
DataAnalysis:基本概念,环境介绍,环境搭建,大数据问题
所谓数据就是描述事物的符号,是对客观事物的性质、状态和相互关系等进行记载的物理符号或者是这些物理符号的组合。在计算机系统中,各种文字、字母、数字符号的组合,图形、图像、视频、音频等统称为数据,数据经过加工后就成了信息。
1,概述
1.1,数据的性质
所谓数据就是描述事物的符号,是对客观事物的性质、状态和相互关系等进行记载的物理符号或者是这些物理符号的组合。在计算机系统中,各种文字、字母、数字符号的组合,图形、图像、视频、音频等统称为数据,数据经过加工后就成了信息。
数据是对世界万物的记录,任何可以被测量或是分类的事物都能用数据来表示。在采集完数据后,可以对数据进行研究和分析,从而获得有价值的信息。数据与信息既有联系,又有区别。数据是信息的表现形式,而信息则是数据的内涵,信息是加载于数据之上的,对数据做具体含义的解释。数据和信息是不可分离的,信息依赖数据来表达,数据则生动具体地表达出信息。数据是符号,是物理性的,信息是对原始数据进行加工后处理得到的并对决策产生影响的数据,信息是数据有意义的表示。
数据的类型:
- 类别型(定类和定序):类别型数据是指可以被分成不同组或类别的值或观察结果。通常可以分为定类和定序,定类型数据的各类别没有内在的顺序,而定序型数据有预先指定的顺序。
- 数值型数据(离散和连续):数值型数据是指通过测量得到的数值或观察结果,通常可分为两种,即离散和连续。离散型数据是指只能按计量单位计数的数据,例如:工人数、设备数。相反,连续性数据是指在一定范围内可以任意取值,数值是连续不断的,相邻两个数值可做无限分割(即可取无限个数值)的数据。例如:人体测量的身高和体重。
1.2,数据分析
数据分析是指用适当的统计分析方法对收集来的大量原始数据进行分析,为提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。数据分析的目的是提取不易推断的信息并加以分析,一旦理解了这些信息,就能够对产生数据的系统的运行机制进行研究,从而对系统可能的响应和演变做出预测。
数据分析的过程:
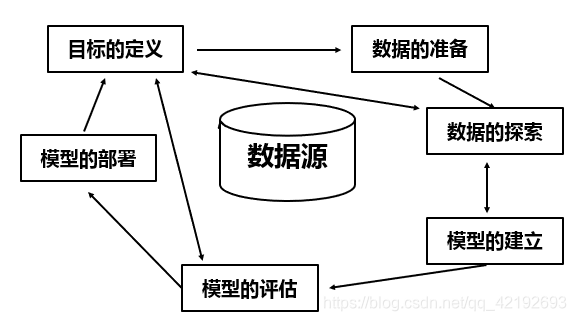
(1)理论过程:问题定义,数据采集,数据预处理,数据探索,数据可视化,预测模型的创建和选择,模型评估,部署。
(2)实际过程:转换和处理原始数据,用可视化的方式呈现数据,建模并做预测。
(3)详细过程:
- 探索性数据分析:一般获得的数据是无规律的、无背景和无业务关联的,需要对这些数据进行清洗,即查漏补缺,确保数据的真实有效性,然后通过图表、用户画像和行为轨迹等挖掘和揭示隐含在数据中的规律。
- 数据价值挖掘:在探索性分析的基础上利用算法、模型和数据挖掘等,进一步确定数据的价值,建立合适的模型。
- 建立业务:通过挖掘的数据价值,建立一定的业务,获得效益。
数据分析的作用:
- 现状分析:所谓现状有两层含义,一层含义是指已经发生的事情,另一层含义是指现在所发生的的事情。通过对企业的基础周报或月报进行分析,可了解企业的整体运营情况,发现企业运营中的问题,了解企业的现状。
- 原因分析:如果通过现状分析,了解到企业存在某些隐患后,就需要分析该隐患。了解该隐患存在的原因和它是如何产生的。
- 预测分析:在分析了现状,也分析了原因后,就需要进行预测分析。通过现在掌握的数据,来预测未来的发展趋势等。
1.3,数据分析、数据挖掘、机器学习、深度学习、统计学
机器学习属于人工智能研究与应用的一个分支领域。机器学习的研究更加偏向理论性,其目的更偏向于是研究一种为了让计算机不断从数据中学习知识,而使机器学习得到的结果不断接近目标函数的理论。
机器学习为数据挖掘提供了理论方法,而数据挖掘技术是机器学习技术的一个实际应用。逐步开发和应用了若干新的分析方法逐步演变而来形成的;这两个领域彼此之间交叉渗透,彼此都会利用对方发展起来的技术方法来实现业务目标,数据挖掘的概念更广,机器学习只是数据挖掘领域中的一个新兴分支与细分领域,只不过基于大数据技术让其逐渐成为了当下显学和主流。
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。晦涩难懂的概念,略微有些难以理解,但是在其高冷的背后,却有深远的应用场景和未来。深度学习是实现机器学习的一种方式或一条路径。其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据。比如其按特定的物理距离连接;而深度学习使用独立的层、连接,还有数据传播方向,比如最近大火的卷积神经网络是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能,让机器认知过程逐层进行,逐步抽象,从而大幅度提升识别的准确性和效率。
数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘本质上像是机器学习和人工智能的基础,它的主要目的是从各种各样的数据来源中,提取出超集的信息,然后将这些信息合并让你发现你从来没有想到过的模式和内在关系。这就意味着,数据挖掘不是一种用来证明假说的方法,而是用来构建各种各样的假说的方法。数据挖掘不能告诉你这些问题的答案,他只能告诉你,A和B可能存在相关关系,但是它无法告诉你A和B存在什么相关关系。机器学习是从假设空间H中寻找假设函数g近似目标函数f。数据挖掘是从大量的数据中寻找数据相互之间的特性。
数据分析是基于数据库系统和应用程序,可以直观的查看统计分析系统中的数据,从而可以很快得到我们想要的结果;这个就是最基本的数据分析功能,也是我们在信息化时代了,除了重构业务流程、提升行业效率和降低成本之外的了。另外数据分析更多的是指从历史数据里面发现有价值的信息,从而提高决策的科学性。数据分析更侧重于通过分析数据的历史分布然后从中得出一些有价值的信息。还有一个数据分析更重要的功能,就是数据可视化。
统计学是在统计实践的基础上,研究如何测定、收集、整理、归纳和分析反映客观现象总体数量的数据,以便给出正确认识的方法论科学,被广泛的应用在各门学科之上,从自然科学和社会科学到人文科学,甚至被用来工商业及政府的情报决策之上。机器学习模型旨在使最准确的预测成为可能;统计模型被设计用于推断变量之间的关系。
1.4,数据挖掘
数据挖掘:从大量的、不完全的、有噪声的、模糊的、随机的数据中,利用统计、计算机、数学等领域的方法提取隐含在其中的信息和知识的过程。
数据挖掘特点:处理的数据规模十分庞大,非精确性查询(分析),快速响应变更,发现规则,动态变化
数据挖掘原理:利用算法对处理好的输入和输出数据进行训练,并得到模型, 然后再对模型进行验证,使得模型能够在一定程度上刻画出数据由输入到输出的关系, 然后再利用该模型,对新输入的数据进行计算,从而得到对我们有用的新的输出。
关联(Apriori,FP-Tree,HotSpot)无监督:
基于规则中处理的变量的类别,关联规则可以分为布尔型和数值型。
基于规则中数据的抽象层次,可以分为单层关联规则和多层关联规则。
基于规则中涉及的数据的维数,关联规则可以分为单维的和多维的。
回归(线性回归,非线性回归,逐步回归,逻辑回归)有监督:
回归是确定两种或两种以上变数间相互定量关系的一种统计分析方法。
回归在数据挖掘中是最为基础的方法,也是应用领域和应用场景最多的方法,只要是量化型问题, 我们一般都会先尝试用回归方法来研究或分析。
分类(KNN,贝叶斯,神经网络,逻辑斯蒂,判别分析,支持向量机(SVN),决策树)有监督
- 分类是最为常见的问题, 其典型的应用就是根据事物在数据层面表现的特征,对事物进行科学的分类。
聚类(K-Means,层次聚类,神经网络,高斯混合,模糊C均值)无监督
- 聚类分析又称群分析,是根据“物以类聚”的道理,对样品进行分类的一种多元统计分析方法,它们讨论的对象是大量的样品,要求能合理地按各自的特性来进行合理的分类,没有任何模式可供参考或依循,即是在没有先验知识的情况下进行的。
- 分类和聚类的区别在于是否预先定义好类别
数据准备
- 数据选择:从数据源中搜索所有与业务对象有关的内部和外部数据信息,并从中选择出适用于数据挖掘应用的数据。
- 数据质量分析:缺失数据,数据错误,度量标准错误,编码不一致,无效元数据。
- 数据预处理:数据清洗,数据集成,数据归约,数据变换。
数据的探索:探索数据是对数据进行初步研究,以便投资者更好地了解数据的特征,为建模的变量选择和算法选择提供依据。主要方法:描述统计,数据的可视化,数据探索的建模活动。
模型的建立:模型的建立是数据挖掘的核心,在这一步要确定具体的数据挖掘模型(算法),并用这个模型原型训练出模型的参数,得到具体的模型形式。
模型的评估:模型评估阶段需要对数据挖掘过程进行一次全面的回顾,从而决定是否存在重要的因素或任务由于某些原因被忽视,此阶段的关键目的是判断是否还存在一些重要的(商业)问题仍未得到充分考虑。指标:精度,时间效率,空间效率。
模型的部署:模型的部署就是将通过验证评估的模型,部署到实际的业务系统中进行数据分析处理。
2,数据分析环境
2.1,Python与数据分析
常用的数据分析工具有Python、R语言、MATLAB等,但在大数据分析领域,Python是最受欢迎的主流程序语言。究其原因有以下几点:
- Python是一种解释型语言,在数据分析的场景中,解释型语言的好处是不需要对代码进行编译和链接,只需要编写好程序,就可直接运行,这样就可以避免解决编译链接过程中所出现的各种问题。同时,Python语言语法和结构相对简单,便于专注于数据分析的新手掌握。
- Python语言拥有与数据分析相关的大量开源库和分析框架,可直接使用,非常方便。另外Python不仅提供了数据处理的平台,而且它还能跟很多语言对接。
- Python其实不是只能用于数据分析,它还有很多其他方面的用途。例如,Python是一门通用型编程语言它可以作为脚本来使用,还能操作数据库;而且由于Django等框架的问世,Python近年来还可以用于开发Web应用,这就使Python开发的数据分析项目完全可以与Web服务器兼容,从而可以整合到Web应用中。
2.2,Python中常用的类库
类库是用来实现各种功能的类的集合。Python数据分析中常用的类库有Numpy、pandas、Matplotlib和SciPy等,这些类库在数据分析中起着很重要的作用。
(1)NumPy是Python科学计算的基础包,它可提供以下功能:
- 快速高效的多维数组对象ndarray。
- 用于对数组执行元素级计算和直接对数组执行数学运算的函数。
- 用于读写硬盘上基于数组的数据集的工具。
- 线性代数运算、傅里叶变换,以及随机数生成。
- 用于将C、C++、Fortran代码集成到Python工具。
除了为Python提供快速的数组处理能力,NumPy在数据分析方面还有另外一个主要作用,即作为算法之间传递数据的容器。对于数值型数据,NumPy数组在存储和处理数据时要比内置的Python数据结构高效得多。此外,由高级语言(C和Fortran)编写的库可直接操作NumPy数组中的数据。
(2)pandas是Python数据分析的核心库,它是基于NumPy构建的含有复杂数据结构和工具的数据分析报包。pandas最初是被作为金融数据分析工具而开发出来的,因此,它为时间序列分析提供了很好的支持。pandas纳入了大量和标准数据模型,提供了大量的可快速便捷处理数据的函数和高效操作数据集所需的工具。
类似于NumPy的核心是ndarray,pandas则是围绕着Series和DataFrame这两个核心数据结构展开的,而Series和DataFrame分别对应于一维的序列和二维的表结构。pandas提供了复杂精细的索引功能,以便快捷地完成重塑、切片、聚合和选取数组子集等操作。
(3)Matplotlib是最流行的用于绘制数据图表的Python库,它非常适合创建出版物中用的图表。Matplotlib提供了一整套与MATLAB相似的命令API,十分适合交互式地进行制图,而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中。通过Matplotlib的pyplot子库提供的与MATLAB类似的绘图API,可方便用户快速绘制2D图表,例如直方图、条形图、散点图等。
Matplotlib还提供了名为pylab的模块,其中包括了许多NumPy和pyplot中常用的函数,方便用户快速进行计算和绘图。Matplotlib与IPython结合提供了一个非常好的交互式数据绘图环境,绘制图表也是交互式的,用户可以利用绘图窗口工具栏中的相应工具放大图表的某个区域,或对某个图表进行平移浏览。
(4)SciPy是一组专门用于科学计算的开源Python库,它构建于NumPy的基础上,提供了一个用于在Python中进行科学计算的工具集。SciPy经常与NumPy、pandas、Matplotlib和IPython这些核心库一起使用,SciPy主要包括8个包,这些包分别对应着不同的科学计算领域:
- scipy.integrate:数值积分例程和微分方程求解器。
- scipy.linalg:扩展了由numpy.linalg提供的线性代数例程和矩阵分解功能。
- scipy.optimize:函数优化器(最小化器)和跟踪查找算法。
- scipy.signal:信号处理工具。
- scipy.sparse:稀疏矩阵和稀疏线性系统求解器。
- scipy.special:SPECFUN的包装器。
- scipy.starts:标准连续和离散概率分布,各种统计校验方法,以及更好的描述统计法。
- scipy.weave:利用内联的C++代码加速数组计算的工具。
(5)scikit-learn是一个简单有效的数据挖掘和数据挖掘分析工具,可供用户在各种环境下重复使用,而且scikit-learn是建立在NumPy、SciPy和Matplotlib的基础上,对一些常用的算法进行了封装。scikit-learn的基本功能主要分为六大部分:分类、回归、聚类、数据降维、模型选择和数据预处理。在数据量不大的情况下,scikit-learn可以解决大部分问题。对算法不精通的用户在执行建模任务时,并不需要自行编写所有算法,只需简单地调用scikit-learn库里的模块即可。
(6)IPython是Python科学计算标准工具集的组成部分,它为交互和探索式计算提供了一个高效的开发环境。它是一个增强的Pythonshell,目的是提高编写、测试、调试Python代码的速度,主要用于交互式数据处理和利用Matplotlib对数据进行可视化处理。
3,环境搭建
3.1,Anaconda
Anaconda是一个开源的Python发行版,预装了Conda、Python和Jupyter Notebook等180个科学库,及其依赖项。更直观的理解就是,Anaconda是一个支持Linux、Mac和Windows系统,集众多Python库和环境管理软件。
Anaconda可以在同一个机器上安装不同版本的软件包及其依赖项,并能够在不同的环境之间切换,可以很方便地解决多版本Python并存、切换以及各种第三方安装问题。Anaconda利用命令Conda来进行包和环境的管理,也可以使用pip进行包的管理,并且已经包含了Python相关的配套工具。
Anaconda的安装(Windows):
- 进入清华大学Anaconda开源镜像源,进行下载,也可以选择Miniconda。地址
- 选择适合版本,这里选择:Miniconda3-py37_4.8.2-Windows-x86_64。
- 自定义安装,安装完成后在开始菜单,选择Anaconda Prompt命令即可运行Anaconda。
Miniconda的安装(Ubuntu):
sh Miniconda3-4.6.14-Linux-x86_64.shMiniconda的卸载(Ubuntu):
- 将miniconda3文件夹删除。
- 修改.bashrc文件,删除conda的信息。
- 重新打开终端,完成卸载。
Miniconda的无法使用(Ubuntu):
vim ~/.bashrc export PATH=/root/miniconda3/bin:$PATH source ~/.bashrc
Anaconda的使用:Anaconda其实是一个打包集合,里面预装好了conda、某个版本的Python、众多包及科学计算工具等。对于Anaconda的使用,其实就是对conda的使用。conda可以理解为一个工具(或者是可执行的命令),其核心功能为第三方库(包)和环境的管理。
(1)包管理
- 首先运行Anaconda,查看Python版本。命令:python。
- 通过conda list命令可以查看安装的包。命令:conda list。
- 通过conda命令可以进行包的安装和卸载,也可以通过pip命令进行打包的安装和下载。
-i https://pypi.tuna.tsinghua.edu.cn/simple(2)环境管理
conda的环境管理功能允许开发者同时安装若干不同版本的Python。对于不同的项目而言,使用独立稳定的Python很重要,以下就是安装Python环境的命令。
conda create --name data-analysis python=3.10创建环境成功后,可通过activate data-analysis命令进入该环境中,通过conda deactivate退出该环境。
activate test查看创建的环境
conda info -e删除conda环境
conda remove --name data-analysis --all(3)切换清华源:临时
pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple some-package(3)切换清华源:永久
vim ~/.condarcchannels: - http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ - http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ - http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/ show_channel_urls: true default_channels: - http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main - http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r - http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2 custom_channels: conda-forge: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud msys2: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud bioconda: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud menpo: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud pytorch: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud pytorch-lts: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud simpleitk: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud(4)恢复默认
conda config --show channels conda config --remove-key channels

3.2,Jupyter Notebook
Jupyter Notebook是一个交互式的在线编辑器,它可以每编辑一行代码就运行该代码,并将运行结果显示在该代码的下方,以方便用户查看。对于数据分析而言,Jupyter Notebook的最大优势是可以重现整个数据分析过程。
Jupyter Notebook本质上是一个支持实时代码、数学方程式、可视化和Markdown的Web应用程序。它允许用户创建和共享包含代码、方程式、可视化和文本的文档。它的用途:数据清理和转换、数值建模、统计建模、数据可视化、机器学习等。它的优势:
- 可选择语言:支持超过40种编程语言,包括Python、R、Julia、Scala等。
- 分享笔记本:可以使用电子邮件、Dropbox、GitHub和Jupyter Notebook Viewer与他人共享。
- 交互式输出:代码可生成丰富的交互输出,包括HTML、图像、视频、LaTex等。
- 大数据整合:通过Python、R、Scala编程语言使用Apache Spark等大数据框架工具。
Jupyter Notebook的安装:Ipython Notebook是一个性能强大的Python终端,Ipython Notebook是集文本、代码图像和公式的展现于一体的超级Python Web界面。但是Ipython Notebook从4.0开始被改名为Jupyter Notebook,换句话说,Jupyter Notebook是由Ipython Notebook发展而来的,其本质上是在本地搭建了一个Jupyter Notebook的服务器。程序员在前端编辑代码,然后把代码块提交给本地的Python解释器执行,最后再把输出的信息回传给前端显示出来。所以,为了能使用Jupyter Notebook,必须首先在后台运行JupyterNotebook的服务器。
Anaconda自带Jupyter,如果使用Miniconda或者不使用Anaconda可以使用如下代码安装:
(data-analysis) C:\Users\Bing>conda install jupyter启动Jupyter Notebook
(data-analysis) C:\Users\Bing>Jupyter Notebook [I 15:45:53.905 NotebookApp] Writing notebook server cookie secret to C:\Users\Bing\AppData\Roaming\jupyter\runtime\notebook_cookie_secret [I 15:45:54.478 NotebookApp] Serving notebooks from local directory: C:\Users\Bing [I 15:45:54.479 NotebookApp] Jupyter Notebook 6.4.3 is running at: [I 15:45:54.480 NotebookApp] http://localhost:8888/?token=a1e7150e733a343845eb7660fefffeb6fa5b59c955990fde [I 15:45:54.481 NotebookApp] or http://127.0.0.1:8888/?token=a1e7150e733a343845eb7660fefffeb6fa5b59c955990fde [I 15:45:54.481 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [C 15:45:54.491 NotebookApp] To access the notebook, open this file in a browser: file:///C:/Users/Bing/AppData/Roaming/jupyter/runtime/nbserver-10532-open.html Or copy and paste one of these URLs: http://localhost:8888/?token=a1e7150e733a343845eb7660fefffeb6fa5b59c955990fde or http://127.0.0.1:8888/?token=a1e7150e733a343845eb7660fefffeb6fa5b59c955990fde E:\Miniconda3\envs\data-analysis\lib\json\encoder.py:257: UserWarning: date_default is deprecated since jupyter_client 7.0.0. Use jupyter_client.jsonutil.json_default. return _iterencode(o, 0)
导入虚拟环境
- 创建python虚拟环境
conda create -n learn python=3.6 --learn:虚拟环境变量 --3.6:python版本
- 激活环境
conda activate learn --learn:虚拟环境名字
- 安装ipykernel
conda install ipykernel
- 查看可关联的环境
jupyter kernelspec list Available kernels: python3 E:\Miniconda3\envs\data-analysis\share\jupyter\kernels\python3
- 内核关联环境
python -m ipykernel install --user --name learn1 --display-name "learn2" --learn1:Anaconda的虚拟环境名 --learn2:Jupyter的Python环境名
- 删除内核
jupyter kernelspec remove learn1
- Jupyter中切换环境
配置 Jupyter Notebook
#切换回基础环境 activate base #创建/显示jupyter notebook配置文件 jupyter notebook --generate-config Writing default config to: C:\Users\shao12138\.jupyter\jupyter_notebook_config.py打开文件,修改
c.NotebookApp.notebook_dir = '' 默认目录位置 c.NotebookApp.iopub_data_rate_limit = 100000000 这个改大一些否则有可能报错
4,大数据问题
针对海量数据的数据处理,可以使用的方法非常多,常见的方法有Hash(字典)法、Bit-map(位图)法、Bloom filter法、数据库优化法、倒排索引法、外排序法、Trie数、堆、双层桶法以及MapReduce法等。
布隆过滤器:布隆过滤器实际上是一个很长的二进制向量和一系列随机的哈希函数。在存储数据时,将数据分别通过多个哈希函数映射成不同的位,在查找数据时,将需要查找的数据同样通过这些哈希函数进行映射,若所有的位都被标记,则表示该数据可能存在于集合中,否则则可以确定该数据不存在于集合中。布隆过滤器主要用于判断一个元素是否存在于一个集合中以及对大规模数据进行快速检索,比如判断一个URL是否已经被爬虫爬取过等。它的优点是空间效率和查询时间都比一般的算法要好得多,但缺点是有一定的误识别率和删除困难。
4.1,读取超量内存数据
【问题】只有4GB内存怎么读取一个5GB的数据?
【方法一】可以通过生成器,分多次读取,每次读取数量相对少量的数据(500MB)进行处理,处理结束后在读取后面的500MB。
【方法二】可以通过Linux命令split切割成小文件,然后再对数据进行处理,此方法效率比较高。可以按照行数切割,可以按照文件大小切割。在Linux下可以使用cat命令进行合并。
【方法三】利用虚拟内存技术(例如mmap)将数据映射到磁盘上,然后通过访问磁盘的方式来处理数据,避免将整个数据加载到内存中。
4.2,如何从大量的url中找出相同的url
【问题】给定a、b两个文件,各存放50亿个url,每个url各占64B,内存限制是4GB,请找出a、b两个文件共同的url。
【方法】由于每个url需要占64B,所以50亿个url占用的空间大小为50亿*64=5GB*64=320GB。由于内存大小只有4GB,因此不可能一次性把所有的url都加载到内存中处理。可以采用分治法,即把一个文件中的url按照某个某一个特征分成多个文件,使得每个文件的内容都小于4GB。
- 遍历文件a,对遍历到的 ulr 求 hash(url)%500,根据计算结果把遍历到的url分别存储到a0,a1,...,a499,这样每个文件大小约600MB。
- 使用同样方法遍历文件b,把文件 b 中的 url 分别存储到文件b0,b1,b2,...,b499中。这样处理后,所有可能相同的url都被保存在对应的小文件(a0-b0,a1-b1,...,a499-b499)中,不对应的小文件不可能有相同的url。然后我们只要求出这个1000对小文件中相同的url即可。
- 通过上面的划分,与ai中url相同的url一定在bi中。如果url在hash_set中存在,那么说明这个url是这两个文件共同的url,可以把这个url保存到另外一个单独的文件中。当把文件a0~a499都遍历完成后,就找到两个文件的共同url。
4.3,如何从大量数据中找出高频词
【问题】有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,要求返回频数最高的100个词。
【方法】由于文件代销为1GB,而内存大小只有1MB,因此不可能一次把所有的词读入到内存中处理,因此也需要采用分治方法,把一个大的文件分解成多个小文件,从而保证每个文件的大小都小于1MB,进而可以直接被读取到内存中处理。
- 遍历文件,对遍历到的每一个词,执行如下Hash操作:hash(x)%2000,将结果为i的词存放到文件ai中,通过这个分解步骤,可以使每个字文件大小约为400KB左右。
- 统计出每个文件中出现频率最高的100个词。最简单的方法就是使用字典来实现,具体实现方法为,遍历文件中的所有词,对遍历到的词,如果字典中不存在,那么把这个词存入字典中,如果这个词在字典中存在,那么这个词对应的值+1。遍历完后可以非常容易地找出出现频率最高的10个词。
- 第2步找出了每个文件出现频率最高的100个词,这一步可以通过维护一个小顶堆来找出所有词中出现频率最高的100个。具体方法为,遍历第一个文件,把第一个文件中出现最高的100个词构建成一个小顶堆。(如果第一个文件中词小于100,那么可以继续遍历第2个文件,直到构建好有100 个结点的小顶堆为止)。继续遍历,如果遍历到的词出现次数大于堆顶上词出现次数,那么可以用新遍历到底的词替换堆顶的词,然后重新调整这个堆为小顶堆。当遍历完所有文件后,这个小顶堆中的词就是出现频率最高的100个词。当然这一步也可以采用类似归并排序的方法把所有文件中出现频率最高的100个词排序,最终找出频率最高的100个词。
4.4,如何在大量的数据中找出不重复的整数
【问题】在2.5亿个整数中找出不重复的整数,内存不足以容纳所有数据。
【方法一:分治法】分治法:采用Hash的方法,把这2.5亿个数划分到更小的文件中,从而保证每个文件的大小不超过可用的内存大小。然后对于每个小文件而言,所有的数据可以一次性被加载到内存中,因此可以使用字典或set来找到每个小文件中不重复的数。当处理完所有的文件后就可以找出这2.5亿个整数中所有的不重复的数。
【方法二:位图法】对于整数相关的算法的求解,位图法是一种非常实用的算法。对本道题而言,如果可用的内存空间超过1GB就可以使用这个方法。具体思路:假设整数占用4GB,4B也就是32位,可用表示的整数的个数为2^32。可用使用2bit表示各个数字的状态:用00表示这个数字没有出现过,01表示出现过1次,10表示出现了多次,11不使用。
根据上面逻辑,再遍历这2.5亿个整数的时候,如果这个整数对应的位图中的位为00,那么修改成01,如果为01那么修改为10,如果为10那么保持原值不变。这当所有的数据遍历完成后,可以再遍历一遍位图,位图中为01的对应数字就是没有重复的数字。
4.5,如何在大量的数据中判断一个数是否存在
【问题】在2.5亿个整数中找出不重复的整数,内存不足以容纳这2.5亿个整数。
【方法一:分治法】对于大数据相关的算法,分治法是一个非常好的方法。主要思路:可以根据实际可用内存的情况,确定一个Hash函数,例如hash(value)%1000,通过这个Hash函数可以把2.5亿个数字划分为1000个文件中(a1,a2,...,a1000),然后再对待查找的数字使用相同的Hash函数求出Hash值,假设计算出Hash值为i,如果这个数存在,那么它一定在文件ai中。通过这种方法就可以把题目的问题转换为文件ai中是否存在这个数。那么在接下来的求解过程中可以选用的思路比较多,如下所示:
- 由于划分后的文件比较小了,可以直接被装载到内存中,可以把文件中所有的数字都保存到hash_set中,然后判断待查找的数字是否存在。
- 如果这个文件中的数字占用的空间还是太大,那么可以用相同的方法把这个文件继续划分为更小的文件,然后确定待查找的数字可能存在的文件,然后在响应的文件中继续查找。
【方法二:位图法】对于这类判断数字是否存在、判断数字是否重复的问题,位图法是一种非常高效的方法。这里以32位整型为例,它可以表示数字的个数为2^32。可以申请一个位图,让每个整数对应位图中的一个bit,这样2^32个数需要位图的大小为512MB。具体实现的思路:申请一个512MB大小的位图,并把所有的位都初始化为0;接着遍历所有的整数,对遍历到的数字,把相应位置上的bit设置为1。最后判断待查找的数对应的位图上的值是多少,如果是0,那么表示这个数字不存在,如果是1,那么表示这个数字存在。
4.6,如果查询最热门的查询串
【问题】搜索引擎会通过日志文件把用户每次检索使用的所有查询串都记录下来,每个查询串的长度为1~255B。
【假设】目前有1000万个记录(这些查询串的重复度比较高,虽然总数是1000万,但如果除去重复后那么不超过300万个。一个查询串的重复读越高,说明查询的用户越多,也就越热门),请统计最热门的10个查询串,要求使用的内存不能超过1GB。
【方法一:分治法】对字符串设置一个Hash函数,通过这个Hash函数把所字符串划分到更多更小的文件中,从而保证每个小文件中的字符串都可以直接被加载到内存中处理,然后求出每个文件中出现次数最多的10个字符串;最后通过一个小顶堆统计出所有文件中出现最多的10个字符串。从功能角度出发,这种方法是可行的,但是由于需要对文件遍历两遍,而且Hash函数也需要被调用1000万次,所以性能不是很好。
【方法二:字典法】虽然字符串的总数比较多,但是字符串的种类不超过300万个,因此可以考虑把所有字符串出现的次数保存在一个字典中(键值为字符串,值为字符串出现的次数)。字典所需要的空间为300万*(255+4)=3MB*259=777MB(其中,4表示用来记录字符串出现次数的整数占用4B)。由此可见1G的内存空间是足够用的。
- 遍历字符串,如果字符串在字典中不存在,那么直接存入字典中,键为这个字符串,值为1.如果字符串在字典中已经存在了,那么把对应的值直接加1。这一步操作的时间复杂度为O(N),其中N为字符串的数量。
- 在第一步的基础上找出出现频率最高的10个字符串。可以通过小顶堆的方法来完成,遍历字典的前10个元素,并根据字符串出现的次数构建一个个小顶堆,然后接着遍历字典,只要遍历到字符串的出现次数大于堆顶字符串的出现次数,就用遍历的字符串替换堆顶的字符串,然后把堆调整为小顶堆。
- 对所有剩余的字符串都遍历一遍,遍历完成后堆中的10个字符就是出现次数最多的字符串。这一步时间复杂度为O(Nlog10)。
【方法三:trie树法】方法二中使用字典来统计每个字符串出现的次数。当这些字符串有大量相同前缀的时候,可以考虑使用trie树来统计字符串出现的次数。可以在树的结点中保存字符串出现的次数加1,否则这个字符串构建新的结点,构建完成后把叶子结点中字符串的出现次数设置为1。这样便利完成字符串后就可以直接到每个字符串出现次数,然后通过遍历这个树就可以找出出现次数最多的字符串。trie树经常被用来统计字符串的出现次数。它的另外一个大的用途就是字符串查找,判断是否有重复的字符串等。
4.7,如何统计不同电话号码的个数
【问题】已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
【方法】本质是求解数据重复的问题,对于这类问题,一般而言,首先会考虑位图法。8位电话号码可以表示的范围是:00000000~99999999,如果用1bit来表示一个号码,那么总共需要1亿个bit,总共需要大约100MB内存。因此可以申请一个位图并初始化为0,然后遍历所有电话号码,把遍历到的电话号码对应的位图中的bit设置为1。当遍历完成后,如果bit值为1,那么表示这个电话号码在文件中存在,否则这个bit对应的电话号码在文件中不存在。所以bit值为1的数量即为不同电话号码的个数。
最核心的算法是如何确定电话号码对应的是位图中的哪一位:
- 00000000对应位图最后一位:0x00000...000000000001。
- 00000001对应位图最后一位:0x00000...000000000010。
- 00000012对应位图最后一位:0x00000...100000000000。
通常而言,位图都是通过一个整数数组来实现的(假设一个整数占用32bit)。由此可以得出通过电话号码获取位图中对应位置的方法如下(电话号码为P):
- 通过P/32就可以计算出该电话号码在bitmap数组的下标。(因为每个整数占用32bit,通过这个公式就可以确定这个电话需要移动多少个32位,也就是可以确定它对应的bit在数组中的位置。)
- 通过P%32就可以计算出这个电话号码在这个整形数字中具体的bit的位置,也就是1这个数字对应的左移次数。因此可以通过把1左移P%32位然后把得到的值与这个数组中的值做或运算,这样就可以把这个电话号码在位图中对应的为位置1。
4.9,如何从5亿个数中找出中位数
如果这道题目没有内存大小的限制,则可以把所有的数字排序后找出中位数,但是最好的排序算法的时间复杂度都是 O(NlogN)(N 为数字的个数)。这里介绍另外一种求解中位数的算法——双堆法。
【方法一:双堆法】
这个算法的主要思路是维护两个堆,一个大顶堆,一个小顶堆,且这两个堆需要满足如下两个特性。
- 特性一:大顶堆中最大的数小于或等于小顶堆中最小的数。
- 特性二:保证这两个堆中的元素个数的差不能超过 1。
若数据总数为偶数时,当这两个堆建立好以后,中位数显然就是两个堆顶元素的平均值。当数据总数为奇数时,根据两个堆的大小,中位数一定在数据多的堆的堆顶。对本题而言,具体实现思路:维护两个堆 maxHeap 与 minHeap,这两个堆的大小分别为 max_size 和 min_size,然后开始遍历数字。对于遍历到的数字 data:
1)如果 data<maxHeap 的堆顶元素,此时为了满足特性 1,只能把 data 插入到 maxHeap 中。为了满足特性二,需要分以下几种情况讨论。
- ① 如果 max_size≤min_size,则说明大顶堆元素个数小于小顶堆元素个数,此时把 data 直接插入大顶堆中,并把这个堆调整为大顶堆。
- ② 如果 max_size>min_size,为了保持两个堆元素个数的差不超过 1,则需要把 maxHeap 堆顶的元素移动到 minHeap 中,接着把 data 插入到 maxHeap 中。同时通过对堆的调整,分别让两个堆保持大顶堆与小顶堆的特性。
2)如果 maxHeap 堆顶元素 ≤data≤minHeap 堆顶元素,则为了满足特性一,可以把 data 插入任意一个堆中,为了满足特性二,需要分以下几种情况讨论:
- ① 如果 max_size<min_size,显然需要把 data 插入到 maxHeap 中;
- ② 如果 max_size>min_size,显然需要把 data 插入到 minHeap 中;
- ③ 如果 max_size==min_size,可以把 data 插入到任意一个堆中。
3)如果 data>maxHeap 的堆顶元素,此时为了满足特性一,只能把 data 插入到 minHeap 中。为了满足特性二,需要分以下几种情况讨论:
- ① 如果 max_size≥min_size,那么把 data 插入到 minHeap 中;
- ② 如果 max_size<min_size,那么需要把 minHeap 堆顶元素移到 maxHeap 中,然后把 data 插入到 minHeap 中。
通过上述方法可以把 5 亿个数构建成两个堆,两个堆顶元素的平均值就是中位数。由于需要把所有的数据都加载到内存中,当数据量很大时,因为无法把数据一次性加载到内存中,因此这种方法比较适用于数据量小的情况。对本题而言,5 亿个数字,每个数字在内存中占 4B,5 亿个数字需要的内存空间为 2GB 内存。当可用的内存不足 2GB 时,显然不能使用这种方法,下面介绍另外一种方法。
【方法二:分治法】分治法的核心思想是把一个大的问题逐渐转换为规模较小的问题来求解。对于本题而言,顺序读取这 5 亿个数字;
- 对于读取到的数字 num,如果它对应的二进制中最高位为 1,则把这个数字写入到 f1 中,如果最高位是 0,则写入到 f0 中。通过这一步就可以把这 5 亿个数字划分成两部分,而且 f0 中的数字都大于 f1 中的数字(因为最高位是符号位)。
- 通过上面的划分很容易知道中位数是在 f0 中还是在 f1 中。假设 f1 中有 1 亿个数,那么中位数一定在文件 f0 中,且它的值为 f0 文件中的数字排序的第 1.5 亿个数与它后面一个数的平均值。
- 对于 f0,可以用次高位的二进制的值继续把这个文件一分为二,使用同样的思路可以确定中位数是哪个文件中的第几个数。直到划分后的文件可以被加载到内存时,把数据加载到内存中以后排序,从而找出中位数。
需要注意的是,这里有一种特殊情况需要考虑,当数据总数为偶数时,如果把文件一分为二后发现两个文件中的数据有相同的个数,那么中位数就是 f0 文件中的最大值与 f1 文件中的最小值的平均值。如果要求一个文件中所有数据的最大值或最小值,可以使用前面介绍的分治法进行求解。
4.10,如何对 100 亿数据进行排序?
【问题】内存只有 2G,如何对 100 亿数据进行排序?
【方法1】将存储着 100 亿数据的文本文件一条一条导入到数据库中,然后根据某个字段建立索引,数据库进行索引排序操作后我们就可以依次提取出数据追加到结果集中。这种方法的特点就是操作简单, 运算速度较慢,对数据库设备要求较高。
【方法2】分治法(外部排序):
- 把这个 37 GB 的大文件,用哈希或者直接平均分成若个小文件(比如 1000 个,每个小文件平均 38 MB 左右)。
- 拆分完了之后,得到 1000 个 30 多 MB 的小文件,那么就可以放进内存里排序了,可以用快速排序,归并排序,堆排序等等。
- 1000 个小文件内部排好序之后,就要把这些内部有序的小文件,合并成一个大的文件,可以用堆排序来做 1000 路合并的操作(假设是从小到大排序,用小顶堆):
首先遍历 1000 个文件,每个文件里面取第一个数字,组成
(数字, 文件号)这样的组合加入到堆里,遍历完后堆里有 1000 个(数字,文件号)这样的元素。然后不断从堆顶 pop 元素追加到结果集,每 pop 一个元素,就根据它的文件号去对应的文件里,补充一个元素进入堆中,直到那个文件中的元素被拿完。
按照上面的操作,直到堆被取空了,此时最终结果文件里的全部数字就是有序的了。
【方法3】位图法(Bitmap):对于 100 亿个 32 位整数,我们可以将它们分为 2^32 个不同的桶中。每个桶对应一个二进制位,我们可以用一个位图来表示这些桶。位图中的每个二进制位都表示一个桶是否存在数据。例如,第 i 个二进制位为 1 表示第 i 个桶中存在数据,为 0 表示第 i 个桶中不存在数据。然后,我们可以使用桶排序算法对位图进行排序。由于位图中只有 0 和 1 两种值,因此桶排序的时间复杂度为 O(1)。最后,将排序后的位图转换回原来的数字序列。这可以通过按位遍历位图来实现。例如,对于第 i 个二进制位为 1 的桶,我们可以将所有在该桶中的数字输出到结果序列中。需要注意的是,位图法需要额外的空间来存储位图,但由于位图压缩效果很好,所需的空间相对较小,因此在内存受限的情况下,位图法是一种非常有效的排序算法。
4.11,如何找出排名前500的数
【问题】有 20 个数组,每个数组有 500 个元素,并且有序排列。如何在这 20*500 个数中找出前 500 的数?
【方法】对于 TopK 问题,最常用的方法是使用堆排序。对本题而言,假设数组降序排列,可以采用以下方法:
- 首先建立大顶堆,堆的大小为数组的个数,即为 20,把每个数组最大的值存到堆中。
- 接着删除堆顶元素,保存到另一个大小为 500 的数组中,然后向大顶堆插入删除的元素所在数组的下一个元素。
- 重复上面的步骤,直到删除完第 500 个元素,也即找出了最大的前 500 个数。
为了在堆中取出一个数据后,能知道它是从哪个数组中取出的,从而可以从这个数组中取下一个值,可以把数组的指针存放到堆中,对这个指针提供比较大小的方法。
import lombok.Data; import java.util.Arrays; import java.util.PriorityQueue; @Data public class DataWithSource implements Comparable<DataWithSource> { /** * 数值 */ private int value; /** * 记录数值来源的数组 */ private int source; /** * 记录数值在数组中的索引 */ private int index; public DataWithSource(int value, int source, int index) { this.value = value; this.source = source; this.index = index; } /** * * 由于 PriorityQueue 使用小顶堆来实现,这里通过修改 * 两个整数的比较逻辑来让 PriorityQueue 变成大顶堆 */ @Override public int compareTo(DataWithSource o) { return Integer.compare(o.getValue(), this.value); } } class Test { public static int[] getTop(int[][] data) { int rowSize = data.length; int columnSize = data[0].length; // 创建一个columnSize大小的数组,存放结果 int[] result = new int[columnSize]; PriorityQueue<DataWithSource> maxHeap = new PriorityQueue<>(); for (int i = 0; i < rowSize; ++i) { // 将每个数组的最大一个元素放入堆中 DataWithSource d = new DataWithSource(data[i][0], i, 0); maxHeap.add(d); } int num = 0; while (num < columnSize) { // 删除堆顶元素 DataWithSource d = maxHeap.poll(); result[num++] = d.getValue(); if (num >= columnSize) { break; } d.setValue(data[d.getSource()][d.getIndex() + 1]); d.setIndex(d.getIndex() + 1); maxHeap.add(d); } return result; } public static void main(String[] args) { int[][] data = { {29, 17, 14, 2, 1}, {19, 17, 16, 15, 6}, {30, 25, 20, 14, 5}, }; int[] top = getTop(data); System.out.println(Arrays.toString(top)); // [30, 29, 25, 20, 19] } }

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 2
2 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)