
大数据系统技术
由HDFS和Mapreduce组成的大数据处理框架;HDFS为海量的数据提供存储功能MapReduce为海量的数据提供计算功能。
大数据系统
技术方案
Hadoop是最受欢迎、最成熟、应用最广的大数据系统架构之一
| 方案 | 组件 |
|---|---|
| 静态数据的批量处理 | Hadoop |
| 流式数据的实时处理 | Storm |
| 交互式数据处理 | Spark |
大数据主流工具
| 名称 | 描述 |
|---|---|
| Hadoop | 是一个具有分布式存储(HDFS)和分布式计算(MapReduce)的大数据处理框架 |
| ZooKeeper | 是Hadoop和HBase的重要组件;是一个分布式的、开放源码的分布式应用程序协调服务 |
| HBase | 是一个高可靠性、高拓展性、面向列、可伸缩的分布式结构化存储系统 |
| Spark | 是专为大规模数据处理而设计的快速通用的计算引擎; 是一种与 Hadoop相似的开源集群计算环境; |
| Hive | 可以存储、查询和分析存储在Hadoop中的大规模数据 |
| MongoDB | 是一个基于分布式文件存储的数据库 |
| Kafka | 是一种高吞吐量的分布式发布订阅消息系统 |
| Storm | 是一个实施的、分布式以及高容错的计算系统 |
| Flume | 是一种分布式的日志收集框架 |
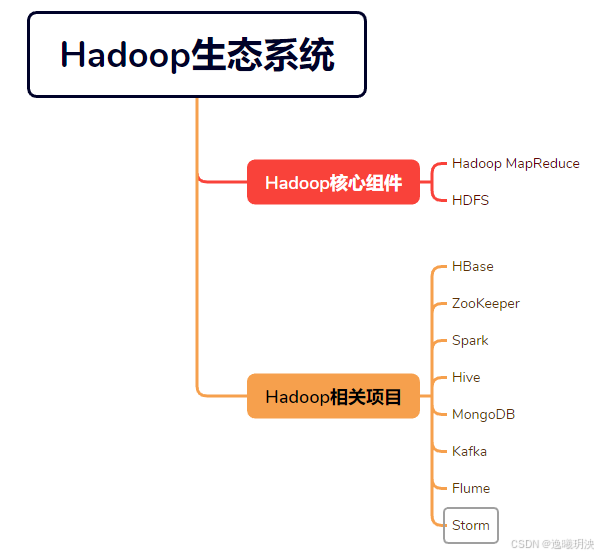
工具介绍
Hadoop
由
HDFS和Mapreduce组成的大数据处理框架;
HDFS为海量的数据提供存储功能
MapReduce为海量的数据提供计算功能
版本区别
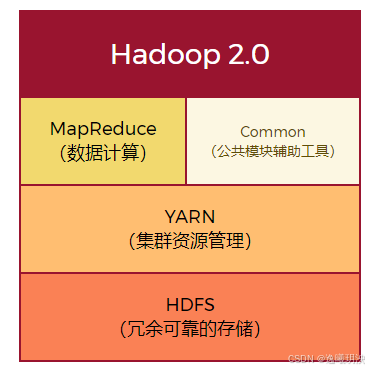

组件的服务进程
HDFS服务进程
工作结构式是:主从结构
即,主节点
NameNnode,从节点DataNode
| NameNode | DataNode | Secondary NameNode |
|---|---|---|
负责接收用户的操作请求、维护文件系统的目录结构、管理文件与块(Block)之间的关系,块与DataNode之间的关系 |
负责存储文件;文件被分成块,存储在磁盘上 |
辅助NameNode工作;用于备份元数据和恢复元数据 |
MapReduce和Yarn的服务进程
同样,工作结构也是:主从结构
即,主节点
ResourceManager,从节点NodeManager
| ResourceManager | NodeManager |
|---|---|
负责接收客户提交的计算任务,然后把计算任务分配给NodeManageer执行,并监控其执行情况 |
复制执行ResourceManager分配的计算任务 |
优点
| 描述 | |
|---|---|
| 可靠性 | 使用位存储和处理数据 |
| 高拓展性 | 计算是在可用的计算机集群之间分配数据并完成计算任务,集群可以无限拓展 |
| 高效性 | 能在节点之间动态的移动数据,并保证各个节点的动态平衡 |
| 高容错性 | 能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配 |
| 低成本 | 开源软件,项目成本大大降低 |
Zookeeper
是Hadoop和HBase的重要组件;
基于Hadoop集群
目标:封装好那些复杂的、容易出错的关键服务,把
简单易用的接口和功能稳定、性能高效的系统提供给用户
身份特性
| Leader | Follower | Observer |
|---|---|---|
负责客户端写操作的请求 |
负责客户端读操作的请求;并参与leader的选举 |
是特殊的follower,可以接收客户端读操作的请求,但不会参与选举 |
HBase
-
使用此项技术,可以在廉价的
PC Server上搭建起大规模数据存储的集群 -
位于
Hadoop生态系统中HDFS的上层,依靠MapReduce进行资源管理;便于拓展集群 -
需要在Hadoop和ZooKeeper的基础上工作,依赖ZooKeeper
对于
HBase版本≥0.98.5,需要在启动HBase之前,提前设置JAVA_HOME环境变量对于
HBase版本<0.98.5,HBase会检测Java的位置,若无Java有提示
有严格JDK支持列表;需要根据HBase官网版本文档及JDK对应版本进行安装使用
如果基于
HDFS平台的分布式模式安装,必须考虑HBase与Hadoop的兼容性
功能
| Client | 包含HBase的接口,维护着一些高速缓存;用于加快对HBase的访问 |
|---|---|
| ZooKeeper | 实时监控Region和Server的状态;存储HBase的模式 |
| Master | 为Region Server分配Region;负责Region Server的负载均衡 |
| Region Server | 维护Master分配给它的Region,并处理这些Region的I/O请求; |
运行模式
| 独立模式(Standalone) 默认模式 |
分布式模式(Distributed) | |
|---|---|---|
| 伪分布模式 | 完全分布式模式 | |
| 使用本地文件系统,运行,在同一个JVM中所有HBase守护进程和本地ZooKeeper | 守护进程运行在单个节点 | 守护进程运行在集群中的所有节点上 |
| 既可以在本地文件系统运行,也可以在HDFS上运行 | 只能在HDFS上运行 |
HDFS与HBase对比
| HDFS | HBase |
|---|---|
| 更适合批处理场景 | 更适合对数据进行随机读写、大量高并发应用、读写访问等非常简单的操作 |
| 不支持数据随机查找、 | 不适用于关系查询和计算 |
| 不适合增量数据处理,不支持数据更新 |
Spark
将
Stream数据分成小的时间片段,以类似batch批量处理的方式来处理这小部分数据;
-
类
Hadoop MapReduce的通用并行框架 -
启用内存分布数据集;即在内存上运行
性能优点
| 描述 | |
|---|---|
| 有更快的运行速度 | 因:启用内存分布数据集 |
| 易用性 | 提供多种高级运算符 |
| 通用性 | 提供大量的库 |
| 支持多种资源管理器 | 支持第三方以及自带的独立集群管理器 |
| Shark | 提供和Hive一样的HiveQL命令接口,最大程度保持和Hive的兼容 |
| Spark R | 为R语言提供轻量级的Spark前端的R包;提供一个分布式的data frame数据结构 |
Hive
环境:Java、Hadoop、MySQL
-
在
Hadoop生态系统中Hadoop组件之上 -
基于
Hadoop的数据仓库
运行模式
| 嵌入模式 | 本地模式 | 远程模式 |
|---|---|---|
元数据信息被存储在Hive自带的Derby数据库中,而且只允许创建一个连接 |
元数据信息被存储在MySQL中,MySQL与Hive运行在同一台物理计算机或服务器上 |
元数据信息被存储在MySQL中,MySQL与Hive运行在不同物理计算机或服务器上 |
| 用于测试 | 用户开发与测试 | 用于实际生产环境 |
数据仓库的两个方面
| 面向主题的 | 集成的 |
|---|---|
| 这是一个面向主题的、集成的、不可更新的、随时间而变化的数据集合 用于支持企业或组织的决策分析处理 |
仓库中的数据来自分散的操作型数据,包含规范化以及非规范化的数据;它将所需数据从原来的信息中抽取出来,进行加工与集成、统一与综合,保证仓库信息的一致性; |
优点
- 学习成本低,开发灵活
缺点
-
执行速度慢
-
不支持数据的更新、删除操作
MongoDB
-
介于
关系数据库与非关系数据库之间的产品 -
首先要先配置好Hadoop集群服务,才配置MongoDB服务
-
仅在
Hadoop集群的主节点上配置MongoDB
基本概念
文档
是
MongoDB中数据的基本单位,类似关系型数据库中的行(但比行复杂)多个键及其关联的值有序的放在一起就构成了文档
集合
就是一组文档,类似关系型数据库中的
表;
数据库
由多个文档组成集合,多个集合组成数据库
系统数据库
| Admin数据库 | Local数据库 | Config数据库 |
|---|---|---|
| 是一个权限数据库 | 用于存储本地单台服务器的任意集合;不会被复制 | 当使用分片模式时,用于保存分片的信息;仅在内部使用 |
数据模型
一个
MongoDB实例可以包含一组数据库(Database)、一个数据库可以包含一组集合(Collection)、一个集合可以包含一组文档(Document)、一个文档可以包含一组字段(Field),每个字段都是一个键值对(Key/Value pair)
功能特性
| 1. 面向集合存储,易存储对象类型的数据 | 7. 使用高效的二进制数据存储,包括大型对象 (如视频等) |
|---|---|
| 2. 模式自由 | 8. 自动处理碎片,以支持云计算层次的扩展性 |
| 3. 支持动态查询 | 9. 支持Ruby、Python、Java、C++、PHP、C#等多种语言 |
| 4. 支持完全索引 | 10. 文件存储格式为BSON(JSON文件的一种扩展) |
| 5. 支持查询 | 11. 可通过网络访问 |
| 6. 支持复制和故障恢复 |
场景
| 适用场景 | 不适用场景 |
|---|---|
| 1. 网站实时数据处理 | 1. 要求高事务性的系统 |
| 2. 缓存 | 2. 传统的商业智能应用 |
| 3. 高伸缩性的场景 | 3. 复杂的跨文档(表)的级联查询 |
Kafka
是一个分布式消息队列
必须首先配置
Hadoop、ZooKeeper集群服务依赖ZooKeeper服务
- 具有高性能、持久化、多副本备份、横向扩展能力
基本概念
代理服务器
Kafka集群中包含一个或多个服务器,这种服务器被称为代理服务器(Broker)或Kafka集群
- 已发布的消息会保存在一组服务器中
话题(Topic)
是消息的
分类名
分区(Partition)
是物理上的概念;每个话题包含一个或多个分区
生产者(Producer)
能够发布消息到
Kafka Broker的任何对象
消费者(Consumer)
是从
Kafka Broker读取消息的客户端;可以订阅一个或多个话题
消费者组群
为消费者进行分类;每个消费者属于一个特定的消费者组群;
特性
| 通过O(1)的磁盘数据结构提供消息的持久化 |
|---|
| 高吞吐量 |
| 支持通过Kafka服务器和消费机集群来进行消息分区 |
| 支持Hadoop并行数据加载 |
Flume
- 用于高效收集、聚合和移动大量且多数据源的日志数据
基本概念
| 客户端(Client) | 运行在一个独立的线程中,会产生数据 |
|---|---|
| 事件(Event) | 对数据的一种封装,是一个数据单元;是Flume中传输数据最基本的单元 |
| 代理(Agent) | 是Flume运行的核心;是Flume中最小的独立运行单位 |
| 数据源(Source) | 是数据的收集端;负责从客户端手机捕获数据并进行格式化,随后将数据封装到事件里,最后将事件放到一个或多个通道中 |
| 通道(Channel) | 是中转事件的一个临时存储,保存由Source组件传递过来的事件 |
| 沉槽(Sink) | 从通道中取出事件,负责将事件传输到下一跳或最终目的地 |
| Flume数据流 |
可靠性
使用事务的方式保证整个传输事件过程的可靠性
-
当
事件被存入Channel后、或者被传到下一个代理后、或者被存入外部目的地后、Sink才允许吧事件从Channel中删除掉 -
当节点出现故障时,日志能够被传输到其他节点上,不会丢失
由弱到强的可靠性保障:Besteffort1 ——> Store on Failure2 ——> end-to-end3
场景
| 多个代理顺序连接 | 多个代理的数据汇聚到同一个代理 | 多级流 |
|---|---|---|
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中 |
将多个代理的数据汇聚到一个用来存储数据的存储系统 | 当多种日志流流入一个代理时,将混杂的日志流分开,为每种类型的日志建立一个自己的传输通道 |
Storm
是一个分布式实时流式计算平台;
必须首先配置
Hadoop、ZooKeeper集群服务依赖ZooKeeper服务
依靠
ZooKeeper集群实现节点间的信息交换
基本概念
| 概念名 | 描述 | 作用 |
|---|---|---|
| Tuple | 被处理的数据 | |
| Spout | 数据源 | 一个Topology中的数据生产者 |
| Bolt | 数据操作 | 所有的数据处理都由Bolt完成 |
| Task | 运行于Spout或Bolt中的线程 |
|
| Worker | 运行Task线程的进程 |
具体处理组件逻辑的进程 负责实际的计算和网络通信 |
关键组件
| Topology | 一个实时应用程序; 即各个组件间的消息流动形成逻辑上的一个拓扑结构 |
|---|---|
| Steam | 以Tuple为单位组成的一条有向无界的数据流 |
| Nimbus | 负责管理Supervisor、调度Topology |
| Supervisor | 接收Nimbus发来的工作指派并基于要求运行工作进程 |
集群架构
采用主从架构
即,主节点
Nimbus,从节点(工作节点)Supervisor
- 计算模型为
DAG计算模型,Spout和Bolt节点在有向无环图李灵活组合构成Stream数据流,数据流以Tuple为基本的数据单元
适用场景
| 流数据处理 | 可以处理源源不断的消息 |
|---|---|
| 连续计算 | 可以进行连续查询并把结果即时反馈给客户 |
| 分布式 | 处理延迟极低 |
| 机器学习 | |
| 实时分析 | 数据在内存中处理 |
优点
-
常驻运行
-
流式处理(数据发一点处理一点)
-
实时处理(数据在内存中不写入磁盘)
-
DAG(Directed Acyclic Graph,有向无环图)模型
参考
《云计算与大数据技术(Linux网络平台+虚拟化技术+Hadoop数据运维)》·邢丽

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)