
神经网络训练算法
1. 传统优化问题大多数深度学习算法都涉及某种形式的优化。优化指的是改变 xxx 以最小化或最大化某个函数 f(x)f(x)f(x) 的任务。通常以最小化 f(x)f(x)f(x) 指代大多数最优化问题。最大化可经由最小化算法最小化 −f(x)- f(x)−f(x) 来实现。通常,把要最小化或最大化的函数 f(x)f(x)f(x) 称为 目标函数(objective function)、代价函数(
1. 传统优化问题
大多数深度学习算法都涉及某种形式的优化。优化指的是改变 xxx 以最小化或最大化某个函数 f(x)f(x)f(x) 的任务。通常以最小化 f(x)f(x)f(x) 指代大多数最优化问题。最大化可经由最小化算法最小化 −f(x)- f(x)−f(x) 来实现。
通常,把要最小化或最大化的函数 f(x)f(x)f(x) 称为 目标函数(objective function)、代价函数(cost function)、损失函数(loss function)或误差函数(error function)。
1.1 一维函数
对一维函数 y=f(x)y=f(x)y=f(x),其导数 f′(x)=dydx\displaystyle f'(x)=\frac{dy}{dx}f′(x)=dxdy代表 f(x)f(x)f(x) 在点 xxx 处的斜率,导数展示了输入的小变化对函数目标值的影响,
即: f(x+ϵ)≈f(x)+ϵ⋅f′(x)\displaystyle f(x+\epsilon)\approx f(x)+\epsilon\cdot f'(x)f(x+ϵ)≈f(x)+ϵ⋅f′(x),这告诉我们如何调整 xxx 来改善目标函数 yyy。
当 ϵ\epsilonϵ 足够小时,若 f(x−ϵ⋅sign(f′(x)))<f(x)\displaystyle f(x-\epsilon\cdot sign(f'(x))) <f(x)f(x−ϵ⋅sign(f′(x)))<f(x) ,则可以将 x 往导数的反方向移动一小步来减小 f(x)f(x)f(x) 。这就是梯度下降的内涵。
1.2 多维函数
对多维输入的函数 f:Rn→R\displaystyle f:\mathbf R^n\to\mathbf Rf:Rn→R,其偏导数 ∂f(x)∂xi\displaystyle \frac{\partial f(\mathbf x)}{\partial x_i}∂xi∂f(x) 衡量点 x\mathbf xx 出只有 xix_ixi 增加时 f(x)f(\mathbf x)f(x) 如何变化。记 f(x)f(\mathbf x)f(x) 的梯度为 ∇xf(x)\displaystyle \nabla_\mathbf x f(\mathbf x)∇xf(x),它是包含所有偏导数的向量 (∂f(x)∂x1,∂f(x)∂x2,⋯ ,∂f(x)∂xi,⋯ ,∂f(x)∂xn)\displaystyle (\frac{\partial f(\mathbf x)}{\partial x_1},\frac{\partial f(\mathbf x)}{\partial x_2},\cdots,\frac{\partial f(\mathbf x)}{\partial x_i},\cdots,\frac{\partial f(\mathbf x)}{\partial x_n})(∂x1∂f(x),∂x2∂f(x),⋯,∂xi∂f(x),⋯,∂xn∂f(x))。
梯度向量指向上爬坡,函数增大;负梯度向量指向下爬坡,函数减小。故在负梯度方向上移动可以减小 fff,
则可将函数点更新为: x′=x−ϵ⋅∇xf(x)\mathbf x'=\mathbf x-\epsilon\cdot\nabla_\mathbf x f(\mathbf x)x′=x−ϵ⋅∇xf(x)。
这是多维函数的梯度下降(gradient descent),也被称为最速下降法(method of steepest descent)。
1.3 Jacobian 和 Hessian 矩阵
当一个函数的输入和输出都为向量时,其所有的偏导数的矩阵被称为 Jacobian矩阵。假设函数 f:Rn→Rm\displaystyle f:\mathbf R^n\to\mathbf R^mf:Rn→Rm,则其Jacobian矩阵是一个 m×nm\times nm×n的矩阵,可描述为: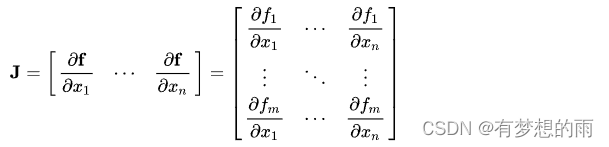
其中,矩阵分量可表示为 Jij=∂fi∂xj\displaystyle J_{ij}=\frac{\partial f_i}{\partial x_j}Jij=∂xj∂fi。
而函数的 二阶导数 不止一个,其合并成的矩阵被称为Hessian 矩阵,它告诉我们,一阶导数将如何随着输入的变化而改变。它表示只基于梯度信息的梯度下降步骤是否会产生如我们预期的那样大的改善。Hessian 矩阵可描述为: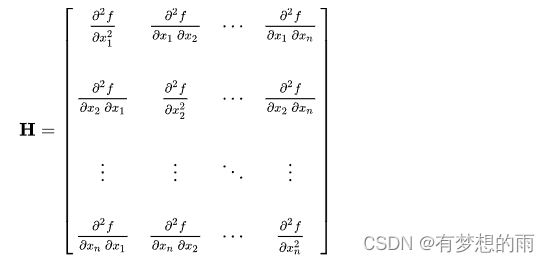
其中,矩阵分量可表示为 Hij=∂2f∂xi∂xj\displaystyle H_{ij}=\frac{\partial^2 f}{\partial x_i \partial x_j}Hij=∂xi∂xj∂2f。
仅使用梯度信息的优化算法被称为一阶优化算法 (first-order optimization algorithms),如梯度下降;使用 Hessian 矩阵的优化算法被称为二阶最优化算法(second-order optimization algorithms),如牛顿法。
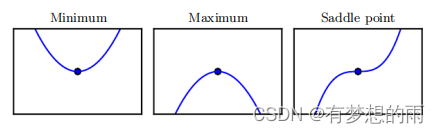
对函数而言,当 f′(x)=0f'(x)=0f′(x)=0 时,即达到驻点(全局极小点、全局极大点、局部极小点、局部极大点或鞍点),如下图所示。
1.4 牛顿法
1.4.1一维函数
对于一个需要求解的优化函数 f(x)f(x)f(x), 求函数的极值的问题可以转化为求导函数 f′(x)=0f'(x)=0f′(x)=0。
1.4.2 多维函数
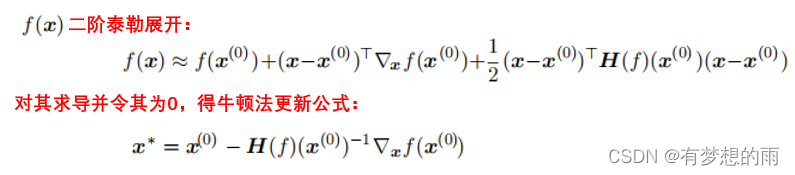
若用损失函数 J(θ)J(\theta)J(θ),则为:
其算法如下:
牛顿法用于训练大型神经网络受限于其显著的计算负担。Hessian 矩阵中元素数目是参数数量的平方,因此,如果参数数目为 kkk(甚至是在非常小的神经网络中 k 也可能是百万级别),牛顿法需要计算 k×kk\times kk×k 矩阵的逆,计算复杂度为 O(k3)O(k^3)O(k3)。另外,由于参数将每次更新都会改变,每次训练迭代都需要计算Hessian 矩阵的逆。因此,只有参数很少的网络才能在实际中用牛顿法训练。
1.4.3 全局牛顿法
牛顿法最突出的优点是收敛速度快,具有局部二阶收敛性,但是,基本牛顿法的初始点需要足够“靠近”极小点,否则,有可能导致算法不收敛。这样就引入了全局牛顿法。
但在机器学习的背景下,我们要优化的函数可能含有许多不是最优的局部极小点,或者还有很多处于非常平坦的区域内的鞍点,尤其是当输入是多维的时候。这使得优化变得很困难。
2. 深度学习优化算法和传统优化的差异
用于深度模型训练的优化算法与传统的优化算法在几个方面有所不同。机器学习通常是间接作用的。在大多数机器学习问题中,我们关注某些性能度量 P,其定义于测试集上并且可能是不可解的。因此,机器学习只是间接地优化 P。我们希望通过降低代价函数 J(θ)J(θ)J(θ) 来提高 P。这一点与纯优化不同,纯优化最小化目标 P 本身。
2.1 经验风险最小化
通常,代价函数可写为训练集上的平均,即: J(θ)=E(x,y)∼p^dataL(f(x;θ),y)\displaystyle J(\theta)=\mathit E_{(\mathbf x,\mathbf y)\sim\hat{p}_{data}}L(f(\mathbf x;\mathbf\theta),y)J(θ)=E(x,y)∼p^dataL(f(x;θ),y),
其中,LLL 是每个样本的损失函数,f(x;θ)f(\mathbf x;\mathbf\theta)f(x;θ) 输入 x\mathbf xx 时的预测输出,p^data\hat{p}_{data}p^data 是经验分布,θ\thetaθ 是模型参数,yyy 是目标输出。
实际上,跟希望最小化取自 数据本身的分布 pdata{p}_{data}pdata 的期望,而不仅仅是有限训练集上的对应目标函数,
即: J∗(θ)=E(x,y)∼pdataL(f(x;θ),y)\displaystyle J^*(\theta)=\mathit E_{(\mathbf x,\mathbf y)\sim{p}_{data}}L(f(\mathbf x;\mathbf\theta),y)J∗(θ)=E(x,y)∼pdataL(f(x;θ),y)。
而经常使用训练集上的经验分布 p^data\hat{p}_{data}p^data 代替真实分布 pdata{p}_{data}pdata ,这就是 经验风险最小化(empirical risk minimization),即基于最小化平均训练误差。通过最优化经验风险,来达到降低实际风险。但是,经验风险最小化很容易导致过拟合。
2.2 代理损失函数
当损失函数(比如分类误差)不能被高效优化时,通常会优化代理损失函数(surrogate loss function)。代理损失函数作为原目标的代理,还具备一些优点。在某些情况下,代理损失函数比原函数学到的更多。
例如,使用对数似然替代目标函数时,在训练集上的 0-1 损失达到 0 之后,测试集上的 0-1 损失还能持续下降很长一段时间。这是因为即使 0-1 损失期望是零时,我们还能拉开不同类别的距离以改进分类器的鲁棒性,获得一个更强壮的、更值得信赖的分类器,从而,相对于简单地最小化训练集上的平均 0-1 损失,它能够从训练数据中抽更多信息。
2.3 提前终止
传统优化和我们用于训练算法的优化有一个重要不同,训练算法通常不会停止在局部极小点。反之,机器学习通常优化surrogate loss function,当满足设置好的提前终止的收敛条件时停止(防止过拟合)。与纯优化不同的是,提前终止时surrogate loss function仍然有较大的导数,而纯优化终止时导数较小。
2.4 随机(小批量算法)
机器学习算法的目标函数通常可以分解为训练样本上的求和。机器学习中的优化算法在计算参数的每一次更新时,通常仅使用整个数据集中一部分来估计损失函数的期望值。
使用整个训练集的优化算法被称为批量或确定性(deterministic)梯度算法,因为它们会在一个大批量中同时处理所有样本。每次只使用单个样本的优化算法有时被称为随机(stochastic)或者 在线(online)算法。大多数用于深度学习的算法介于以上两者之间,使用一个以上,而又不是全部的训练样本。
2.4.1 小批量算法的大小决定因素
(1)更大的批量会计算更精确的梯度估计,但是回报却是小于线性的。
(2)极小批量通常难以充分利用多核架构,这使得出现了绝对最小批量(absolute minimum batch size),低于这个值的小批量处理不会减少计算时间。
(3)如果批量处理中的所有样本可以并行地处理,那么内存消耗和批量大小会正比。
(4)在某些硬件上使用特定大小的数组时,运行时间会更少。尤其是在使用GPU 时,通常使用 2 的幂数作为批量大小可以获得更少的运行时间。一般,2 的幂数的取值范围是 32 到 256,16 有时在尝试大模型时使用。
(5)可能是由于小批量在学习过程中相当于加入了噪声,它们会有一些正则化效果 。泛化误差通常在批量大小为 1 时最好。因为梯度估计的高方差,小批量训练需要较小的学习率以保持稳定性。但因为低的学习率和每个批量的计算都会产生更多的步骤,会导致总的运行时间变大。
3. 基本算法
3.1 随机梯度下降(Stochastic gradient descent,SGD)

SGD 算法中的一个关键参数是学习率 ϵ\epsilonϵ。SGD 中梯度估计中是引入噪声了的(来自于m 个训练样本的随机采样),并且不会在极小点处消失。相比之下,当使用批量梯度下降到达极小点时,整个损失函数的真实梯度会变得很小,之后为 0,因此批量梯度下降可以使用固定的学习率。
在具体的训练过程中,有必要随着时间的推移逐渐降低学习率,记第 k 步迭代的学习率记作 ϵk\epsilon_kϵk。实践中,一般会线性衰减学习率直到第 τ\tauτ 次迭代: ϵk=(1−α)⋅ϵ0+α⋅ϵτ\displaystyle \epsilon_k=(1-\alpha)\cdot\epsilon_0+\alpha\cdot \epsilon_{\tau}ϵk=(1−α)⋅ϵ0+α⋅ϵτ,
其中,α=kτ\displaystyle\alpha=\frac{k}{\tau}α=τk,即在 τ\tauτ 步之后,保持 ϵ\epsilonϵ 为常数。
3.2 动量法(momentum)
SGD学习过程有时会很慢。动量方法 旨在加速学习,特别是处理高曲率、小但一致的梯度,或是带噪声的梯度。动量算法积累了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。其效果图如下: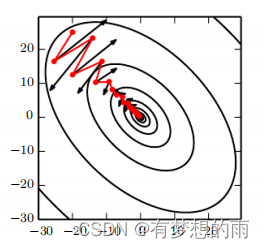
动量法引入了变量 vvv 充当速度角色——它代表参数在参数空间
移动的方向和速率。超参数 α∈[0,1)\alpha\in[0,1)α∈[0,1) 决定了之前梯度的贡献衰减的快慢。其参数更新规则为: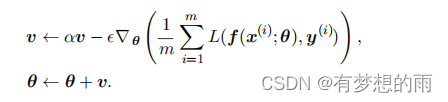
其中,速度 vvv 累积了梯度和之前梯度的影响,相较于学习率 ϵ\epsilonϵ,α\alphaα 越大,之前梯度对现在方向的影响就越大。带动量的SGD算法如下:

步长只是梯度范数乘以学习率。现在,步长取决于梯度序列的大小和排列。当许多连续的梯度指向相同的方向时,步长最大。如果动量算法总是观测到梯度 g,那么它会在方向 −g-g−g 上不停加速,直到达到最终速度,其中步长为:ϵ⋅∣∣g∣∣1−α\displaystyle \frac{\epsilon\cdot||g||}{1-\alpha}1−αϵ⋅∣∣g∣∣。
可将动量法的超参数 ϵ\epsilonϵ 视为 11−α\displaystyle \frac{1}{1-\alpha}1−α1。如,α = 0.9 对应着最大速度 10 倍于梯度下降算法。和学习率一样,α\alphaα 也会随着时间不断调整,一般初始值是一个较小的值,随后会慢慢变大。随着训练的推进,在后期收缩 ϵ\epsilonϵ 要比调整 α\alphaα 重要。
3.3 Nesterov 动量
Nesterov 动量是动量法的一个变种,其更新规则如下: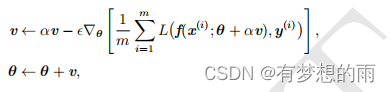
其中参数 α\alphaα 和 ϵ\epsilonϵ 发挥了和标准动量方法中类似的作用。Nesterov 动量和标准动量之间的区别体现在梯度计算上。Nesterov 动量中,梯度计算在施加当前速度之后。因此,Nesterov 动量可以解释为往标准动量方法中添加了一个 校正因子。其算法如下:
4. 自适应学习率算法
学习率对模型的性能有显著的影响,是难以设置的超参数之一。损失函数通常高度敏感于参数空间中的某些方向,而不敏感于其他。动量算法可以在一定程度缓解这些问题,但这样做的代价是引入了另一个超参数。因此,在学习过程中自动适应学习率是有必要的。
4.1 AdaGrad 算法
AdaGrad 算法独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平方值总和的平方根。具有损失最大偏导的参数相应地有一个快速下降的学习率,而具有小偏导的参数在学习率上有相对较小的下降。其效果是在参数空间中更为平缓的倾斜方向会取得更大的进步。其算法如下:
凸优化情况下,AdaGrad 算法具有一些令人满意的理论性质。对于训练深度神经网络模型而言,从训练开始时积累梯度平方会导致有效学习率过早和过量的减小。AdaGrad 在某些深度学习模型上效果不错,但不是全部都好。
4.2 RMSProp
RMSProp 算法是对 AdaGrad 进行修改以在非凸设定下效果更好,改变梯度积累为指数加权的移动平均。
AdaGrad 旨在应用于凸问题时快速收敛。当应用于非凸函数训练神经网络时,学习轨迹可能穿过了很多不同的结构,最终到达一个局部是凸碗的区域。AdaGrad 根据平方梯度的整个历史收缩学习率,这有可能导致学习率在达到这样的凸结构前就变得太小了。RMSProp 使用指数衰减平均以丢弃遥远过去的历史,使其能够在找到凸碗状结构后快速收敛,它就像一个初始化于该碗状结构。
相比于 AdaGrad,使用移动平均引入了一个新的超参数 ρ\rhoρ,用来控制移动平均的长度范围。其算法如下:
4.3 Adam
Adam被视为结合 RMSProp 和具有一些重要区别的动量的变种。首先,在 Adam 中,动量直接并入了梯度一阶矩(指数加权)的估计。将动量加入 RMSProp 最直观的方法是将动量应用于缩放后的梯度。其次,Adam 包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩的估计。RMSProp 也采用了(非中心的)二阶矩估计,但是没有修正因子。其算法如下所示:

5 二阶优化方法
5.1 牛顿法
见 1.4节所示
5.2 共轭梯度法
共轭梯度是一种通过迭代下降的 共轭方向(conjugate directions) 以有效避免 Hessian 矩阵求逆计算的方法。
多维情况下,单个点处每个方向上的二阶导数是不同。Hessian 的条件数衡量这些二阶导数的变化范围。当 Hessian 的条件数很差时,梯度下降法也会表现得很差。这是因为一个方向上的导数增加得很快,而在另一个方向上增加得很慢。梯度下降不知道导数的这种变化,所以它不知道应该优先探索导数长期为负的方向。病态条件也导致很难选择合适的步长。步长必须足够小,以免冲过最小而向具有较强正曲率的方向上升。这通常意味着步长太小,以致于在其他较小曲率的方向上进展不明显。如下图左所示。
而共轭梯度的每一个由梯度给定的线性搜索方向,都保证正交于上一个线性搜索方向。假设上一个搜索方向是 dt−1\mathbf d_{t-1}dt−1。在极小值处,线性搜索终止,方向 dt−1\mathbf d_{t-1}dt−1 处的方向导数为零:∇θJ(θ)⋅dt−1=0\displaystyle \nabla_{\theta}J(\theta)\cdot \mathbf d_{t-1}=0∇θJ(θ)⋅dt−1=0。因为该点的梯度定义了当前的搜索方向,而 dt=∇θJ(θ)\displaystyle \mathbf d_t=\nabla_{\theta}J(\theta)dt=∇θJ(θ) 不会贡献于方向dt−1\mathbf d_{t-1}dt−1。因此方向 dt\mathbf d_{t}dt 正交于 dt−1\mathbf d_{t-1}dt−1。
如下图右所示,下降正交方向的选择不会保持前一搜索方向上的最小值。因此,在当前梯度方向下降到极小值时,必须重新最小化之前梯度方向上的目标。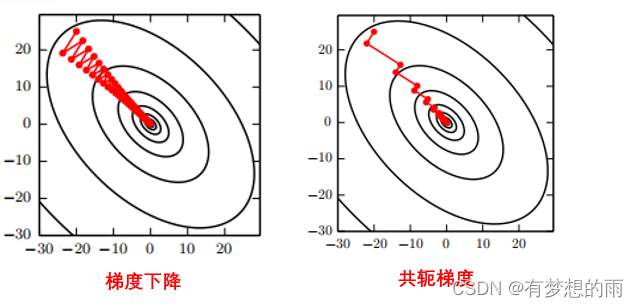
在共轭梯度法中,寻求一个和先前线性搜索方向共轭(conjugate)的搜索方向,即它不会撤销该方向上的进展。在训练迭代 ttt 时,下一步的搜索方向 dt\mathbf d_tdt 的形式为:dt=∇θJ(θ)+βt⋅dt−1\displaystyle \mathbf d_t=\nabla_{\theta}J(\theta)+\beta_t\cdot \mathbf d_{t-1}dt=∇θJ(θ)+βt⋅dt−1,
其中,系数 βt\beta_tβt 的大小控制我们应沿方向 dt−1\mathbf d_{t-1}dt−1 加回多少到当前搜索方向上。
若 dtTHdt−1=0\mathbf d^T_{t}H\mathbf d_{t-1}=0dtTHdt−1=0,(H 是 Hessian 矩阵),则两个方向 dt\mathbf d_{t}dt 和 dt−1\mathbf d_{t-1}dt−1 是共轭的。而适应共轭的直接计算方法会涉及到 H 特征向量的计算,用以选择 βt\beta_tβt 。共轭梯度法提供了不计算 Hessian矩阵也能计算 βt\beta_tβt 的方法,如下:
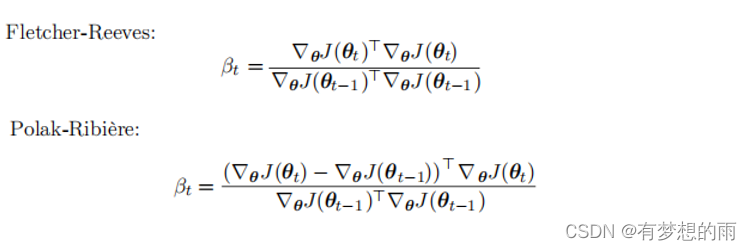
对于二次曲面而言,共轭方向确保梯度沿着前一方向大小不变。因此,在前一方向上仍然是极小值。而在 k-维参数空间中,共轭梯度只需要至多 k 次线性搜索就能达到极小值。共轭梯度算法如下所示:

6.其他优化方法
除上述方法外,还有启发式算法也可用于神经网络的训练,如蚁群算法、粒子群算法、模拟退火算法等。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)