
Copilot推出两年半,代码助手应用有何新进展?
今天我们聊一聊智能开发。智能开发通常指的是在软件开发过程中应用人工智能技术,以提高开发效率、质量和创新性。在大模型诞生之后,智能开发一直被视为 AI 落地的典型场景,走在前沿的开发者也快速接受了代码推荐为主要形态的 AI 辅助编程。但在此之后,我们期望大模型可以带来更大的效率提升。在日前举办的上,百度前端架构师、百度技术组织委员会 Web 方向负责人张立理带来了主题为“”的演讲。下面是演讲实录,我
今天我们聊一聊智能开发。智能开发通常指的是在软件开发过程中应用人工智能技术,以提高开发效率、质量和创新性。
在大模型诞生之后,智能开发一直被视为 AI 落地的典型场景,走在前沿的开发者也快速接受了代码推荐为主要形态的 AI 辅助编程。但在此之后,我们期望大模型可以带来更大的效率提升。
在日前举办的 QCon 全球软件开发大会上,百度前端架构师、百度技术组织委员会 Web 方向负责人张立理带来了主题为“大模型技术重塑智能研发新范式”的演讲。
下面是演讲实录,我们在不改变原义基础上进行了删减。
👇👇👇
我来自百度的工程效能部,我们的主要任务是推动智能研发场景和相关产品的内部实施,比如我们的百度文心快码。在这方面,无论是我自己的使用体验还是对工具的研发,我都投入了大量的精力和积累了丰富的经验。
研发工具的发展
在我看来,重塑并不是简单地将模型作为一个工具来使用,而是要让模型深入到研发的每一个环节,承担更多的功能和责任,实现真正的变革。我将从几个不同的角度来分享我对重塑的看法以及我的实践经验。
所谓的重塑可以从多个视角来理解。首先,我们不妨从研发工具的角度来看看,自从 GitHub Copilot 大约两年半前推出以来,这一类代码助手应用经历了怎样的发展,带来了哪些变化。
Go Fat:更大规模的代码补全
Go Fat,是指智能研发工具在不断扩展其功能和能力。以代码续写为例,这是大家在使用这类工具时常见的功能:当你输入一行代码后,工具会显示一段灰色的幽灵文本,这是模型基于推理预测你接下来可能要编写的代码片段。你只需按下 Tab 键,这段文本就会上屏,替代你手动敲击键盘,从而提升编写效率。
传统的续写功能大多是以行为单位的,比如 JetBrains 的官方智能功能,称为 Full Line code completion,就是基于整行的补全。但以行为单位的补全与我们编写代码时的逻辑概念并不完全吻合。因此,许多工具开始尝试承担更多的代码生成任务,实现更大规模的补全。例如,快捷的代码补全可以扩展到一个分支,如果有注释作为引导,工具可以生成整个方法的逻辑代码,提供更大范围的补全,进一步提升开发效率。
在智能研发工具的发展过程中,我们不可避免地面临一个挑战:多写多错。在有限的上下文中,单行代码的准确率相当高,但随着代码行数的增加,准确率会下降。对于开发者来说,判断一行代码的正确性可能只需要 0.5 秒,但判断 10 行代码的正确性则可能 5 秒都做不完,这种复杂度的增加是非线性的。因此,在处理多行代码时,准确率变得极其重要。
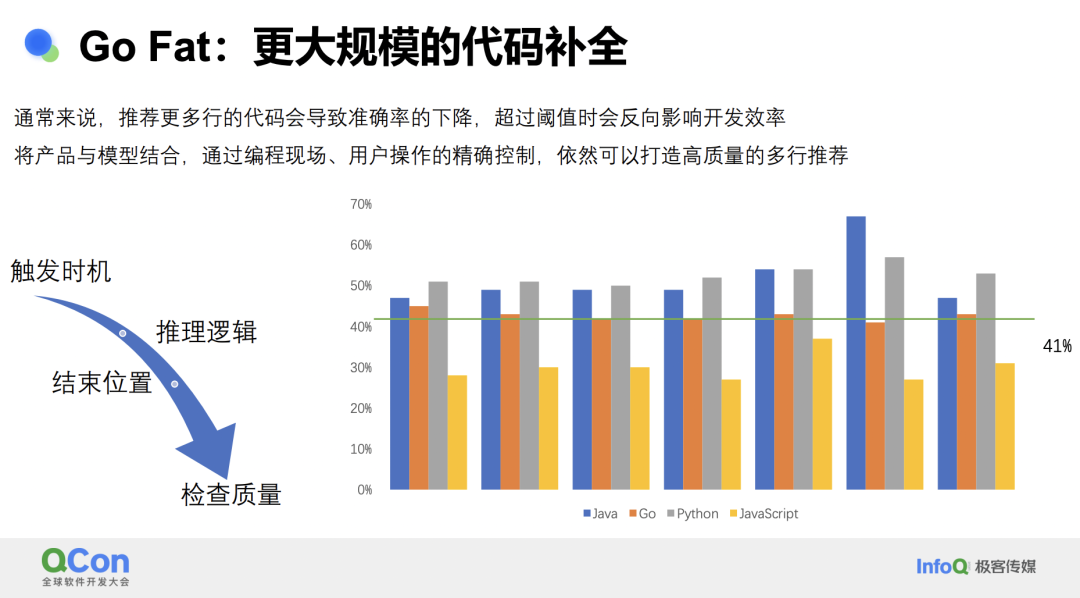
智能开发产品从几个角度对准确率进行优化。首先是触发时机,并不是所有情况下都适合进行多行补全。例如,当你写了一半的代码时,补全这一行会更准确;但如果在此基础上继续补全三行,准确性就会降低。此外,如果没有上下文联系,比如只写了一个方法名“do work”,此时补全多行代码显然是不合适的,因为缺乏足够的信息,只能进行猜测。因此,大多数产品会在特殊的语法节点进行控制,比如 if、for 语句,或者在有注释、连续空行以及其他逻辑的情况下,选择最合适的多行补全时机。
其次是推理逻辑,即模型能够获取的信息,包括前文、后文、相关文件、依赖文件以及库检索等。这部分在后续的开发者个人的章节会详细描述。
模型推理时不会因换行符而停止,而是会持续推导,但这种持续推导会导致错误率增加。因此,我们需要在语法层面控制结束位置,比如在 if 块结束时停止推理。
最后是质量检查,以规避模型的一些常见错误行为,比如输出连续重复的 token 或者与光标后的代码重复的内容。通过这些检查,我们可以隐藏不合格或明显低质量的推理结果,因为这些结果不仅不会提升效率,反而会增加开发者阅读代码的负担,降低效率。
根据我们的数据,多行推理的采纳率甚至可以超过平均值。在采样数据时,平均采纳率 大约为 41%,而多行推理,包括主流语言,可以达到 50% 以上。这表明,当产品和模型结合得当时,进行更大规模的补全可以取得更好的效果。
Be Rich:丰富的生成能力
Be Rich,即工具的生成能力。除了补全代码,智能工具还提供了更丰富的功能。以代码调优为例,大模型天生具备解释、分析、总结和摘要的能力,因此,当我们要求模型进行代码优化时,它在局部代码规模上的表现是相对可靠的。例如,对于一段代码,模型能够指出其中的重复部分可以提取,建议将明显的字符串转换为常量,指出违反类型安全的地方,并提供修复后的代码。这样,我们不仅在编写代码的过程中使用模型,还可以在代码已经存在的情况下,进一步通过模型进行局部重构和优化,这些能力正在逐渐落地。同时,我们通过产品校验确保优化后的代码与实际代码能够无缝合并,没有任何逻辑上的损失,从而获得最佳的代码重构和优化效果。
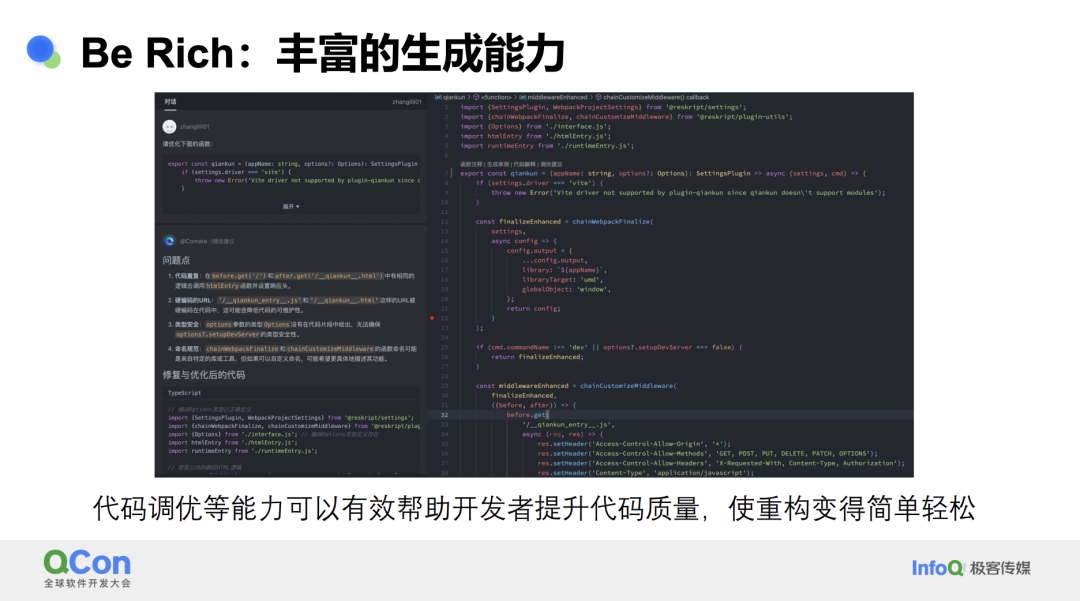
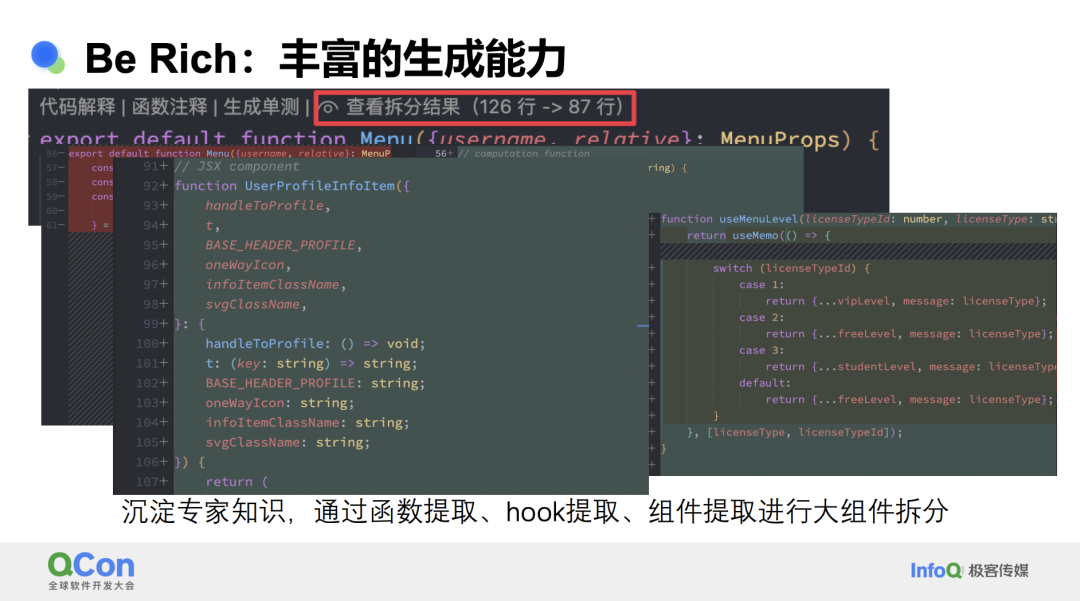
另一个能力是函数拆分。我们并不是简单地让模型自由地做拆分,而是针对特定场景进行特殊的模型提示词优化。
以前端 React 组件拆分为例,首先,我们会从组件中提取通用逻辑作为通用函数,这些函数可以在任何地方复用。其次,组件中有一个称为 hook 的概念,这是组件特有的可复用逻辑,我们也会将其提取为独立的可复用单元。最后,我们会将一个组件拆分成多个小组件,然后将它们重新组合在一起。这是我们在日常工作中进行代码拆分的常见实践。
我们作为产品开发者所做的,就是将工程师的日常经验和实践转化为模型的提示词和产品能力,沉淀到我们的产品中。这样,经验丰富的工程师的实际效果可以让更广泛的开发者受益,这远远比简单地告诉模型去拆分函数要准确得多。
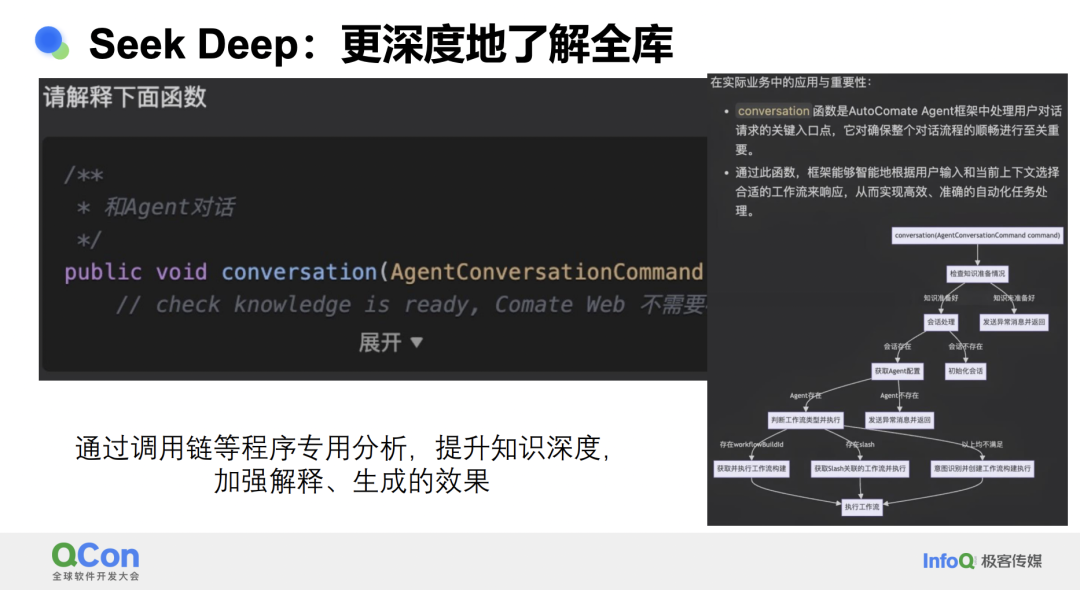
Seek Deep:更深度地了解全库
Seek Deep,即更深度地了解整个代码库。过去,模型对于代码库的理解非常有限,以前它们在帮助编写代码时,主要依据的是光标前后的内容,以及中间应该写什么。然而,随着技术的进步,通过嵌入和向量化等手段,我们现在可以对整个代码库进行索引和理解。
最典型的例子是分析函数的作用。以前,模型可能只能逐行解释这个函数是做什么的。但现在,有了对整个代码库的理解后,我们可以清晰地看到业务逻辑流程,这不仅仅是函数调用的流程。我们可以了解这个业务逻辑的含义,它先做什么,后做什么,以及哪些模块会使用到这个业务逻辑。这种理解类似于流程图,能够直观地展现出来,让你不仅知道一个函数的作用,还能了解这个函数在整个项目中扮演的角色。
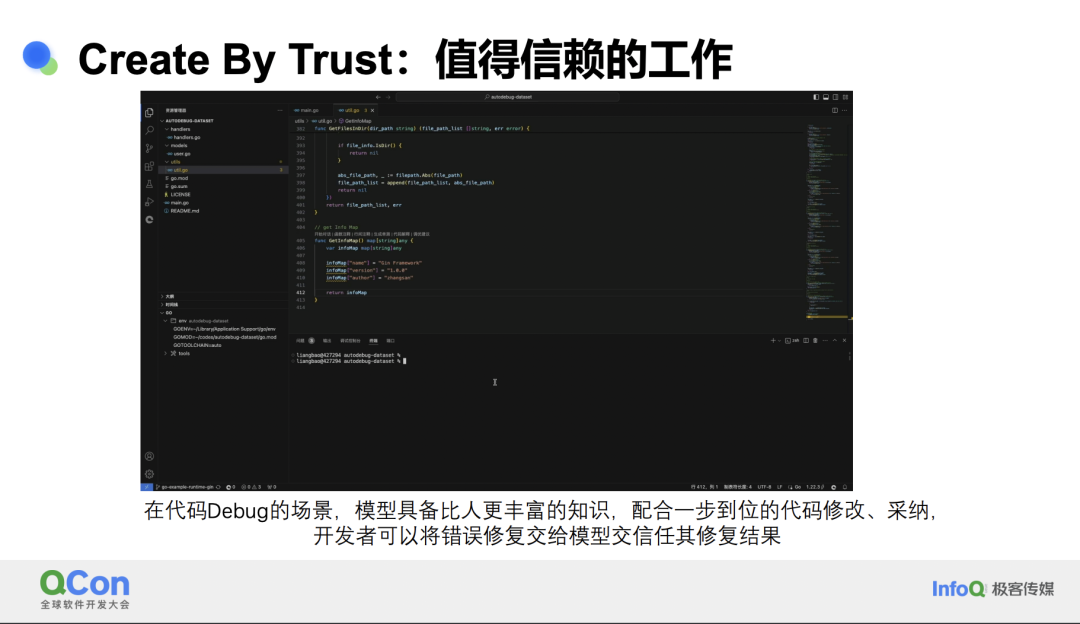
Create By Trust:值得信赖的工作
Create By Trust 指的是创造值得信赖的工作成果。在许多情况下,模型生成的内容可能存在错误,这使得开发者对这些错误抱有一种焦虑心态。
为了解决这个问题,我们可以在一些特定场景下让模型介入,例如在运行一个命令时。开发者经常会遇到命令执行出错的情况,这时可以让模型尝试修复错误。模型能够非常准确地定位到具体文件的某一行或几行,并在文件中直接修改代码。采纳模型提供的代码后,有一个明显的好处:你可以重新运行该命令,并立即看到结果。如果结果显示正确,即表示命令执行成功,这种成功与否的反馈能够给工程师带来对结果好坏的信赖感。
At Your Hand:更贴合现场的交互
At Your Hand,我们希望智能研发工具的交互更加贴合程序员的工作现场。程序员的工作现场主要是代码编辑区,而不是旁边的目录树。许多产品在侧边栏中加入了对话功能,这是一种基础形态,更多是用户想到时才去使用,而不是真正融入到工作流程中。现在,大多数产品都在推广一种称为 Inline Chat 的功能,它直接在代码编辑区内弹出对话框。在这个对话框中,你可以输入具体的代码需求,由于它是从代码区触发的,所以更倾向于直接生成代码,而不是进行解释或问答。然后,它可以直接在编辑区内写出代码,不仅可以新增代码,还可以选择一段代码进行修改。这种形态更加紧密地与工作现场结合,使焦点不需要转移,使用起来更方便、更友好、更快捷。
免费资料
另外,我还给大家准备了一套特别全的「AI 大模型学习资料包」,首次免费送给大家(买不买课都送)!
✅ AI 大模型学习路线图(2025 版)
✅ GeekAGI 知识库:DeepSeek、AI Agent 、MCP、AI 工具和框架、AI 提效案例
✅ AI 大模型面试题 300 道
✅ 26 套 AI 大模型行业研究报告
✅ 50+ AI 大模型必读电子书
👇👇扫码免费领取全部内容👇👇

资料详细内容如下
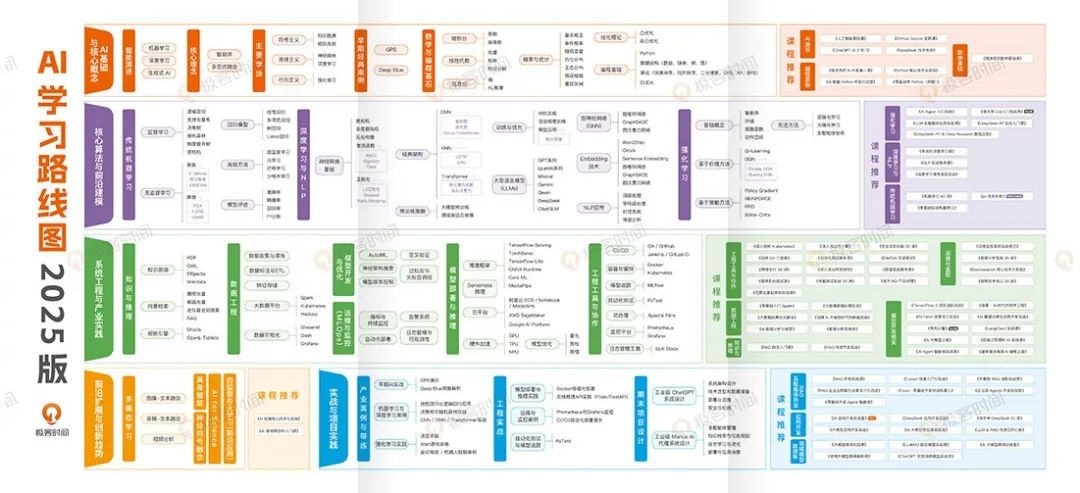
福利 1:AI 学习路线图(2025版)
2025 年入门 AI 大模型该学什么,有这张图就够了!
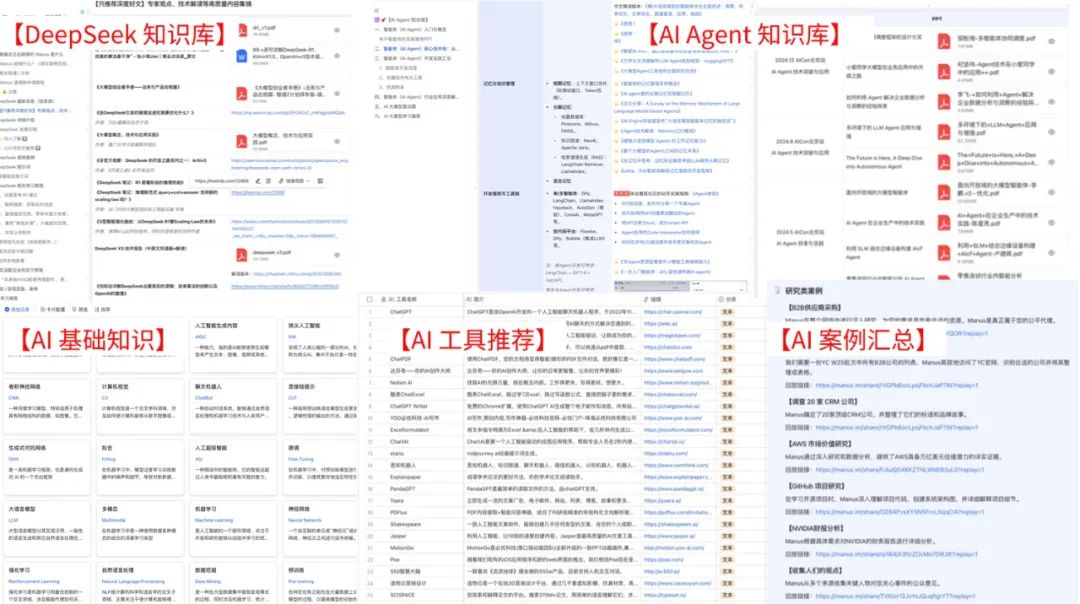
福利 2:GeekGI 知识库
DeepSeek 知识库
AI Agent 知识库
1200+ AI 工具和框架
MJ、SD 等 AI 应用的一条龙教程
AI 经典开源项目、工作提效 / 副业变现案例
福利 3:AI 大模型面试题 300 道
包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG、Agent 面试真题…
福利 4:24 套技术大会 2025 年案例 PPT

👇👇扫码免费领取全部内容👇👇




技术共进,成长同行——讯飞AI开发者社区
更多推荐


 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)