
transformer中编码器注意力机制(multihead selfattention )和 解码器注意力机制(masked multihead selfattention)的区别是什么
Transformer模型中的Multihead Self-Attention和Masked Multihead Self-Attention是其核心组件,主要区别在于信息可见性和应用场景。Multihead Self-Attention允许双向信息流动,适合捕捉全局依赖关系,常用于编码器或非自回归任务的解码器。而Masked Multihead Self-Attention通过因果掩码限制信息流
·
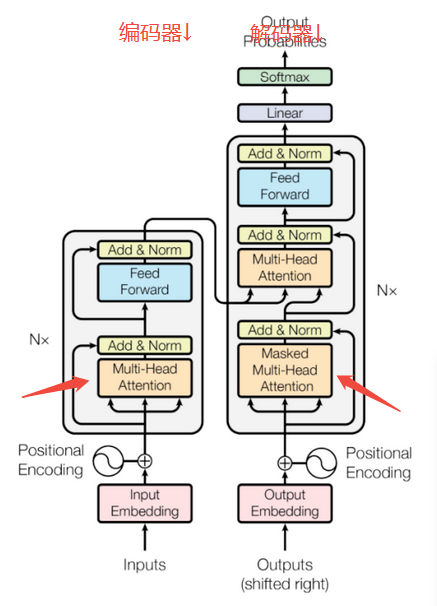
上图为transformer结构图
Multihead Self-Attention 和 Masked Multihead Self-Attention 是 Transformer 模型中的核心组件,主要区别在于 信息可见性限制 和 应用场景。以下是两者的详细对比:
1. 核心机制差异
- Multihead Self-Attention
- 无掩码限制:每个位置可以关注序列中所有其他位置(包括过去和未来),允许双向信息流动。
- 并行计算:所有位置的注意力权重一次性计算完成,适合捕捉全局依赖关系。
- 典型应用:主要用于编码器(如 BERT),或非自回归任务的解码器。
- Masked Multihead Self-Attention
- 因果掩码(Causal Mask):通过掩码矩阵禁止当前位置关注未来的位置,仅允许关注过去和当前的信息。
- 单向计算:模拟自回归生成过程,避免未来信息泄露(如 GPT 生成文本时需逐个预测)。
- 典型应用:解码器的自回归生成阶段(如 Transformer 解码器或 GPT)。
2. 结构实现对比
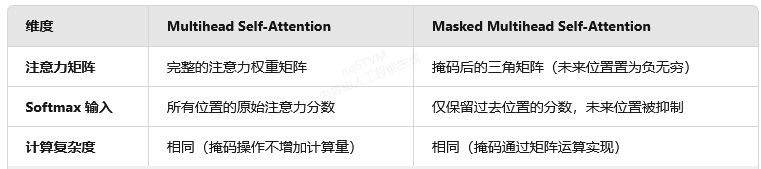
3. 功能与场景差异
- Multihead Self-Attention
- 双向建模:适合需要全局上下文的任务(如文本分类、翻译的编码阶段)。
- 示例:BERT 通过双向注意力学习词语的上下文表征。
- Masked Multihead Self-Attention
- 单向建模:强制模型仅依赖历史信息生成当前输出(如文本生成、语音合成)。
- 示例:GPT 生成每个词时只能看到已生成的左侧文本。
4. 训练与推理差异
- 训练效率
- 普通自注意力:支持全序列并行训练(如编码器)。
- 掩码自注意力:训练时仍可并行(掩码通过矩阵实现),但推理时需逐步生成(自回归)。
- 信息流限制
- 普通自注意力:允许模型学习双向依赖,增强表征能力。
- 掩码自注意力:限制信息流以避免过拟合未来数据,提升生成可控性。
5. 延伸:其他掩码类型
- 填充掩码(Padding Mask):两者均可使用,用于忽略无效位置(如填充符)。
- 交叉注意力(Cross-Attention):解码器中可能结合掩码自注意力(处理目标序列)和普通注意力(关联编码器输出)。
总结
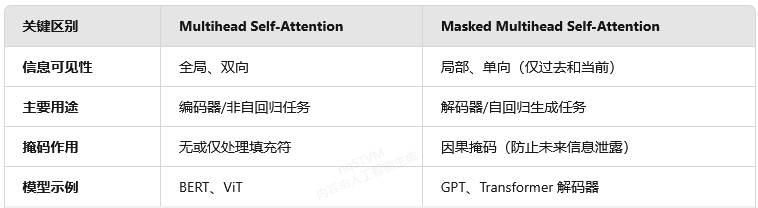
通过这一设计,Transformer 模型既能利用双向信息进行编码,又能严格遵循自回归规则生成序列,兼顾了表征能力和生成可控性。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 6
6 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)