
大数据学习13之分布式事件流平台Kafka——整合Flume和Kafka完成实时数据采集
1.流程图Flume==> Kafka ==>Spark Streaming
文章目录
1.流程图
Flume==> Kafka ==>Spark Streaming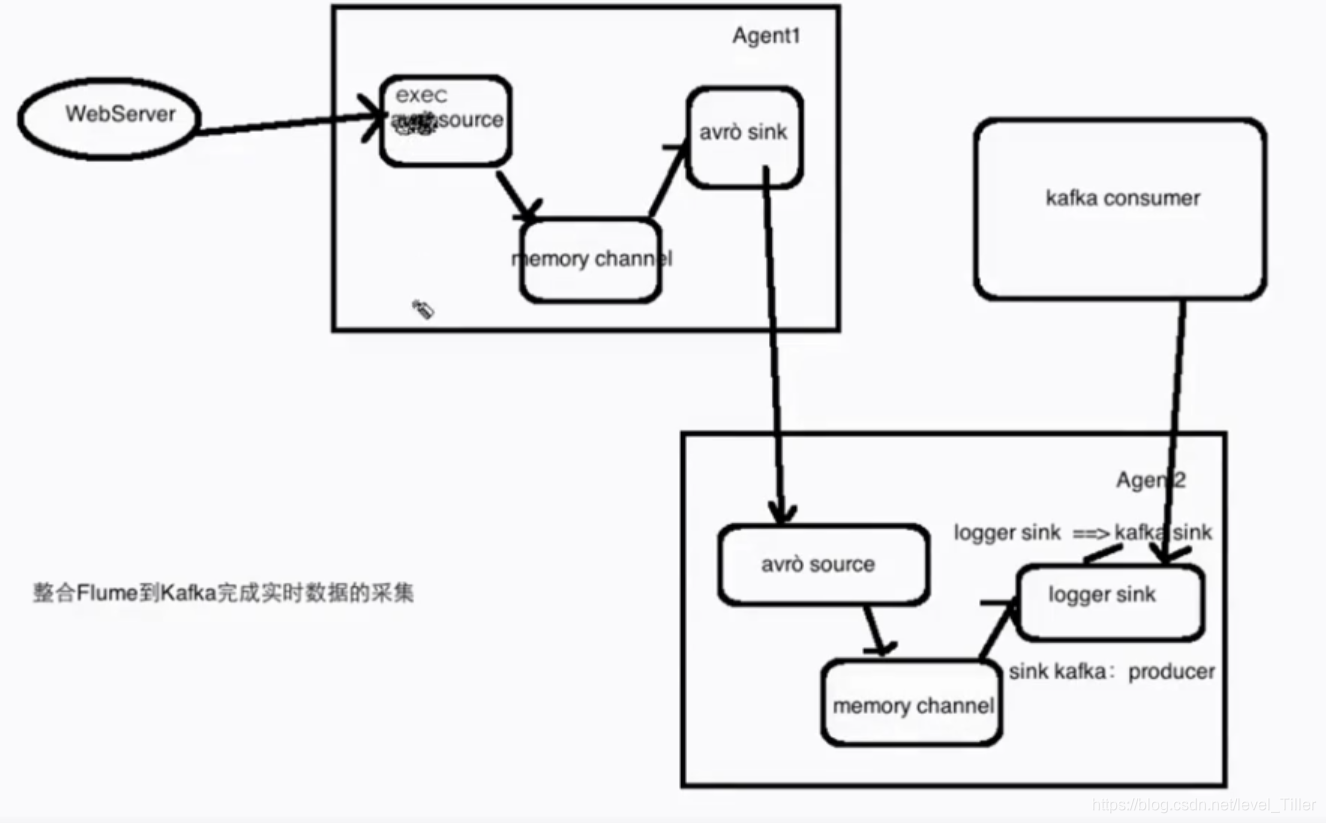
2.步骤
1. 在$FLUME_HOME的conf目录下中新建avro-memory-kafka.conf
我的flume的版本是1.6.0的,每个版本的文档会有所差别
参考:http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#kafka-sink
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop000
avro-memory-kafka.sources.avro-source.port = 44444
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = hadoop000:9092
avro-memory-kafka.sinks.kafka-sink.topic = hello_topic
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
avro-memory-kafka.sinks.kafka-sink.requiredAcks =1
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
2.启动zookpeer和kafka
zkServer.sh start
kafka-server-start.sh $KAFKA_HOME/config/server.properties
让这个进程一直运行
[hadoop@hadoop000 Desktop]$ jps
3396 Jps
3247 QuorumPeerMain
3295 Kafka
这个地方不能单单由jps中的服务进行判断。此时我发现网络出现了问题导致zookeeper连接失败:
C[hadoop@hadoop000 Desktop]$ ifconfig
eth3 Link encap:Ethernet HWaddr 00:0C:29:95:DD:9A
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:37907 errors:0 dropped:0 overruns:0 frame:0
TX packets:19023 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:11408706 (10.8 MiB) TX bytes:2173740 (2.0 MiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:19071796 errors:0 dropped:0 overruns:0 frame:0
TX packets:19071796 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1504777840 (1.4 GiB) TX bytes:1504777840 (1.4 GiB)
在windows中ipconfig查看ip发现出现改变,设置为静态ip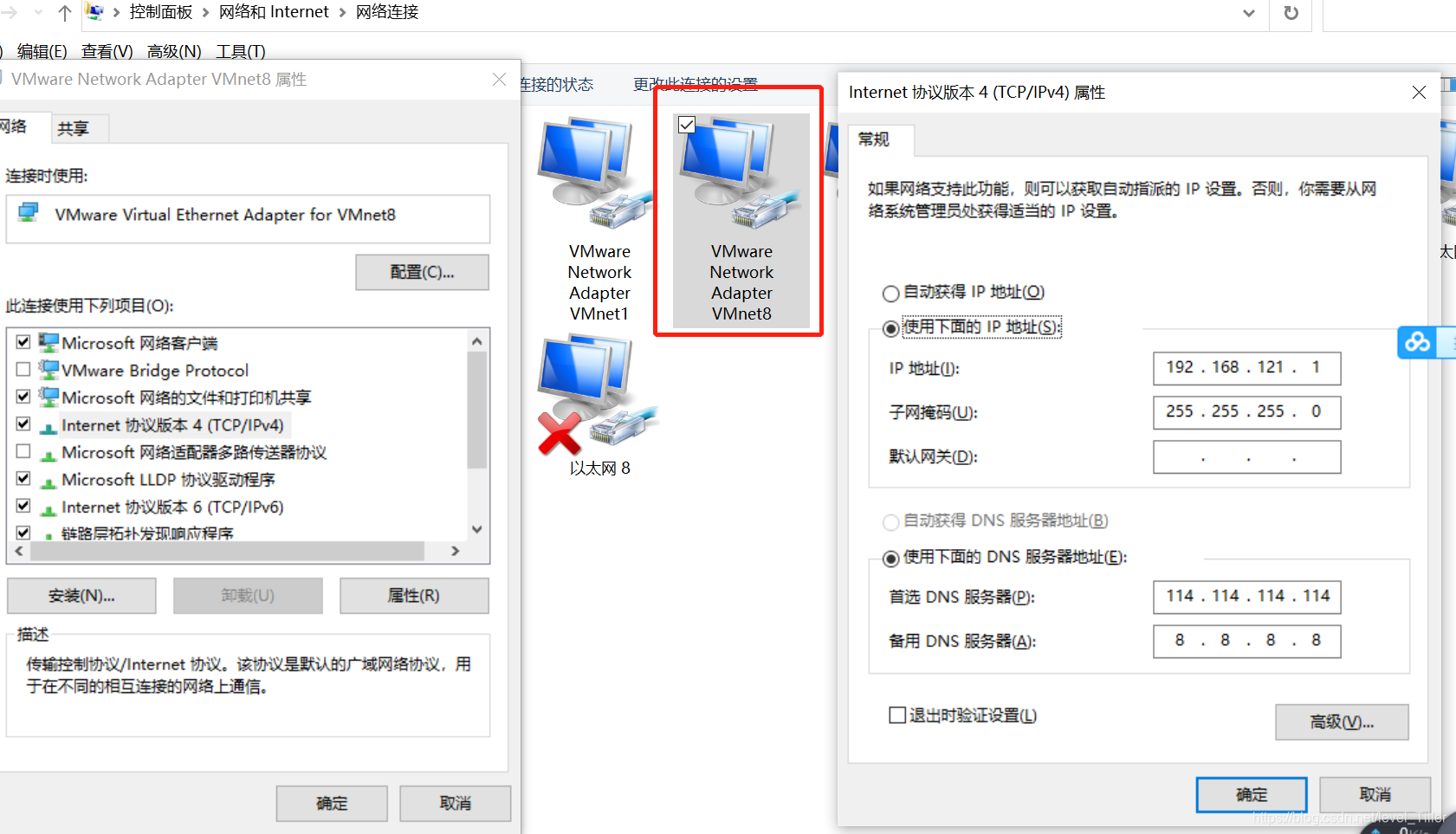
然后是虚拟机的编辑,虚拟网络编辑器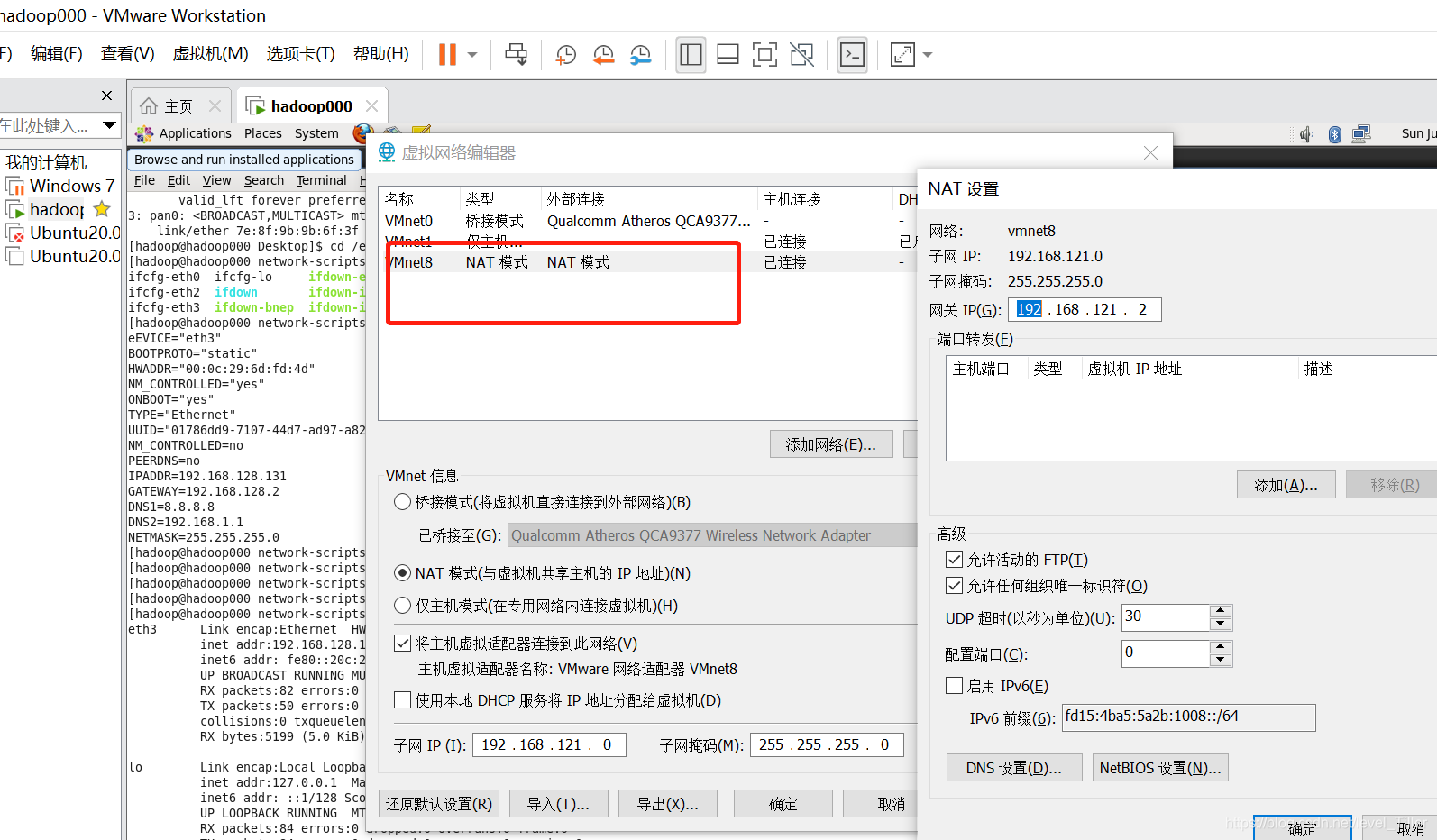
使用ip addr,发现虚拟机网络mac地址也发生改变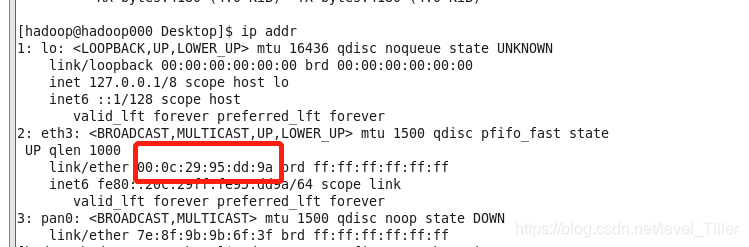
切换路径cd /etc/sysconfig/network-scripts
我这里的网卡叫eth3,所以修改sudo vim ifcfg-eth3文件,不要忘记IPADDR等进行对应修改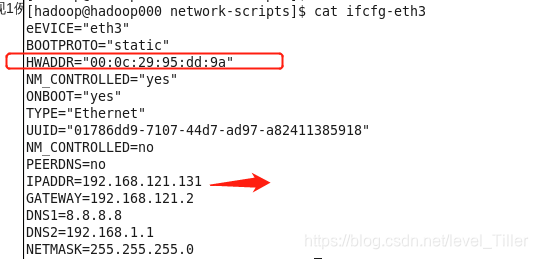
重启网络使其生效 service network restart
不要忘记修改过后关闭此terminal,然后再打开一个新的操作
3.启动两个agent收集传递日志
查看kafka中的topic列表,我们flume在文件中读到的数据,并发送到的kafka的主题就是hello_topic,在此列表中
[hadoop@hadoop000 Desktop]$ kafka-topics.sh --list --zookeeper hadoop000:2181
hello_topic
hellp-replicated-topic
hellp_topic
kafka_streaming_topic
my-replicated-topic
streamingtopic
启动配置完毕后需注意是flumeB监控的是flumeA,所以需要按顺序开启,先开启flumeB,后再启动flumeA。
flume-ng agent \
--name avro-memory-kafka \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/avro-memory-kafka.conf \
-Dflume.root.logger=INFO,console
再在新的terminal中启动服务器A的flume agent
flume-ng agent \
--name exec-memory-avro \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-avro.conf \
-Dflume.root.logger=INFO,console
[hadoop@hadoop000 data]$ cat $FLUME_HOME/conf/exec-memory-avro.conf
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -F /home/hadoop/data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop000
exec-memory-avro.sinks.avro-sink.port = 44444
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
4.启动kafka消费者消费这个topic,后期不应该使用这个kafka consumer ,而是应该使用spark streaming
由于avro-memory-kafka.conf中batchSize和发送时间的设置,kafka消费者接收的会慢一点–延迟
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic hello_topic
[hadoop@hadoop000 data]$ jps
6322 Jps
5523 Application
5400 ConsoleConsumer
3501 Application
3247 QuorumPeerMain
3295 Kafka
5.追加数据到/home/hadoop/data/data.log
因为exec source中command配置 :tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容
注意启动flume agent的时候有没有选错配置文件,topic是否一致
输入数据到/home/hadoop/data/data.log文件中,kafka消费者可以接收的到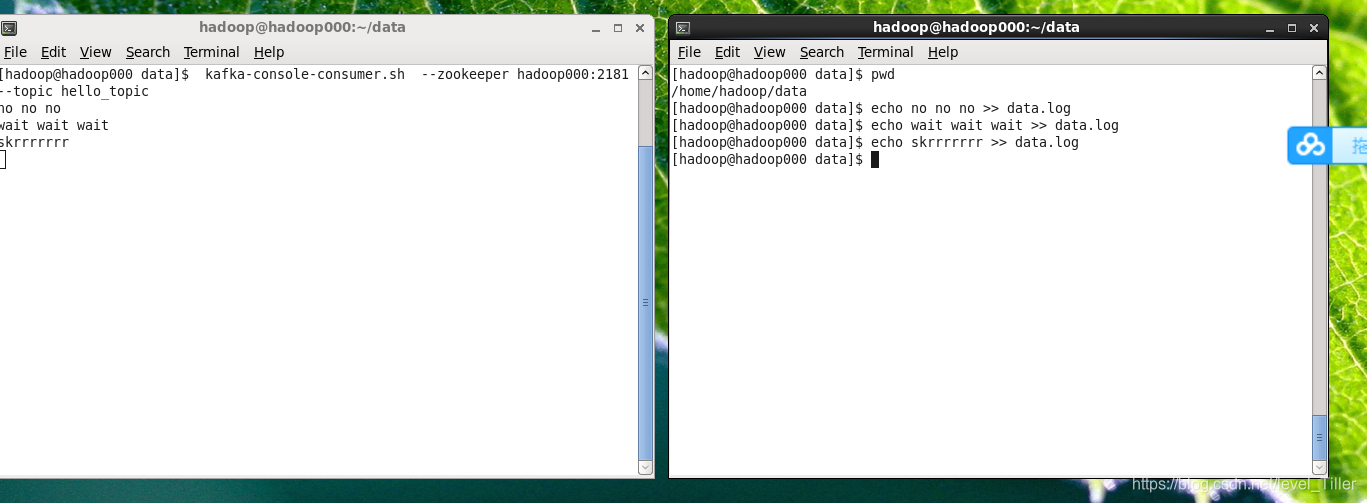

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)