
机器学习基础概念深度解析:从理论到实战
机器学习是一门强大的技术,它通过对数据的学习和分析,能够为我们提供有价值的预测和决策支持。简单来说,就是根据已有的数据,进行算法选择,并基于算法和数据构建模型,最终对未来进行预测。在使用时需要合理选择 n_neighbors 参数,若想测试一系列的 n_neighbors 值,可以重复进行多次实验,观察不同参数值带来的结果差异。在训练过程中,通过调整 n_neighbors 等参数,观察模型在验证
机器学习基础概念深度解析:从理论到实战
一、机器学习概述
(一)定义
Machine Learing(ML) 是一门涉及构建和研究能够从数据中学习的算法的科学学科。简单来说,就是根据已有的数据,进行算法选择,并基于算法和数据构建模型,最终对未来进行预测。通过历史数据进行建模,再利用建模后的公式进行预测处理,理论上,数据量越多,预测就越准确。
(二)与人工智能和深度学习的关系
人工智能是研究使计算机模拟人的某些思维过程和智能行为(如学习、推理、思考、规划等)的学科,涉及计算机科学、心理学、哲学和语言学等学科。深度学习是机器学习领域中的一个新研究方向,它让机器学习更接近人工智能的最初目标。
二、机器学习的分类及应用场景

(一)监督学习
监督学习是机器学习中重要的分支,其数据集由特征值和目标值构成。它又可细分为回归和分类等任务。
1. 回归:只有一个输入数据 X,需要对其进行处理得出未知结果 Y,即从一个数据推测出另一个数据,前提是有样例作为参考。例如,根据房屋面积、房间数量等特征来预测房屋价格。
2. 分类:将数据划分到不同的类别中。比如,判断一封邮件是垃圾邮件还是正常邮件。在使用近邻算法进行分类时,最重要的参数是选取多少个近邻作为预测依据,在 scikit_learn 中这个参数叫 n_neighbors。当这个参数过小时,分类结果易受干扰,随机性很强;反之,如果 n_neighbors 过大,实际近邻的影响将削弱。

(二)无监督学习
无监督学习不需要目标值,主要包括聚类和降维等任务。
1. 聚类:将数据集中的样本自动分组到不同的簇中,这些簇通常是不相交的。例如,将客户根据消费习惯进行分类,以便企业制定不同的营销策略。
2. 降维:降低数据的复杂度,减少冗余信息,参数减少,增强鲁棒性。PCA(主成分分析)就是一个重要的降维应用,在大数据处理中能有效减小运算量。
(三)半监督学习
半监督学习使用的数据一部分是标记过的,而大部分是没有标记的,通过利用未标记数据来提高学习效果。
(四)强化学习
强化学习使用机器的个人历史和经验来做出决定,不涉及提供正确的答案或输出,只关注性能。其经典应用是玩游戏,反映了人类根据积极和消极的结果进行学习的方式。
三、机器学习的数据处理流程
(一)数据收集与准备
收集与问题相关的数据,并进行清洗、预处理等操作,确保数据的质量和可用性。例如,处理缺失值、异常值等。
(二)特征工程
从原始数据中提取有用的特征,对特征进行选择和转换,以提高模型的性能。比如,对文本数据进行词袋模型转换。
(三)模型选择与训练
根据数据的特点和问题的类型,选择合适的算法和模型。然后使用训练数据对模型进行训练,调整模型的参数。例如,使用 scikit_learn 库中的算法进行模型训练。
(四)模型评估与优化
使用测试数据对训练好的模型进行评估,常见的评估指标有准确率、召回率、均方误差等。如果模型的性能不理想,需要对模型进行优化,如调整超参数、使用正则化方法等。
四、常用机器学习算法

(一)近邻算法
近邻算法根据数据之间的距离来进行预测。在使用时需要合理选择 n_neighbors 参数,若想测试一系列的 n_neighbors 值,可以重复进行多次实验,观察不同参数值带来的结果差异。
(二)决策树
决策树是一种直观且易于理解的监督学习方法,适用于分类与回归任务。它通过对数据的特征进行划分,构建出决策树模型。
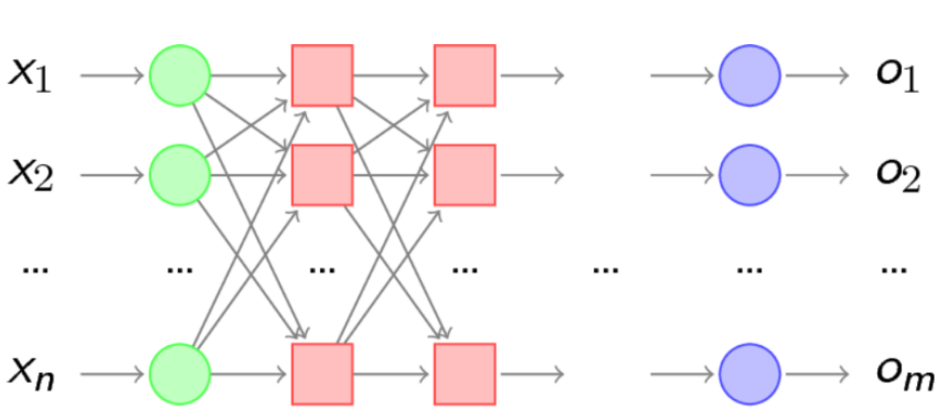
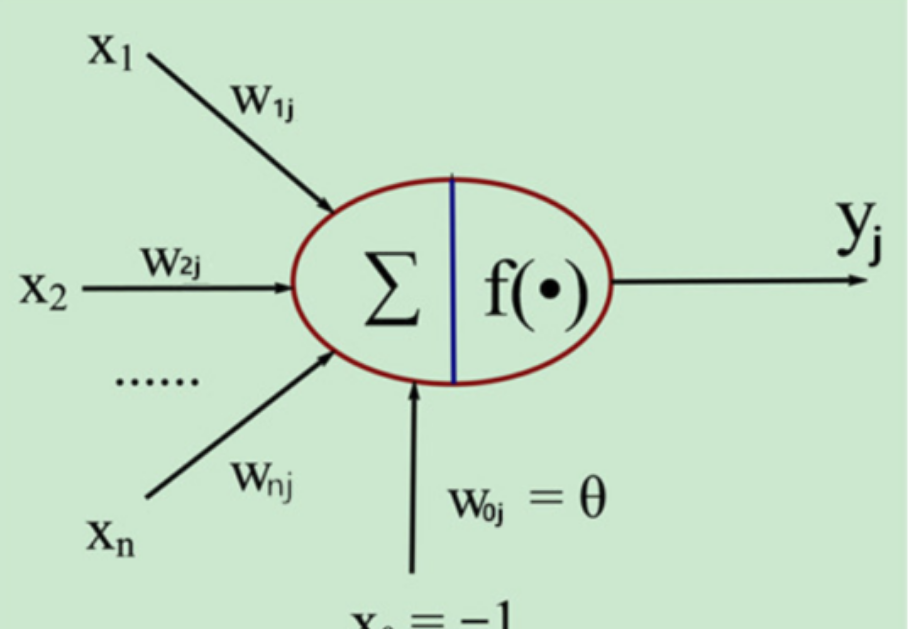
(三)神经网络相关模型
1. 人工神经元模型(M - P 模型):是神经网络最基本的模型。
2. 感知机:最简单的神经网络结构,类似于 M - P 模型,有基本的输入和输出。
3. 前馈神经网络:常见的如感知机、BP 神经网络、RBF 径向基网络等。
4. 卷积神经网络(CNN):包含卷积层和池化层,适用于大型图像处理和语音识别等任务,能够降低复杂度,减少冗余信息,增强鲁棒性。
五、机器学习实战案例
(一)准备工作
以使用 scikit - learn 的近邻算法进行估计器分类为例,目标是建立分类器,自动判别数据的好坏。数据集来自 ionosphere.data 和 ionosphere.names,需将其保存到用户主目录下的 Data 文件夹中。
(二)模型训练与调优
在训练过程中,通过调整 n_neighbors 等参数,观察模型在验证集上的性能表现,选择最优的参数组合。例如,使用网格搜索方法来寻找最优的 n_neighbors 值。
(三)结果评估
使用测试集对训练好的模型进行评估,计算准确率、召回率等指标,以评估模型的性能。
六、机器学习中的常见问题及解决方法
(一)欠拟合与过拟合
1. 欠拟合:学习能力太差,训练样本的一般性质尚未学好。解决方法包括增加模型复杂度、增加训练数据等。
2. 过拟合:学习能力过强,把训练样本所包含的不太一般的特性都学到了。可采用 Dropout 方法(前向传播时,随机选取和丢弃指定层次之间的部分神经连接)等进行解决。
(二)反向传播与优化
反向传播是神经网络中重要的算法,Adam(自适应时刻估计方法)能够自动改变学习速率大小,实现智能化的优化。

七、总结
机器学习是一门强大的技术,它通过对数据的学习和分析,能够为我们提供有价值的预测和决策支持。不同类型的机器学习算法适用于不同的应用场景,在实际应用中需要根据具体问题选择合适的算法和模型。同时,要注意处理好欠拟合、过拟合等问题,不断优化模型性能,以实现更好的预测效果。无论是在学术研究还是工业应用中,机器学习都有着广阔的发展前景。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)