
llamaindx+Chaintlit个人学习笔记
首先在讲RAG之前我们要先理解什么是大模型(llm)人话:大模型就是一个被训练得特别“大”的人工智能程序,它懂语言、懂知识、懂逻辑,能帮你写文章、聊天、做题、画图、写代码。官方语言:然后我们来讲讲大模型和用户的简单交互示意。
1.1.RAG简述
首先在讲RAG之前我们要先理解什么是大模型(llm)
大模型(llm)
人话: 大模型就是一个被训练得特别“大”的人工智能程序,它懂语言、懂知识、懂逻辑,能帮你写文章、聊天、做题、画图、写代码。
官方语言:

然后我们来讲讲大模型和用户的简单交互示意
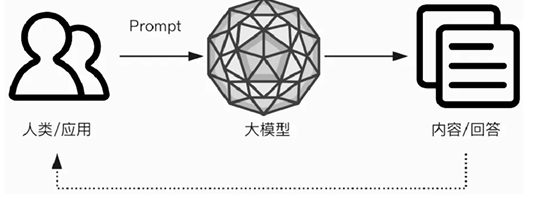
关键词:
⼈类/应⽤(Human/Application):与大模型通过输入提示(Prompt)交互的用户或程序。
提示(Prompt):用户或程序输入的信息
⼤模型(Large Model):人工智能模型
内容/回答(Content/Answer):处理提示生成的信息
反馈循环(Feedback Loop):用户和程序根据大模型回复进行进一步交互或者跳转。
了解RAG
RAG是干什么的
是为了解决大模型回复幻觉问题和其他时效性,可靠性和准确性方面的不足。因为大模型没有对错意识,它只会认为自己回复的都是对的,导致幻觉问题。
RAG是如何解决幻觉问题的呢?
答案是给大模型准备外部相关数据和上下文,来帮助其准确回答。这样子大模型生成内容时就不单单只依靠训练时的知识。
就像下面这样子
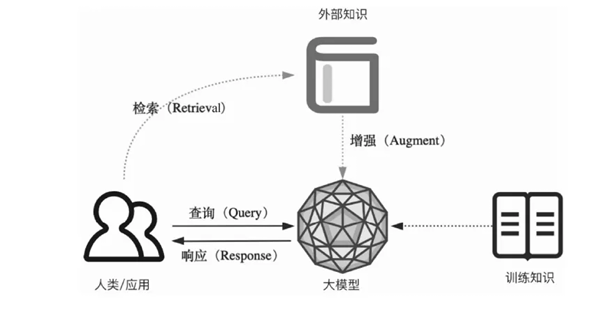
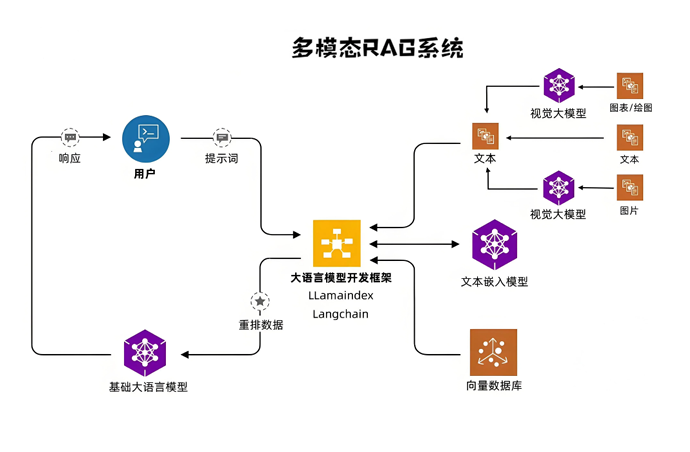
RAG技术实现流程
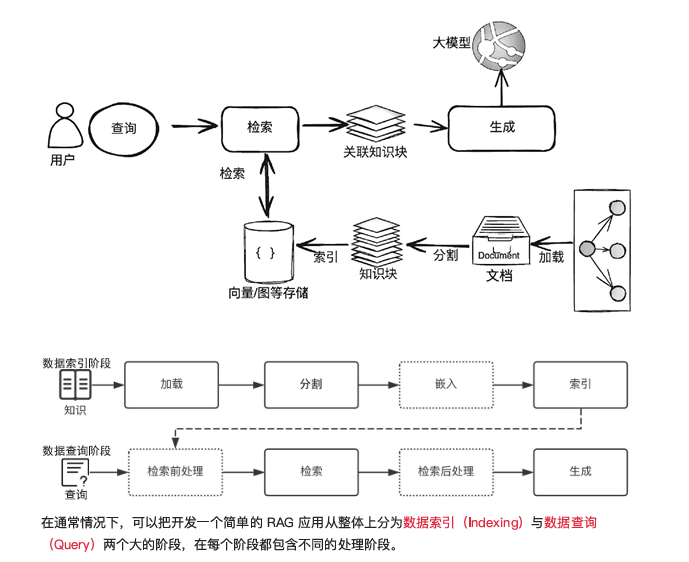
我们来简单讲解一下这个流程
用户提问 → 去资料库找相关内容 → 把内容+问题一起给大模型 → 大模型照着资料回答
| 步骤 | 比喻 | 技术动作 |
|---|---|---|
| ① 找食材 | 去冰箱拿菜 | 检索器把问题变成“关键词”,向量搜索从知识库(文档、网页、数据库)捞出最相关的段落 |
| ② 备料 | 把菜洗好切好 | 把捞到的段落排序、去重、截断,做成**“参考资料包”** |
| ③ 炒菜 | 照着菜谱做 | 把问题+参考资料一起喂给大模型,让它“照着资料”生成答案,并注明出处 |
我们来放上官方原文:
我们来对比一下大模型(Large Model)、RAG(检索增强生成) 与 Agent(智能体) 三者在多个维度上的定义与特点:
| 维度 | 大模型(Large Model) | RAG(检索增强生成) | Agent(智能体) |
|---|---|---|---|
| 核心定义 | 拥有百亿/千亿参数,通过海量数据预训练获得通用知识与推理能力 | 在生成阶段动态检索外部知识,将检索结果与输入共同送入模型生成答案 | 以大模型为“大脑”,具备自主感知、规划、调用工具并执行多步决策的能力 |
| 知识来源 | 训练语料中的静态参数知识,知识截止后无法更新 | 外部数据库、文档、API、互联网等,无需重训练即可更新知识 | 可融合大模型知识、RAG检索结果、传感器数据及第三方工具返回信息 |
| 知识时效性 | 受训练时间窗限制,需重训或微调才能更新 | 随外部数据变化即时更新,天然支持最新信息 | 与RAG结合后具备实时性,可主动抓取数据保持最新 |
| 生成准确性 | 易出现幻觉,尤其在长尾或专业领域 | 通过检索可靠片段显著降低幻觉,提高事实一致性 | 可交叉验证信息,进一步降低错误率 |
| 可控/可解释性 | 黑盒,难以追溯答案依据 | 可引用原文片段,便于溯源与审核 | 可记录完整“思维链+工具调用”日志,实现过程可审计 |
| 成本与资源 | 训练成本极高,推理成本随参数量线性增加 | 省去重训费用,仅发送相关片段,降低token消耗 | 在RAG基础上增加工具调用与推理开销,可通过缓存与并行优化 |
| 任务适用性 | 通用语言任务:对话、翻译、摘要、创作等 | 知识密集型问答、企业文档助手、客服、报告生成等 | 复杂多步任务:旅行规划、智能运维、数据分析、机器人控制等 |
| 技术组件 | Transformer、自注意力机制、预训练+微调/提示工程 | Embedding模型、向量数据库、检索器、重排序、Prompt模板 | 规划器、工具箱、记忆模块、执行器、反馈回路 |
| 优势总结 | 泛化与创造能力强,端到端简洁 | 成本低、实时性好、可溯源、易于领域定制 | 自主决策、多轮交互、工具扩展、可完成端到端业务闭环 |
| 主要挑战 | 幻觉、知识过时、训练成本高、可解释性差 | 检索质量依赖索引与Embedding效果,需维护外部库 | 任务分解准确性、工具可靠性、安全权限管理、复杂流程调试 |
三者的关系总结:
大模型是基础,提供语言理解与生成能力;
RAG通过检索增强大模型的知识处理能力;
Agent将大模型和RAG应用于实际任务,实现自主执行与交互。
2.通过llamaindex+chaintlit搭建RAG项目
2.1.实现基本聊天功能
step1:创建虚拟化环境
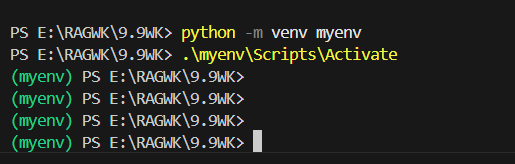
在要创建项目的目录下输入命令
| 终端类型 | 激活命令 | 退出命令 |
|---|---|---|
| PowerShell | .venv\Scripts\Activate.ps1 |
deactivate |
| CMD | .venv\Scripts\activate.bat |
deactivate |
如果第一次在 PowerShell 里若提示 “禁止运行脚本”,先执行一次(只需一次)
Set-ExecutionPolicy -ExecutionPolicy
RemoteSigned -Scope CurrentUser
激活后提示符前面会出现 (.venv)
(.venv) PS D:\Projects\MyBlog> python -m pip --version
step2:安装llamaindex框架
tips:LlamaIndex(原 GPT Index)是一个面向大模型(LLM)应用的数据框架,核心使命只有一句话:“把您的私有数据快速、低成本地塞进 LLM,让模型回答得更准、更新、更可溯源。”**
pip install llama-index
或者
pip install llama-index-llms-openai
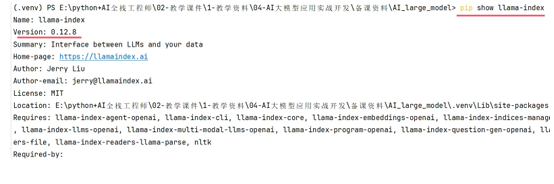
显示这个就是安装成功
step3:准备一个大模型apikey(如deepseek)
这个不会的可以去哔哩哔哩看教程:免费使用deepseekapi
step4:创建llms.py文件并且配置大模型
# 从 LlamaIndex 的 LLMs 子模块中导入 OpenAI 类
# 这是为了使用 OpenAI 的 API 进行语言处理任务
from llama_index.llms.openai import OpenAI
def deepseek_1lm(**kwargs):
"""
创建并返回一个 DeepSeek 聊天语言模型实例。
该函数通过指定 API 密钥、模型名称和 API 基础 URL 以及固定的温度参数来初始化一个 OpenAI 语言模型实例,
主要用于与 DeepSeek 提供的聊天语言模型进行交互。
参数:
**kwargs: 允许用户传入任意额外的关键字参数,以支持语言模型的定制化配置。
这些参数将直接传递给 OpenAI 类的构造函数。
返回:
llm:一个初始化后的 OpenAI 语言模型实例,用于进行语言处理任务。
该实例已预配置为使用 DeepSeek 的 API 服务。
"""
# 使用预设的 DeepSeek API 配置创建 OpenAI 实例
# 包括固定的 API 密钥、模型名称、API 基础 URL 和温度参数
llm = OpenAI(
api_key="你的apikey",
model="deepseek-chat",
api_base="https://api.deepseek.com/v1",
temperature=0.7,
**kwargs
)
return llm
step5:解决opeanai不支持deepseek大模型问题
在llms中添加代码
from typing import Dict
# 导入所有可用模型和聊天模型的字典,用于后续更新支持的模型
from llama_index.llms.openai.utils import ALL_AVAILABLE_MODELS, CHAT_MODELS
# 定义 DeepSeek 模型的字典,包含模型名称和对应的 token 限制
DEEPSEEK_MODELS: Dict[str, int] = {
"deepseek-chat": 64000,
}
# 更新所有可用模型和聊天模型的字典,添加 DeepSeek 模型
ALL_AVAILABLE_MODELS.update(DEEPSEEK_MODELS)
CHAT_MODELS.update(DEEPSEEK_MODELS)
完整llms代码:
from llama_index.llms.openai import OpenAI
from llama_index.llms.openai.utils import ALL_AVAILABLE_MODELS, CHAT_MODELS
from typing import Dict
# 定义DeepSeek模型的字典,包含模型名称和对应的token限制
DEEPSEEK_MODELS: Dict[str, int] = {
"deepseek-chat": 64000,
}
# 更新所有可用模型和聊天模型的字典,添加DeepSeek模型
ALL_AVAILABLE_MODELS.update(DEEPSEEK_MODELS)
CHAT_MODELS.update(DEEPSEEK_MODELS)
def deepseek_llm(**kwargs):
llm = OpenAI(
model="deepseek-chat",
api_key="sk-fe5f3a95dc88471ba7a3c2e17c384ac0",
api_base="https://api.deepseek.com/v1", # 关键
temperature=0.7,
**kwargs)
return llm
step6:安装添加使用Chainlit 框架
tipsChainlit 是一个开源异步 Python 框架,定位是“只写后端逻辑,自动生成 ChatGPT 同款界面”,用来极速搭建可投产的大模型对话应用,把原本需要前后端配合数周的开发量压缩到几分钟。
下载安装Chainlit
pip install chainlit
检查安装是否成功
chainlit hello
出现web界面就是成功
如果报以下错误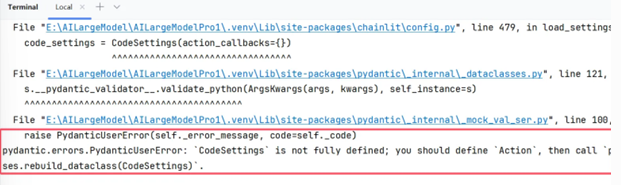
原因:这个问题最主要的问题是pydantic的版本问题
解决方案
卸载pydantic
pip uninstall pydantic
#安装pydantic为2.9.2版本即可
pip install pydantic==2.9.2
chainlit hello

构建app.py
# 导入 Chainlit 库,用于构建和部署 AI 应用
import chainlit as cl
# 导入 Settings 类,用于配置 llama_index 的核心设置
from llama_index.core import Settings
# 导入 SimpleChatEngine 类,用于实现简单的聊天引擎
from llama_index.core.chat_engine import SimpleChatEngine
# 导入自定义的 DeepSeek 语言模型
from llms import deepseek_llm
# Chainlit 聊天开始事件处理函数
@cl.on_chat_start
async def start():
"""
当聊天开始时异步执行的函数。
初始化设置和聊天引擎,并向用户发送欢迎消息。
1. 初始化 Settings.llm 为 deepseek_1lm()。
2. 创建一个 SimpleChatEngine 实例,并存储到用户会话中。
3. 异步发送一条消息给用户,介绍自己并询问用户需要的帮助。
"""
# 初始化大型语言模型(LLM)设置
Settings.llm = deepseek_llm()
# 创建一个简单的聊天引擎实例
chat_engine = SimpleChatEngine.from_defaults()
# 将聊天引擎对象存储到用户会话中,以便后续使用
cl.user_session.set("chat_engine", chat_engine)
# 发送一条欢迎消息,介绍 AI 助手的功能和作用
await cl.Message(
author="Assistant",
content="你好!我是 AI 助手。有什么可以帮助你的吗?"
).send()
# Chainlit 消息事件处理函数
@cl.on_message
async def main(message: cl.Message):
"""
处理接收到的消息,并使用 chat_engine 生成回复。
参数:
message:cl.Message 类型,表示接收到的消息。
"""
# 从用户会话中获取 chat_engine 对象
chat_engine = cl.user_session.get("chat_engine")
# 初始化一个空的消息对象,内容为空,作者为 "Assistant"
msg = cl.Message(content="", author="Assistant")
# 使用 chat_engine 的 stream_chat 方法处理接收到的消息内容,并将结果转换为异步响应
res = await cl.make_async(chat_engine.stream_chat)(message.content)
# 流式界面输出:遍历生成的响应内容,逐个令牌地输出
for token in res.response_gen:
await msg.stream_token(token)
# 发送完整的消息
await msg.send()
保存为 app.py,然后在终端执行:
chainlit run app.py
运行效果
2.2添加私域知识问答
step1:创建私域向量数据
创建 app_chat_basic_rag.py
# 向量存储索引类,用于创建和管理向量数据库
# Settings:设置类,用于配置全局变量
# SimpleDirectoryReader:简单目录读取器类,用于从指定目录读取文档
# StorageContext:存储上下文类,用于管理存储配置
# load_index_from_storage:从存储加载索引的函数
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
Settings,
StorageContext,
load_index_from_storage
)
# 聊天模式枚举类,用于定义聊天模式
from llama_index.core.chat_engine.types import ChatMode
# 聊天内存缓冲区类,用于管理会话的记忆
from llama_index.core.memory import ChatMemoryBuffer
# 导入自定义的 LLM 和嵌入模型
from llms import deepseek_llm
from embeddings import embed_model_local_bge_small
# 设置全局 LLM 和嵌入模型
Settings.llm = deepseek_llm()
Settings.embed_model = embed_model_local_bge_small()
def index_data():
"""
构建索引数据,执行一次即可。
"""
# 加载数据(数据连接器)
# 使用 SimpleDirectoryReader 从指定目录读取数据,input_dir="data"
data = SimpleDirectoryReader(input_dir="data").load_data()
# 构建索引
# VectorStoreIndex.from_documents 方法用于从加载的文档数据中构建向量存储索引
# show_progress=True 显示进度条
index = VectorStoreIndex.from_documents(data, show_progress=True)
# 对向量数据库持久化
# 将索引数据保存到本地目录 "./index"
index.storage_context.persist(persist_dir="./index")
async def create_chat_engine_rag():
"""
异步创建基于检索增强生成(RAG)的聊天引擎。
首先初始化一个存储上下文,从指定路径加载索引;
然后构建一个聊天记忆缓冲区以存储聊天历史;
最后使用加载的索引、聊天记忆以及系统提示创建并返回一个聊天引擎。
"""
# 初始化存储上下文,从持久化目录 "./index" 加载索引
storage_context = StorageContext.from_defaults(persist_dir="./index")
index = load_index_from_storage(storage_context)
# 创建聊天记忆缓冲区,限制 token 数量为 1024
memory = ChatMemoryBuffer.from_defaults(token_limit=1024)
# 创建聊天引擎
# chat_mode 设置为 CONTEXT 模式,表示基于上下文回答
# system_prompt 定义 AI 的行为规则
chat_engine = index.as_chat_engine(
chat_mode=ChatMode.CONTEXT,
memory=memory,
system_prompt=(
"你是一个 AI 助手,可以基于用户提供的上下文内容,回答用户的问题,"
"不能随意编造回答。"
)
)
return chat_engine
# 构建索引(仅首次运行)
if __name__ == "__main__":
index_data()
在data文件夹下放入我们的知识库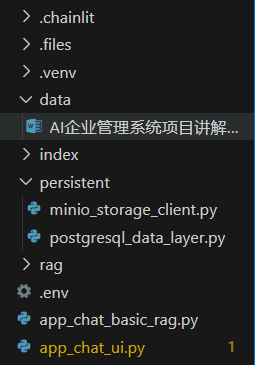
✅ 代码功能解释
-
index_data函数 -
加载数据:从指定目录
"data"中读取文档数据。 -
构建索引:使用加载的文档数据构建向量存储索引,并显示进度条。
-
持久化索引:将构建的索引保存到磁盘目录
"index"下。 -
create_chat_engine_rag函数 -
初始化存储上下文:设置默认持久化目录为
"./index"。 -
加载索引:从存储路径中加载之前构建的索引。
-
构建聊天记忆缓冲区:创建一个用于存储聊天历史的内存缓冲区,限制 token 数量为 1024。
-
创建聊天引擎:基于加载的索引、聊天记忆和系统提示创建聊天引擎,并返回该引擎。
。

安装模块:llama-index-embeddings-huggingface 或者 llama-index-embeddings-ollama
| 安装包名 | 功能说明 | 适用场景 |
|---|---|---|
| llama-index-embeddings-huggingface | 使用 Hugging Face 的 transformers/embedding 模型(如 sentence-transformers 系列)来生成向量 | 需要 Hugging Face 模型(本地/在线),适合通用中文/英文语义检索 |
| llama-index-embeddings-instructor | 使用 InstructorEmbedding(hkunlp/instructor-xl 等)模型,支持任务指导型 embedding,可在 Prompt 里加指令提升向量表示效果 | 适合需根据任务语境(分类、检索、QA)定制 embedding 的场景 |
| llama-index-embeddings-ollama | 使用 Ollama 本地大模型的 embedding 能力(如 llama2、mistral 等),无需依赖外部 API | 本地私有化部署,避免 API 费用 & 数据外泄风险 |
pip install llama-index-embeddings-huggingface
# 或者
pip install llama-index-embeddings-ollama
# 或者
pip install llama-index-embeddings-instructor
创建 embeddings.py
# 从 llama_index 库中导入 HuggingFaceEmbedding 类
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 本地模型
def embed_model_local_bge_small(**kwargs):
"""
创建并返回一个本地缓存的 BAAI/bge-small-zh-v1.5 嵌入模型实例。
使用本地缓存可以减少模型加载时间,提高效率。
参数:
**kwargs:支持 HuggingFaceEmbedding 的额外配置。
返回:
HuggingFaceEmbedding 实例,用于生成文本嵌入。
"""
embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-zh-v1.5",
cache_folder=r"../embed_cache",
**kwargs
)
return embed_model
# 在线模型(Ollama)
def embed_model_ollama_nomic(**kwargs):
"""
创建并返回一个 OllamaEmbedding 实例,用于文本嵌入任务。
使用 Nomic 提供的最新文本嵌入模型,通过指定服务器地址进行在线推理。
参数:
**kwargs:提供扩展灵活性。
返回:
OllamaEmbedding 实例。
"""
from llama_index.embeddings.ollama import OllamaEmbedding
ollama_embedding = OllamaEmbedding(
model_name="nomic-embed-text:latest",
base_url="http://123.60.22.2:11434",
**kwargs
)
return ollama_embedding
代码功能解释
这段代码定义了两个函数,用于创建不同的文本嵌入模型实例:
-
embed_model_local_bge_small:
- 创建并返回一个本地缓存的 BAAI/bge-small-zh-v1.5 嵌入模型实例。
- 使用 HuggingFaceEmbedding 类初始化模型,指定模型名称和缓存文件夹路径。
- 支持通过 **kwargs 传递额外参数以自定义配置。
-
embed_model_ollama_nomic:
- 创建并返回一个 OllamaEmbedding 实例,用于处理文本嵌入任务。
- 指定模型名称为 “nomic-embed-text:latest”,基础 URL 为提供嵌入服务的服务器地址。
- 支持通过 **kwargs 传递额外参数,但未具体使用。
step3 优化app.py代码
# 导入 chainlit 库,用于构建和部署 AI 驱动的聊天应用
import chainlit as cl
# 导入 Settings 类,用于配置 llama_index 的核心设置
from llama_index.core import Settings
# 导入 deepseek_llm,这可能是一个自定义的语言模型接口
from llms import deepseek_llm
# 导入 create_chat_engine_rag 函数,用于创建基于检索增强生成(RAG)的聊天引擎
from app_chat_basic_rag import create_chat_engine_rag
@cl.on_chat_start
async def start():
"""
当聊天开始时异步执行的初始化函数。
该函数负责初始化与聊天相关的设置和引擎。
它首先配置语言模型,然后创建聊天引擎,并在用户会话中设置。
最后,它发送一条欢迎消息给用户。
"""
# 初始化语言模型
Settings.llm = deepseek_llm()
# 异步创建带有 RAG(检索增强生成)的聊天引擎
chat_engine = await create_chat_engine_rag()
# 在用户会话中设置聊天引擎,以便后续使用
cl.user_session.set("chat_engine", chat_engine)
# 发送欢迎消息给用户
await cl.Message(
author="Assistant",
content="你好!我是 AI 助手。有什么可以帮助你的吗?"
).send()
@cl.on_message
async def main(message: cl.Message):
"""
处理接收到的消息,并使用 chat_engine 生成回复。
参数:
message:cl.Message 类型,表示接收到的消息。
此函数首先从用户会话中获取 chat_engine,然后创建一个空的助理消息。
之后,它使用 chat_engine 对收到的消息内容生成回复,并通过流式界面输出回复。
"""
# 从用户会话中获取 chat_engine
chat_engine = cl.user_session.get("chat_engine")
# 创建一个空的助理消息
msg = cl.Message(content="", author="Assistant")
# 使用 chat_engine 生成回复
res = await cl.make_async(chat_engine.stream_chat)(message.content)
# 流式界面输出
for token in res.response_gen:
await msg.stream_token(token)
# 发送消息
await msg.send()
运行结果
运行:python .\app_chat_basic_rag.py
chainlit run app.py -w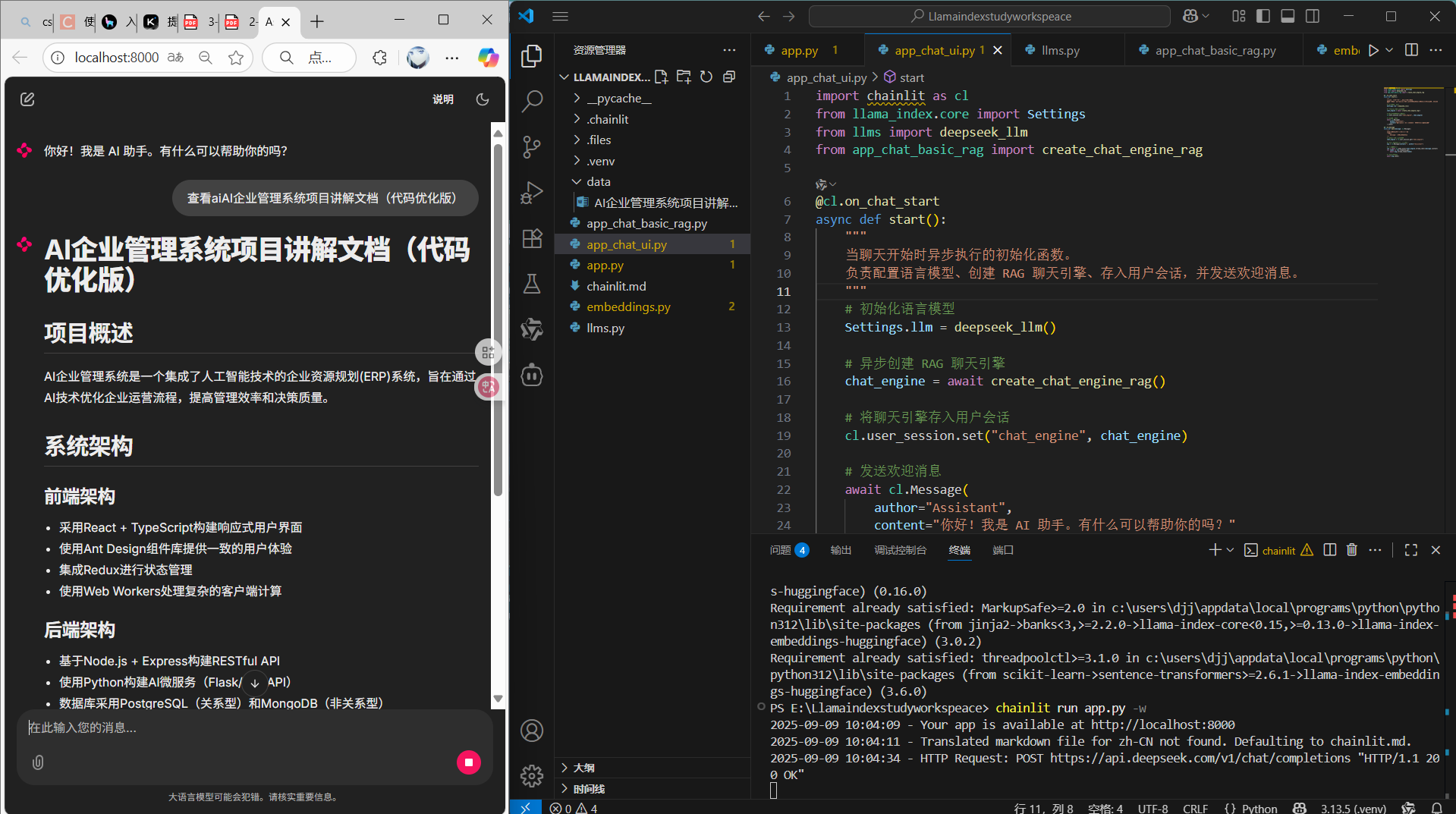
LlamaIndex 传统RAG系统设计及开发

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)