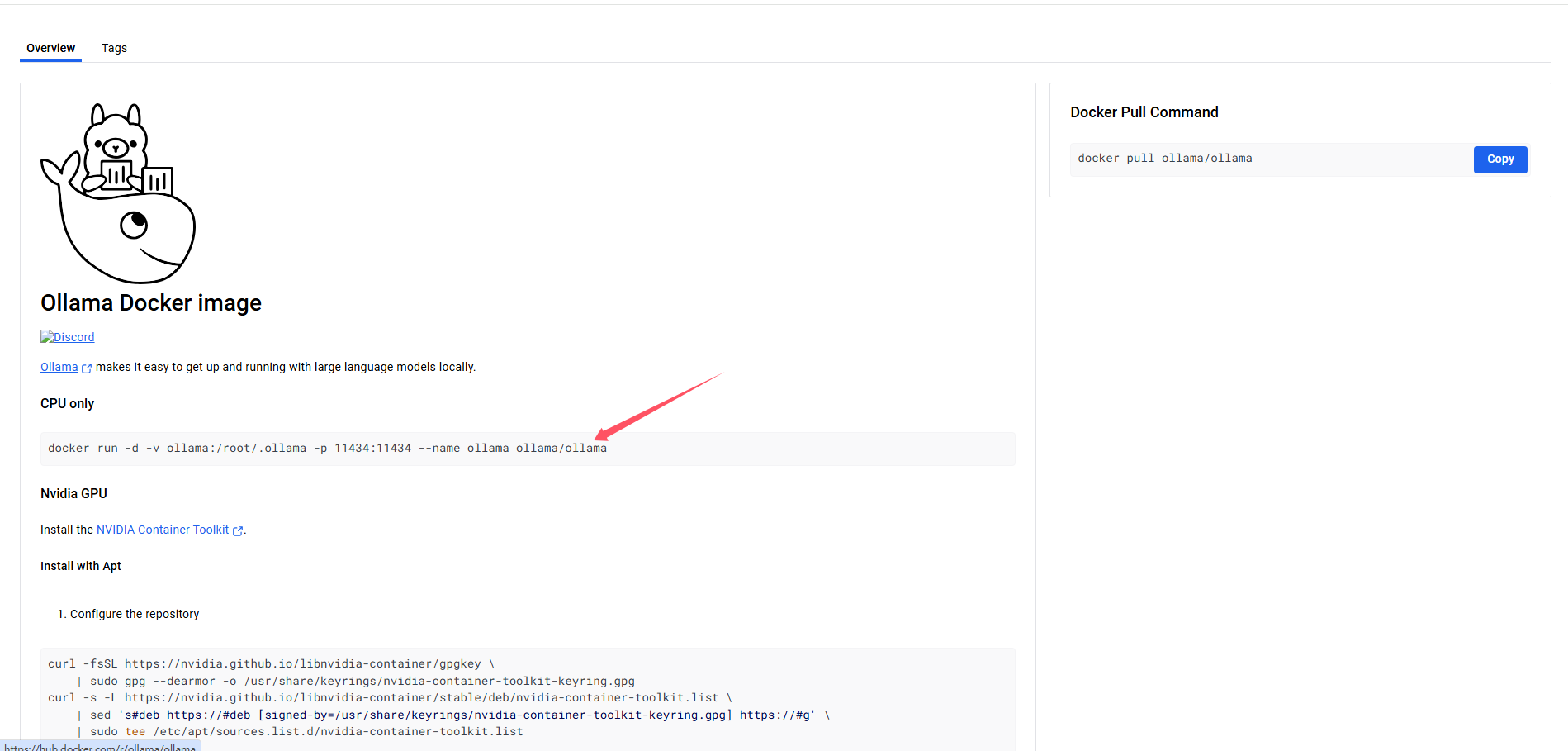
启动成功
在docker中能看到端口号,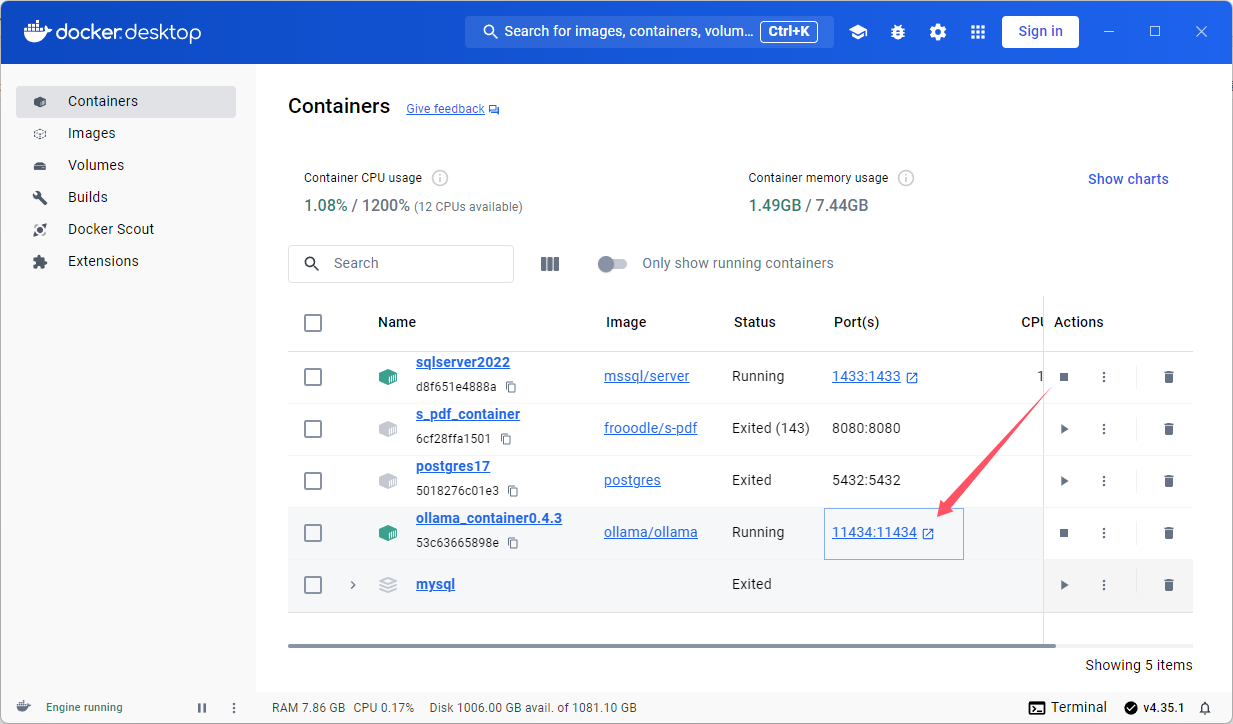
本地通过以下地址访问
http://localhost:11434/
代表ollama正常启动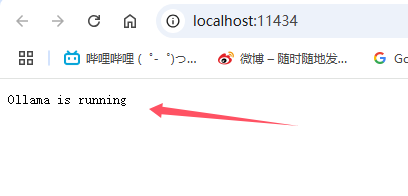
使用ollama命令
在ollama命令前,增加
docker exec -it ollama_contain_name
如以下完整的命令
docker exec -it ollama_contain_name ollama run qwen2.5-coder:3b
本地没有模型会先自动下载模型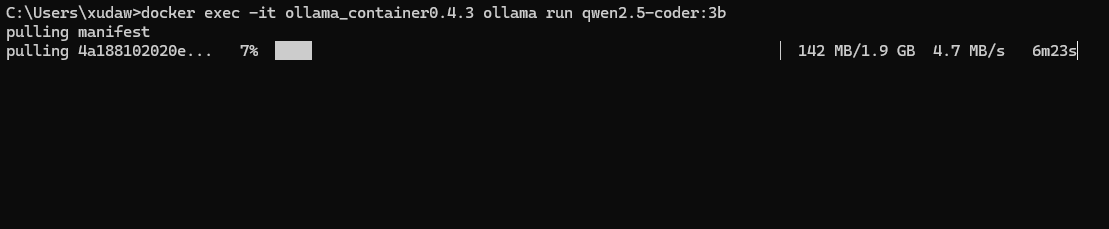
docker部署应用访问ollama的url
http://host.docker.internal:11434
或者使用本机ip地址:11434
ollama删除部署模型
ollama rm model_name
使用ollama的api
'''
Author: xudawu
Date: 2025-08-20 11:22:01
LastEditors: xudawu
LastEditTime: 2025-08-20 11:48:00
'''
import requests
import json
# url = "http://192.168.30.72:11434/api/generate"
# data = {
# "model": "gpt-oss:120b",
# "prompt": "用Python写一个Hello World",
# "stream": False
# }
# response = requests.post(url, json=data)
# # 字符串转字典
# result_dict = json.loads(response.text)
# print('模型思考')
# print(result_dict.get('think'))
# print('- '*20)
# print("模型输出:")
# print(result_dict.get('response'))
# print('- '*20)
# print('历史')
# print(response.history)
# 非流式多轮对话
'''
def ollama_chat(model="gpt-oss:120b"):
# 初始化对话历史(空列表)
chat_history = []
print(f"开始与 {model} 对话(输入 'exit' 退出):")
while True:
# 1. 获取用户输入
user_input = input("你:")
if user_input.lower() == "exit":
print("对话结束")
break
# 2. 将用户输入添加到对话历史
chat_history.append({"role": "user", "content": user_input})
# 3. 调用 Ollama 的 chat 接口
response = requests.post(
url="http://192.168.30.72:11434/api/chat",
json={
"model": model,
"messages": chat_history, # 传递完整对话历史
"stream": False # 非流式
}
)
# 4. 解析模型响应
result = json.loads(response.text)
assistant_reply = result["message"]["content"]
# 5. 将模型响应添加到对话历史(用于下一轮上下文)
chat_history.append({"role": "assistant", "content": assistant_reply})
# 6. 打印模型回复
print(f"{model}:{assistant_reply}\n")
# 启动对话(可替换为其他模型,如 "gemma"、"mistral" 等)
if __name__ == "__main__":
ollama_chat(model="gpt-oss:120b")
'''
# 流式多轮对话
def handle_stream_response(model="gpt-oss:120b"):
chat_history = [] # 维护对话历史
print(f"开始与 {model} 对话(输入 'exit' 退出):")
while True:
# 1. 获取用户输入
user_input = input("你:")
if user_input.lower() == "exit":
print("对话结束")
break
# 2. 更新对话历史
chat_history.append({"role": "user", "content": user_input})
# 3. 发送流式请求
try:
with requests.post(
url="http://192.168.30.72:11434/api/chat",
json={
"model": model,
"messages": chat_history,
"stream": True # 启用流式输出
},
stream=True, # 保持连接,接收分块数据
timeout=300 # 大模型响应较慢,设置较长超时
) as response:
print(f"{model}:", end="", flush=True) # 不换行,实时拼接内容
full_reply = "" # 累积完整回复
# 4. 逐行解析流式响应
for line in response.iter_lines():
if not line:
continue # 跳过空行
# 解析单行JSON
try:
chunk = json.loads(line.decode("utf-8"))
except json.JSONDecodeError as e:
print(f"\n解析错误:{e},原始内容:{line}")
continue
# 提取当前片段内容
if "message" in chunk and "content" in chunk["message"]:
content = chunk["message"]["content"]
print(content, end="", flush=True) # 实时打印
full_reply += content # 累积到完整回复
# 检查是否结束
if chunk.get("done", False):
break
# 5. 更新对话历史(添加完整回复)
chat_history.append({"role": "assistant", "content": full_reply})
print("\n") # 本轮对话结束后换行
except Exception as e:
print(f"\n请求错误:{str(e)}")
# 出错时移除最后一条用户输入,避免污染历史
chat_history.pop()
if __name__ == "__main__":
handle_stream_response(model="gpt-oss:120b") # 替换为你的模型名

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)