
动手学深度学习 - 现代递归神经网络 - 10.6 编码器-解码器架构(Encoder-Decoder Architecture)
摘要:编码器-解码器架构是处理序列到序列任务的核心框架,通过编码器将变长输入压缩为状态向量,再由解码器自回归生成目标序列。该架构具有高度通用性,广泛应用于机器翻译、语音识别、文本摘要等场景。其核心优势包括信息压缩能力、生成灵活性及模块化设计。随着注意力机制的引入,有效解决了长序列信息丢失问题。在工业实践中,该架构已拓展至多模态应用,如视频字幕生成、跨语言迁移学习和图文生成系统,通过灵活组合不同编码
动手学深度学习 - 现代递归神经网络 - 10.6 编码器-解码器架构(Encoder-Decoder Architecture)
在序列到序列的任务中,输入和输出往往具有不等长的时间步,典型代表如机器翻译。这类任务的核心挑战在于如何将输入序列压缩成一个中间状态,并据此生成目标序列。为了解决这一问题,编码器-解码器(Encoder-Decoder)架构应运而生,并成为后续所有序列生成模型(包括注意力机制、Transformer等)的基石。
10.6.1 编码器-解码器结构图解
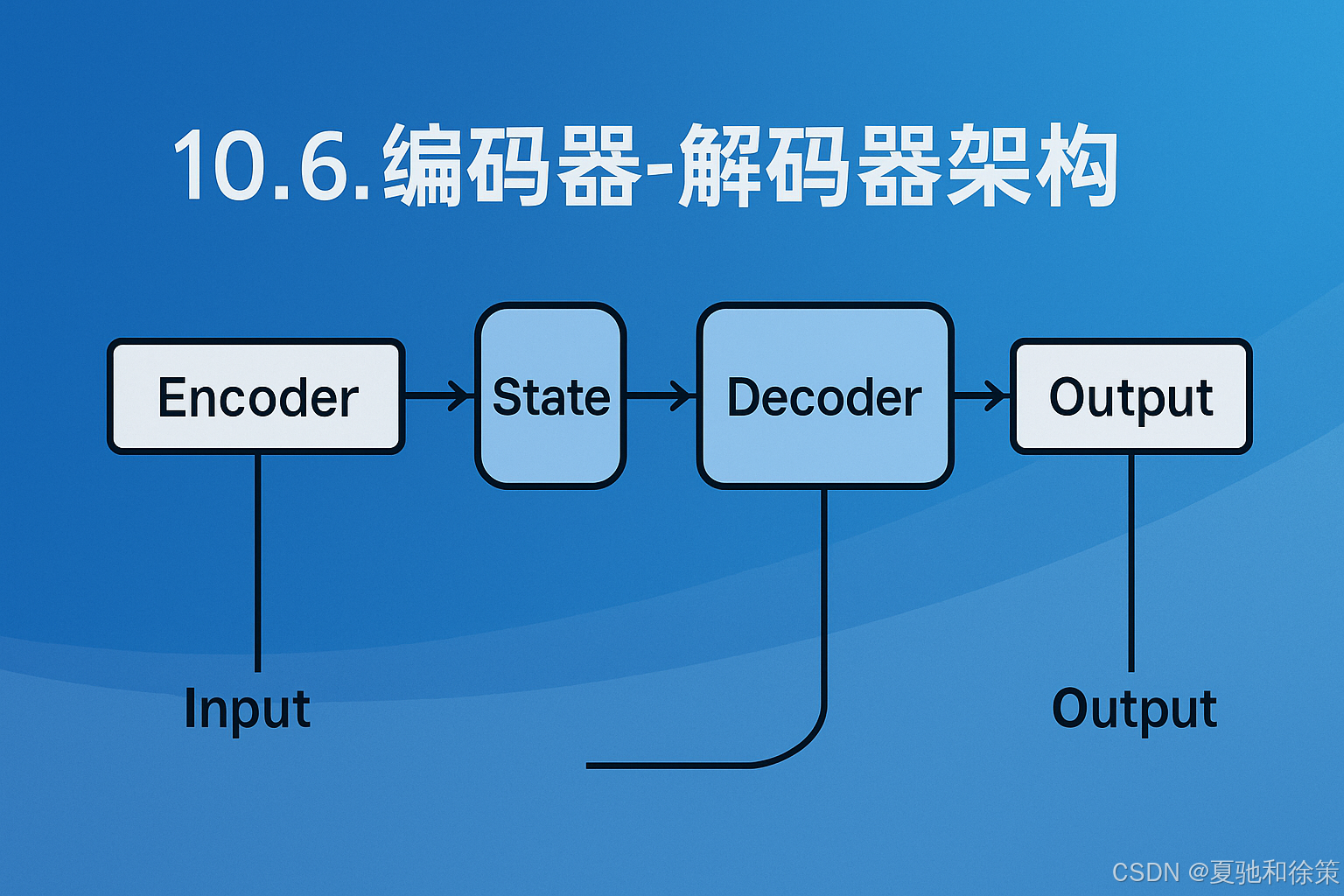
整个架构如图所示,由三部分组成:
-
编码器(Encoder):接收可变长度的输入序列,并将其压缩为一个状态向量(state);
-
状态(State):存储编码器的压缩表示,作为解码器的初始输入;
-
解码器(Decoder):基于该状态向量和已有的部分输出,逐步生成目标序列。
这是一种典型的条件语言模型设计。我们可以将其类比为:先听完一句话(编码器),再基于理解进行翻译或回复(解码器)。
例如,输入句子:“They are watching .”
输出目标:“Ils regardent .”
10.6.2 编码器接口设计
在代码实现中,Encoder 类为所有编码器定义了一个统一接口:
class Encoder(nn.Module):
def forward(self, X, *args):
raise NotImplementedError
它只要求实现一个输入 X 到编码状态的前向传播函数,便于后续替换不同结构的编码器(如 RNN、GRU、Transformer 等)。
10.6.3 解码器接口设计
解码器的接口更复杂一些,它需要:
-
初始化状态:
init_state(enc_outputs, *args) -
逐步解码:
forward(X, state)
class Decoder(nn.Module):
def init_state(self, enc_all_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
这使得解码器可以灵活支持自回归解码过程,在每个时间步基于之前的输出和当前状态进行更新。
10.6.4 编码器-解码器联合结构
将两者结合后,我们得到如下封装:
class EncoderDecoder(d2l.Classifier):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)[0]
这段代码清晰地展现了编码器输出如何被初始化为解码器的状态,并进一步推动目标序列的生成过程。
10.6.5 小结
-
编码器-解码器架构是处理输入输出长度不一致的序列任务的关键解决方案;
-
它将输入序列映射为一个固定维度的中间状态,再由解码器逐步解码为输出;
-
后续所有 Seq2Seq 模型(包括注意力机制和 Transformer)都可以看作是该架构的扩展版本。
📘 理论理解
编码器-解码器(Encoder-Decoder)架构是为了解决**序列到序列(seq2seq)**问题而提出的通用框架,最初用于机器翻译(如英文到法文),也广泛用于语音识别、文本摘要、图像字幕生成等任务。
-
编码器 Encoder 将输入序列压缩成一个固定长度的向量(也称为上下文向量或状态向量
state),捕捉输入的全部信息。 -
解码器 Decoder 在生成目标序列时,利用
state和已经生成的部分目标序列逐步进行预测。
关键点包括:
-
信息压缩能力:Encoder 对变长输入进行向量压缩,理论上可提取全局特征;
-
生成能力:Decoder 自回归生成输出,每一步依赖之前的输出(或真实标签);
-
接口解耦性:Encoder 和 Decoder 被抽象为两个独立模块,可组合不同架构(如 CNN + RNN, Transformer + RNN)。
这个结构的通用性极强,之后引入注意力机制(Attention)就是在这基础上增加了对上下文中各部分的权重建模。
🏢 大厂实战理解(以字节跳动 / Google / OpenAI 等为例)
在实际工业场景中,Encoder-Decoder 架构早已脱离了“只做机器翻译”的阶段,成为构建一切“从一个输入序列生成另一个输出序列”的标准范式。
📌 场景 1:字节跳动 - 多模态字幕生成
输入: 视频中的音频(语音序列) → Encoder
输出: 视频字幕(字符序列) → Decoder
-
编码器采用 Transformer 或 Conformer 结构提取音频特征;
-
解码器生成字幕(支持多语言),并使用 beam search 保证输出质量;
-
如果没有 Encoder-Decoder 架构,系统就无法处理语音长度和字幕长度不等的问题。
📌 场景 2:Google - 文本摘要 / 自动回复
输入: 一段长文 → Encoder
输出: 简短摘要或一句回复 → Decoder
-
编码器使用 BERT/Transformer 对上下文进行编码;
-
解码器使用类似 GPT 的结构生成摘要,生成过程为自回归;
-
可配合 Pointer Network 做摘要中的复制操作。
📌 场景 3:OpenAI Codex - 代码补全
输入: 函数定义 / 注释 → Encoder
输出: 函数体的代码补全 → Decoder
-
使用专门编码器建模自然语言指令;
-
使用 GPT-like 解码器生成 Python、JavaScript 等代码;
-
编码器与解码器共享部分权重以提升学习效率。
💼 大厂面试题(带逐步解析答案)
🧠 面试题 1:为什么 Encoder-Decoder 架构适用于机器翻译等序列到序列任务?
参考答案:
Step 1:明确问题本质
机器翻译是一种典型的序列到序列任务,其输入和输出长度不一定相同,且无严格对齐(如英语单词数量 ≠ 中文)。
Step 2:解释 Encoder-Decoder 架构的设计动机
Encoder 可以将变长输入压缩为定长向量state,提取全局语义;Decoder 逐步生成输出序列,使得模型具备“读完再说”的能力,避免逐字对齐。
Step 3:总结优势
这种架构具备高度可扩展性,可进一步接 Attention,或搭配多模态输入,能处理任意输入输出长度的自然语言任务。
🧠 面试题 2:在 Encoder-Decoder 中,为什么不直接把最后一个 Encoder 输出作为 Decoder 初始输入?
参考答案:
Step 1:区分 encoder 输出和 decoder 输入的角色
编码器的最后输出表示整个输入序列的压缩状态;而解码器的初始输入(通常是<BOS>或<START>token)代表的是目标语言生成的起点。
Step 2:说明这种分离的好处
将encoder state用作 decoder 的隐状态(hidden state 或 memory)初始化,而不是直接作为词输入,避免信息误导,同时支持 decoder 从<BOS>开始自回归生成。
Step 3:拓展真实工程实践
在实际中,decoder 的输入来自前一时刻输出(teacher forcing),这样便于训练阶段收敛、预测阶段灵活自回归。
🧠 面试题 3:Encoder-Decoder 中的状态 state 是定长的,会带来哪些问题?有什么解决方法?
参考答案:
Step 1:识别问题来源
编码器输出state的定长表示会导致信息瓶颈,尤其是在长文本翻译时,模型可能无法压缩所有输入序列的关键信息。
Step 2:给出负面影响
这会导致翻译遗漏、词义不清、上下文消失等问题,即便模型总体参数很大也无能为力。
Step 3:引入改进方法
加入 Attention 机制,让 Decoder 每一步都可以“回头看” Encoder 的全部输出(而不是只看最后一个state向量)。这突破了压缩瓶颈,使模型动态选择信息源。
🧠 面试题 4(代码实践类):请写出 PyTorch 中如何定义一个 EncoderDecoder 类,并说明各组件的 forward 流程?
参考答案(简化版):
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)[0]
解析流程:
调用 encoder 得到编码后的所有时间步输出
enc_outputs;使用 decoder 的
init_state()方法初始化解码状态;用
decoder()根据dec_X和解码状态逐步生成结果。
🏢 大厂真实场景题(附思路与解析)
🎯 场景题 1:字节跳动多语言字幕生成系统
**背景:**在抖音国际版 TikTok 中,AI 需要将视频语音自动转成多语言字幕。你作为工程负责人,选择了 Encoder-Decoder 架构作为核心方案,请说明其优势,并设计具体方案。
✅ 解题思路:
-
Step 1:问题建模
-
输入:音频帧序列(时长变长)
-
输出:目标语言文字序列(长度不定)
-
-> 属于典型的 Sequence-to-Sequence 问题
-
-
Step 2:模型方案设计
-
使用
声学特征提取器(如 Mel-spectrogram)提取音频特征 -
Encoder:Bi-LSTM 或 CNN+Transformer 提取上下文表示 -
Decoder:Auto-regressive 文字生成模块(可接 Beam Search) -
加入 Attention 或 Transformer 结构缓解长语音压缩问题
-
-
Step 3:优势总结
-
能灵活处理输入输出不等长情况
-
可在 Decoder 阶段融合目标语言模型做约束
-
训练时可用 Teacher Forcing 加速收敛
-
🎯 场景题 2:腾讯 AI Lab 智能问答系统跨语言迁移
**背景:**你要在英语 QA 模型的基础上,快速上线一套印地语问答系统,数据不足,模型无法从头训练。此时如何使用 Encoder-Decoder 架构实现迁移学习?
✅ 解题思路:
-
Step 1:问题本质
-
多语言迁移:Encoder 需处理不同语种,Decoder 输出语义回答
-
核心:让 Encoder 学习语义层次的跨语言共享表征
-
-
Step 2:具体方法
-
使用共享 Encoder:训练时用英文语料+印地语并行语料联合预训练
-
使用语言标签控制输出(Multilingual Decoder 或 Adapter 模块)
-
使用 Encoder-Decoder 架构接通跨语种理解与回答生成
-
-
Step 3:工程可行性
-
可以复用大规模英语 QA 模型参数
-
Encoder 在双语场景中具备共享语义能力
-
Decoder 可轻量调整参数做 fine-tuning
-
🎯 场景题 3:阿里搜索团队 - 跨模态检索中的图文生成系统
**背景:**在电商搜索中,用户上传图片后希望生成一段商品描述(如“红色条纹长袖T恤”)。请问 Encoder-Decoder 架构如何应用在图文生成任务中?有哪些关键注意点?
✅ 解题思路:
-
Step 1:任务理解
-
输入:图像特征(CNN 提取)
-
输出:描述文本序列
-
是一个视觉输入 → 语言输出的典型 seq2seq 任务
-
-
Step 2:结构方案
-
Encoder:使用 CNN(如 ResNet)提取图像特征 → Flatten → Linear 变换 -
Decoder:LSTM 或 Transformer 解码器 + Softmax 输出文字 -
中间加入 Attention over CNN patch features(类似图像 caption)
-
-
Step 3:难点与解决
-
图像无自然时间维度 → 加入位置编码或区域特征排序
-
Decoder 对语义一致性要求高 → 引入 CIDEr、BLEU 等评价指标优化
-


技术共进,成长同行——讯飞AI开发者社区
更多推荐

 20
20 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)