
大数据项目实战-基于招聘网职位数据的可视化实验教程(四、数据采集)
/ 编码格式,发送编码格式统一用UTF-8// 设置连接超时时间,单位毫秒// 请求获取数据的超时时间(即响应时间),单位毫秒if (params!= null) {// 执行HTTP请求// 检查响应状态= null) {// 读取响应内容= null) {// 创建并返回响应对象// 返回错误响应// 创建一个默认的HttpClient实例。
配置eclipse
我们需要使用eclipse通过编写java代码,爬取拉勾网中职位的数据
准备hadoop-2.7.3.tar.gz,eclipse,hadoop-eclipse-plugin-2.7.3.jar,hadoop.dll,winutile.exe
hadoop.dll,winutile.exe等等相关文件
链接:https://pan.baidu.com/s/1DnTw3lChFJy_fRfkKXInBg
提取码:xzyp
hadoop-2.7.3.tar.gz:链接:https://pan.baidu.com/s/1I1FvgICCyeBURzGx62l4QA
提取码:xzyp
把hadoop.dll和winutile.exe放到hadoop的bin文件夹里
jar包倒在eclipse安装路径的plugins
一、分析与准备
(一)分析网页数据结构
使用Google浏览器打开指定网页,按F12键进入到开发者模式,切换到Network这一项,通过设置过滤规则,查看Ajax请求中的JSON文件。
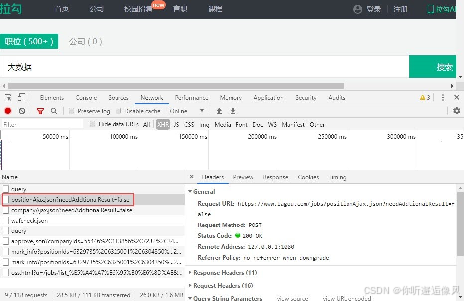
在JSON文件中找到并查看大数据相关的职位信息。
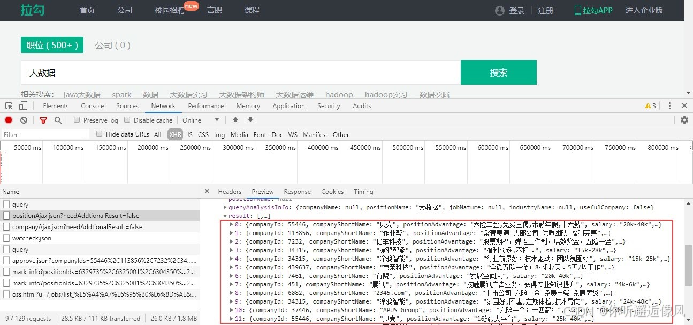
(二)数据采集环境准备
1.新建Maven项目
打开Eclipse新建项目
选择Maven项目
创建简易项目
配置Maven工程
Maven工程jobcase-reptile
2.新建Package包
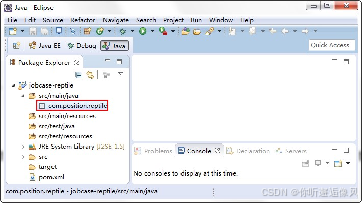
3.配置 pom.xml
在pom文件中添加编写爬虫程序所需的HttpClient和JDK1.8依赖
<dependencies>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
二、采集网页数据
(一)创建响应结果JavaBean类
通过创建的HttpClient响 应结果对象作为数据存储的载体,对响应结果中的状态码和数据内容进行封装
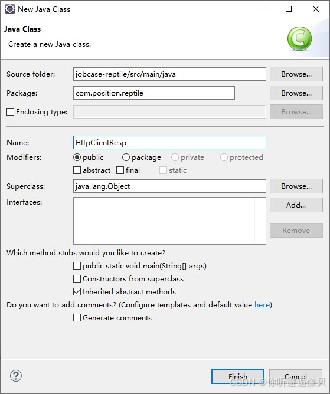
(二)封装HTTP请求的工具类
1.在com.position.reptile包下,创建一个命名为HttpClientUtils.java文件的工具类,用于实现HTTP请求的方法。
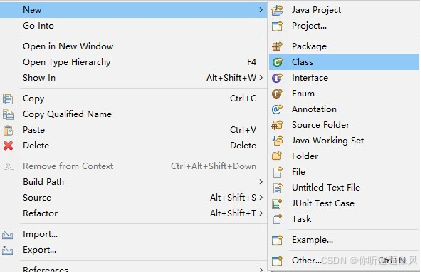
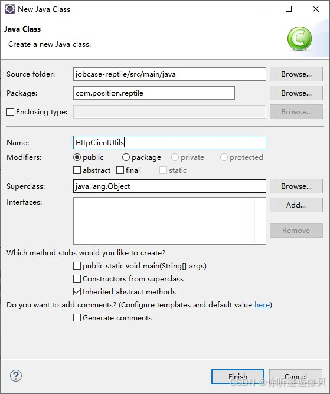
2.在类中定义常量的方式定义参数的内容
// 编码格式,发送编码格式统一用UTF-8
private static final String ENCODING = "UTF-8";
// 设置连接超时时间,单位毫秒
private static final int CONNECT_TIMEOUT = 6000;
// 请求获取数据的超时时间(即响应时间),单位毫秒
private static final int SOCKET_TIMEOUT = 6000;
3.工具类中定义packageHeader()方法用于封装HTTP请求头的参数
public static void packageHeader(Map<String, String> params,HttpRequestBase httpMethod) {
if (params != null) {
Set<Entry<String, String>> entrySet = params.entrySet();
for (Entry<String, String> entry : entrySet) {
httpMethod.setHeader(entry.getKey(), entry.getValue());
}
}
}
4.工具类中定义packageParam()方法用于封装HTTP请求参数
public static void packageParam(Map<String, String> params,
HttpEntityEnclosingRequestBase httpMethod)
throws UnsupportedEncodingException {
if (params != null) {
List<NameValuePair> nvps = new ArrayList<NameValuePair>();
Set<Entry<String, String>> entrySet = params.entrySet();
for (Entry<String, String> entry : entrySet) {
nvps.add(new BasicNameValuePair(entry.getKey(),
entry.getValue()));
}
httpMethod.setEntity(new UrlEncodedFormEntity(nvps,ENCODING));
}
}
5.在工具类中定义getHttpClientResult()方法用于获取HTTP响应内容
public static HttpClientResp getHttpClientResult(CloseableHttpResponse httpResponse, CloseableHttpClient httpClient, HttpRequestBase httpMethod) throws Exception {
// 执行HTTP请求
httpResponse = httpClient.execute(httpMethod);
// 检查响应状态
if (httpResponse != null && httpResponse.getStatusLine() != null) {
String content = "";
// 读取响应内容
if (httpResponse.getEntity() != null) {
content = EntityUtils.toString(httpResponse.getEntity(), ENCODING);
}
// 创建并返回响应对象
return new HttpClientResp(httpResponse.getStatusLine().getStatusCode(), content);
}
// 返回错误响应
return new HttpClientResp(HttpStatus.SC_INTERNAL_SERVER_ERROR);
}
6.在工具类中定义doPost()方法通过HttpClient Post方式提交请求头和请求参数,从服务端返回状态码和json数据内容。
public static HttpClientResp doPost(String url, Map<String, String> headers, Map<String, String> params) throws Exception {
// 创建一个默认的HttpClient实例
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建一个HttpPost对象,并设置请求的URL
HttpPost httpPost = new HttpPost(url);
// 配置请求的超时时间
RequestConfig requestConfig = RequestConfig.custom()
.setConnectTimeout(CONNECT_TIMEOUT) // 设置连接超时时间
.setSocketTimeout(SOCKET_TIMEOUT) // 设置读取数据超时时间
.build();
httpPost.setConfig(requestConfig);
// 将请求头信息添加到HttpPost对象中
packageHeader(headers, httpPost);
// 将请求参数添加到HttpPost对象中
packageParam(params, httpPost);
CloseableHttpResponse httpResponse = null;
try {
// 执行HTTP请求并获取响应结果
return getHttpClientResult(httpResponse, httpClient, httpPost);
} finally {
// 确保在最终块中释放资源,避免资源泄漏
release(httpResponse, httpClient);
}
}
7.工具类中定义release ()方法用于释放httpclient(HTTP请求)对象资源和httpResponse(HTTP响应)对象资源
public static void release(CloseableHttpResponse httpResponse, CloseableHttpClient httpClient) throws IOException {
// 检查httpResponse是否为null,如果不是则关闭它以释放资源
if (httpResponse != null) {
httpResponse.close();
}
// 检查httpClient是否为null,如果不是则关闭它以释放资源
if (httpClient != null) {
httpClient.close();
}
}
(三)封装存储在HDFS的工具类
1.在pom.xml文件中添加Hadoop依赖,用于调用HDFS API
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
2.创建名为HttpClientHdfsUtils 工具类,实现通过HDFS存储数据
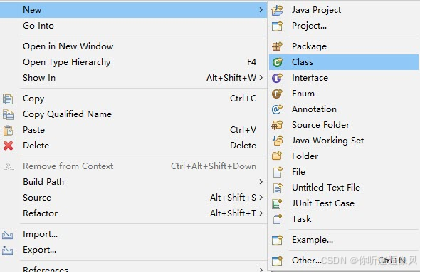
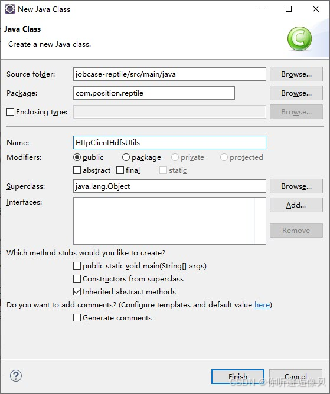
3.在HDFS工具类中定义createFileBySysTime()方法将采集的数据写入HDFS
public static void createFileBySysTime(String url, String fileName, String data) {
// 设置Hadoop用户为root
System.setProperty("HADOOP_USER_NAME", "root");
Path path = null; // 定义文件路径变量
Calendar calendar = Calendar.getInstance(); // 获取当前日期和时间的实例
Date time = calendar.getTime(); // 获取当前时间
SimpleDateFormat format = new SimpleDateFormat("yyyyMMdd"); // 定义日期格式
String filePath = format.format(time); // 将当前时间格式化为字符串
Configuration conf = new Configuration(); // 创建Hadoop配置对象
URI uri = URI.create(url); // 将URL字符串转换为URI对象
FileSystem fileSystem; // 定义文件系统对象
try {
// 获取指定URI的文件系统
fileSystem = FileSystem.get(uri, conf);
// 定义目标文件路径
path = new Path("/JobData/" + filePath);
// 如果目标路径不存在,则创建该目录
if (!fileSystem.exists(path)) {
fileSystem.mkdirs(path);
}
// 在目标路径下创建新文件并获取输出流
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path(path.toString() + "/" + fileName));
// 将数据写入到文件中
IOUtils.copyBytes(new ByteArrayInputStream(data.getBytes()), fsDataOutputStream, conf, true);
// 关闭文件系统
fileSystem.close();
} catch (IOException e) {
e.printStackTrace(); // 捕获并打印异常信息
}
}
4.在类的main()方法中再创建一个Map集合params,将请求参数放入集合中
// 创建一个HashMap来存储请求参数
Map<String, String> params = new HashMap<String, String>();
// 设置搜索关键词为"大数据"
params.put("kd", "大数据");
// 设置搜索城市范围为"全国"
params.put("city", "全国");
// 循环设置分页参数,从第1页到第30页
for (int i = 1; i < 31; i++) {
// 将当前页码转换为字符串并设置为参数"pn"的值
params.put("pn", String.valueOf(i));
}
5.在类的main()方法通过HttpClient的post请求实现数据的获取,并将数据保存到HDFS中
// 循环从第1页到第30页,发送POST请求并处理响应
for (int i = 1; i < 31; i++) {
// 设置当前页码为参数"pn"的值
params.put("pn", String.valueOf(i));
// 发送POST请求到指定的URL,并获取响应结果
HttpClientResp result = HttpClientUtils
.doPost("https://www.lagou.com/jobs/positionAjax.json?" +
"needAddtionalResult=false&first=true&px=default",
headers, params);
// 将响应结果保存到HDFS中,文件名为"page"加上当前页码
HttpClientHdfsUtils.createFileBySysTime("hdfs://hadoop01:9000",
"page" + i, result.toString());
// 线程休眠500毫秒,避免请求过于频繁
Thread.sleep(1 * 500);
}
(四)实现网页数据采集
1.通过浏览器进入开发者模式查看请求头的详细内容
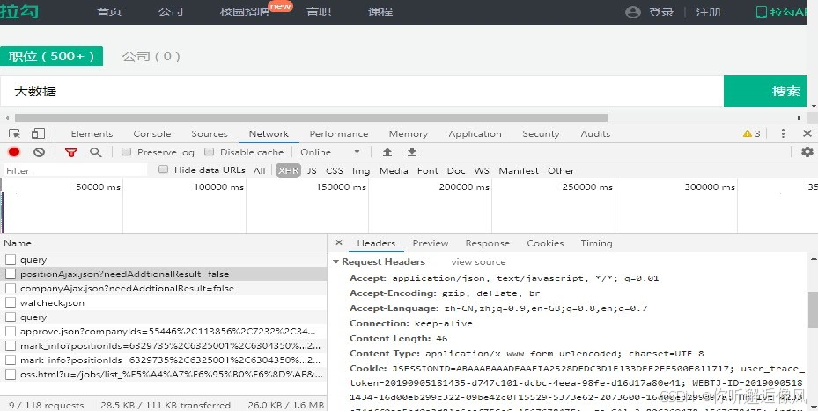
2.创建名为HttpClientData的主 类,用于实现数据采集功能。
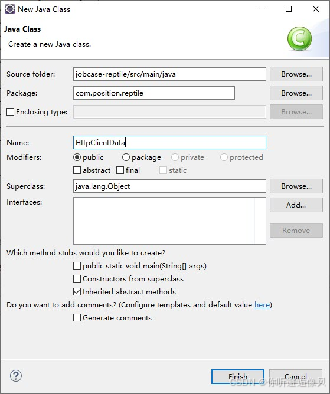
3.在类中创建main()方法,在main()方法中创建Map集合headers,将请求头参数放入集合中
// 创建一个HashMap来存储HTTP请求的头部信息
Map<String, String> headers = new HashMap<String, String>();
// 设置Cookie,通常通过登录获取,此处为空字符串表示未设置
headers.put("Cookie", ""); // Cookie通过登录的方式设置
// 保持连接活跃
headers.put("Connection", "keep-alive");
// 接受的数据类型,这里指定了JSON和JavaScript,以及通配符*
headers.put("Accept", "application/json, text/javascript, */*; q=0.01");
// 设置接受的语言,优先级从左到右递减
headers.put("Accept-Language", "zh-CN,zh;q=0.9,en-GB;q=0.8,en;q=0.7");
// 设置用户代理,模拟浏览器访问
headers.put("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) " +
"AppleWebKit/537.36 (KHTML, like Gecko) " +
"Chrome/75.0.3770.142 Safari/537.36");
// 设置内容类型为表单提交,编码为UTF-8
headers.put("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8");
// 设置Referer,表明请求来源页面
headers.put("Referer",
"https://www.lagou.com/jobs/list_%E5%A4%A7%E6%95%B0%E6%8D%AE?" +
"px=default&city=%E5%85%A8%E5%9B%BD");
// 设置请求的来源域
headers.put("Origin", "https://www.lagou.com");
// 设置X-Requested-With,用于标识Ajax请求
headers.put("X-Requested-With", "XMLHttpRequest");
// 设置反爬虫验证Token,此处为None表示未设置
headers.put("X-Anit-Forge-Token", "None");
// 设置缓存控制,no-cache表示不使用缓存
headers.put("Cache-Control", "no-cache");
// 设置反爬虫验证Code,此处为0表示未设置
headers.put("X-Anit-Forge-Code", "0");
// 设置请求的主机名
headers.put("Host", "www.lagou.com");
4.在Eclipse开发工具中运行主类文件HttpClientData.java,最终将采集的数据存储到HDFS 的/JobData/202210XX中,程序运行完成后在三台虚拟机中任意一台执行Shell指令“hdfs dfs -ls /JobData/202210XX”,均可查看最终采集的数据结果,需要注意的是hdfs上的创建目录名称是根据运行程序的时间而定,所以需根据个人运行程序的时间对指令中的目录进行修改,最终采集的数据结果。
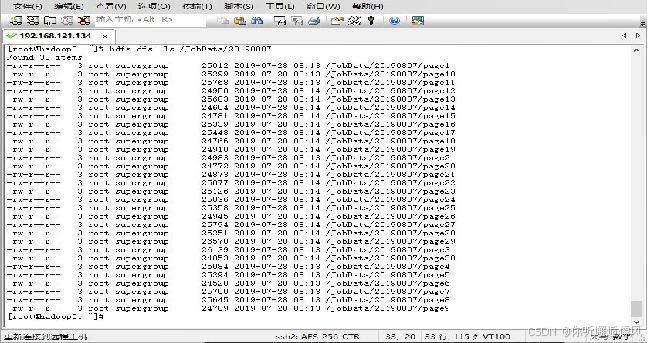
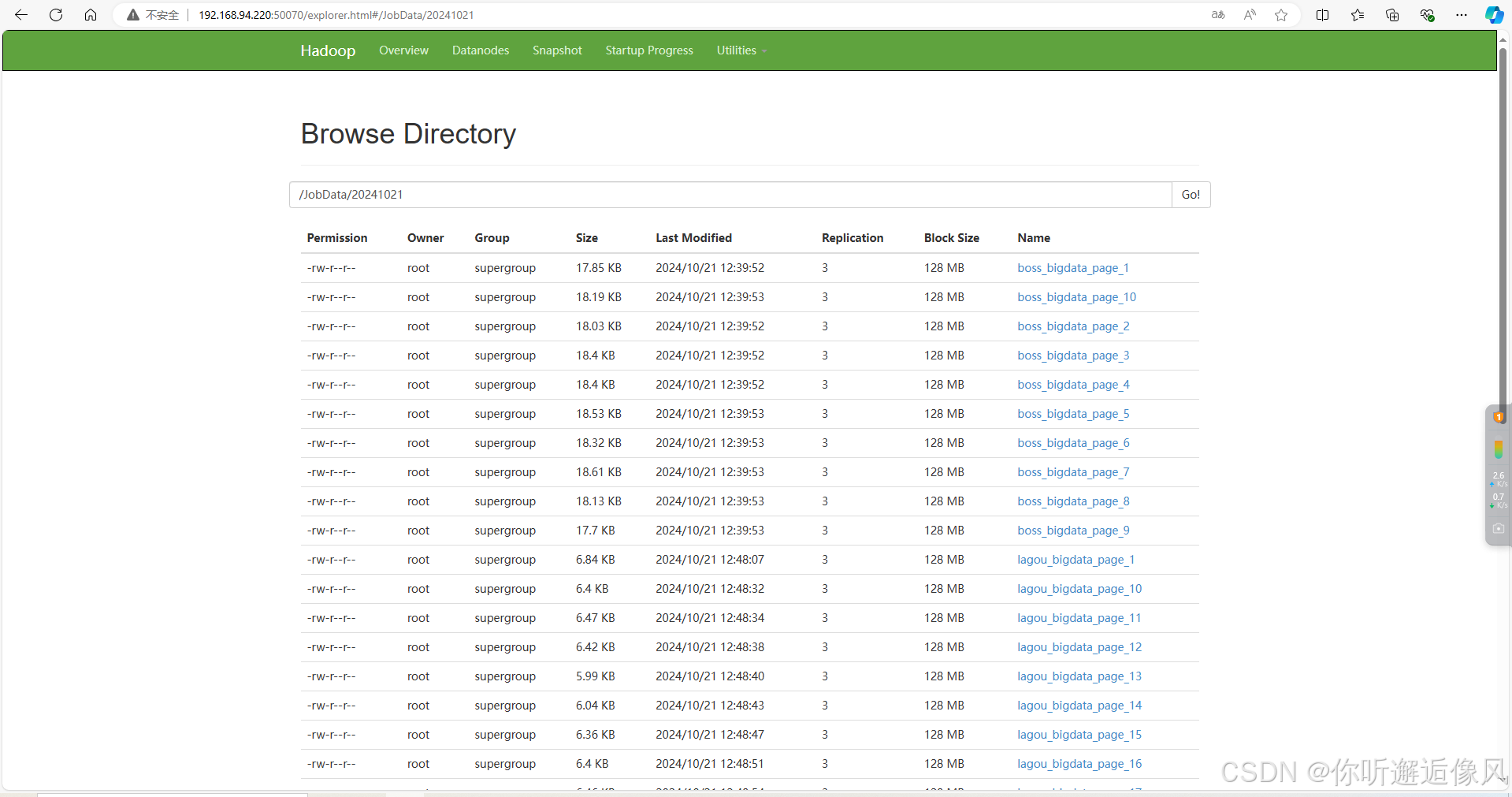
需要注意的是,在爬取数据的过程中,你需要将自己的hadoop启动起来,否则程序会报错,这样我们就获取到了数据,下回我们将对这些数据进行处理。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)