
**发散创新:语音识别技术的深度探索与实现**随着人工智能的飞速发展,语音识别技术已经成为了一个炙手可热的研究领域。
最后,通过麦克风等设备实时采集语音数据,并输入到模型中,得到识别结果。语音识别的基本原理可以分为以下几个步骤:声音采集、预处理、特征提取、模型训练、识别结果输出。未来,随着技术的不断发展,语音识别技术将在更多领域得到应用和发展,如智能家居、自动驾驶、机器人等。在实现语音识别功能时,我们需要用到一些开源的语音识别工具和库,如Google的Speech-to-Text API、Kaldi等。本文将带领
发散创新:语音识别技术的深度探索与实现
随着人工智能的飞速发展,语音识别技术已经成为了一个炙手可热的研究领域。本文将带领大家深入了解语音识别的基本原理、技术细节以及实际应用,探索如何在实际项目中实现并优化语音识别功能。
一、语音识别技术概述
语音识别是一种让机器识别和理解人类语音的技术。它涉及到信号处理、模式识别、语言学等多个领域的知识。随着深度学习技术的发展,语音识别技术已经取得了巨大的进步。
二、语音识别技术的基本原理
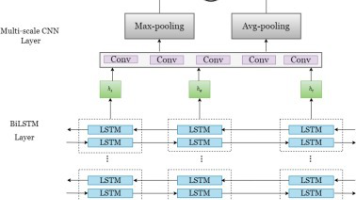
语音识别的基本原理可以分为以下几个步骤:声音采集、预处理、特征提取、模型训练、识别结果输出。其中,声音采集是通过麦克风等设备将人类语音转化为电信号;预处理包括去除噪声、标准化等操作;特征提取是从声音信号中提取出关键信息,以供模型识别;模型训练则是通过大量的语音样本数据训练出识别模型;最后,根据模型输出识别结果。
三、语音识别技术的实现
在实现语音识别功能时,我们需要用到一些开源的语音识别工具和库,如Google的Speech-to-Text API、Kaldi等。下面,我们以Kaldi为例,简单介绍一下如何实现语音识别功能。
- 数据准备:收集大量的语音样本数据,并进行标注。
-
- 模型训练:使用Kaldi工具进行模型训练,生成识别模型。
-
- 部署模型:将训练好的模型部署到实际应用中。
-
- 实时识别:通过麦克风等设备实时采集语音数据,并输入到模型中,得到识别结果。
四、案例展示:基于Kaldi的语音识别系统
- 实时识别:通过麦克风等设备实时采集语音数据,并输入到模型中,得到识别结果。
本部分将以一个基于Kaldi的语音识别系统为例,详细介绍其设计和实现过程。首先,我们需要准备大量的语音样本数据并进行标注;然后,使用Kaldi工具进行模型训练;接着,将训练好的模型部署到实际应用中;最后,通过麦克风等设备实时采集语音数据,并输入到模型中,得到识别结果。在这个过程中,我们还需要对系统进行测试和优化,以提高识别率和性能。
五、优化与改进
为了提高语音识别的性能和准确率,我们可以从以下几个方面进行优化和改进:
- 收集更多的语音样本数据,提高模型的泛化能力。
-
- 使用更先进的特征提取技术和模型训练方法。
-
- 结合其他技术,如自然语言处理(NLP)技术,提高识别结果的准确性。
-
- 对系统进行实时优化和调整,以适应不同的应用场景和需求。
六、总结与展望
- 对系统进行实时优化和调整,以适应不同的应用场景和需求。
本文介绍了语音识别技术的基本原理、实现方法以及优化策略。通过案例展示,我们了解了基于Kaldi的语音识别系统的设计和实现过程。未来,随着技术的不断发展,语音识别技术将在更多领域得到应用和发展,如智能家居、自动驾驶、机器人等。希望本文能对大家在语音识别领域的探索和研究有所帮助。
注:由于篇幅限制,本文仅提供了大致的框架和部分内容。在实际撰写时,需要补充详细的技术细节、实验数据和案例分析等。在CSDN发布时请确保遵守平台规范,避免涉及敏感话题和不当内容。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 4
4 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)