
大数据技术之Hive------操作记录笔记
尚硅谷Hive学习
尚硅谷Hive入门学习笔记
一 .基本概念
1.1hive简介:
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并
提供类 SQL 查询功能。
Hive 本质:将 HQL 转化成 MapReduce 程序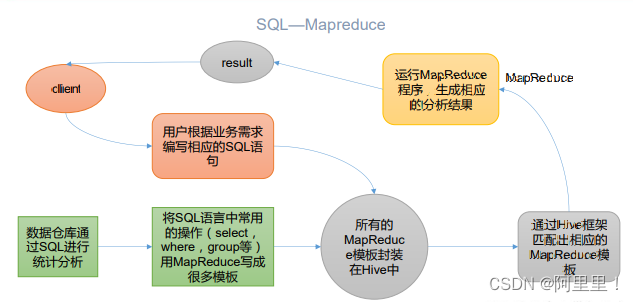
(1)Hive 处理的数据存储在 HDFS
(2)Hive 分析数据底层的实现是 MapReduce
(3)执行程序运行在 Yarn 上
Hive就有点像hadoop的客户端
1.2 Hive的优缺点
1.2.1优点:
(1)操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
(2)避免了去写 MapReduce,减少开发人员的学习成本。
(3)Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
(4)Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较
高。
(5)Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
1.2.2缺点
1)Hive 的 HQL 表达能力有限
(1)迭代式算法无法表达(嵌套 子查询)
(2)数据挖掘方面不擅长,由于 MapReduce 数据处理流程的限制,效率更高的算法却
无法实现。
2)Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化.
(2)Hive 调优比较困难,粒度较粗.
1.3 Hive 架构原理
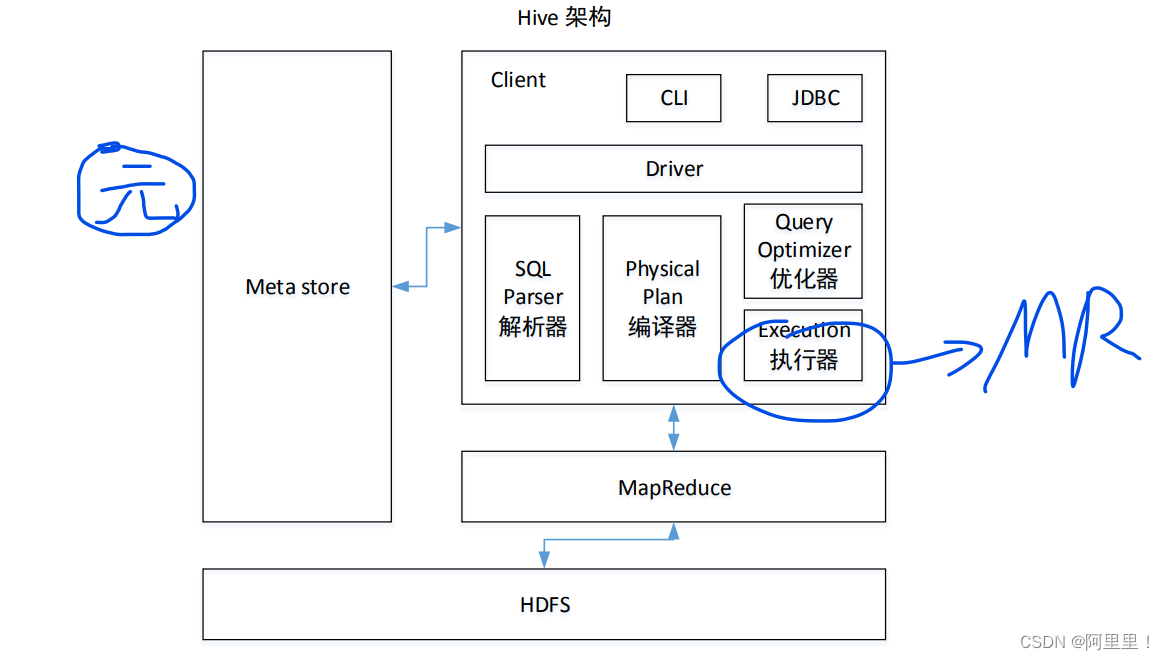
1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
尚硅谷大数据技术之 Hive
—————————————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、
表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore
3)Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
4)驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第
三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL
语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来
说,就是 MR/Spark。
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver,
结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将
执行返回的结果输出到用户交互接口。
1.4 安装 Hive
1)把 apache-hive-3.1.2-bin.tar.gz 上传到 linux 的/opt/software 目录下
2)解压 apache-hive-3.1.2-bin.tar.gz 到/opt/module/目录下面
[atguigu@hadoop102 software]$ tar -zxvf /opt/software/apache-hive-3.1.2-
bin.tar.gz -C /opt/module/
3)修改 apache-hive-3.1.2-bin.tar.gz 的名称为 hive
[atguigu@hadoop102 software]$ mv /opt/module/apache-hive-3.1.2-bin/
/opt/module/hive
4)修改/etc/profile.d/my_env.sh,添加环境变量
[atguigu@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
5)添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
6)解决日志 Jar 包冲突
[atguigu@hadoop102 software]$ mv $HIVE_HOME/lib/log4j-slf4j-impl2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak
7)初始化元数据库
[atguigu@hadoop102 hive]$ bin/schematool -dbType derby -initSchema
2.2.2 启动并使用 Hive
1)启动 Hive
[atguigu@hadoop102 hive]$ bin/hive
2)使用 Hive
hive> show databases;
hive> show tables;
hive> create table test(id int);
hive> insert into test values(1);
hive> select * from test;
1.5 MySQL 安装
先将元数据拷贝进来:
1)将 MySQL 的 JDBC 驱动拷贝到 Hive 的 lib 目录下
[atguigu@hadoop102 software]$ cp /opt/software/mysql-connector-java5.1.37.jar ./lib
2)在/conf 目录下新建 hive-site.xml 文件
**[atguigu@hadoop102 software]$ vim /conf/hive-site.xml**
添加如下内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
开始安装MySQL
1)检查当前系统是否安装过 MySQL
[atguigu@hadoop102 ~]$ rpm -qa|grep mariadb
mariadb-libs-5.5.56-2.el7.x86_64
//如果存在通过如下命令卸载
[atguigu @hadoop102 ~]$ sudo rpm -e --nodeps mariadb-libs
2)将 MySQL 安装包拷贝到/opt/software 目录下
[atguigu @hadoop102 software]# ll
总用量 528384
-rw-r--r--. 1 root root 609556480 3 月 21 15:41 mysql-5.7.28-
1.el7.x86_64.rpm-bundle.tar
3)解压 MySQL 安装包
[atguigu @hadoop102 software]# tar -xf mysql-5.7.28-1.el7.x86_64.rpmbundle.tar
4)在安装目录下执行 rpm 安装
[atguigu @hadoop102 software]$
sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
5)删除/etc/my.cnf 文件中 datadir 指向的目录下的所有内容,如果有内容的情况下(没有则不管):
查看 datadir 的值:
[mysqld]
datadir=/var/lib/mysql
删除/var/lib/mysql 目录下的所有内容:
[atguigu @hadoop102 mysql]# cd /var/lib/mysql
[atguigu @hadoop102 mysql]# sudo rm -rf ./* //注意执行命令的位置
6)初始化数据库
[atguigu @hadoop102 opt]$ sudo mysqld --initialize --user=mysql
7)查看临时生成的 root 用户的密码
[atguigu @hadoop102 opt]$ sudo cat /var/log/mysqld.log
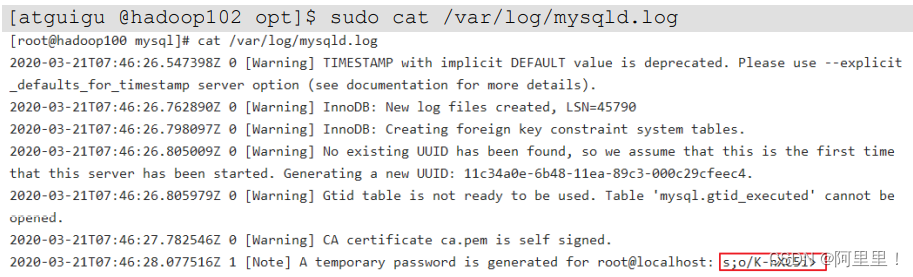
8)启动 MySQL 服务
[atguigu @hadoop102 opt]$ sudo systemctl start mysqld
9)登录 MySQL 数据库
[atguigu @hadoop102 opt]$ mysql -uroot -p
Enter password: 输入临时生成的密码(刚刚截图中的那个)
登录成功.
10)必须先修改 root 用户的密码,否则执行其他的操作会报错
mysql> set password = password("新密码");
11)修改 mysql 库下的 user 表中的 root 用户允许任意 ip 连接
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;(刷新操作)
查看是否修改成功:

通过 use mysql 进入到 mysql
再查看所以的表
查询user表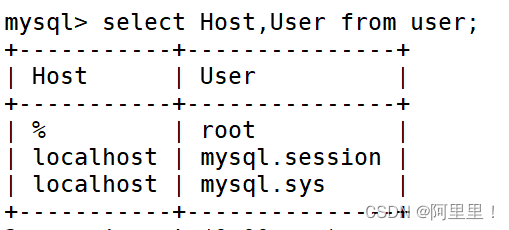
这样就修改成功了。
1.6 Hive 元数据配置到 MySQL
之前我们已经拷贝了驱动和配置文件了。所以我们直接配置元数据。
1)登陆 MySQL
[atguigu@hadoop102 software]$ mysql -uroot -p000000
2)新建 Hive 元数据库
mysql> create database metastore;
mysql> quit;
3) 初始化 Hive 元数据库
[atguigu@hadoop102 software]$ schematool -initSchema -dbType mysql -
verbose
再次启动hive
[atguigu@hadoop102 hive]$ bin/hive
最开始我们建立了一个test表。但是因为我们初始化了元数据库,所以你发现这里show tables什么都没有。但是我们重建立一个test表后,还是能够访问到最初的test表中的数据,就是因为元素据只是存储的mysql和hdfs的一个索引,我们将元数据重置过后再建立索引依然能够访问到。
1.7 多方式访问Hive
1)使用元数据服务的方式访问 Hive
在 hive-site.xml 文件中添加如下配置信息
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
启动 metastore
[atguigu@hadoop202 hive]$ hive --service metastore
2020-04-24 16:58:08: Starting Hive Metastore Server
注意: 启动后窗口不能再操作,需打开一个新的 shell 窗口做别的操作
启动 hive
[atguigu@hadoop202 hive]$ bin/hive
2).使用 JDBC 方式访问 Hive
在 hive-site.xml 文件中添加如下配置信息
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
(JDBC也 需要去启动方式1的metastore)
启动 hiveserver2
[atguigu@hadoop102 hive]$ bin/hive --service hiveserver2
启动 beeline 客户端(需要多等待一会)
[atguigu@hadoop102 hive]$ bin/beeline -u jdbc:hive2://hadoop102:10000 -n
atguigu
看到如下界面就连接成功
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://hadoop102:10000>
二. Hive 数据类型
2.1 基本数据类型
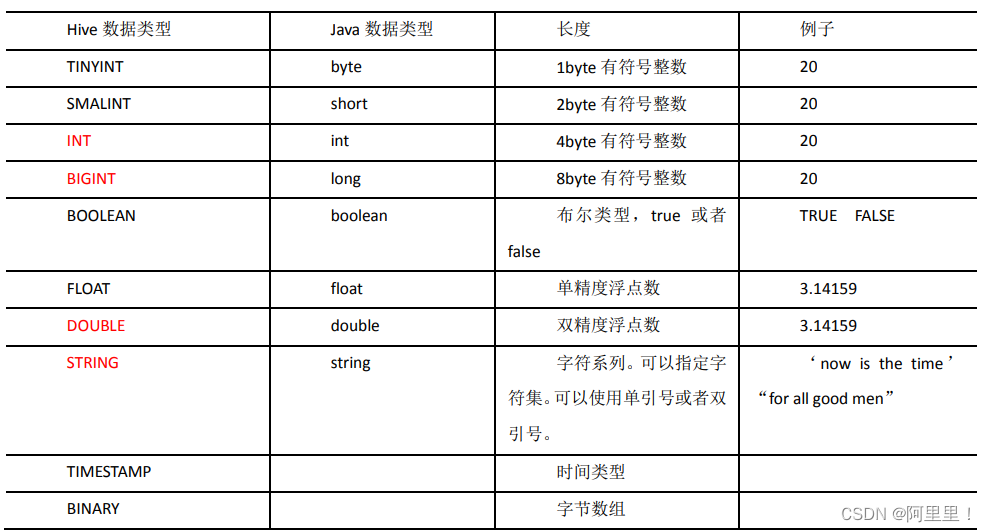
对于 Hive 的 String 类型相当于数据库的 varchar 类型,该类型是一个可变的字符串,不
过它不能声明其中最多能存储多少个字符,理论上它可以存储 2GB 的字符数
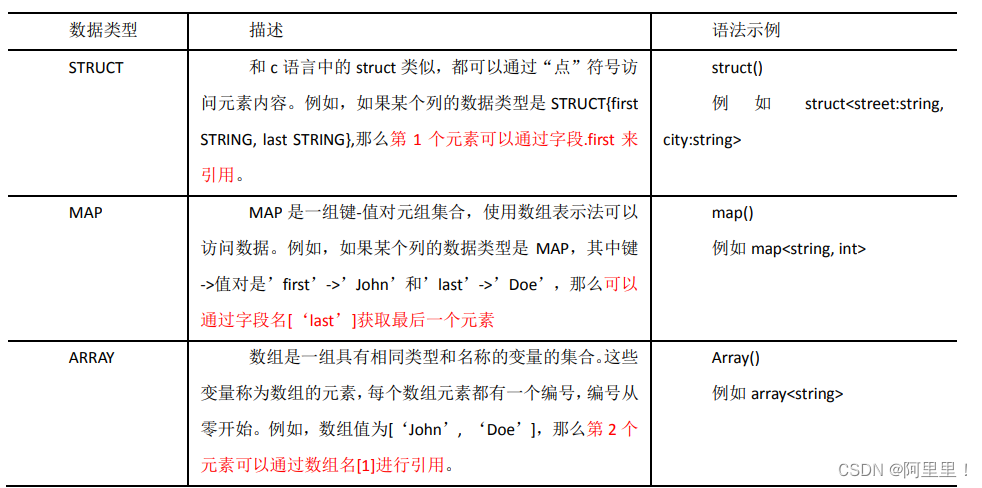
2.2 集合数据类型
数据如下:
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表 Array,
"children": { //键值 Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //结构 Struct,
"street": "hui long guan",
"city": "beijing"
}
}
数组和结构体和JAVA的访问方式一样 ,集合访问数据有所不同:
访问三种集合列里的数据,以下分别是 ARRAY,MAP,STRUCT 的访问方式
hive (default)> select friends[1],children['xiao song'],address.city from
test
where name="songsong";
OK
_c0 _c1 city
lili 18 beijing
Time taken: 0.076 seconds, Fetched: 1 row(s)
2.3 类型转化
Hive 的原子数据类型是可以进行隐式转换的,类似于 Java 的类型转换,例如某表达式
使用 INT 类型,TINYINT 会自动转换为 INT 类型,但是 Hive 不会进行反向转化,例如,某表
达式使用 TINYINT 类型,INT 不会自动转换为 TINYINT 类型,它会返回错误,除非使用 CAST
操作。
1)隐式类型转换规则如下
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换成
INT,INT 可以转换成 BIGINT。
(2)所有整数类型、FLOAT 和 STRING 类型都可以隐式地转换成 DOUBLE。
(3)TINYINT、SMALLINT、INT 都可以转换为 FLOAT。
(4)BOOLEAN 类型不可以转换为任何其它的类型。
2)可以使用 CAST 操作显示进行数据类型转换
例如 CAST(‘1’ AS INT)将把字符串’1’ 转换成整数 1;如果强制类型转换失败,如执行
CAST(‘X’ AS INT),表达式返回空值 NULL
三. DDL 数据定义
3.1 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
1)创建一个数据库,数据库在 HDFS 上的默认存储路径是/user/hive/warehouse/*.db。
hive (default)> create database db_hive;
2)避免要创建的数据库已经存在错误,增加 if not exists 判断。(标准写法)
hive (default)> create database db_hive;
FAILED: Execution Error, return code 1 from
org.apache.hadoop.hive.ql.exec.DDLTask. Database db_hive already exists
hive (default)> create database if not exists db_hive;
3)创建一个数据库,指定数据库在 HDFS 上存放的位置
hive (default)> create database db_h ive2 location '/db_hive2.db';
3.2 数据库操作
1)显示数据库
hive> show databases;
2)过滤显示查询的数据库
hive> show databases like 'db_hive*';
OK
db_hive
db_hive_1
3)显示数据库信息
hive> desc database db_hive;
OK
db_hive hdfs://hadoop102:9820/user/hive/warehouse/db_hive.db
atguiguUSER
4)显示数据库详细信息,extended
hive> desc database extended db_hive;
OK
db_hive hdfs://hadoop102:9820/user/hive/warehouse/db_hive.db
atguiguUSER
5)切换当前数据库
hive (default)> use db_hive;
6)修改数据库
用户可以使用 ALTER DATABASE 命令为某个数据库的 DBPROPERTIES 设置键-值对属性值,
来描述这个数据库的属性信息。
hive (default)> alter database db_hive
set dbproperties('createtime'='20170830');
在 hive 中查看修改结果
hive> desc database extended db_hive;
db_name comment location owner_name owner_type parameters
db_hive hdfs://hadoop102:9820/user/hive/warehouse/db_hive.db
atguigu USER {createtime=20170830}
7)删除空数据库
hive>drop database db_hive2;
如果删除的数据库不存在,最好采用 if exists 判断数据库是否存在
hive> drop database db_hive;
FAILED: SemanticException [Error 10072]: Database does not exist: db_hive
hive> drop database if exists db_hive2;
如果数据库不为空,可以采用 cascade 命令,强制删除
hive> drop database db_hive;
FAILED: Execution Error, return code 1 from
org.apache.hadoop.hive.ql.exec.DDLTask.
InvalidOperationException(message:Database db_hive is not empty. One or
more tables exist.)
hive> drop database db_hive cascade;
3.2 创建表
1) 建表语法
默认建的表为内部表,也就是管理表。
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
2)字段解释说明
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;
用户可以用 IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实
际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外
部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY 创建分区表
(5)CLUSTERED BY 创建分桶表
(6)SORTED BY 不常用,对桶中的一个或多个列另外排序
(7)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] (设置’,'为分割限制符):(row format delimited flelds terminated by ‘,’) [COLLECTION ITEMS TERMINATED BY char] :(集合分隔符 )
[MAP KEYS TERMINATED BY char]:(key,value分隔符) [LINES TERMINATED BY char]:行分隔符
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,
property_name=property_value, …)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW
FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需
要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表
的具体的列的数据。
SerDe 是 Serialize/Deserilize 的简称, hive 使用 Serde 进行行对象的序列与反序列化。
(8)STORED AS 指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列
式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED
AS SEQUENCEFILE。
(9)LOCATION :指定表在 HDFS 上的存储位置。
(10)AS:后跟查询语句,根据查询结果创建表。
(11)LIKE 允许用户复制现有的表结构,但是不复制数据。
3.3 管理表与外部表的互相转换
(1)查询表的类型
hive (default)> desc formatted student2;
Table Type: MANAGED_TABLE(内部表)
(2)修改内部表 student2 为外部表
alter table student2 set tblproperties('EXTERNAL'='TRUE');
(3)查询表的类型
hive (default)> desc formatted student2;
Table Type: EXTERNAL_TABLE
(4)修改外部表 student2 为内部表
alter table student2 set tblproperties('EXTERNAL'='FALSE');
(5)查询表的类型
hive (default)> desc formatted student2;
Table Type: MANAGED_TABLE
注意:(‘EXTERNAL’=‘TRUE’)和(‘EXTERNAL’=‘FALSE’)为固定写法,区分大小写!
3.3 修改表
重命名表
1)语法
ALTER TABLE table_name RENAME TO new_table_name
2)实操案例
hive (default)> alter table dept_partition2 rename to dept_partition3;
3.4 增加/修改/替换列信息
(1)更新列(CHANGE)
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name
column_type [COMMENT col_comment] [FIRST|AFTER column_name]
(2)增加和替换列(ADD|REPLACE)
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT
col_comment], ...)
注:ADD 是代表新增一字段,字段位置在所有列后面(partition 列前),
REPLACE 则是表示替换表中所有字段。
这里的替换操作 ,如表中有两列数据,替换过后则可成为一列文字。当然这个操作都是正对元数据的,HDFS中实际存储不变。
3.5 删除表
hive (default)> drop table dept;
删除表注意我们上面叫的外部表和内部表的区别。
四. DML 数据操作
4.1 数据导入

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)