
【AI概念】卷积神经网络(CNN)vs. 循环神经网络(RNN)vs. Transformer详解(附详尽Python代码演示)| 定义与原理、数学公式、案例与代码可视化、结构对比与优缺点
大家好,我是爱酱。本篇將會系统梳理卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network, RNN)和Transformer三大深度学习架构的原理、结构、优势、典型应用与数学表达。内容非常详细,并有友善的代码解释、流程解析等,适合初学者和进阶者系统理解。注:本文章含大量数学算式、详细例子说明及大量代码演示,
大家好,我是爱酱。本篇將會系统梳理卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network, RNN)和Transformer三大深度学习架构的原理、结构、优势、典型应用与数学表达。内容非常详细,并有友善的代码解释、流程解析等,适合初学者和进阶者系统理解。
注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
注:本文章颇长近10000字,建议先收藏再慢慢观看。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、卷积神经网络(Convolutional Neural Network, CNN)

1. 定义与核心思想
卷积神经网络(CNN)是一类专为处理具有网格结构(如图像、音频)的数据而设计的前馈神经网络。CNN通过局部感受野、权值共享和池化等机制,能够自动提取空间局部特征,实现平移不变性和高效的特征学习。
-
英文专有名词:Convolutional Neural Network, CNN, Convolution, Pooling, Feature Map, ReLU
2. 结构组成
-
卷积层(Convolutional Layer):用可学习的卷积核(filter)在输入上滑动,实现特征提取。
-
激活函数(Activation Function):常用ReLU,增加非线性。
-
池化层(Pooling Layer):如最大池化(max pooling)、平均池化(average pooling),用于降采样和特征压缩。
-
全连接层(Fully Connected Layer):将提取的特征映射到最终输出,如分类概率。
3. 数学公式
单通道二维卷积计算公式:
其中为输入,
为卷积核,
为偏置。
4. 主要优势
-
局部连接和权值共享极大减少参数数量,提升泛化能力。
-
自动学习多层次空间特征,无需手工设计特征。
-
对图像的平移、缩放等具有较强的鲁棒性。
5. 典型应用
-
图像分类、目标检测、医学图像分析、视频识别、推荐系统、文本分类等。
二、循环神经网络(Recurrent Neural Network, RNN)

1. 定义与核心思想
循环神经网络(RNN)是一类专门处理序列数据(sequence data)的神经网络。RNN通过隐藏状态的循环连接,使得网络能够“记忆”历史信息,建模时间或序列上的依赖关系。
-
英文专有名词:Recurrent Neural Network, RNN, Hidden State, Sequence, Time Step, Backpropagation Through Time (BPTT)
2. 结构组成
-
输入层(Input Layer):接收序列的每个元素。
-
隐藏层(Hidden Layer):每个时刻
的隐藏状态
不仅依赖当前输入
,还依赖前一时刻的隐藏状态
。
-
输出层(Output Layer):输出序列的每个元素或最终结果。
3. 数学公式
RNN的基本递推公式:
其中、
为激活函数,
、
、
为权重矩阵。
4. 主要优势
-
能捕捉序列数据中的时序依赖关系,适合处理变长输入。
-
适用于自然语言、语音、时间序列等任务。
5. 典型应用
-
机器翻译、文本生成、语音识别、时间序列预测、情感分析等。
三、Transformer

1. 定义与核心思想
Transformer是一种基于自注意力机制(Self-Attention)的深度学习模型架构,最初由Vaswani等人在2017年提出,彻底改变了序列建模和自然语言处理(NLP)领域。Transformer通过自注意力机制捕捉序列中任意位置的依赖关系,摆脱了传统RNN对序列顺序的强依赖,实现了高效并行和更强的长距离依赖建模。
-
英文专有名词:Transformer, Self-Attention, Multi-Head Attention, Positional Encoding
-
核心思想:用自注意力机制(Self-Attention)为序列中每个位置动态分配对其它位置的关注权重,支持并行计算和全局建模。
2. 结构组成
Transformer主要由编码器(Encoder)和解码器(Decoder)两部分组成,每部分由多个相同的层堆叠而成。
-
编码器层:包含多头自注意力(Multi-Head Self-Attention)和前馈神经网络(Feed-Forward Network),每个子层后有残差连接和层归一化(Layer Normalization)。
-
解码器层:在编码器结构基础上,增加对编码器输出的注意力机制(Encoder-Decoder Attention),用于结合输入序列信息。
3. 数学表达
-
自注意力机制(Self-Attention):
给定输入序列的查询(Query)
,键(Key)
,值(Value)
,自注意力输出为:
其中,
是键的维度,用于缩放。
-
多头注意力(Multi-Head Attention):
其中每个头为:
为可学习参数矩阵。
-
前馈网络(Feed-Forward Network):
4. 主要优势
-
并行计算:不依赖序列顺序,支持GPU并行加速。
-
长距离依赖建模:自注意力机制能捕捉任意位置的依赖关系,突破RNN的“短记忆”问题。
-
灵活性强:广泛应用于NLP、计算机视觉、语音等多模态任务。
5. 典型应用
-
机器翻译(如Google翻译)、文本生成(GPT系列)、文本理解(BERT系列)
-
图像识别(Vision Transformer, ViT)
-
语音识别与合成
四、CNN、RNN与Transformer的结构对比与优缺点
| 维度 | 卷积神经网络(CNN) | 循环神经网络(RNN) | Transformer |
|---|---|---|---|
| 主要结构 | 卷积层、池化层、全连接层 | 循环隐藏层、时间步递归 | 编码器-解码器结构,多头自注意力机制 |
| 处理数据类型 | 网格结构数据(图像、音频) | 序列数据(文本、语音、时间序列) | 序列数据,支持并行处理 |
| 计算效率 | 高,支持并行 | 低,序列依赖,难并行 | 高,完全并行,适合大规模训练 |
| 长距离依赖建模 | 有限,感受野限制 | 有限,梯度消失问题 | 优秀,自注意力捕捉任意距离依赖 |
| 参数共享 | 卷积核权重共享 | 时间步权重共享 | 无权重共享,注意力权重动态计算 |
| 优点 | 参数少,适合图像特征提取 | 适合序列建模,捕捉时间依赖 | 并行高效,长距离依赖,灵活性强 |
| 缺点 | 不适合长序列依赖 | 训练难,梯度消失,计算慢 | 计算资源需求高,模型复杂 |
| 典型应用 | 图像分类、目标检测、语音识别 | 机器翻译、语音识别、文本生成 | 机器翻译、文本理解、图像识别 |
五、典型应用案例与可视化示例
1. 卷积神经网络(CNN)
-
应用案例:图像分类(如CIFAR-10、ImageNet)
-
可视化示例:卷积层特征图(Feature Maps)
注:请大家记得先
pip install tensorflow scikit-learn matplotlib等依赖!注:请一定要把路径换为您自己图片的路径。用什么图片不重要,爱酱这里就换上一张猫猫的图片(cat.jpg)。你可以选择任何图片。
注:第一次的时候可能会要先下载一下Dataset,需要等待一下。
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input, decode_predictions
from tensorflow.keras.models import Model
# 用原始字符串写法,避免Windows路径转义问题
img_path = r'D:\XXX\XXX\cat.jpg' # 替换为你的图片路径
# 加载预训练VGG16模型(去掉顶层全连接层)
model = VGG16(weights='imagenet', include_top=False)
# 加载并预处理图片
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# 获取所有卷积层的输出
layer_outputs = [layer.output for layer in model.layers if 'conv' in layer.name]
activation_model = Model(inputs=model.input, outputs=layer_outputs)
# 预测所有卷积层的激活
activations = activation_model.predict(x)
# 可视化第一卷积层的前16个特征图
first_layer_activation = activations[0] # 取第一个卷积层输出,shape: (1, height, width, channels)
plt.figure(figsize=(15, 15))
for i in range(16):
plt.subplot(4, 4, i+1)
plt.imshow(first_layer_activation[0, :, :, i], cmap='viridis')
plt.axis('off')
plt.suptitle('CNN Feature Maps (First Conv Layer)')
plt.show()
# 加载完整模型用于分类预测
full_model = VGG16(weights='imagenet', include_top=True)
# 重新预处理图片用于完整模型
img_for_pred = image.load_img(img_path, target_size=(224, 224))
x_pred = image.img_to_array(img_for_pred)
x_pred = np.expand_dims(x_pred, axis=0)
x_pred = preprocess_input(x_pred)
# 预测分类结果
preds = full_model.predict(x_pred)
# 解码预测结果
decoded_preds = decode_predictions(preds, top=3)[0]
# 打印预测结果
print("Top 3 Predictions:")
for i, (imagenet_id, label, prob) in enumerate(decoded_preds):
print(f"{i+1}. {label}: {prob*100:.2f}%")
爱酱的猫猫图片:
结果:

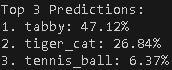
注:tabby就是虎斑猫
说明:
-
前半部分:可视化第一卷积层的16个特征图,帮助你理解CNN如何“看”图片。
-
后半部分:用完整VGG16模型对图片进行分类预测,并输出Top 3类别及其概率,让你看到“模型识别了什么”。
-
路径用原始字符串,避免Windows路径报错。
-
若模型预测结果不是猫,可能是因为猫的品种或姿态与ImageNet训练集不同,属于正常现象。
2. 循环神经网络(RNN)
-
应用案例:文本情感分析
-
可视化示例:RNN隐藏状态随时间步变化
注:请大家记得先
pip install tensorflow scikit-learn matplotlib等依赖!
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
from sklearn.model_selection import train_test_split
# 生成简单序列数据
np.random.seed(0)
X = np.random.rand(1000, 10, 1) # 1000个样本,序列长度10,特征1
# 目标是序列中每个样本的和是否大于5(二分类)
Y = (np.sum(X, axis=1) > 5).astype(int).reshape(-1)
# 划分训练和测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=42)
# 构建RNN模型
model = Sequential([
SimpleRNN(32, activation='relu', input_shape=(10, 1)),
Dense(2, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
history = model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test), verbose=1)
# 预测测试集
y_pred = model.predict(X_test)
# 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Val Loss')
plt.title('RNN Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Val Accuracy')
plt.title('RNN Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 打印部分预测结果
print('Sample predictions (probabilities) for first 5 test samples:')
print(y_pred[:5])
print('Predicted classes:')
print(np.argmax(y_pred[:5], axis=1))
print('True classes:')
print(y_test[:5])


说明:
-
前半部分:训练RNN并可视化loss和accuracy曲线,帮助你理解RNN的训练过程。
-
后半部分:输出部分预测概率、预测类别和真实类别,让你看到RNN的“识别/判断”能力。
3. Transformer
-
应用案例:机器翻译
-
可视化示例:注意力权重热力图
注:请大家记得先
pip install tensorflow matplotlib等依赖!
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, MultiHeadAttention, LayerNormalization, Dropout
from tensorflow.keras.models import Model
# 简单Transformer编码器层定义
class TransformerEncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(TransformerEncoderLayer, self).__init__()
self.mha = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)
self.ffn = tf.keras.Sequential([
Dense(dff, activation='relu'),
Dense(d_model)
])
self.layernorm1 = LayerNormalization(epsilon=1e-6)
self.layernorm2 = LayerNormalization(epsilon=1e-6)
self.dropout1 = Dropout(rate)
self.dropout2 = Dropout(rate)
def call(self, x, training, mask=None):
attn_output, attn_scores = self.mha(x, x, x, attention_mask=mask, return_attention_scores=True)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output)
return out2, attn_scores
# 构建简单Transformer模型
input_seq = Input(shape=(10, 16)) # 序列长度10,特征维度16
encoder_layer = TransformerEncoderLayer(d_model=16, num_heads=2, dff=64)
encoder_output, attn_scores = encoder_layer(input_seq, training=False)
model = Model(inputs=input_seq, outputs=[encoder_output, attn_scores])
# 生成随机输入数据
np.random.seed(0)
input_data = np.random.rand(1, 10, 16).astype(np.float32)
# 预测
encoder_out, attention_weights = model.predict(input_data)
# 可视化第一个头的注意力权重
plt.figure(figsize=(8, 6))
plt.imshow(attention_weights[0, 0], cmap='viridis')
plt.colorbar()
plt.title('Transformer Attention Weights (Head 1)')
plt.xlabel('Key Positions')
plt.ylabel('Query Positions')
plt.show()
# 打印编码器输出形状
print('Encoder output shape:', encoder_out.shape)
print('Attention weights shape:', attention_weights.shape)

![]()
说明:
-
前半部分:构建并运行一个简单的Transformer编码器,输入随机序列。
-
可视化部分:展示Transformer自注意力权重热力图,直观理解模型“关注”序列中的哪些位置。
-
后半部分:输出编码器的输出shape和注意力权重shape,帮助理解模型输出结构。
总结:卷积神经网络(CNN)vs. 循环神经网络(RNN)vs. Transformer
卷积神经网络(CNN)、循环神经网络(RNN)和Transformer是深度学习领域三大经典架构,各自针对不同类型的数据和任务展现出独特优势。理解它们的结构原理、特性及适用场景,对于AI系统设计和工程落地至关重要。
卷积神经网络(CNN)
CNN以卷积操作为核心,利用局部感知和权重共享机制,能够高效提取图像、音频等网格结构数据中的局部特征。其主要优势在于参数数量少,计算效率高,能有效捕捉空间相关性和层次结构,广泛应用于图像分类、目标检测、医学影像等领域。CNN通过多层堆叠实现从低级到高级的特征抽取,是计算机视觉领域的主力模型。
局限性在于:感受野有限,难以直接捕获长距离依赖或全局上下文信息;对序列建模能力有限,处理文本、时间序列等任务时表现不如RNN和Transformer。
循环神经网络(RNN)
RNN通过隐藏状态的循环连接,能够“记忆”历史信息,专门设计用于处理序列数据,如文本、语音、时间序列等。RNN适合捕捉时序依赖和变长输入,广泛应用于机器翻译、语音识别、文本生成等任务。
主要优势在于能建模时间动态行为和短距离依赖,但局限性也很明显:传统RNN难以捕捉长距离依赖(长期依赖问题),容易出现梯度消失或爆炸,训练效率低,难以并行处理长序列数据。为此,LSTM、GRU等变种被提出以缓解这些问题。
Transformer
Transformer基于自注意力机制(Self-Attention),彻底改变了序列建模方式。它能够直接建模序列中任意位置的全局依赖关系,大幅提升了长距离特征捕获能力。Transformer结构支持完全并行计算,极大提高了训练和推理效率,尤其适合大规模数据和长序列任务。
核心优势包括:
-
全局上下文捕获能力强,能动态关注序列中任意位置的信息。
-
并行化效率高,适合GPU/TPU等硬件加速。
-
归纳偏置少,适应性强,能处理文本、图像、音频等多模态数据。
-
在NLP、CV等领域设立了多个新基准,成为BERT、GPT、ViT等主流大模型的基础。
局限性在于模型参数多、计算资源需求高,且在极短序列或小数据场景下不一定优于传统方法。
综合对比
-
特征提取能力:Transformer > RNN ≈ CNN(全局语义特征,尤其在长序列/复杂结构中Transformer最强)。
-
长距离依赖建模:Transformer ≈ RNN > CNN(RNN和Transformer均能捕捉长距离依赖,但Transformer更高效)。
-
并行计算:Transformer > CNN > RNN(RNN需顺序处理,Transformer和CNN可高效并行)。
-
适用场景:CNN主攻图像、RNN主攻序列、Transformer适合文本、图像、语音及多模态任务。
结论
三大架构各有千秋,CNN擅长局部特征提取和空间建模,RNN适合时序建模和短期依赖,Transformer则以自注意力机制实现全局特征捕获和高效并行,推动了AI在NLP、CV等领域的突破。未来,随着多模态、长序列和大模型的发展,Transformer及其变体将持续引领AI架构创新,但CNN和RNN在特定场景下依然不可替代。理解并灵活运用这三类模型,是AI工程与研究的基础能力。
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 37
37 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)