
【AI】【机器学习】机器学习算法总结、资料汇总、个人理解
机器学习如今是数学、计算机、人工智能、大数据系必备的基础专业课,在我刚入大学那会(大约18年左右)是最流行的,到了后来深度学习热潮盖过了之前的机器学习,再到23/24年的大语言模型,技术一直在不断发展。机器学习是这些技术的入门基础,在许多院校计算机系和软件系列为研究生必修课程之一。本文将结合本科学过的知识和工作之后的内容,复盘下机器学习算法总结、资料汇总、个人理解。
1 前言
机器学习如今是数学、计算机、人工智能、大数据系必备的基础专业课,在我刚入大学那会(大约18年左右)是最流行的,到了后来深度学习热潮盖过了之前的机器学习,再到23/24年的大语言模型,技术一直在不断发展。机器学习是这些技术的入门基础,在许多院校计算机系和软件系列为研究生必修课程之一,也是部分院校大数据/人工智能考研的必备知识。本文将结合本科学过的知识和工作之后的内容,复盘下机器学习算法总结、资料汇总、个人理解。
2 资料汇总
2.1 书本教材汇总
①《统计学习方法》 李航
体验:涵盖主流的机器学习算法,同时也是部分985考研院校人工智能专业的参考书,相比西瓜书少点内容,但是经典算法都覆盖了
②《机器学习》 周志华
体验:不仅涵盖主流的机器学习算法,在结尾部分同时也写了部分前沿的章节,比如模仿学习,强化学习,也是部分985考研院校人工智能专业的参考书,相比李航书更难,更全面点
③ 《R语言数据挖掘》 薛薇 中国人民大学
体验:我本科统计学专业,当时入门机器学习各类算法就是从这本书入门的,不推荐,没上面好理解
3 个人整理汇总
3.1 常见算法汇总
| 算法 | 主要思想 | 优缺点 | 其他优秀参考信息 |
| K近邻法 |
工作原理:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
k值选取(通常奇数,根号下样本数目,交叉验证选取最佳k值) |
优缺点: 优点 简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归(回归问题取平均值); 计算复杂性高;空间复杂性高; |
Python3《机器学习实战》学习笔记(一):k-近邻算法(史诗级干货长文)_python k近邻算法-CSDN博客 |
| 决策树 |
工作原理:决策树看成一个if-then规则的集合,将决策树转换成if-then规则的过程是这样的:由决策树的根结点(root node)到叶结点(leaf node)的每一条路径构建一条规则;路径上内部结点的特征对应着规则的条件,而叶结点的类对应着规则的结论。决策树的路径或其对应的if-then规则集合具有一个重要的性质:互斥并且完备。这就是说,每一个实例都被一条路径或一条规则所覆盖,而且只被一条路径或一条规则所覆盖。这里所覆盖是指实例的特征与路径上的特征一致或实例满足规则的条件。 算法步骤: 决策构建,3个步骤:特征选择(经验熵(香农熵)公式、条件熵成为条件经验熵公式、信息增益公式计算)、决策树的生成和决策树的修剪(原因每个样本够涵盖了,过拟合)。优缺点(过拟合--叶子节点需要的最小样本数量,或者数的最大深度,交叉验证剪枝) |
||
| 朴素贝叶斯 | 重点:条件概率的计算公式,全概率公式,条件概率的另一种写法,文章加粗贝叶斯推断的含义,贝叶斯推断的简单例子,朴素贝叶斯例子---对条件个概率分布做了条件独立性的假设,简单理解概率独立可以相乘,朴素贝叶斯推断的一些优缺点(加粗),朴素贝叶斯推断总结(加粗黑字,文本处理) 朴素贝叶斯补充:拉普拉斯平滑通过 “加α” 修正概率估计,避免零值问题并提升模型鲁棒性,是处理离散特征稀疏性的基础技术。实际应用中需根据数据分布调整α值以平衡偏差与方差。 |
见jack-cui博客 | |
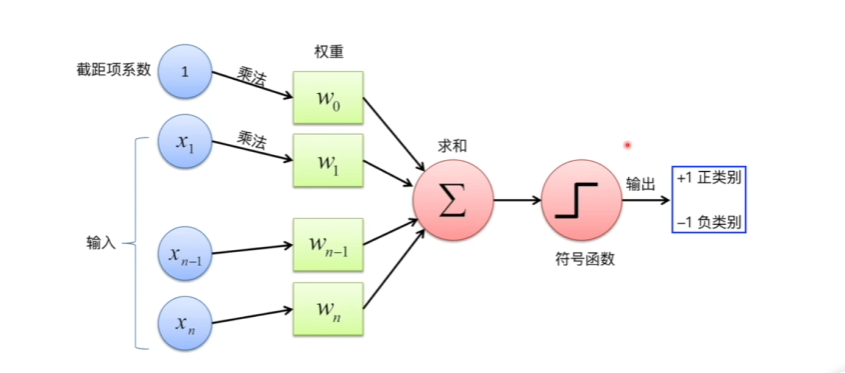
| 感知机 |
线性函数组合->符号决策函数->输出0或者1 损失函数及算法过程
|
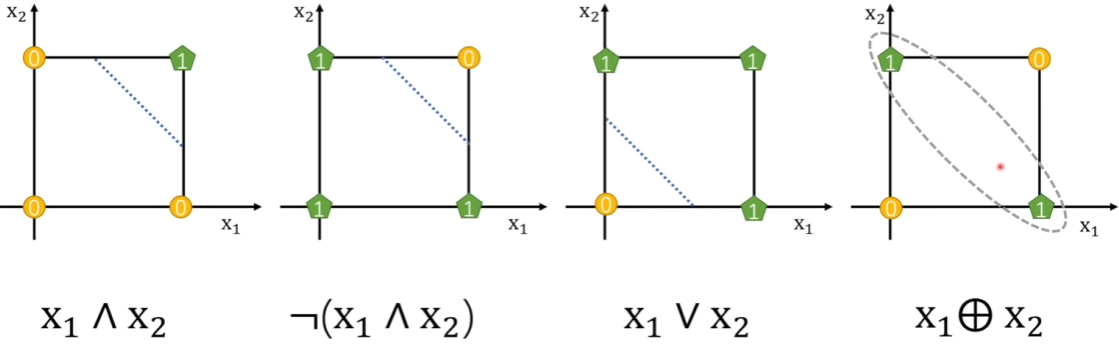
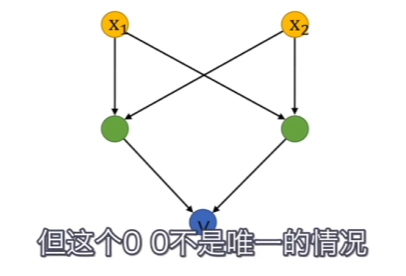
优点: ①便于解决线性问题,可以将其最终二分类 缺点: ①异或无法分类和非线性问题无法直接解决 处理方案:异或无法分类可以同通过叠加感知机解决
处理方案:线性问题无法分类可以类似SVM,升维度再线性切分解决 演进方向:神经网络(与神经网络不同在于个数组合和激活函数不同) |
|
| Logistic回归 | 代价函数满足J(θ)的最大的θ值即是我们需要求解的模型(加粗),梯度上升算法找最优值,个人总结(参考博客总结)就是目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以由最优化算法完成。总结(加粗),Logistic回归的优缺点。 Logistic回归补充:SAG的优势:通过历史梯度平均减少方差,比SGD收敛更快且更稳定。(即加粗总结中的它可以在新数据到来时就完成参数更新,而不需要重新读取整个数据集来进行批量处理。) |
见jack-cui博客系列 | |
| 支持向量机 | SVM:目标函数(分类间隔最大)、优化对象(超平面方程;"分类间隔"方程;)博客中步骤1 到步骤6的关键优化方程,步骤5关键是不等式约束优化问题(关键拉格朗日函数和KKT条件)=》拉格朗日函数=》拉格朗日对偶(可以看博客里面内嵌的另外一个链接,这里要用到凸优化对偶优化方面的知识,当前只能记住结论)=>SMO算法求解(SMO 通过分解问题→优化两变量→更新模型的循环,将 SVM 的训练复杂度从on3->on2,smo算法推导很复杂这里,看博客没看懂,) SMO:松弛变量【豆包:实际数据的复杂性:现实中的数据几乎不可能完全线性可分,松弛变量允许模型在合理范围内容错。避免过拟合:通过控制 C,模型可以在噪声较多的区域适当降低间隔,提高泛化能力。统一处理线性和非线性问题:结合核函数,松弛变量使 SVM 既能处理线性可分数据(硬间隔),也能处理非线性或含噪声数据(软间隔)】=》对偶小于C=>后续没看懂(包括核函数) |
8分钟,lailai带你学懂支持向量机(下)| SVM,核方法,SMO_哔哩哔哩_bilibili smo粗略理解(当前只找到这个) 还有王木头这节课的截图,机器学习本质 模型 策略 算法 https://blog.csdn.net/qq_39521554/article/details/80723770 某csdn博主的总结通俗解释smo算法 |
什么是SVM,如何理解软间隔?什么是合叶损失函数、铰链损失函数?SVM与感知机横向对比,挖掘机器学习本质 |
| 聚类 | 聚类是一种无监督学习,将相似的对象归到同一个簇中,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。即聚类后同一类的数据尽可能聚集到一起,不同数据尽量分离。;K-Means 聚类的步骤 | 见jack-cui系列 | |

3.2 机器学习基础
| 关键点 | 关键总结 | 优秀参考链接 |
| 损失函数 |
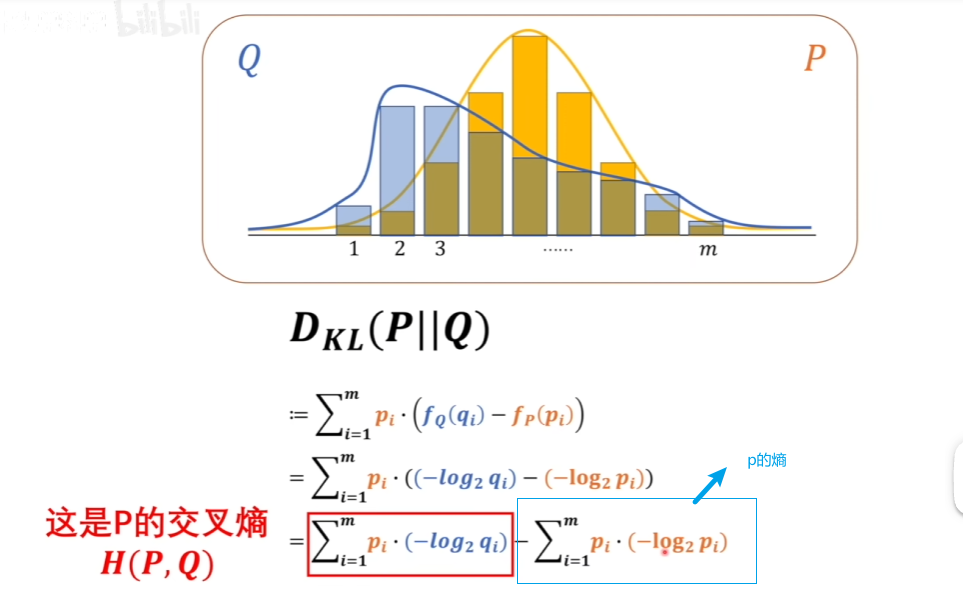
本意就是模型预测和实际数据之间的差异 主要三种 1.最小二乘法 2.极大似然法(实际结果出来,假设的模型分布最符合当前实际情况的-即概率最大的) 3.交叉熵法 熵的定义
KL散度(相对熵)
交叉熵越小代表2个模型越接近 |
|
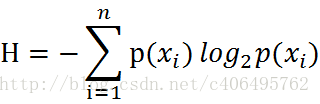
3.3 最优化梯度下降算法
见另外博客子系列:
3.4 其他疑问
1 激活函数为什么不能是线性的?
吴恩达系列解答:线性的意味着50层神经网络的线性变换和2层的变换没有任何区别
2 不同类型的激活函数 梯度下降的速度是不一样的
3 l1/l2正则化比较好的解释博客 红色石头will
https://blog.csdn.net/red_stone1/article/details/80755144
4 反向传播算法 b站 风中摇曳的小萝卜讲的不错
https://space.bilibili.com/168709400/lists/636173?type=season
5 dropout 原理和作用 csdn cv技术指南
https://blog.csdn.net/Mike_honor/article/details/125892375
6 神经网络初始化参数会导致梯度下降时候会很慢,会指数级减少,所以初始值最好选择1左右
7 梯度检验的作用
https://blog.csdn.net/uncle_ll/article/details/145121954
deepseek回答: 梯度检验比反向传播慢很多,由于算法本质不同,可以用于检测反向传播对不对
附录:
主要参考 jack-cui博客
https://jackcui.blog.csdn.net/article/details/75172850
王木头学科学(神经网络合集+tranformer解释、概率论合集、神经网络底层原理、机器学习理论基础、正则化解释)
https://space.bilibili.com/504715181/lists
吴恩达系列课程笔记--学到5.1后续没继续深入
https://blog.csdn.net/csdn_xmj/article/details/120461230
https://blog.csdn.net/qq_42859149/article/details/128312152
https://blog.csdn.net/qq_44543774/article/details/119154088
b站耿直哥

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)