
机器学习 K近邻
机器学习 K近邻 KNN (k-neareast neighbor) 是解决分类与回归问题最基本的机器学习算法之一, 该算法没有显式的训练过程. 本节内容包括: k近邻是什么, K近邻案例实战.
概述
k 近邻 (k-neareast neighbor, kNN) 是解决分类与回归问题最基本的机器学习算法之一. 该算法没有显式的训练过程.
k 近邻算法的核心思想用一一句话就可以概括: "给定测试样本, 基于某种距离度量找出训练集中与其最近的 k 个训练样本, 然后基于这 k 个邻近 的信息进行预测.
k 近邻算法的三个要素:
- 距离度量
- k 值的选择
- 分类决策规则
案例 (电影题材定义)
简介
动作片和爱情片的区别在于: 动作片中打斗镜头的次数较多, 而爱情片中接吻镜头较多. 但是我们不能单纯通过是否存在打斗镜头或者接吻镜头来判断影片的类别.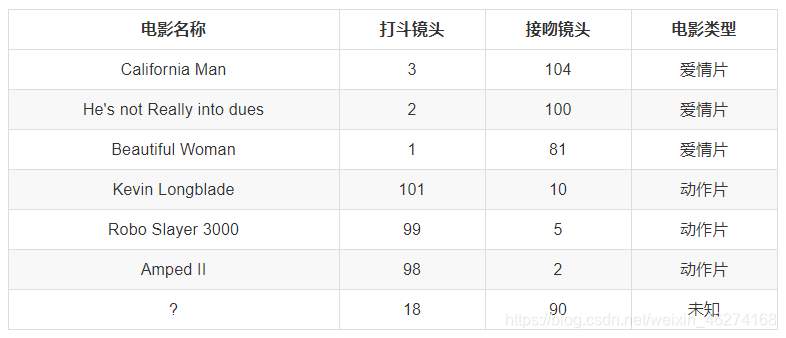
距离度量
两部电影的相似程度可用距离来表示. 若两部电影之间的特征越接近,则认为这两部电影越相似.
因此, 我们需要考虑如何度量两个样本之间的距离.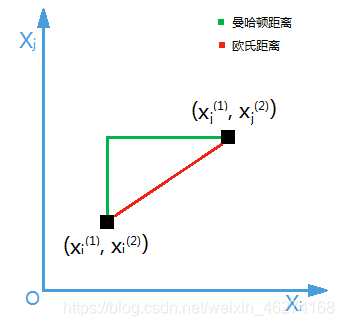
欧式距离
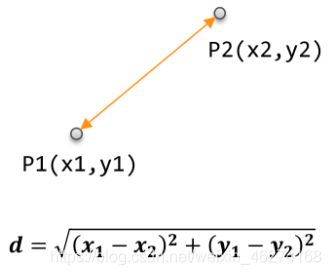
如果说输入变量有四个特征, 例如 (1,3,5,2) 和(7,6,9,4)之间的距离计算为: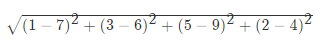
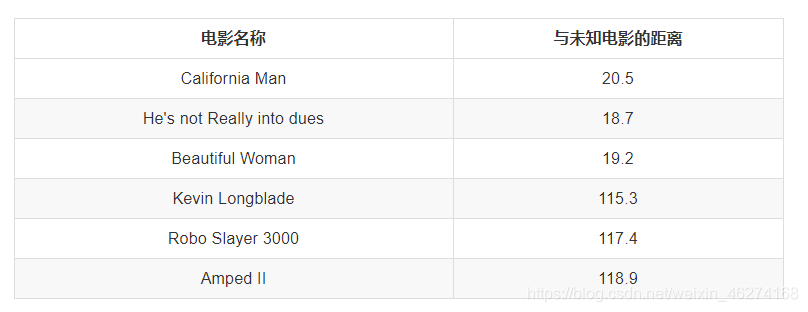
我们可以看出, 排名前三的电影类型都是爱情片, 所以我们判定这个未知电影也是一个爱情片.
K 值的选择
有时候, k 值的选择不同, 预测的结果也会不同.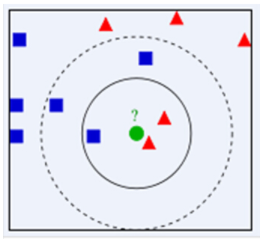
k 值的选取决定了绿色小球的类别.
上图汇总, 当 k = 3 时, 小球为红三角形; 当 k = 5 时, 小球为蓝色正方形.
注: 可以用交叉验证法来确定最优的 k 值. (后面会讲)
分类决策规则
在分类问题中, 我们通常是在取 k 个样本后, 采取多数表决. 而在回归问题 (Regression) 中, 我们可以取 k 个样本后, 对其结果 Y 进行平均或者加权平均.
注: k 近邻算法只能在较小的样本上使用, 且使用并不广泛.
数据集分割
为什么要做数据集分割
一般在进行模型的测试时, 我们会将数据分为训练集合测试集. 在给定的样本空间中, 拿出大部分样本作为训练集来训练模型, 剩余的小部分样本使用刚建立的模型进行预测.
注: 分割数据前, 要确定我们已经对数据进行了明确.
图示
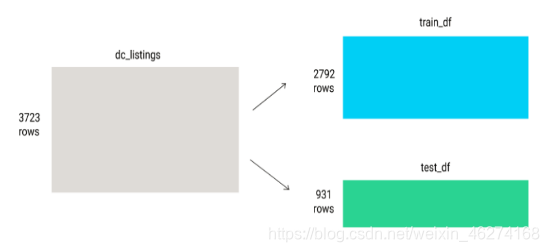
代码如下:
# 训练集 train: x_train, y_train, 测试集 test: x_test, y_test
x_train, x_test, y_train, y_test = train_test_split(li.data, li.target, test_size=0.25)
交叉验证
训练集与测试集的分割可以使用 cross_validation 中的 train_test_split 方法. train_test_split 方法内部使用的就是交叉验证迭代器, 默认不会进行打散. (如果数据具有时间性, 千万不要打散数据在划分)
代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 实例化
li = load_iris()
# 注意返回值: 训练集 train: x_train, y_train, 测试集 test: x_test, y_test
x_train, x_test, y_train, y_test = train_test_split(li.data, li.target, test_size=0.25)
# 调试输出
print("训练集特征值和目标值: ", x_train, y_train)
print("测试集特征值和目标值: ", x_test, y_test)
K 折交叉验证, 初始采样分割成 K 个样本, 一个单独的子样本被保留作为验证模型的数据, 其他 K-1 个样本用来训练. 交叉验证重复 K 次, 每个子样本验证异常, 平均 K 次的结果或者使用其它结合方式, 最终得到一个单一估测. 这个方法的优势在于, 同时复用运用随机产生的子样本进行训练和验证, 每次的结果验证一次.
图解:
代码:
def cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
"""
:param estimator:模型估计器
:param X:特征变量集合
:param y:目标变量
:param cv:int,使用默认的3折交叉验证,整数指定一个(分层)KFold中的折叠数
:return :预估系数
"""
使用交叉验证方法的目的主要有 2 个:
- 从有限的学习数据中获取尽可能多的有效信息
- 可以在一定程度上避免过拟合问题
案例一
鸢尾花. 已知三种品种的鸢尾花(山鸢尾、维吉尼亚鸢尾、变色鸢尾)的花萼长度,花萼宽度,花瓣长度,花瓣宽度 4 个属性各 50 条. 数据样本如下: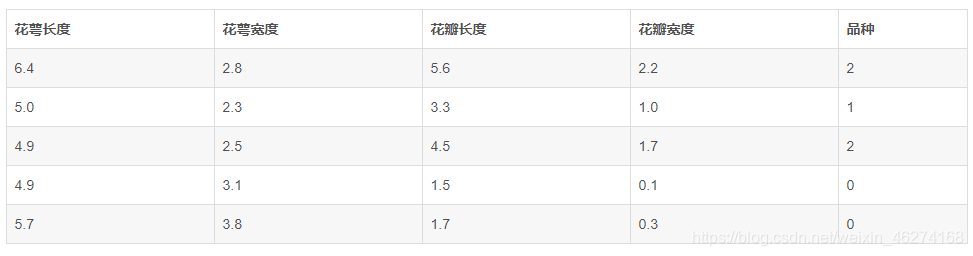
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
def knniris():
"""
鸢尾化分类
:return: None
"""
# 使用加载器读取数据并且存入变量 iris
iris = load_iris()
# 查验数据规模
print(iris.data.shape)
# 查看数据说明 (这是一个好习惯)
print(iris.DESCR)
# 分割数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.25, random_state=42)
# 标准化
ss = StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.fit_transform(x_test)
# estimator流程
knn = KNeighborsClassifier()
# 得出模型
knn.fit(x_train, y_train)
# 进行预测或者得出精度
y_predict = knn.predict(x_test)
score = knn.score(x_test, y_test)
# 通过网格搜索,n_neighbors为参数列表
param = {"n_neighbors": [3, 5, 7]}
gs = GridSearchCV(knn, param_grid=param, cv=10)
# 建立模型
gs.fit(x_train, y_train)
# print(gs)
# 预测数据
print(gs.score(x_test, y_test))
# 分类模型的精确率和召回率
# print("每个类别的精确率与召回率:",classification_report(y_test, y_predict,target_names=lr.target_names))
return None
if __name__ == "__main__":
knniris()
案例二
预测用户签到位置.
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
import pandas as pd
def knn():
"""
K-近邻预测用户签到位置
:return: None
"""
# 读取数据
data = pd.read_csv("train.csv")
print(data.head())
# 处理数据
# 1. 缩小数据, 查询数据筛选
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y< 2.75")
# 2. 处理时间的数据
time_value = pd.to_datetime(data["time"], unit="s")
print(time_value.head())
# 3. 把时间格式转换成字典格式
time_value = pd.DatetimeIndex(time_value)
print(time_value)
# 4. 构造一些特征
data["day"] = time_value.day
data["hour"] = time_value.hour
data["weekday"] = time_value.weekday
print(data.head())
# 5. 把时间戳特征删除
data = data.drop(["time"], axis=1)
print(data.head())
# 6. 删除row_id小于3的数据
place_count = data.groupby("place_id").count()
print(place_count.head())
tf = place_count[place_count.row_id > 10].reset_index()
print(tf[:5])
data = data[data["place_id"].isin(tf.place_id)]
data = data.drop(["row_id"], axis=1)
print(data.head())
# 7. 取出数当中的特征值和目标值
y = data["place_id"]
x = data.drop(["place_id"], axis=1)
# 8. 进行数据分割训练集合和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 特征工程 (标准化)
std = StandardScaler()
# 1. 对测试集和训练集的特征进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 1. 进行算法流程
knn = KNeighborsClassifier(n_neighbors=5)
# 2. fit
knn.fit(x_train, y_train)
# 3. 得出预测结果
y_predict = knn.predict(x_test)
print("预测的目标签到位置为: ", y_predict)
# 4. 得出准确率
print("预测的准确率: ", knn.score(x_test, y_test))
return None
if __name__ == "__main__":
knn()
案例三
Airbnb 房价预测任务.
如果我有一个3个房间的房子, 我能租多少钱呢?
import pandas as pd
import numpy as np
# 特征集
features = ['accommodates', 'bedrooms', 'bathrooms', 'beds', 'price', 'minimum_nights', 'maximum_nights',
'number_of_reviews']
# 读取数据
data = pd.read_csv("listings.csv")
print(data.head())
print(data.shape)
# 筛选特征
data = data[features]
print(data.head())
# 计算距离
data["distance"] = np.abs(data["accommodates"] - 3)
print(data.head())
# 距离排序
distance_array = data["distance"].value_counts().sort_index()
print(distance_array)
# 距离最近的价格
data = data.sample(frac=1, random_state=0)
data = data.sort_values("distance")
print(data["price"].head())
# 转换为数字
data["price"] = data["price"].str.replace("\$|,", "").astype(float)
mean_price = data["price"].iloc[:5].mean()
print(mean_price)
# 模型评估
data = data.drop("distance", axis=1)
print(data.head())
train_df = data.copy().iloc[:2792]
test_df = data.copy().iloc[2792:]
def predict_price(new_listing_value, feature_column):
temp_df = train_df
temp_df["distance"] = np.abs(data[feature_column] - new_listing_value)
temp_df = temp_df.sort_values("distance")
knn_5 = temp_df["price"].iloc[:5]
predicted_price = knn_5.mean()
return predicted_price
test_df["predicted_price"] = test_df["accommodates"].apply(predict_price, feature_column="accommodates")
print(test_df.head())
# 计算方差
test_df["squared_error"] = (test_df["predicted_price"] - test_df["price"]) ** (2)
mse = test_df["squared_error"].mean()
rmse = mse ** 0.5
print("均方根误差: ", rmse)
# 测试不同变量
for feature in ['accommodates', 'bedrooms', 'bathrooms', 'number_of_reviews']:
test_df["predicted_price"] = test_df['accommodates'].apply(predict_price, feature_column=feature)
test_df['squared_error'] = (test_df['predicted_price'] - test_df['price']) ** (2)
mse = test_df['squared_error'].mean()
rmse = mse ** (1 / 2)
print("RMSE for the {} column: {}".format(feature, rmse))
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error
from scipy.spatial import distance
# 特征集
features = ['accommodates', 'bedrooms', 'bathrooms', 'beds', 'price', 'minimum_nights', 'maximum_nights',
'number_of_reviews']
# 读取数据
data = pd.read_csv("listings.csv")
# 筛选特征
data = data[features]
# 数据清洗
data["price"] = data["price"].str.replace("\$|,", "").astype(float)
# 去掉na
data = data.dropna()
# 标准化
data[features] = StandardScaler().fit_transform(data[features])
print(data.head())
# 分割训练集合测试集
normalized_train_df = data.copy().iloc[:2792]
normalized_test_df = data.copy().iloc[2792:]
# 计算距离
first_listing = data.iloc[0][["accommodates", "bathrooms"]]
twentieth_listing = data.iloc[19][["accommodates", "bathrooms"]]
first_twentieth_distance = distance.euclidean(first_listing, twentieth_listing)
print("第一条数据到第二十条数据的距离: ", first_twentieth_distance)
# 完成KNN
cols = ["accommodates", "bathrooms"]
knn = KNeighborsRegressor()
knn.fit(normalized_train_df[cols], normalized_train_df["price"])
two_feature_predictions = knn.predict(normalized_test_df[cols])
two_feature_mse = mean_squared_error(normalized_test_df["price"], two_feature_predictions)
two_feature_rmse = two_feature_mse ** 0.5
print("均方根误差: ", two_feature_rmse)
# 加入更多特征
cols = ['accommodates','bedrooms','bathrooms','beds','minimum_nights','maximum_nights','number_of_reviews']
knn.fit(normalized_train_df[cols], normalized_train_df["price"])
four_features_predictions = knn.predict(normalized_test_df[cols])
four_features_mse = mean_squared_error(normalized_test_df['price'], four_features_predictions)
four_features_rmse = four_features_mse ** 0.5
print("均方根误差: ", four_features_rmse)

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)