
初探神经网络(二)单层感知机的Rosenblatt算法原理
本期大量干货,配合线性代数和较扎实的统计知识食用更佳。介绍过了M-P模型,也了解到了M-P模型本质上是对生物上神经元的抽象模型。在上一章,我反复在强调这只是一个生物学的概念,我相信看到这篇文章的人绝大多数并不是生物科技行业的从业人员,爱好数据科学以及以数据科学为业的读者居多。看完了全文除了一些近似抽象化的数学知识,似乎和数据没什么关联。现在的我在学习新知识时,很喜欢结合那些知识总结成册时,当时提出
本期大量干货,配合线性代数和较扎实的统计知识食用更佳。
介绍过了M-P模型,也了解到了M-P模型本质上是对生物上神经元的抽象模型。在上一章,我反复在强调这只是一个生物学的概念,我相信看到这篇文章的人绝大多数并不是生物科技行业的从业人员,爱好数据科学以及以数据科学为业的读者居多。看完了全文除了一些近似抽象化的数学知识,似乎和数据没什么关联。现在的我在学习新知识时,很喜欢结合那些知识总结成册时,当时提出理论的科学家的视角,了解他们是为了解决什么实际需求而进行了相依的研究。我们在课本上往往看到复杂知识点或者概念或者公理(注意不是定理)都会介绍一些当时的历史背景,小时候只当这是废话,当故事一样的看,连一些提及的导引知识点也一眼带过,懒得用黄色荧光笔再划出来。
渐渐长大,发现了解过背景知识之后,学习之余不再感到枯燥,也因为了解过概念的提出和推导过程,学习过程平铺直叙,变得更加容易融会贯通。这一章节,关于单层感知机,也会从背景出发,只不过这一次主舞台渐渐离开了生物科学,转向了机器学习领域。神经网络一词被提出,在一阵阵关于神经网络的务实探索和无脑鼓吹的风口下,神经网络曾经也一度成为那个没有热搜的时代下屡屡在学术界被提及的热词。浮华褪去,技术不完备理论知识支撑不足,单层感知机的缺陷逐渐暴露出来,最终被Marvin Lee Minsky提出的XOR问题打上一道封印,一盆冷水直浇飘零火焰的根部,这是一条在当时看来几乎不可逾越的鸿沟。本篇文章会在必要的硬核理论推导中,持续穿插神经网络发展的历史时刻。让你的学习过程不会太过枯燥。
1.感知机闪亮登场
1957年,美国心理学家Frank Rosenblatt提出一种具有单层计算单元的神经网络,称为感知机(Perceptron)。这是第一次M-P模型脱离于生物学概念正式进入了人工智能领域。Rosenblatt在一台IBM 704计算机上模拟实现了一种他提出的叫做“感知机”(Perceptron)的神经网络模型,这个模型看似只是简单地把一组M-P模型平铺排列在一起,但是它再配合上赫布法则,就可以做到不依靠人工编程,仅靠机器学习来完成一部分的计算机视觉和模式识别方面的任务,只因为传递信号的此时不再是固定的信号大小,即 “来自第 iii 个神经元的输入”,记作xi′x_i'xi′ 。xi′x_i'xi′ 受到输入层被抽象化的单个或多个神经元影响,由它们来决定 xix_ixi 的大小。权重 wiw_iwi 仍然存在,只不过指向的是神经元之间的连接权重,接到多个上一层的神经元传输的兴奋或抑制信号,共同作用于这一神经元,但这个信号本身又受到其传入的信号影响,因为最底层的神经元接收到的信号并不来自神经元,而是常数 xix_ixi 。
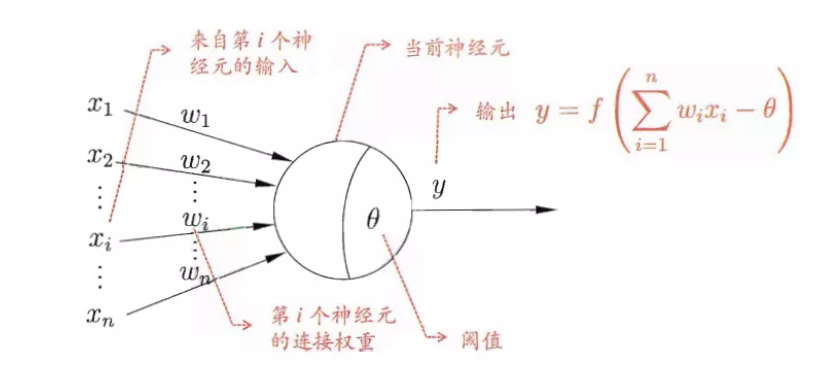
这就展现了一条独立于图灵机之外的,全新的实现机器模拟智能的道路。一个可能是“图灵机”级别的新成果,这光想想都令人激动,一下子引起科学界的关注,并且得到了以美国海军为首的多个组织的资助。它其实就是基于M-P模型的结构。我们可以看看它的拓扑结构图。

这个结构非常简单,如果你还记得前面所讲的M-P神经元的结构的话,这个图其实就是输入输出两层神经元之间的简单全连接(全连接表示任一层的任一神经元都和其他层的任一神经元存在连接)。
这是一次伟大的进步!
以现在的视角来看,会觉得只是从抽象化单个神经元的过程(即M-P模型),到有人抽象化了类似人体神经元之间信号传递的过程,可夸耀之处在于不仅设计了神经元的信号传递,更突破性的设想了不限于一对一,而是多对多的可能性。但这次探索我愿意比喻为一种“从静到动”,“从特殊推广到一般”的进步。
Pitts 和 McCulloch曾向人们展示了M-P神经元可以通过不同的连接方式和权重来实现逻辑与、或、非运算,Rosenblatt的感知机基本原理,就是利用了神经元可以进行逻辑运算特点,基于赫布法则,调整连接线上的权重和神经元上的阈值。Rosenblatt把一组神经元平铺排列起来,组合成为一个单层的神经元网络,经过学习阶段调整权重,便可实现根据特定特征对输入数据进行分类。不过这种分类只能做到线性分割——即感知机可以应用的前提条件,必须是输入的数据集在特定特征下是线性可分的。
那么我们跳出生物学的M-P模型,将它的拓扑模型应用到逻辑运算中,实现如下:
首先不考虑任何推导和合并过程,我们直接引用现成的衡量标准,即依靠∑\sum∑以及θj\theta_jθj之间的大小关系来衡量,上章已经推导过,公式如下:
∑i=1nwijxi−θj\sum_{i=1}^{n} w_{ij}x_i - \theta_j i=1∑nwijxi−θj
![M-P模型实现逻辑运算][tmp1-3]
也明确过M-P模型的 xix_ixi 和 wiw_iwi 都是量化后的确定常数,那么我们赋值:
令w1=w2=1w_1 = w_2 = 1w1=w2=1,θ=2\theta=2θ=2,则 yj=f(1×x1+1×x2−2)y_j = f(1×x_1+1×x_2-2)yj=f(1×x1+1×x2−2),仅在 x1=x2x_1=x_2x1=x2 时,才有 y=1y=1y=1 ,否则 y=0y=0y=0 ,即“逻辑与”的效果。
令w1=w2=1w_1 = w_2 = 1w1=w2=1,θ=0.5\theta=0.5θ=0.5,yj=f(1×x1+1×x2−0.5)y_j = f(1×x_1+1×x_2-0.5)yj=f(1×x1+1×x2−0.5),仅在 x1=1x_1=1x1=1 或者 x2=1x_2=1x2=1 时,才有 y=1y=1y=1 ,否则 y=0y=0y=0,即“逻辑或”的效果。
令 w1=−0.6w_1=-0.6w1=−0.6,w2=0w_2=0w2=0,θ=−0.5\theta=-0.5θ=−0.5,则 y=f(−0.6×x1+0×x2+0.5)y=f(-0.6×x_1+0×x_2+0.5)y=f(−0.6×x1+0×x2+0.5) ,那 x1=1x_1=1x1=1 时,有 y=0y=0y=0 ,那 x1=0x_1=0x1=0 时,有 y=1y=1y=1 ,即“逻辑非”的效果。
我为什么会说这是一个从特殊到一般的过程呢?虽然分类任务的本质并未改变,但感知机的出现是对M-P神经元的重排和有机结合,就好像方程到函数的进步,推广到一般之后,一切都将豁然开朗。
感知机的学习机制如下:
- 对权值参数 wiw_iwi 初始化
- 将训练集的一个输入值传递到输入层,通过感知机计算输出值(-1或+1)
- 比较感知机计算的输出值和真实的输出值是否相同,若输出值小于期望值,则向输出值更大的方向增加权重,反之亦然
- 对训练集中下一个输出值重复步骤2,步骤3,直到感知机不再出错
以上的学习机制还暂时不需要你立刻理解它的实现逻辑,因为中间缺失的知识点很多,先亮明学习机制,目的在于让你从实际的运行过程中对感知机有一个最初步的了解。所以不需要在这里有太长思维上的逗留,在你度过下面的介绍和推导后,希望你回头再看这段学习机制,相信你会有不一样的见解。(这种感觉可能类比学生时代很喜欢先看看一本书最后面的章节知识,再从头读时会时不时迸发出“哦哦,那个细节原来是这个基础知识延申而来的”,这种感觉让我不断在学习中被激励。)
2.Rosenblatt算法
介绍Rosenblatt算法之前,有必要补充一点从M-P模型到单层感知机之间的过渡知识。单层感知机主要用于解决线性可分的两类问题,认为规定两类分别记为{-1,+1},此时:
yk=f(netj)=sgn(netj)={−1(netj<0)+1(netj⩾0)y_k = f(net_j) = sgn(net_j) = \left\{ \begin{aligned} -1 &&(net_j < 0) \\ +1 && (net_j \geqslant 0) \end{aligned} \right. yk=f(netj)=sgn(netj)={−1+1(netj<0)(netj⩾0)
其中:netj=∑i=1nwijxi−θj其中: net_j = \sum_{i=1}^{n} w_{ij}x_i - \theta_j其中:netj=∑i=1nwijxi−θj
如果说和上一章的公式:
yj={受到刺激(netj⩽0)无反应(netj>0) y_j=\left\{ \begin{aligned} 受到刺激 &&(net_j \leqslant 0) \\ 无反应 && (net_j > 0) \end{aligned} \right. yj={受到刺激无反应(netj⩽0)(netj>0)
相比较而言,真的是没有太大的差别,加了一个符号函数sgn()变的更唬人了。事实上,直到单层感知机,要解决的始终都还是二分类的问题,关于单层感知机能否实现多分类任务,我们会在后面的部分再进行讨论。现在只需明确二分类的问题即可。
2.1 Rosenblatt感知机的更新过程
坐稳了,现在我们即将彻底脱离生物学的知识范畴,以数学,计算机科学和统计学的视角去审视这个伟大的拓扑模型。线性分类器的第一个迭代器学习算法是Fank Rosenblatt在1965年为感知机提出的,这个算法提出以后受到了很大的关注,下面我们看一下Rosenblatt算法最原始的形式。
给定线性可分的数据集S和学习率 η ϵ R+(R+\eta\ \epsilon\ ℝ^+(ℝ^+η ϵ R+(R+表示相应上标指示全体数字组成的集合) ,其中:w0← 0w_0 \leftarrow\ 0w0← 0 b0← 0b_0 \leftarrow\ 0b0← 0 k← 0k \leftarrow\ 0k← 0 R← max1⩽ i ⩽ l∥x∥R \leftarrow\ max_{1\leqslant\ i\ \leqslant\ l}\|x\|R← max1⩽ i ⩽ l∥x∥ 重复此步骤,实现过程伪代码:
for iii = 1 to lll
if yi((wk∗xi)+bk)⩽0y_i((w_k * x_i)+b_k) \leqslant 0yi((wk∗xi)+bk)⩽0 then
wk+1← wk+ηyixiw_{k+1} \leftarrow\ w_k + \eta y_ix_iwk+1← wk+ηyixi
bk+1← bk+ηyiR2b_{k+1} \leftarrow\ b_k + \eta y_iR^2bk+1← bk+ηyiR2
k=k+1k = k+1k=k+1
end if
end for
直到在for循环中没有错误发生,返回值为 (wk,bk)(w_k,b_k)(wk,bk),其中的 kkk 表示错误次数。
要不要这么恶心…这是些啥东西…
不着急,我们慢慢的理顺这个思想。毕竟时当时提出的论文内容,不管是思路上,还是实现过程,甚至使用的数学符号,都有些格格不入。引用某博主对此内容的一条批注:
算法思想就是对所有的样例,若有样例被误分,那么就会自动的调整权值向量和偏置向量,它会怎么调整呢? 对于输入中xix_ixi对应的权值wiw_iwi,
wi←wi+∗wiw_i \leftarrow w_i + *w_iwi←wi+∗wi
∗wi=a(t−o)xi*w_i = a(t - o) x_i∗wi=a(t−o)xi
ttt 代表当前样例 xxx 的目标输出, ooo 代表感知器的输出, aaa 是一个常数,成为学习速率,为了有一个直观的理解,我举一个例子,若感知器正确分类,则 (t−o)(t - o)(t−o)为零,权值 wiw_iwi 不会调整;若目标输出为+1,而感知器输出为-1,也就是感知器低估了目标输出,此时(t−o)(t-o)(t−o)为2,那么 wiw_iwi 会增加;反过来,若目标输出t为-1,感知器输出为+1,感知器高估了目标的输出,此时 (t−o)=−2(t - o) = -2(t−o)=−2,相应的 wiw_iwi 就会减少。这样,通过有限次的使用感知器训练法则,权重向量就会收敛到一个能正确分类的权向量了,当然这个学习速度a也要够小。
这段引用文字描述了感知机的训练和优化过程,在一次次的试错过程中,它根据和真实值的差值大小逐渐的向真实值逼近。文字简单易懂,但怎么严格证明这个方法能够在这个模型中实现呢?
首先我们定义输入数据,假设数据集来源于m维空间的总体 RmR^mRm ,每个样本由特征值和类别组成,样本集记为 XXX ,于是有:
X=(x1,l1),(x2,l2),(x3,l3),...,(xN,lN)={(xi,li)∣i=1,2,...,N}X = {(x^1,l^1),(x^2,l^2),(x^3,l^3),...,(x^N,l^N)} = \{(x^i,l^i)|i = 1,2,...,N\}X=(x1,l1),(x2,l2),(x3,l3),...,(xN,lN)={(xi,li)∣i=1,2,...,N}
xi=(x1,x2,...,xm) , li{−1,+1}x_i = (x^1,x^2,...,x^m)\ ,\ l^i \{-1,+1\}xi=(x1,x2,...,xm) , li{−1,+1}
现有样本 xkx^kxk 注入某感知机,得到∑i=1nwikxi−θk\sum_{i=1}^{n} w_{ik}x_i - \theta_k∑i=1nwikxi−θk,此处的上标 kkk 指代第 kkk 个使权重变化的刺激,而不是第 kkk 个样本。接着上一章的思路,我们把阈值符号包裹在 θ\thetaθ 内,看做是满足某常数的确定样本,目的是为了让上式更加简洁,也便于继续向M-P模型的推导结果靠拢,那么就有:
x^k=(1,xk)=(1,xk1,xk2,...,xmk)\hat{x}^k = (1,x^k) = (1,x_k^1,x_k^2,...,x_m^k)x^k=(1,xk)=(1,xk1,xk2,...,xmk)
w^k=(bk,wk)=(bk,wk1,wk2,...,wkm)\hat{w}_k = (b_k,w_k) = (b_k,w_{k1},w_{k2},...,w_{km})w^k=(bk,wk)=(bk,wk1,wk2,...,wkm)
即 netk=w^kTx^knet_k = \hat{w}_k^T\hat{x}^knetk=w^kTx^k
神经元受到来自 xkx^kxk 刺激后输出为:
yk=sgn(netk)={−1(netj<0)+1(netj⩾0)y_k = sgn(net_k) = \left\{ \begin{aligned} -1 &&(net_j < 0) \\ +1 && (net_j \geqslant 0) \end{aligned} \right. yk=sgn(netk)={−1+1(netj<0)(netj⩾0)
输出 yky_kyk 与实际类别 lkl^klk 比较,有以下四种情况:
- lk=+1,yk=+1l^k = +1,y^k = +1lk=+1,yk=+1,正确被分类,w^k+1=w^k\hat{w}_{k+1} = \hat{w}_{k}w^k+1=w^k
- lk=−1,yk=−1l^k = -1,y^k = -1lk=−1,yk=−1,正确被分类,w^k+1=w^k\hat{w}_{k+1} = \hat{w}_{k}w^k+1=w^k
- lk=+1,yk=+1l^k = +1,y^k = +1lk=+1,yk=+1,错误分类,w^k+1≠w^k\hat{w}_{k+1} \not= \hat{w}_{k}w^k+1=w^k
此时 netk=w^kTx^k⩽0net_k = \hat{w}_k^T\hat{x}^k \leqslant 0netk=w^kTx^k⩽0,调整 w^kT\hat{w}_k^Tw^kT 以使 netknet_knetk增大。设定学习率为某大于零小于1的常数,记为 η\etaη,有:
netk′=[w^k+ηx^k]x^k=w^kTx^k+η∥x^k∥2⩾w^kTx^k=netknet_k' = [\hat{w}_k + \eta\hat{x}^k]\hat{x}^k = \hat{w}_k^T\hat{x}^k + \eta\|\hat{x}^k\|^2 \geqslant \hat{w}_k^T\hat{x}^k = net_knetk′=[w^k+ηx^k]x^k=w^kTx^k+η∥x^k∥2⩾w^kTx^k=netk
因此可令 w^k+1=w^k+ηx^k\hat{w}_{k+1} = \hat{w}_k + \eta\hat{x}^kw^k+1=w^k+ηx^k,经过一次变化,感知机输出开始向真实值逼近。 - lk=+1,yk=+1l^k = +1,y^k = +1lk=+1,yk=+1,错误分类,w^k+1≠w^k\hat{w}_{k+1} \not= \hat{w}_{k}w^k+1=w^k
此时netk=w^kTx^k>0net_k = \hat{w}_k^T\hat{x}^k > 0netk=w^kTx^k>0,调整 w^kT\hat{w}_k^Tw^kT 以使 netknet_knetk减少。
netk′=[w^k+ηx^k]x^k=w^kTx^k+η∥x^k∥2⩽w^kTx^k=netknet_k' = [\hat{w}_k + \eta\hat{x}^k]\hat{x}^k = \hat{w}_k^T\hat{x}^k + \eta\|\hat{x}^k\|^2 \leqslant \hat{w}_k^T\hat{x}^k = net_knetk′=[w^k+ηx^k]x^k=w^kTx^k+η∥x^k∥2⩽w^kTx^k=netk
因此可令 w^k+1=w^k−ηx^k\hat{w}_{k+1} = \hat{w}_k - \eta\hat{x}^kw^k+1=w^k−ηx^k,经过一次变化,感知机输出开始向真实值逼近。
上述四种情况可合并为:
netklk=w^kTx^klk<0→w^k+1=w^k+ηx^klknet_kl^k = \hat{w}_k^T\hat{x}^kl^k <0 \rightarrow \hat{w}_{k+1} = \hat{w}_k + \eta\hat{x}^kl^knetklk=w^kTx^klk<0→w^k+1=w^k+ηx^klk
即异号表示预测与真实值不符,此时通过学习率调整权重,从w^k\hat{w}_kw^k调整至w^k+1\hat{w}_{k+1}w^k+1,其方向根据学习率决定靠拢真实值的程度,变化量为ηx^klk\eta\hat{x}^kl^kηx^klk,为便于整理和代码推导,记x^k′=x^klk{\hat{x}^k}' = \hat{x}^kl^kx^k′=x^klk。最终得到了在被激活函数处理前所有输入的值(并非感知机输出!!!),其结果为:
w^kTx^k′<0→w^k+1=w^k+ηx^k′\hat{w}_k^T{\hat{x}^k}' <0 \rightarrow \hat{w}_{k+1} = \hat{w}_k + \eta{\hat{x}^k}'w^kTx^k′<0→w^k+1=w^k+ηx^k′
当预测正确时,正常输出结果。
2.2 感知机的收敛性(Novikoff定理)
![感知机定义][tmp2-1]
抱歉直到现在才拿出一个规范的定义。我的讲述方式其实更希望能够对文章整体反复结合上下文去阅读,直接在开头抛出定义,会显得非常晦涩,也会缺乏和上文M-P模型部分的衔接内容。内容直接截取自李航的《统计学习方法》,感知机在描述中非常恰当,就是特征向量 xxx 和权重向量 www 加偏置 bbb 的值经过激活函数 sign()sign()sign() 最终输出结果。这个规范定义请大家牢记。
![Novikoff定理][tmp2-2]
Novikoff定理表明,对于线性可分数据集感知机学习算法原始形式收敛,即经过有限次迭代可以得到一个将训练数据集完全正确划分的分离超平面及感知机模型。Novikoff定理强调了线性可分数据集能够被单层感知机确定一个超平面将数据集完全正确分开,始终不要忘记,感知机学习的目标是求得一个能够将训练集正实例点和负实例点完全分开的分离超平面。
2.3 感知机的收敛原理
Rosenblatt感知器对于线性可分的两类问题总是有效的,但采用的方式与高斯分类器、逻辑回归、决策树还有支持向量机截然不同。那么能否保证它对所有线性可分的两类问题都能收敛?下面将利用夹逼定理对收敛性进行证明。
下界证明部分
已知在感知机误判的情况下,经过变化w^k+1=w^k+ηx^k\hat{w}_{k+1} = \hat{w}_k + \eta\hat{x}^kw^k+1=w^k+ηx^k可以使感知机输出向真实值方向逼近。现定义第 kkk 个刺激 x^k′{\hat{x}^k}'x^k′ 和它对应的权重 w^k\hat{w}_kw^k 共同影响权重 w^k+1\hat{w}_{k+1}w^k+1 ,那么就有:
w^2=w^1+ηx^1′\hat{w}_2 = \hat{w}_1 + {\eta\hat{x}^1}'w^2=w^1+ηx^1′
w^3=w^2+ηx^2′\hat{w}_3 = \hat{w}_2 + {\eta\hat{x}^2}'w^3=w^2+ηx^2′
w^4=w^3+ηx^3′\hat{w}_4 = \hat{w}_3 + {\eta\hat{x}^3}'w^4=w^3+ηx^3′
.........
w^n+1=w^n+ηx^n′,即w^n+1=w^1+η∑k=1n+x^k′\hat{w}_{n+1} = \hat{w}_n + {\eta\hat{x}^n}',即\hat{w}_{n+1} = \hat{w}_1 + \eta\sum_{k=1}^{n} + {\hat{x}^k}'w^n+1=w^n+ηx^n′,即w^n+1=w^1+ηk=1∑n+x^k′
因为样本线性可分,就有:∀x^i′,∃ w^∗∈Rm+1,w^∗Tx^i′>0\forall{\hat{x}^i}',\exist \ \hat{w}_*\inℝ^{m+1},\hat{w}_*^T {\hat{x}^i}' > 0∀x^i′,∃ w^∗∈Rm+1,w^∗Tx^i′>0
于是:w^∗T(w^n+1−w^n)=w^∗Tw^1+η∑k=1nw^∗Tx^k′−−−−⟶A=minw^∗Tx^k′>0\hat{w}_*^T(\hat{w}_{n+1} - \hat{w}_n) = \hat{w}_*^T \hat{w}_1 + \eta\sum_{k=1}^n \hat{w}_*^T {\hat{x}^k}' \stackrel{A = min\hat{w}_*^T {\hat{x}^k}'>0}{----\longrightarrow}w^∗T(w^n+1−w^n)=w^∗Tw^1+η∑k=1nw^∗Tx^k′−−−−⟶A=minw^∗Tx^k′>0
w^∗T(w^n+1−w^1)>w^∗Tw^1+η∑k=1nA=w^∗Tw^1+nηA\hat{w}_*^T(\hat{w}_{n+1} - \hat{w}_1) > \hat{w}_*^T \hat{w}_1 + \eta\sum_{k=1}^n A = \hat{w}_*^T \hat{w}_1 + n\eta Aw^∗T(w^n+1−w^1)>w^∗Tw^1+η∑k=1nA=w^∗Tw^1+nηA
其中,令A=minw^∗Tx^k′>0A = min\hat{w}_*^T {\hat{x}^k}'>0A=minw^∗Tx^k′>0:
根据柯西不等式,有:
∥w^∗∥2∥w^n+1−w^∗∥2⩾[w^∗T(w^n+1−w^∗)]2>(w^∗Tw^1+nηA)2=(w∗Tw^1)2+2w∗Tw^1(nηA)2\|\hat{w}_*\|^2\|\hat{w}_{n+1}-\hat{w}_*\|^2 \geqslant[\hat{w}_*^T(\hat{w}_{n+1} - \hat{w}_*)]^2 > (\hat{w}_*^T\hat{w}_1 + n\eta A)^2 = (w_*^T \hat{w}_1)^2 + 2w_*^T \hat{w}_1 (n\eta A)^2∥w^∗∥2∥w^n+1−w^∗∥2⩾[w^∗T(w^n+1−w^∗)]2>(w^∗Tw^1+nηA)2=(w∗Tw^1)2+2w∗Tw^1(nηA)2
记 a=w^∗Tw^1,b=∥w^∗∥a = \hat{w}_*^T\hat{w}_1,b = \|\hat{w}_*\|a=w^∗Tw^1,b=∥w^∗∥,那么有:
∥w^n+1−w^1∥2⩾(w^∗Tw^1)2+2w^∗Tw^1nηA+(nηA)2∥w^∗∥2=(ηAb)2n2+2aηAb2n+(ab)2\|\hat{w}_{n+1} - \hat{w}_1\|^2 \geqslant \frac{(\hat{w}_*^T\hat{w}_1)^2 + 2\hat{w}_*^T\hat{w}_1n\eta A + (n\eta A)^2}{\|\hat{w}_*\|^2} = (\frac{\eta A}{b})^2n^2 + \frac{2a \eta A}{b^2} n + (\frac{a}{b})^2∥w^n+1−w^1∥2⩾∥w^∗∥2(w^∗Tw^1)2+2w^∗Tw^1nηA+(nηA)2=(bηA)2n2+b22aηAn+(ba)2
因为 ∥w^∗∥2\|\hat{w}_*\|^2∥w^∗∥2 的值与方向有关,不妨令 b=∥w^∗∥=1b = \|\hat{w}_*\| = 1b=∥w^∗∥=1 ,则:
∥w^n+1−w^1∥2⩾(ηA)2+2aηAn+a2\|\hat{w}_{n+1} - \hat{w}_1\|^2 \geqslant (\eta A)^2 + 2a \eta A n + a^2∥w^n+1−w^1∥2⩾(ηA)2+2aηAn+a2
上界证明部分
同样的,有:
w^2=w^1+ηx^1′\hat{w}_2 = \hat{w}_1 + {\eta\hat{x}^1}'w^2=w^1+ηx^1′
w^3=w^2+ηx^2′\hat{w}_3 = \hat{w}_2 + {\eta\hat{x}^2}'w^3=w^2+ηx^2′
w^4=w^3+ηx^3′\hat{w}_4 = \hat{w}_3 + {\eta\hat{x}^3}'w^4=w^3+ηx^3′
.........
w^n+1=w^n+ηx^n′\hat{w}_{n+1} = \hat{w}_n + {\eta\hat{x}^n}'w^n+1=w^n+ηx^n′
等号左右同时减去一个 w∗^\hat{w_*}w∗^,处理之后,得到:
w^2−w∗^=(w^1−w∗^)+ηx^1′\hat{w}_2 - \hat{w_*} = (\hat{w}_1 - \hat{w_*})+ {\eta\hat{x}^1}'w^2−w∗^=(w^1−w∗^)+ηx^1′
w^3−w∗^=(w^2−w∗^)+ηx^2′\hat{w}_3 - \hat{w_*} = (\hat{w}_2 - \hat{w_*})+ {\eta\hat{x}^2}'w^3−w∗^=(w^2−w∗^)+ηx^2′
w^4−w∗^=(w^3−w∗^)+ηx^3′\hat{w}_4 - \hat{w_*} = (\hat{w}_3 - \hat{w_*})+ {\eta\hat{x}^3}'w^4−w∗^=(w^3−w∗^)+ηx^3′
.........
w^n+1−w∗^=(w^n−w∗^)+ηx^n′\hat{w}_{n+1} - \hat{w_*} = (\hat{w}_n - \hat{w_*})+ {\eta\hat{x}^n}'w^n+1−w∗^=(w^n−w∗^)+ηx^n′
对两边开平方,应用完全平方公式,得到:
∥w^2−w∗^∥2=∥w^1−w∗^∥2+2ηx^1′(w^1−w∗^)T+η2∥x^1′∥2\|\hat{w}_2 - \hat{w_*}\|^2 = \|\hat{w}_1 - \hat{w_*}\|^2 + 2{\eta\hat{x}^1}'(\hat{w}_1 - \hat{w_*})^T + \eta^2\|{\hat{x}^1}'\|^2∥w^2−w∗^∥2=∥w^1−w∗^∥2+2ηx^1′(w^1−w∗^)T+η2∥x^1′∥2
∥w^3−w∗^∥2=∥w^2−w∗^∥2+2ηx^2′(w^2−w∗^)T+η2∥x^2′∥2\|\hat{w}_3 - \hat{w_*}\|^2 = \|\hat{w}_2 - \hat{w_*}\|^2 + 2{\eta\hat{x}^2}'(\hat{w}_2 - \hat{w_*})^T + \eta^2\|{\hat{x}^2}'\|^2∥w^3−w∗^∥2=∥w^2−w∗^∥2+2ηx^2′(w^2−w∗^)T+η2∥x^2′∥2
∥w^4−w∗^∥2=∥w^3−w∗^∥2+2ηx^3′(w^3−w∗^)T+η2∥x^3′∥2\|\hat{w}_4 - \hat{w_*}\|^2 = \|\hat{w}_3 - \hat{w_*}\|^2 + 2{\eta\hat{x}^3}'(\hat{w}_3 - \hat{w_*})^T + \eta^2\|{\hat{x}^3}'\|^2∥w^4−w∗^∥2=∥w^3−w∗^∥2+2ηx^3′(w^3−w∗^)T+η2∥x^3′∥2
.........
∥w^n+1−w∗^∥2=∥w^n−w∗^∥2+2ηx^n′(w^n−w∗^)T+η2∥x^n′∥2\|\hat{w}_{n+1} - \hat{w_*}\|^2 = \|\hat{w}_n - \hat{w_*}\|^2 + 2{\eta\hat{x}^n}'(\hat{w}_n - \hat{w_*})^T + \eta^2\|{\hat{x}^n}'\|^2∥w^n+1−w∗^∥2=∥w^n−w∗^∥2+2ηx^n′(w^n−w∗^)T+η2∥x^n′∥2
根据算法概念,已经确定权重 wk+1^\hat{w_{k+1}}wk+1^ 产生于 wk^\hat{w_k}wk^ 和第k个刺激 x^k′{\hat{x}^k}'x^k′ ,那么就有:
w^kTx^k′⩽0\hat{w}_k^T{\hat{x}^k}' \leqslant 0w^kTx^k′⩽0
于是:
∥w^2−w∗^∥2⩽∥w^1−w∗^∥2+2ηx^1′w∗^T+η2∥x^1′∥2\|\hat{w}_2 - \hat{w_*}\|^2 \leqslant \|\hat{w}_1 - \hat{w_*}\|^2 + 2{\eta\hat{x}^1}'\hat{w_*}^T + \eta^2\|{\hat{x}^1}'\|^2∥w^2−w∗^∥2⩽∥w^1−w∗^∥2+2ηx^1′w∗^T+η2∥x^1′∥2
∥w^3−w∗^∥2⩽∥w^2−w∗^∥2+2ηx^2′w∗^T+η2∥x^2′∥2\|\hat{w}_3 - \hat{w_*}\|^2 \leqslant \|\hat{w}_2 - \hat{w_*}\|^2 + 2{\eta\hat{x}^2}'\hat{w_*}^T + \eta^2\|{\hat{x}^2}'\|^2∥w^3−w∗^∥2⩽∥w^2−w∗^∥2+2ηx^2′w∗^T+η2∥x^2′∥2
∥w^4−w∗^∥2⩽∥w^3−w∗^∥2+2ηx^3′w∗^T+η2∥x^3′∥2\|\hat{w}_4 - \hat{w_*}\|^2 \leqslant \|\hat{w}_3 - \hat{w_*}\|^2 + 2{\eta\hat{x}^3}'\hat{w_*}^T + \eta^2\|{\hat{x}^3}'\|^2∥w^4−w∗^∥2⩽∥w^3−w∗^∥2+2ηx^3′w∗^T+η2∥x^3′∥2
逐项求和,有:
∥w^n+1−w∗^∥2⩽η2∑k=1n∥x^k′∥−2η∑k=2nx^k′w∗^T\|\hat{w}_{n+1} - \hat{w_*}\|^2 \leqslant \eta^2 \sum_{k=1}^{n}\|{\hat{x}^k}'\| - 2 \eta \sum_{k=2}^{n} {\hat{x}^k}' \hat{w_*}^T∥w^n+1−w∗^∥2⩽η2k=1∑n∥x^k′∥−2ηk=2∑nx^k′w∗^T
令 B=maxk∥x^k′∥2>0且A=minkx^k′w∗^T>0B = \max \limits_{k}\|{\hat{x}^k}'\|^2 > 0 且 A = \min \limits_{k} {\hat{x}^k}' \hat{w_*}^T > 0B=kmax∥x^k′∥2>0且A=kminx^k′w∗^T>0,就有:
∥w^n+1−w∗^∥2⩽η2∑k=1nB−2η∑k=2nA=(η2B−2ηA)n\|\hat{w}_{n+1} - \hat{w_*}\|^2 \leqslant \eta^2 \sum_{k=1}^{n}B - 2 \eta \sum_{k=2}^{n} A = (\eta^2B-2 \eta A)n∥w^n+1−w∗^∥2⩽η2k=1∑nB−2ηk=2∑nA=(η2B−2ηA)n
∥w^n+1−w^∗∥2⩽(η2B−2ηA)n\|\hat{w}_{n+1} - \hat{w}_*\|^2 \leqslant (\eta^2B-2 \eta A)n∥w^n+1−w^∗∥2⩽(η2B−2ηA)n
至此,上界下界都已经推导完毕。根据夹逼定理:
(ηA)2n2+2aηAn+a2⩽∥w^n+1−w^∗∥2⩽(η2B−2ηA)n(\eta A)^2n^2 + 2a \eta A n + a^2 \leqslant \|\hat{w}_{n+1} - \hat{w}_*\|^2 \leqslant (\eta^2B-2 \eta A)n(ηA)2n2+2aηAn+a2⩽∥w^n+1−w^∗∥2⩽(η2B−2ηA)n
不等式左边是一个开口向上的一元二次方程,因此必存在,使等式不成立,因此该方法收敛。
这一章信息量极大。且必须要经过扎实的统计基础和数学公式推导,参考书籍选择了李航的《统计学习方法》一书,也集中参考了博客园lanix的文章《Rosenblatt感知器详解》,然而感知机的大门我们只打开了不到三分之一,近期也因为工作调整,日常繁忙一些所以没码多少字,不足之处还望海涵。
欢迎关注我的CSDN博客和github主页,目标是成为首屈一指的数据科学家,成长之路邀你见证。
(暂时没有贴链接和名片的想法,会设计一个公众号的自动回复功能,上线后回复相应神秘代码即可得到主页链接。)
下期预告:初探神经网络(三)感知机的第二部分(标题还没起好)

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)