
【图像分类】影响网络模型的关键因素,以及对小样本检测各种主流的网络模型结果对比
目录1、理解学习率1.1一般选择:1.2增大和减小的缺点:1.3 caffe不同lr_policy参数设置方法2、理解batch_size【一阶SGD】2.1一般选择2.2 增大和减少的缺点:2.3 在合理的范围内增大batch_size的好处3、数据的对比目前已经获得的数据:数据分析1、理解学习率1.1一般选择:学习...
目录
1、理解学习率
1.1一般选择:
学习率可以设置为3、1、0.5、0.1、0.05、0.01、0.005,0.005、0.0001、0.00001具体需结合实际情况对比判断,小的学习率收敛慢,但能将loss值降到更低。
1.2增大和减小的缺点:
学习率越小,损失梯度下降的速度越慢,收敛的时间更长,如公式所示:(新权值 = 当前权值 – 学习率 × 梯度)。公式表达的意义如下图所示:
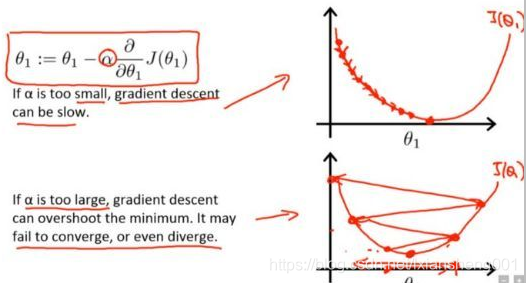
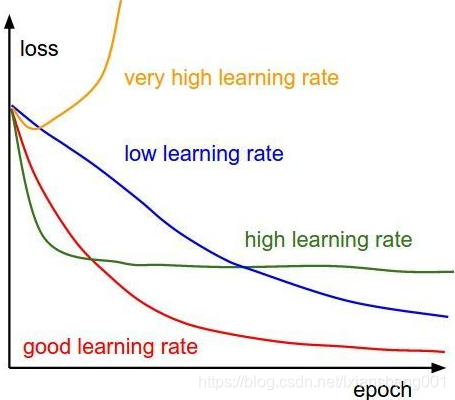
如果学习率过小,梯度下降很慢,如果学习率过大,如Andrew Ng的Stanford公开课程所说梯度下降的步子过大可能会跨过最优值。不同的学习率对loss的影响如下图所示:
1.3 caffe不同lr_policy参数设置方法
fixed:固定策略
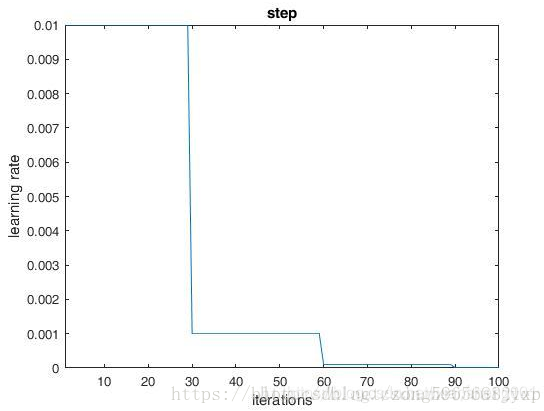
step :均匀分步策略。这个策略要结合参数stepsize使用,当循环次数达到stepsize的整数倍时lr=base_lr*gamma^(floor(iter/stepsize)).
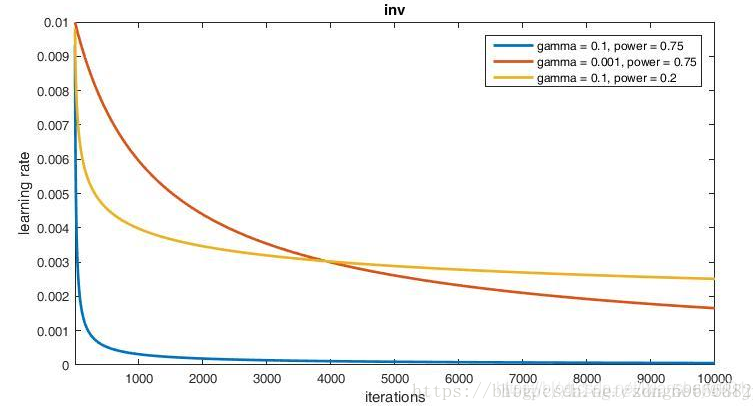
inv,这种学习策略的优势就在于它使得学习率在每一次迭代时都减小,但每次减小又都是一个非常小的数,这样就省去的自己手动调节的麻烦。这种策略使用的也很普遍。
multistep 多分步或不均匀分步。这种学习策略和step策略很相似。这种学习策略需要配合参数stepvalue使用,stepvalue可以在文件中设置多个,如stepvalue=10000,stepvalue=20000,......,当迭代次数达到我们依次指定的stepvalue的值时,学习率就会根据公式重新计算。
2、理解batch_size【一阶SGD】
2.1一般选择
我们训练的时候根据输入图像的尺寸不同,CPU版本batch_size在20到64之间。加上GPU可能达到256以上,例如设置2和32区别在于,每次迭代处理多少张,如果是2张那么迭代速度会很快,loss函数输出到显示器上也更快。若32则本次迭代需要处理32张数据,那么loss结果输出到显示器上就会比2慢很多。
2.2 增大和减少的缺点:
Batch_Size既然 Full Batch Learning 并不适用大数据集SGD 算法的 batch size 并不能无限制地增大。SGD 采用较大的 batch size 时,如果还是使用同样的 epochs 数量进行运算,则准确度往往低于 batch size 较小的场景 ; 而且目前还不存在特定算法方案能够帮助我们高效利用较大的 batch size。泛化性不好
每次只训练一个样本,即 Batch_Size = 1。这就是在线学习(Online Learning)。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。使用在线学习,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
2.3 在合理的范围内增大batch_size的好处
- 内存利用率提高了,大矩阵乘法的并行化效率提高。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
- 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。"
“随着 Batch_Size 增大,处理相同数据量的速度越快。但随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。” 由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
所以在小batch size时,逐渐减少learning rate的神经网络玩的就是退火算法。不同的batch size不仅仅会影响你的收敛速度,还经常影响你最终收敛时的准确率。
二阶导数一般要增大batch_size
参考链接:https://blog.csdn.net/wydbyxr/article/details/84855489
3、数据的对比
目前已经获得的数据:
- CaffeNet网络--【batch_size(train以下都是):32】--1400次迭代Loss变化和Accuracy变化
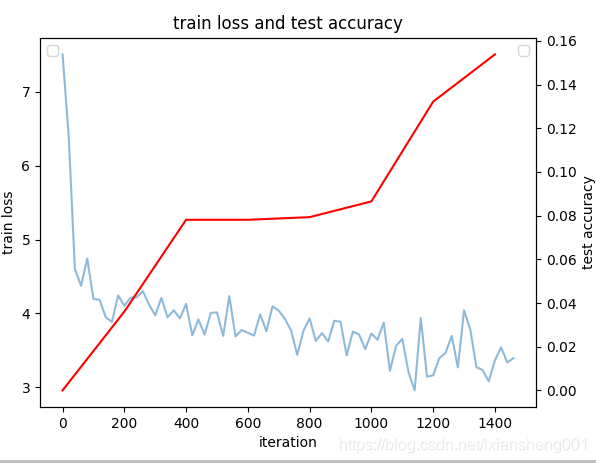
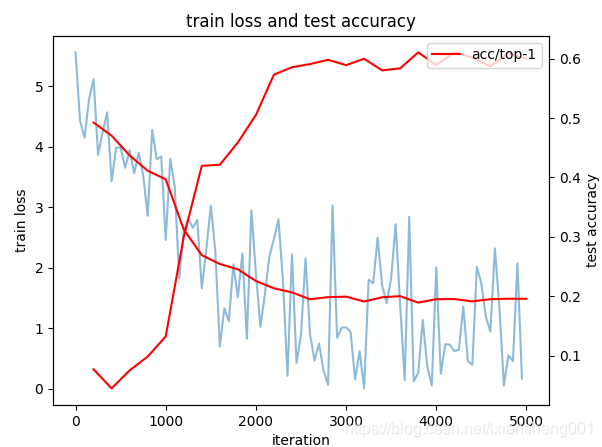
- ResNet网络-以训练好的caffemodel模型作为权值--【batch:3】5000次迭代Loss和accuracy数据变化:如下图所示;
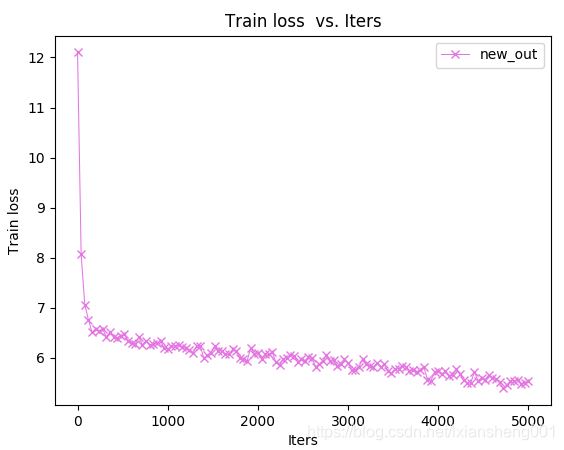
- GoogleNet网络-【batch:8】-迭代5000次数据变化图为:
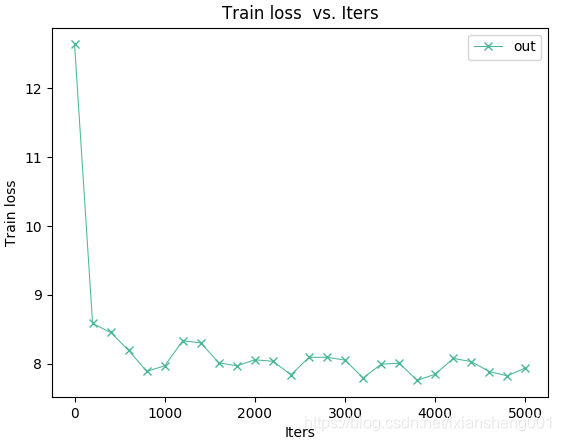
- GoogleNet网络-【batch:2】【262】-迭代5000次数据变化图为:
数据分析
根据以上数据和知识点可以看出:
- 1、batch_size对整个模型有较大的影响,应该选取较大保证每次迭代学习的泛化性,如果设置的太小则导致不能收敛(每次学一个会形成各自为政情况)
- 2、同时对比GoogleNet和caffeNet数据结果可以看出,对于小样本来说模型简单更好一些。这里猜测可能是模型越深越需要大样本去学习特征
- 3、对比GoogleNet两种情况数据(全部样本和抽取49类较大样本),我们可以看到变化还是较大的,对于top5分类精准度两者数据为28%(49类):10%(全部类);从这方面对非均匀样本导致结果变差有了一定的依据。
- 4、最后可以看出ResNet有着较高的表现,但是从Loss函数震荡数据可以分析出可能是由于batch_size设置的太小导致出现了前面说的结果:每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。所以针对合适的数据集选择合适的模型是很重要的,下一部分我会讲一下ResNet的原理。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)