
【实战篇】典型故障排查与性能问题诊断与优化
1 概述
浪潮信息KOS是浪潮信息基于Linux Kernel、OpenAnolis等开源技术自主研发的一款服务器操作系统,支持x86、ARM等主流架构处理器,性能和稳定性居于行业领先地位,具备成熟的 CentOS 迁移和替换能力,可满足云计算、大数据、分布式存储、人工智能、边缘计算等应用场景需求。详细介绍见官网链接https://www.ieisystem.com/kos/product-kos-xq.thtml?id=12126
典型故障排查
2 文件系统损坏修复全流程(xfs_repair)
目前网上出现大量的主机输入输出错误,原因是由于主机文件系统损坏。一线人员大部分采用的是umont 和 mount的方式恢复,这种恢复方式不能真正修复已经损坏的文件系统,在后续使用过程中,仍然会再次出现主机端输入输出错误。
2.1 需要修复的场景
| 1 | 主机侧发现存在文件系统不可读写的情况,也可以通过查看主机端日志来确认是否有文件系统异常发生: xfs_force_shutdown 、I/O error |
|---|---|
| 2 | 出现异常停电,供电恢复正常,主机和阵列系统重起之后 |
| 3 | 存储介质故障:出现LUN失效、RAID失效、以及IO超时或者出现慢盘,对慢盘进行更换,系统恢复正常之后 |
| 4 | 传输介质故障:如光纤、网线等损坏等,数据传输链路断开后又恢复正常之后 |
2.2 检查文件系统
注:检查文件系统必须保证将文件系统umount成功。
在根目录下输入“xfs_ncheck /dev/sdd(盘符);echo $?”(注意:在执行 此命令之前,必须将文件系统umount,否则会出现警告信 “xfs_ncheck: /dev/sdd contains a mounted and writable filesystem ”)敲回车键,查看命令执行返回值:0表示正常,其他为不正常,说明文件系统 损坏,需要修复。
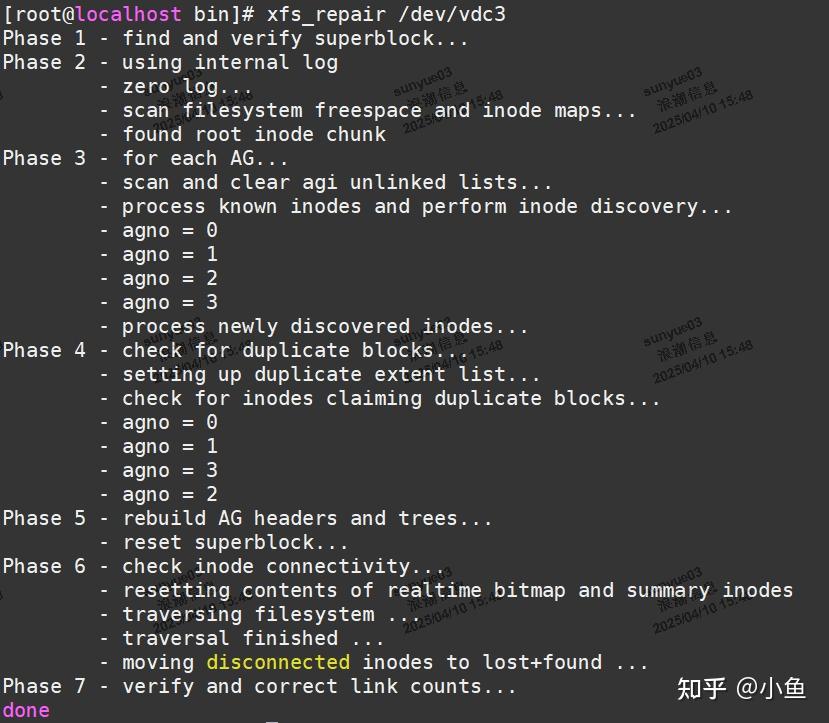
例如:xfs_ncheck /dev/vdc3; echo $?

2.3 修复过程
注:修复时需要暂停主机侧的业务,umount 和 mount 无法修复文件系统 。
先umount要修复的文件系统的分区
然后输入 “xfs_repair /dev/sdd(盘符)”执行修复命令。
xfs_ncheck /dev/sdd; echo $?
如果为0===》成功修复。
如果不为0===》没有成功:请执行xfs_repair –L /dev/sdd命令,再执 行xfs_repair(反复多修复几次)

2.4 xfs常用命令
| xfs_admin | 调整 xfs 文件系统的各种参数 |
|---|---|
| xfs_copy | 拷贝 xfs 文件系统的内容到一个或多个目标系统(并行方式) |
| xfs_db | 调试或检测 xfs 文件系统(查看文件系统碎片等) |
| xfs_check | 检测 xfs 文件系统的完整性 |
| xfs_bmap | 查看一个文件的块映射 |
| xfs_repair | 尝试修复受损的 xfs 文件系统 |
| xfs_fsr | 碎片整理 |
| xfs_quota | 管理 xfs 文件系统的磁盘配额 |
| xfs_metadump | 将 xfs 文件系统的元数据 (metadata) 拷贝到一个文件中 |
| xfs_mdrestore | 从一个文件中将元数据 (metadata) 恢复到 xfs 文件系统 |
| xfs_growfs | 调整一个 xfs 文件系统大小(只能扩展) |
| xfs_logprint | print the log of an XFS filesystem |
| xfs_mkfile | create an XFS file |
| xfs_info | expand an XFS filesystem |
| xfs_ncheck | generate pathnames from i-numbers for XFS |
| xfs_rtcp | XFS realtime copy command |
| xfs_freeze | suspend access to an XFS filesystem |
| xfs_io | debug the I/O path of an XFS filesystem |
2.5 具体应用
查看文件块状况: xfs_bmap -v sarubackup.tar.bz2

查看磁盘碎片状况: xfs_db -c frag -r /dev/vdc3

文件碎片整理: xfs_fsr sarubackup.tar.bz2

磁盘碎片整理: xfs_fsr /dev/vdc3

2.6 最后方法
损失部分数据的修复方法
根据打印消息,修复失败时:
先执行xfs_repair -L /dev/sdd(清空日志,会丢失文件),再执行xfs_repair /dev/sdd,再执行xfs_check /dev/sdd 检查文件系统是否修复成功。
说明:-L是修复xfs文件系统的最后手段,慎重选择,它会清空日志,会丢失用户数据和文件。
备注:
在执行xfs_repair操作前,最好使用xfs_metadump工具保存元数据,一旦修复失败,最起码可以恢复到修复之前的状态。
3 inode耗尽问题的预防与处理
在 Linux 操作系统中,inode 是文件系统中的一个重要概念,它用于唯一标识文件系统中的每个文件或目录。inode 的耗尽通常会导致系统无法创建新的文件或目录,这对于系统的正常运行是至关重要的。本章节将探讨导致 inode 耗尽的原因,并提出一些可能的解决策略,以及预防方案,以帮助系统管理员更好地管理和维护文件系统。
3.1 inode的定义
Linux系统下文件数据储存在"块"中,文件的元信息,例如文件的创建者、文件的创建日期、文件的大小等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
inode也占用硬盘空间,硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
3.2 inode 的组成
inode 通常包含以下信息:
| inode号 | 文件在文件系统中的唯一标识符。 |
|---|---|
| 文件类型 | 指出是文件还是目录。 |
| 权限 | 文件或目录的访问权限,如读、写、执行。 |
| 链接数 | 指向该 inode 的硬链接数量。 |
| 所有者ID | 文件所有者的用户 ID。 |
| 组ID | 文件所有者的组 ID。 |
| 大小 | 文件大小,以字节为单位。 |
| 块大小 | 文件系统分配给文件的数据块的大小。 |
| 时间戳 | 文件的创建时间、最后访问时间和最后修改时间。 |
| 数据块指针 | 指向文件数据实际存储位置的数据块指针。 |
3.3 inode 的作用
inode 是文件系统高效管理文件的关键。当用户访问文件时,系统通过 inode 号快速定位到文件的数据块,而不需要遍历整个文件系统。这样可以显著提高文件访问速度,尤其是在大型文件系统中。此外,inode 还允许实现文件的硬链接,因为硬链接实际上是指向相同 inode 的多个文件名。
3.4 inode 耗尽的原因分析
inode 耗尽通常是由于文件系统的设计和管理不当导致的。以下是一些常见的导致 inode 耗尽的原因:
| 文件数量过多 | 在文件系统中,每个文件或目录都需要一个 inode。如果一个文件系统中有大量的文件或目录,那么 inode 的数量可能会迅速耗尽。特别是在一些用于存储大量小文件的系统中,如邮件服务器或版本控制系统,这个问题尤为突出。 |
|---|---|
| 硬链接的使用 | 硬链接是指向同一 inode 的多个文件名。每个硬链接都会增加 inode 的链接数。如果一个文件被频繁地创建硬链接,而没有相应的删除,那么即使文件被删除,其 inode 仍然被占用,导致 inode 无法被回收。 |
| 文件系统类型 | 不同的文件系统类型对 inode 的分配和管理策略不同。例如,ext4 文件系统在格式化时会预先分配一定数量的 inode。如果分配的 inode 数量不足,那么在文件系统使用过程中可能会出现 inode 耗尽的情况。 |
| 系统漏洞或错误配置 | 系统漏洞或错误配置也可能导致 inode 的异常使用。例如,某些应用程序可能会因为编程错误而创建大量临时文件,或者配置错误导致文件系统参数设置不当,从而加速 inode 的消耗。 |
| 文件系统损坏 | 文件系统损坏可能会破坏 inode 的分配记录,导致无法正确释放已删除文件的 inode,或者错误地分配 inode,从而引起 inode 耗尽的问题。 |
3.5 检测与诊断 inode 耗尽的方法
为了有效管理和维护 Linux 文件系统,系统管理员需要能够及时检测和诊断 inode 耗尽的问题。以下是一些常用的方法和命令,用于检测和诊断 inode 的使用情况。
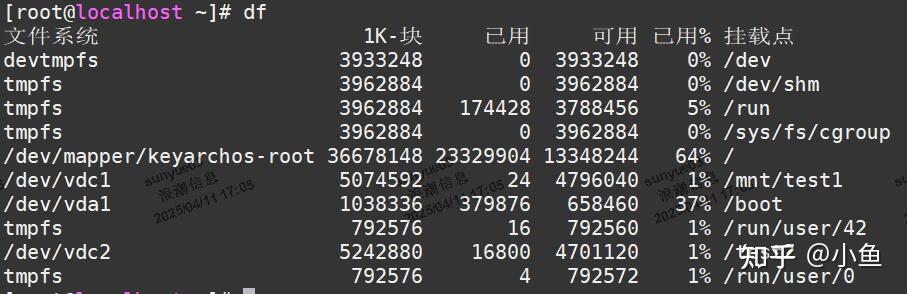
查看磁盘空间使用情况,使用 df 命令
查看inodess使用情况,使用df -i命令
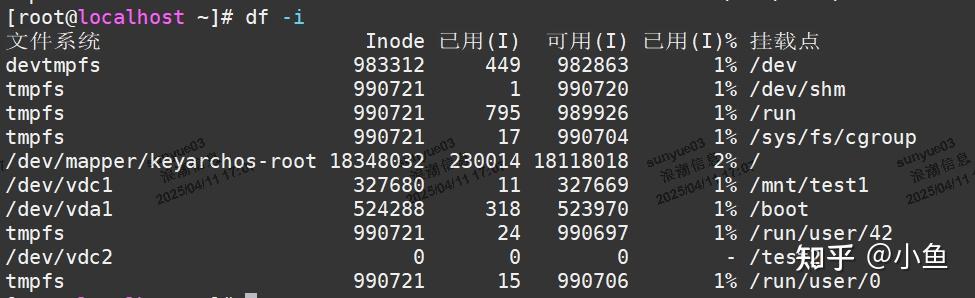
这条命令会显示系统中每个文件系统的 inode 总数、已使用 inode 数、可用 inode 数以及使用百分比。
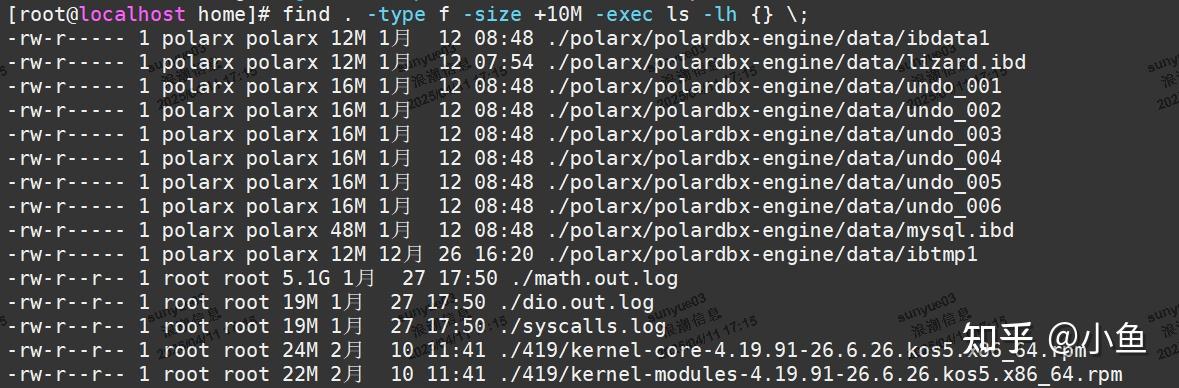
使用 find 命令
find 命令可以用来查找文件系统中占用大量 inode 的文件或目录。例如,以下命令会查找当前目录及其子目录下所有大于 10MB 的文件:
find . -type f -size +10M -exec ls -lh {} \;
检查日志文件
系统日志文件(如 /var/log/syslog 或 /var/log/messages)可能会记录关于文件系统的错误信息,包括 inode 耗尽的警告或错误。定期检查这些日志文件可以帮助诊断问题。

3.6 预防与解决 inode 耗尽的策略
inodes的大小在磁盘格式化分区时确定,跟分区的大小相关,分区越大,inodes越大,反之亦然。
linux操作系统根目录一般分区比较小,如果有定时性的小文件产生而又未及时清理,则很容易造成inodes占满。
inodes占满解决步骤:
查看文件最多的目录
for i in /*; do echo $i; find $i | wc -l; done
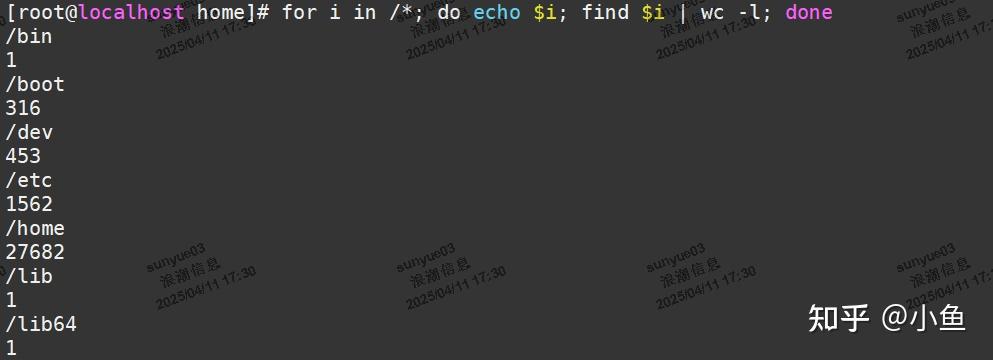
如果确定目录范围,把/*写的具体点
最终发现是/var/spool/postfix/maildrop目录下小文件过多,原因如下:
由于linux在执行cron时,会将cron执行脚本中的output和warning信息,都会以邮件的形式发送给cron所有者。由于客户环境中的sendmail和postfix没有正常运行,邮件发送不成功,导致全部小文件都堆积在maildrop目录下,另由于缺乏自动清理的机制,故此目录下堆积了大量的文件。
经过排查root用户下发现有个每分钟进行一次时钟同步的定时任务,该定时任务每分钟产生一个小文件。
删除大量文件
ls | xargs -n 1000 rm -rf

需要使用xargs命令,不然会删除失败。
设置方面
在crontab -e 第一行增加MAILTO="" ,就没有文件产生啦
重定向
对定时任务设置定向输出文件,不需要日志输出的定时任务可以将日志重定向到/dev/null,如下:
*/10 * * * * /tmp/test.sh >/dev/null 2>&1

定时清理文件
find 目录 -type f -mtime +30 | xargs -n 1000 rm -f
监控inodes的使用
备注:应注意crontab的写法和产生的文件的定时清理
3.7 实际案例分析
邮件服务器 inode 耗尽
背景:一个邮件服务器在运行过程中遇到了 inode 耗尽的问题,导致无法接收和发送邮件。
原因分析:邮件服务器在处理大量邮件时,会在特定的目录下生成大量的临时文件。如果这些临时文件没有被正确删除,或者邮件服务器软件存在 bug 导致不断生成新文件,inode 的数量就会迅速减少。
解决策略:
| 清理临时文件 | 定期检查邮件服务器生成的临时文件目录,并清理这些文件。 |
|---|---|
| 优化邮件服务器配置 | 调整邮件服务器配置,减少临时文件的使用,或者确保文件在不再需要时被正确删除。 |
| 监控和告警 | 实施监控系统,当 inode 使用率达到一定阈值时发送告警,以便及时处理。 |
版本控制系统 inode 耗尽
背景:一个使用版本控制系统(如 Git)的项目组发现,随着项目的发展,版本控制库所在的文件系统 inode 数量逐渐减少。
原因分析:版本控制系统在处理版本变更时,会生成大量的元数据文件。如果项目组频繁进行提交和分支操作,文件系统中会产生大量的文件和目录,从而导致 inode 的快速消耗。
解决策略:
| 定期清理旧版本 | 定期删除不再需要的旧版本和分支,以释放 inode。 |
|---|---|
| 使用更高效的存储策略 | 考虑使用支持 inode 高效管理的文件系统,或者优化版本控制系统的存储策略。 |
| 迁移到更大的文件系统 | 如果 inode 数量确实不足,可以考虑迁移到具有更多 inode 的文件系统。 |
通过上述案例分析,我们可以看到,inode 耗尽的问题通常是由于文件系统的使用模式和管理策略不当导致的。通过合理规划、监控、优化配置和及时清理,可以有效地避免和解决 inode 耗尽的问题。
4 处理僵尸IO请求的实战步骤
4.1 僵尸进程
当 iowait 升高时,进程很可能因为得不到硬件的响应,而长时间处于不可中断状态。从 ps 或者 top 命令的输出中,你可以发现它们都处于 D 状态,也就是不可中断状态(Uninterruptible Sleep)。既然说到了进程的状态,进程有哪些状态你还记得吗?我们先来回顾一下。
top 和 ps 是最常用的查看进程状态的工具,我们就从 top 的输出开始。下面是一个 top 命令输出的示例,S 列(也就是 Status 列)表示进程的状态。从这个示例里,你可以看到 R、D、Z、S、I 等几个状态,它们分别是什么意思呢?
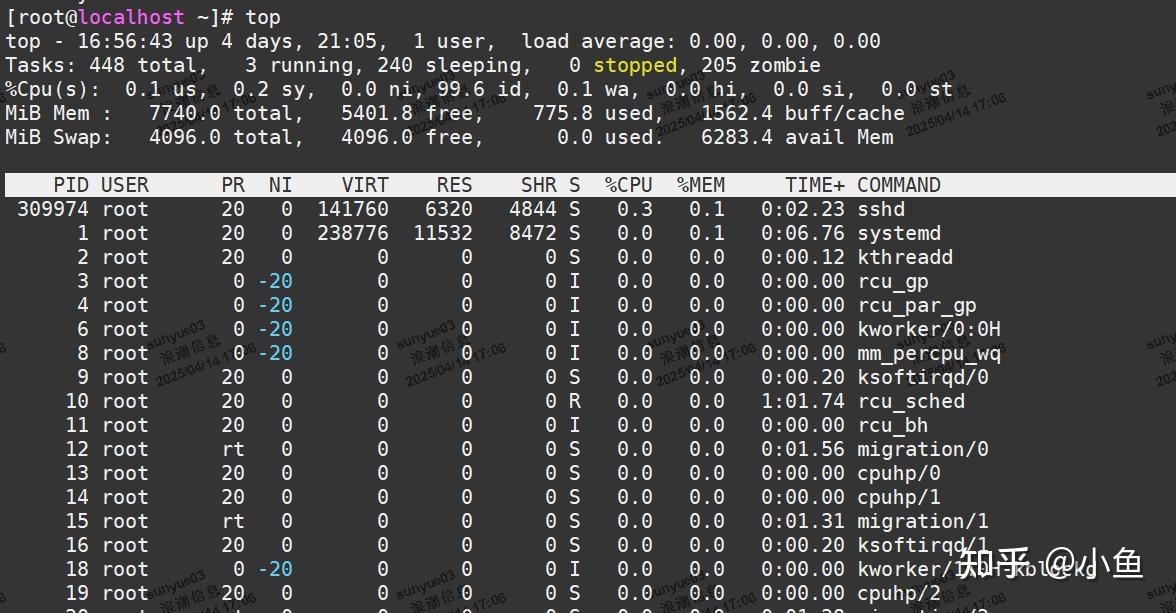
| R | Running 或 Runnable 的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行 |
|---|---|
| D | Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断 |
| Z | Zombie 的缩写,如果你玩过“植物大战僵尸”这款游戏,应该知道它的意思。它表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等) |
| S | Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态 |
| I | Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。前面说了,硬件交互导致的不可中断进程用 D 表示,但对某些内核线程来说,它们有可能实际上并没有任何负载,用 Idle 正是为了区分这种情况。要注意,D 状态的进程会导致平均负载升高, I 状态的进程却不会 |
第一个是 T 或者 t,也就是 Stopped 或 Traced 的缩写,表示进程处于暂停或者跟踪状态。
向一个进程发送 SIGSTOP 信号,它就会因响应这个信号变成暂停状态(Stopped);再向它发送 SIGCONT 信号,进程又会恢复运行(如果进程是终端里直接启动的,则需要你用 fg 命令,恢复到前台运行)。
而当你用调试器(如 gdb)调试一个进程时,在使用断点中断进程后,进程就会变成跟踪状态,这其实也是一种特殊的暂停状态,只不过你可以用调试器来跟踪并按需要控制进程的运行。另一个是 X,也就是 Dead 的缩写,表示进程已经消亡,所以你不会在 top 或者 ps 命令中看到它。
如果系统或硬件发生了故障,进程可能会在不可中断状态保持很久,甚至导致系统中出现大量不可中断进程。这时,你就得注意下,系统是不是出现了 I/O 等性能问题。
再看僵尸进程,这是多进程应用很容易碰到的问题。正常情况下,当一个进程创建了子进程后,它应该通过系统调用 wait() 或者 waitpid() 等待子进程结束,回收子进程的资源;而子进程在结束时,会向它的父进程发送 SIGCHLD 信号,所以,父进程还可以注册 SIGCHLD 信号的处理函数,异步回收资源。
如果父进程没这么做,或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经提前退出,那这时的子进程就会变成僵尸进程。换句话说,父亲应该一直对儿子负责,善始善终,如果不作为或者跟不上,都会导致“问题少年”的出现。
通常,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程退出后,由 init 进程回收后也会消亡。
一旦父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸状态。大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建,所以这种情况一定要避免。
4.2 分析
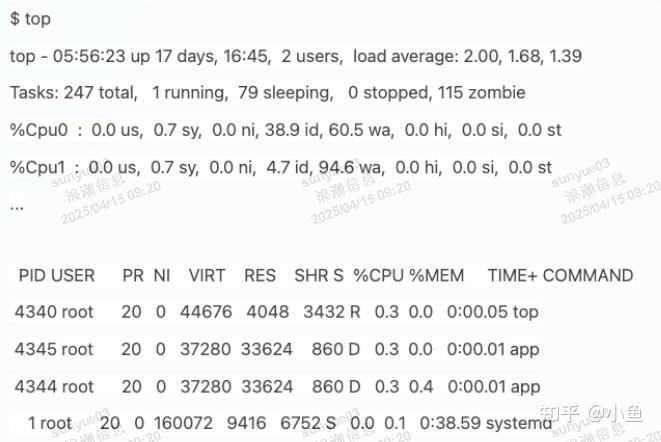
ps aux | grep /app #查看启动的APP

状态分别是 Ss+ 和 D+。其中,
S 表示可中断睡眠状态,D 表示不可中断睡眠状态,
s 表示这个进程是一个会话的领导进程,而 + 表示前台进程组。(也可通过命令查询man ps )
进程组表示一组相互关联的进程,比如每个子进程都是父进程所在组的成员
而会话是指共享同一个控制终端的一个或多个进程组。

4.3 汇总
第一点,iowait 太高了,导致系统的平均负载升高,甚至达到了系统 CPU 的个数。
第二点,僵尸进程在不断增多,说明有程序没能正确清理子进程的资源。
大量不可中断进程和僵尸进程的处理方法
现象:
iowait太高,导致平均负载升高,并且达到了系统CPU的个数
僵尸进程不断增多
分析过程:
1.先分析iowait升高的原因
一般iowait升高,可能的原因是i/o问题
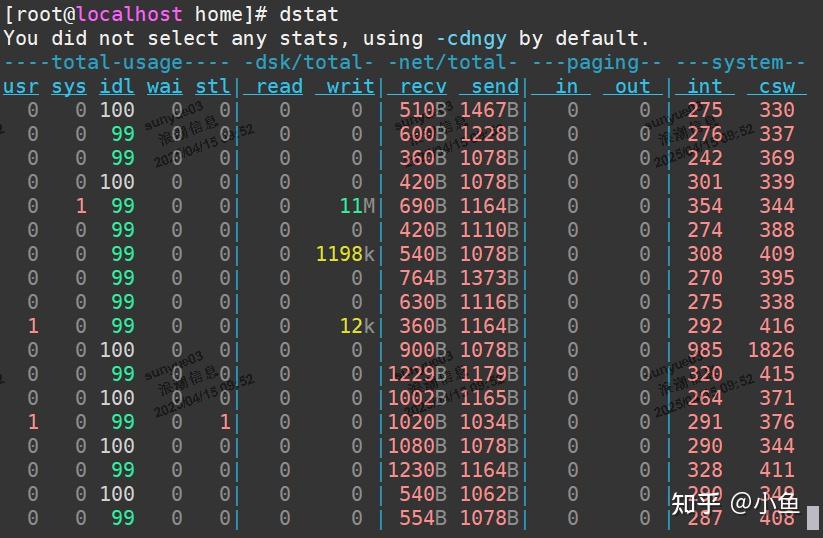
用dstat 命令同时查看cpu和i/o对比情况(如 dstat 1 10 间隔1秒输出10组数据),通过结果可以发现iowait升高时,磁盘读请求(read)升高
所以推断iowait升高是磁盘读导致
定位磁盘读的进程,使用top命令查看处于不可中断状态(D)的进程PID
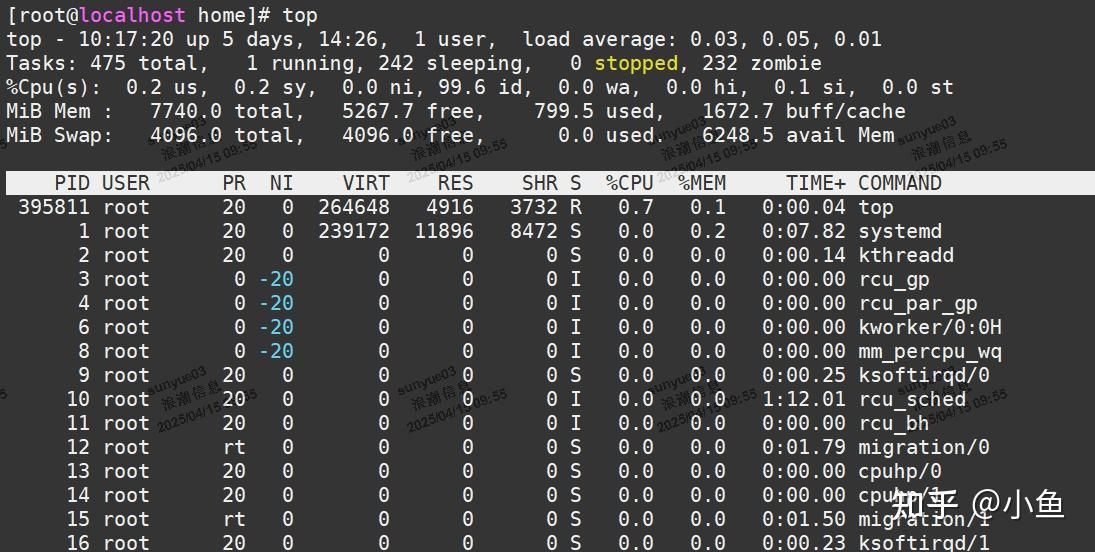
查看对应进程的磁盘读写情况,使用pidstat命令,加上-d参数,可以看到i/o使用情况(如 pidstat -d -p 1 3),发现处于不可中断状态的进程都没有进行磁盘读写

继续使用pidstat命令,但是去掉进程号,查看所有进程的i/o情况(pidstat -d 1 20),可以定位到进行磁盘读写的进程。我们知道进程访问磁盘,需要使用系统调用
下面的重点就是找到该进程的系统调用
使用strace查看进程的系统调用 strace -p

ps aux | grep 如果发现进程处于Z状态,说明已经变成了僵尸进程,不能进行系统调用分析了
既然top和pidstat都不能找出问题,使用基于事件记录的动态追踪工具
操作:
系统上运行 perf record -g ,执行一会儿按ctrl+c停止

执行perf report进一步分析,看有没有I/O操作
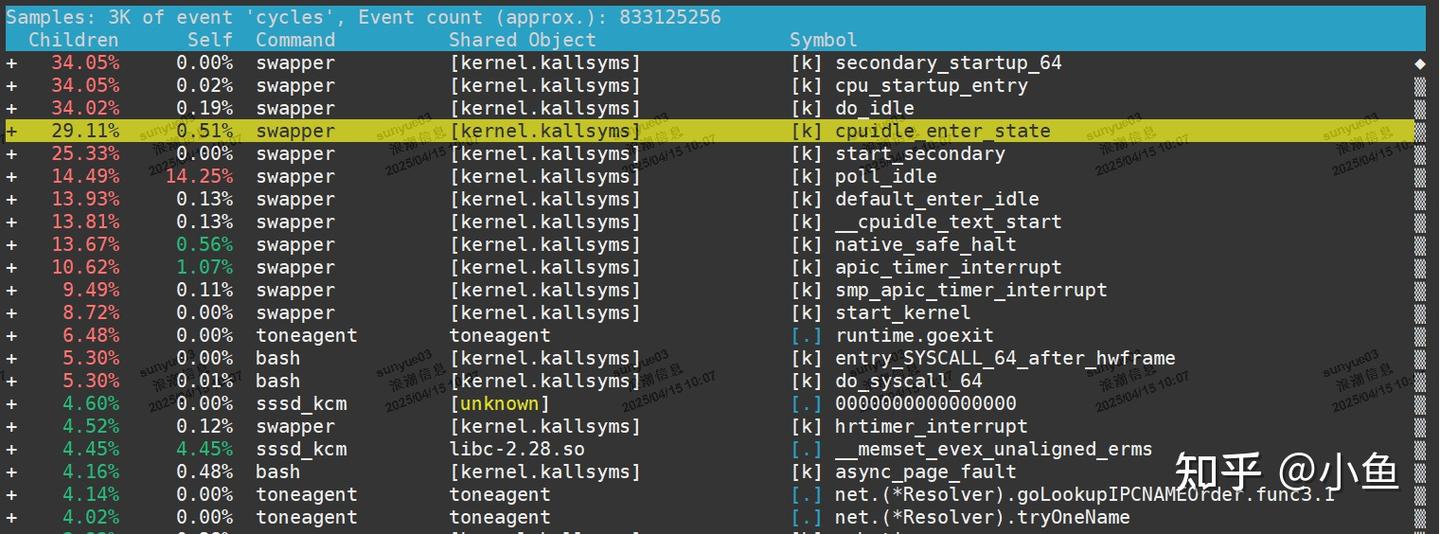
僵尸进程出现的原因是父进程没有回收子进程的资源出现的。解决办法是找到父进程,在父进程中处理,使用pstree查父进程,然后查看父进程的源码检查wait()/waitpid()的调用或SIGCHLD信号处理函数的注册
性能问题诊断与优化
5 识别IOwait的十八种姿势
5.1 什么是 iowait 以及它如何影响 Linux 性能
I/O 等待或者 iowait、wait、wa、%iowait 或 wait% 通常由 top、sar、atop 等 Linux 命令行系统监控工具显示。就其本身而言,它是让我们深入窥探 Linux 系统性能的众多性能统计数据之一。
什么是 I/O 等待?
I/O 等待适用于 Unix 和所有基于 Unix 的系统,包括 macOS、FreeBSD、Solaris 和 Linux。
I/O 等待 (iowait) 是 CPU(或多个 CPU)空闲的时间百分比,在此期间系统有待处理的磁盘 I/O 请求。(来源:man sar)top man 手册页给出了这个简单的解释:"I/O 等待 = 等待 I/O 完成的时间。" 换句话说,I/O 等待的存在告诉我们系统空闲时它可以处理未完成的请求。

在使用 Linux top 和其他工具时,你会注意到 CPU(及其核心)在以下状态下运行:us(用户态)、sy(内核态)、id(空闲)、ni(nice)、si(软中断)、hi(硬中断)、st(steal)和 wa(等待)。其中,用户态、内核态、空闲状态和等待状态的值加起来应为 100%。请注意,"idle" 和 "wait" 是不同的。"idle" CPU 表示没有工作负载存在,而另一方面,"wait" (iowait) 表示 CPU 何时处于空闲状态等待未完成的请求。
如果 CPU 空闲,内核将确定任何来自 CPU 的未完成 I/O 请求(比如 SSD 或 NFS)。如果有,则 "iowait" 计数器递增。如果没有任何待处理的请求,则 "idle" 计数器会增加。
I/O 等待和 Linux 服务器性能
值得注意的是, iowait 有时可以指示吞吐量瓶颈,而在其他时候,iowait 可能完全没有意义。有可能拥有高 iowait 的健康系统,但也可能有完全没有 iowait 的存在瓶颈的系统。
I/O 等待只是 CPU / CPU 核心的指示状态之一。高 iowait 意味着你的 CPU 正在等待请求,但你需要进一步调查以确认来源和影响。
例如,服务器存储(SSD、NVMe、NFS 等)几乎总是比 CPU 性能慢。因此,I/O 等待可能会产生误导,尤其是涉及到随机读/写工作负载时。这是因为 iowait 仅测量 CPU 性能,而不测量存储 I/O。
虽然 iowait 表明 CPU 可以处理更多的工作负载,但根据服务器的工作负载以及负载如何执行计算或使用存储 I/O,并不总是可以解决 I/O 等待。或者实现接近于零的值是不可行的。
根据最终用户体验、数据库查询健康状况、事务吞吐量和整体应用程序健康状况,你必须决定报告的 iowait 是否表明 Linux 系统性能不佳。
例如,如果你看到 1% 到 4% 的低 iowait,然后将 CPU 升到 2 倍的性能,iowait 也会增加。具有相同存储性能的 2 倍更快的 CPU = ~ 2 倍的等待时间。你需要考虑你的工作负载来确定应该首先关注哪些硬件。
监控和减少 I/O 等待相关问题
让我们看看一些用于监视 Linux 上的 I/O 等待的有价值的工具。

5.2 减少 I/O 等待相关问题
采取以下步骤减少与 I/O 等待相关的问题:
| 1 | 优化应用程序的代码和数据库查询。这可以大大降低磁盘读/写的频率。这应该是你的第一个方法,因为应用程序越高效,在硬件上的长期花费就越少。 |
|---|---|
| 2 | 使 Linux 系统和软件版本保持最新。这不仅对安全性更好,而且通常情况下,最新支持的版本会提供显着的性能改进,无论是 Nginx、Node.js、PHP、Python 还是 MySQL。 |
| 3 | 确保有空闲的可用内存。足够的空闲内存,以便大约一半的服务器内存用于内存缓冲区和缓存,而不是交换和换页到磁盘。当然,这个比例会因情况而异。因此,请确保你没有交换,并且内核缓存压力不会因缺少可用内存而变高。 |
| 4 | 调整系统、存储设备和 Linux 内核以提高存储性能和使用寿命。 |
| 5 | 如果一切都失败了:将存储设备升级到更快的 SSD、NVMe 或其他高吞吐量存储设备。 |
5.3 top命令显示iowait (wa)非常高时怎么排查
当 top 命令显示 iowait (wa) 非常高时,表示系统正在等待 I/O 操作完成。要确定是磁盘 I/O 还是网络 I/O 导致的等待,可以使用以下工具和方法进行进一步排查。
使用 iostat 检查磁盘 I/O
iostat 是一个专门用于监控磁盘 I/O 的工具,可以显示磁盘的读写速度和等待时间。
安装 iostat(如果未安装):
yum install sysstat

使用 iostat 查看磁盘 I/O:
iostat -x 1
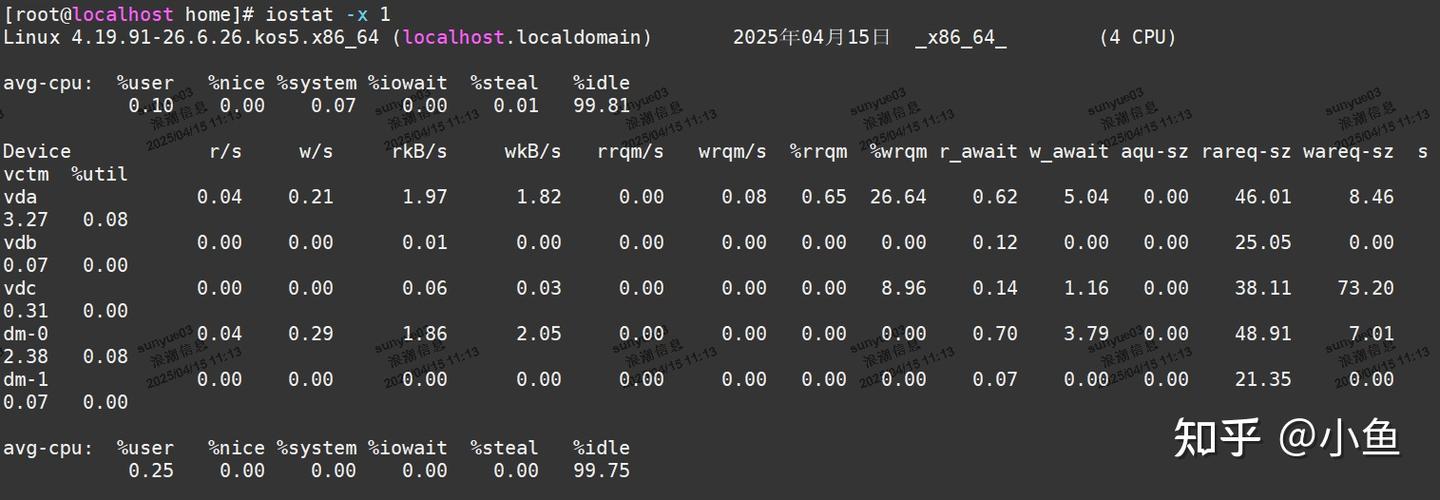
-x:显示扩展统计信息。
1:每秒刷新一次。
关键指标:
| %util | 磁盘利用率。如果接近 100%,表示磁盘 I/O 是瓶颈。 |
|---|---|
| await | 平均 I/O 等待时间(毫秒)。如果较高,表示磁盘响应慢。 |
| r/s 和 w/s | 每秒的读写操作数。 |
如果 %util 和 await 较高,说明磁盘 I/O 是导致 iowait 高的原因。
使用 iotop 检查磁盘 I/O
iotop 是一个实时监控磁盘 I/O 的工具,可以显示每个进程的磁盘读写情况。
安装 iotop(如果未安装):
yum install iotop
使用 iotop:
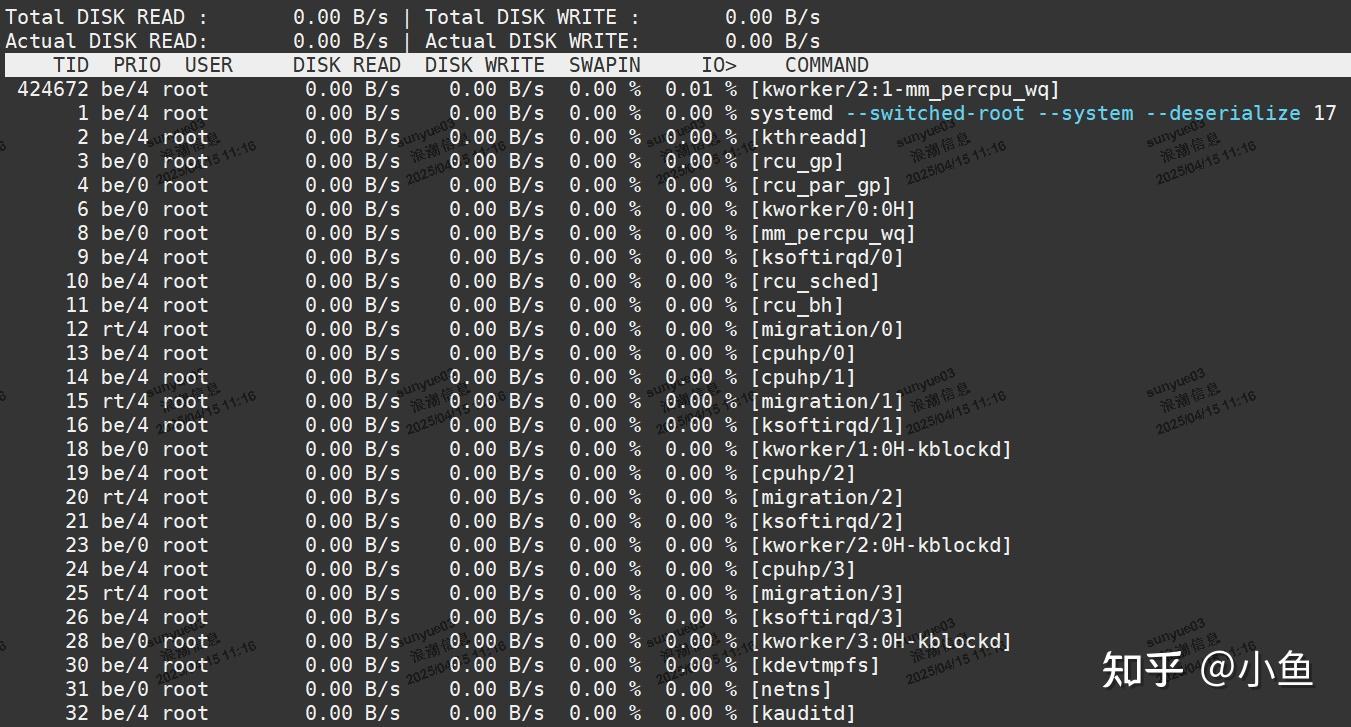
查看哪些进程正在大量读写磁盘。
如果某些进程的磁盘读写量(DISK READ 和 DISK WRITE)非常高,说明它们可能是导致磁盘 I/O 瓶颈的原因。
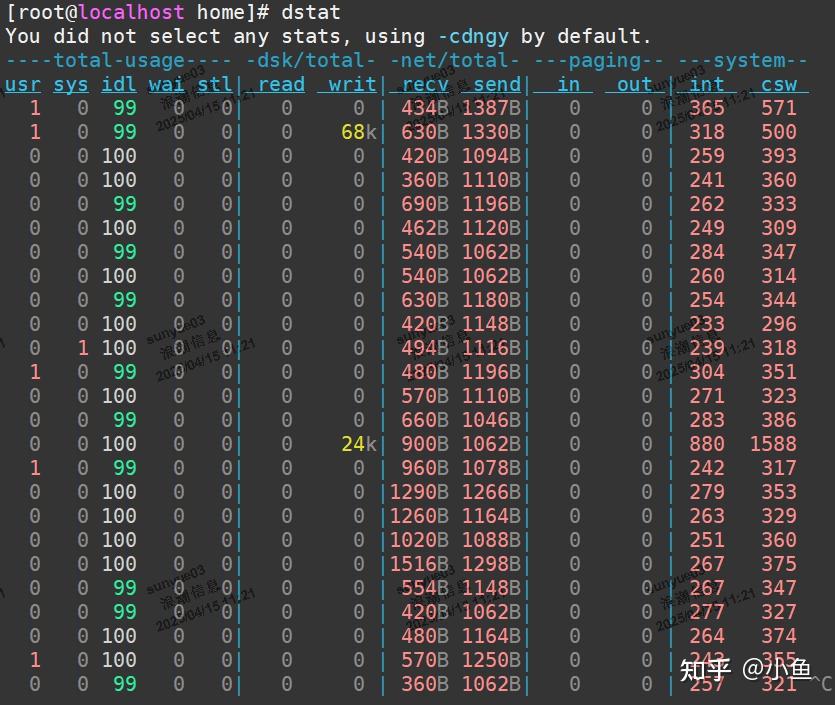
使用 dstat 综合检查
dstat 是一个多功能工具,可以同时监控 CPU、磁盘、网络等资源。
安装dstat:
yum install dstat

使用 dstat:
查看 CPU、磁盘、网络等资源的实时使用情况。
如果磁盘或网络的使用率非常高,说明它们可能是导致 iowait 高的原因。
5.4 总结
iowait 统计数据是一个有用的性能统计数据,可用于监控 CPU 利用率健康状况。当 CPU 空闲并且可以执行更多计算时,它会通知系统管理员。然后,我们可以使用可观察性、基准测试和跟踪工具(例如上面列出的那些工具)来综合了解系统的整体 I/O 性能。你的主要目标应该是消除因等待磁盘、NFS 或其他与存储相关的 I/O 而直接导致的任何 iowait。
6 使用SystemTap分析锁竞争
6.1 SystemTap简介
SystemTap 是一个强大的工具,用于在不修改内核源代码的情况下,对 Linux 内核进行监控和调试。它允许你编写脚本(通常是使用 Stap 语言),来监视和分析系统运行时的行为。想使用 SystemTap 来分析 Linux 文件系统的锁竞争问题,可以按照以下步骤进行:
安装 SystemTap
安装依赖
yum install gcc make elfutils-libelf-devel rpm-devel nss-devel python3-devel
下载软件包
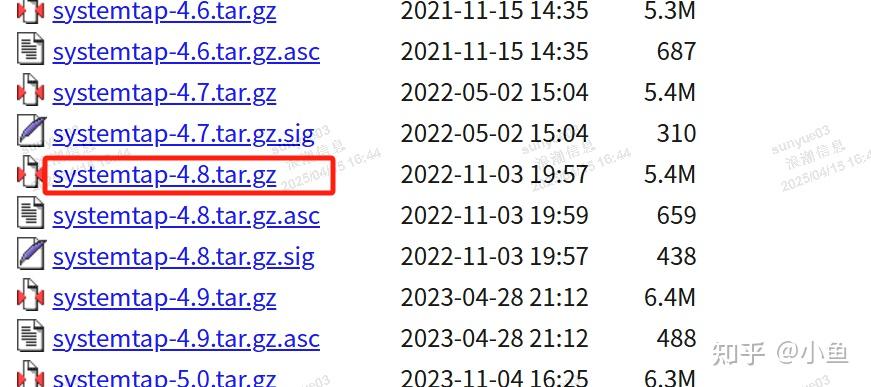
https://sourceware.org/systemtap/ftp/releases/下载systemtap-4.8.tar.gz
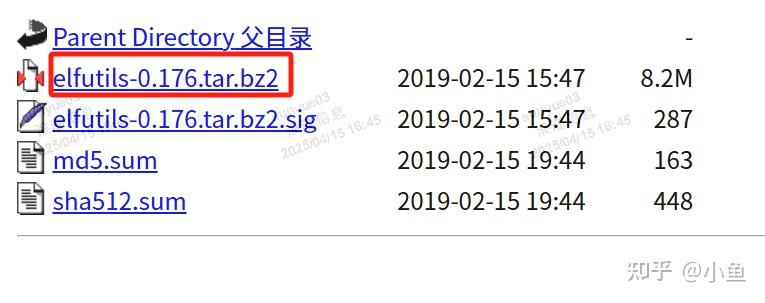
https://sourceware.org/elfutils/ftp/0.176/下载elfutils-0.176.tar.bz2
上传至服务器并解压
tar -zxvf systemtap-4.8.tar.gz
tar -xjf elfutils-0.176.tar.bz2
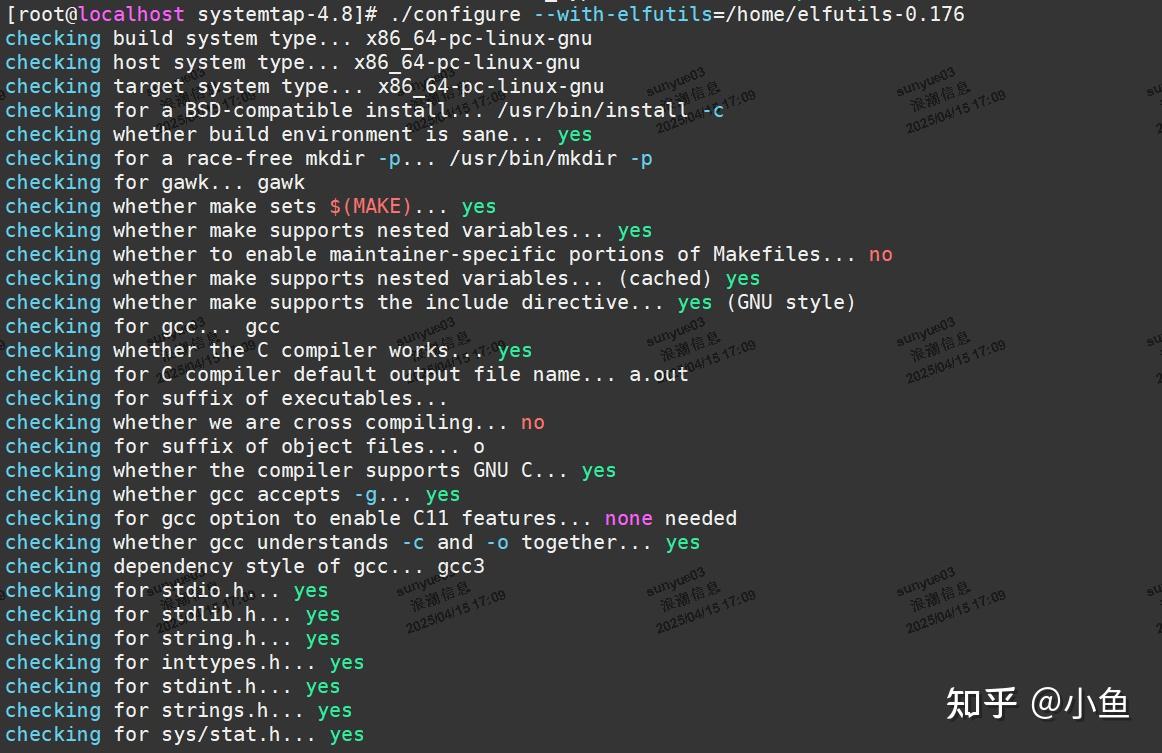
cd到systemtap-4.8目录开始编译安装
./configure --with-elfutils=./elfutils-0.176
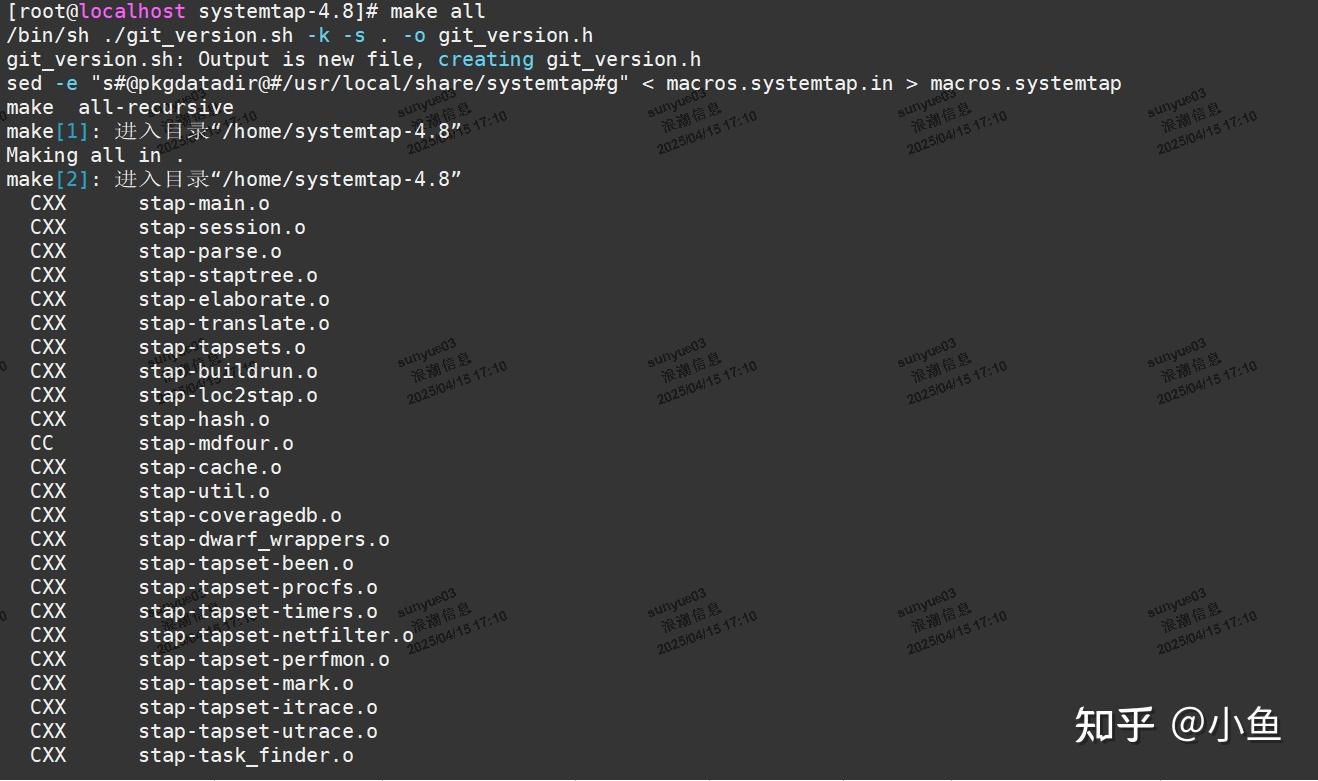
make all
make install
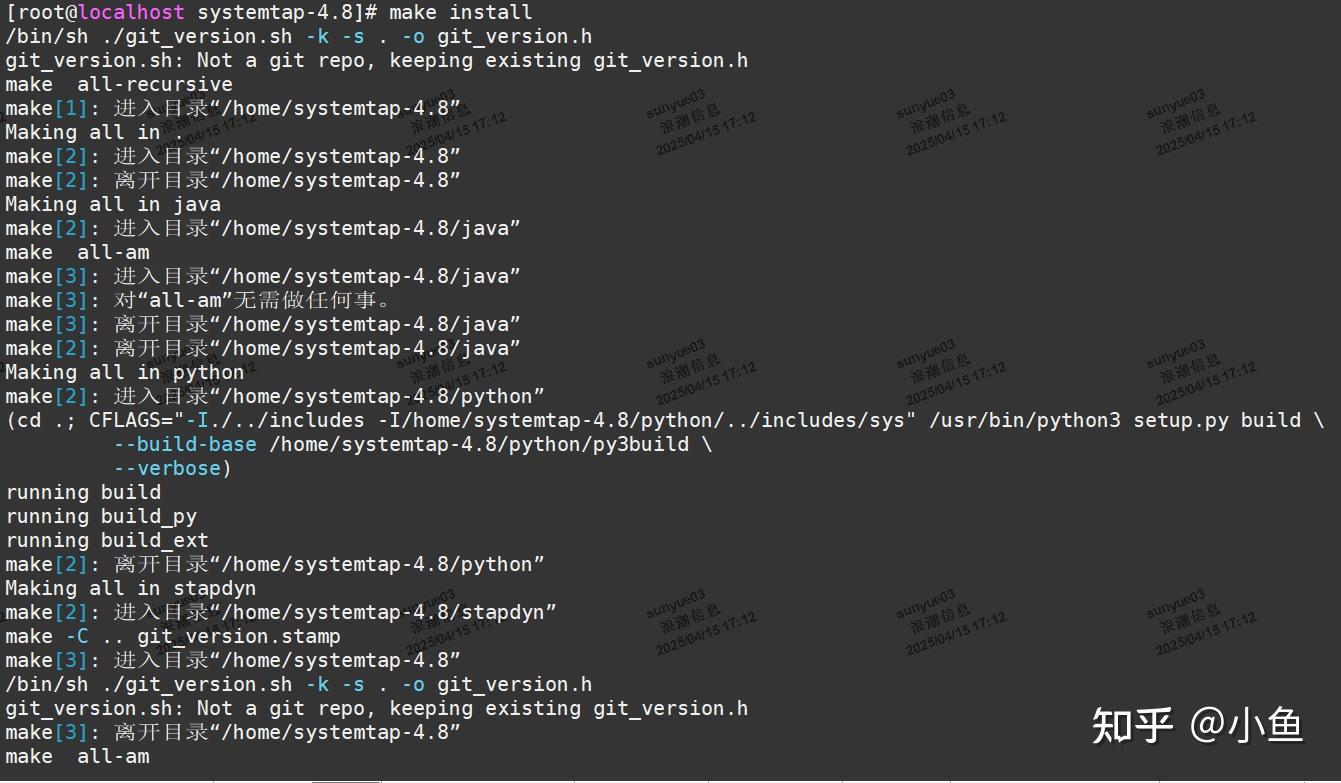
mv /usr/bin/stap /usr/bin/stap.bak
mv stap /usr/bin/
stap -V

6.2 理解文件系统锁
在分析之前,需要了解 Linux 文件系统的锁机制,了解哪些操作会触发锁的获取和释放是非常重要的。
Linux文件系统的锁机制主要包括建议性锁和强制性锁。建议性锁要求进程显式地检查锁的存在并尊重已有的锁,而强制性锁则由内核强制执行,当一个文件被上锁进行写入操作时,内核会阻止其他进程对该文件进行读写操作。
强制性锁
强制性锁是由内核执行的锁,当一个进程对文件设置了强制性锁后,其他进程试图对该文件进行读写操作时会被阻塞,直到锁被释放。这种锁主要用于保护文件的完整性,防止数据损坏。在Linux中,实现强制性锁的函数主要有fcntl和lockf。fcntl函数提供了细粒度的文件锁控制,可以用来实现强制性锁。其函数原型如下:

其中,cmd参数可以取以下值:
| F_SETLKW | 设置锁并等待,如果无法立即获取锁,则阻塞直到锁可用。 |
|---|---|
| F_SETLK | 设置锁但不等待,如果无法立即获取锁,则返回错误。 |
| F_GETLK | 获取锁状态。 |
建议性锁
建议性锁要求每个使用上锁文件的进程都要检查是否有锁存在,并且尊重已有的锁。在一般情况下,内核和系统不使用建议性锁,而是依靠程序员遵守这个规定。实现建议性锁的函数有lockf()和fcntl()。lockf函数用于对文件施加建议性锁,其函数原型如下:
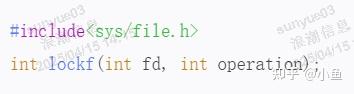
其中,operation参数可以取以下值:
| LOCK_SH | 共享锁,允许多个进程对同一文件读取,不允许写入。 |
|---|---|
| LOCK_EX | 排他锁(写锁),确保只有一个进程能够写入文件。 |
| LOCK_UN | 解锁操作,释放锁。 |
| LOCK_NB | 非阻塞锁标志,与LOCK_SH或LOCK_EX组合使用,如果无法立即加锁,则返回错误并设置errno为EWOULDBLOCK。 |
6.3 编写 SystemTap 脚本
创建一个 SystemTap 脚本来跟踪文件系统的锁操作。以下是一个基本的示例,用于探测通用VFS锁调用:
global lock_acquires, lock_releases
probe kernel.function("__lock_buffer").entry {
lock_acquires++
}
probe kernel.function("unlock_buffer").entry {
lock_releases++
}
probe timer.ms(1000) {
printf("Lock Acquires: %d\n", lock_acquires)
printf("Lock Releases: %d\n", lock_releases)
lock_acquires = 0
lock_releases = 0
}
这个脚本会监控__lock_buffer和unlock_buffer函数的调用次数,并每秒打印一次这些次数。
6.4 运行 SystemTap 脚本
保存你的脚本到一个文件中,例如 fs_locks.stp,然后使用以下命令运行它:
stap fs_locks.stp
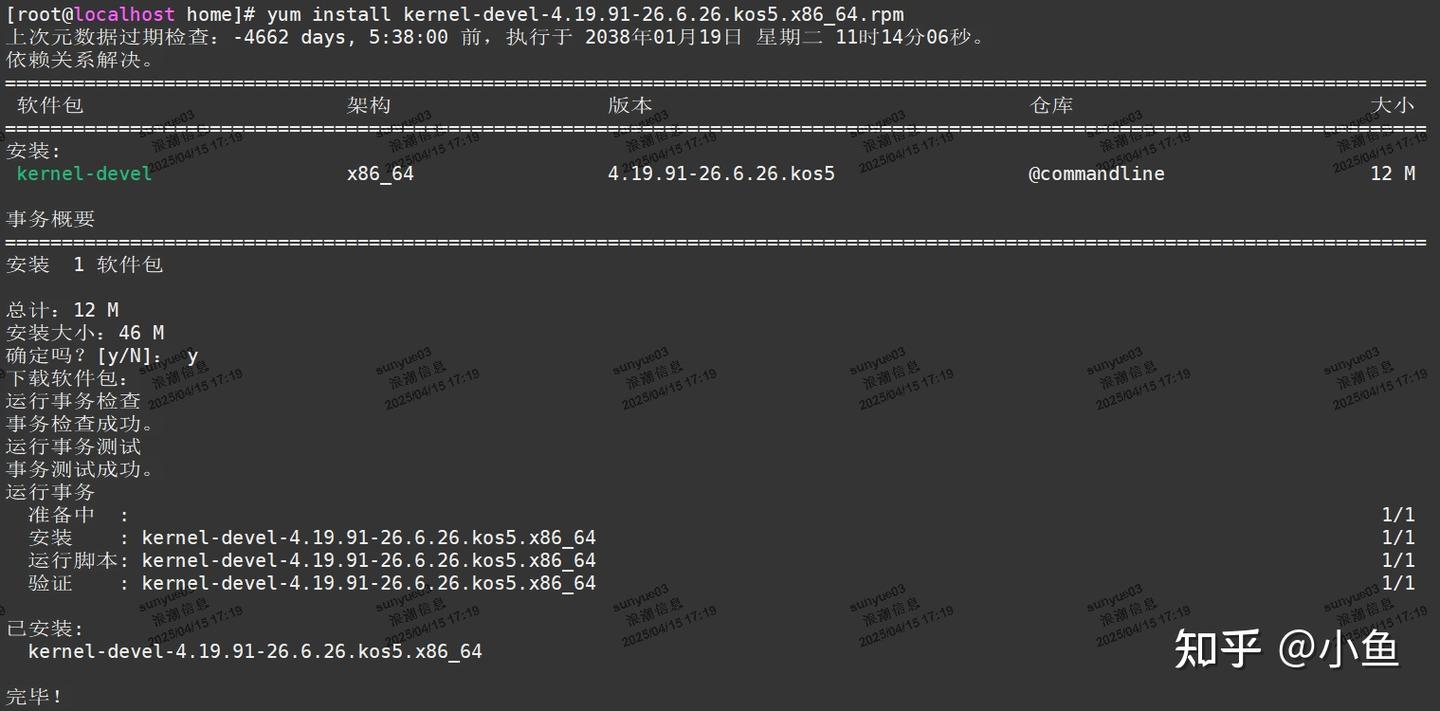
运行之前需要先下载一个内核devel包并安装,如我们这里下载安装kernel-devel-4.19.91-26.6.26.kos5.x86_64.rpm
再运行脚本
6.5 分析输出
观察输出的锁获取和释放次数,以识别是否存在频繁的锁竞争。如果发现锁竞争非常高,可能需要进一步分析哪些操作导致了这些锁的频繁获取和释放。
6.6 深入分析
如果你发现某些特定的函数或操作导致锁竞争,你可以进一步细化你的 SystemTap 脚本,例如跟踪特定函数的调用路径或参数:
probe kernel.function("some_specific_function").call {
printf("Function called: %s\n", probefunc())
}
7 文件系统性能优化
由于各种的I/O负载情形各异,Linux系统中文件系统的缺省配置一般来说都比较中庸,强调普遍适用性。然而在特定应用下,这种配置往往在I/O性能方面不能达到最优。因此,如果应用对I/O性能要求较高,除了采用性能更高的硬件(如磁盘、HBA卡、CPU、MEM等)外,我们还可以通过对文件系统进行性能调优,来获得更高的I/O性能提升。总的来说,主要可以从三个方面来做工作:
| 1 | Disk相关参数调优 |
|---|---|
| 2 | 文件系统本身参数调优 |
| 3 | 文件系统挂载(mount)参数调优 |
当然,负载情况不同,需要结合理论分析与充分的测试和实验来得到合理的参数。下面以SATA磁盘上的EXT3文件系统为例,给出Linux文件系统性能优化的一般方法。请根据自身情况作适合调整。
7.1 Disk相关参数
Cache mode:启用WCE=1(Write Cache Enable), RCD=0(Read Cache Disable)模式
启用写缓存
hdparm -W 1 /dev/sda

禁用读缓存
hdparm -R 0 /dev/sda

Linux I/O scheduler算法
经过实验,在重负载情形下,deadline调度方式对squidI/O负载具有更好的性能表现。其他三种为noop(fifo), as, cfq,noop多用于SAN/RAID存储系统,as多用于大文件顺序读写, cfq适于桌面应用。
echo deadline > /sys/block/vdc/queue/scheduler

deadline调度参数
对于redhat linux建议 read_expire = 1/2 write_expire,对于大量频繁的小文件I/O负载,应当这两者取较小值。更合适的值,需要通过实验测试得到。
echo 500 > /sys/block/vdc/queue/iosched/read_expire
echo 1000 > /sys/block/vdc/queue/iosched/write_expire

readahead 预读扇区数
预读是提高磁盘性能的有效手段,目前对顺序读比较有效,主要利用数据的局部性特点。比如在我的系统上,通过实验设置通读256块扇区性能较优。
blockdev --setra 256 /dev/vdc

7.2 EXT3文件系统参数
block size = 4096 (4KB)
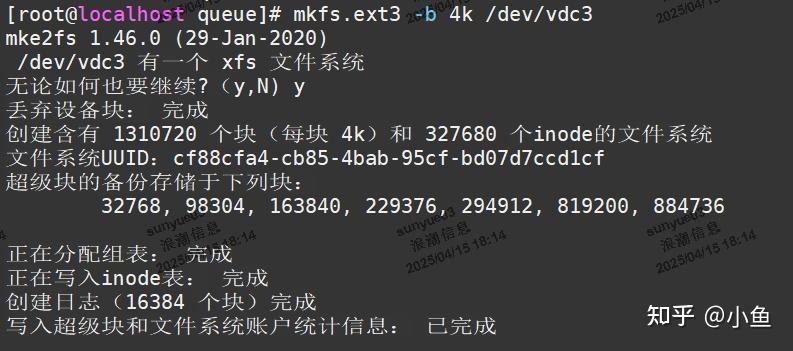
mkfs.ext3 -b指定,大的数据块会浪费一定空间,但会提升I/O性能。EXT3文件系统块大小可以为1KB、2KB、4KB。
如:
inode size
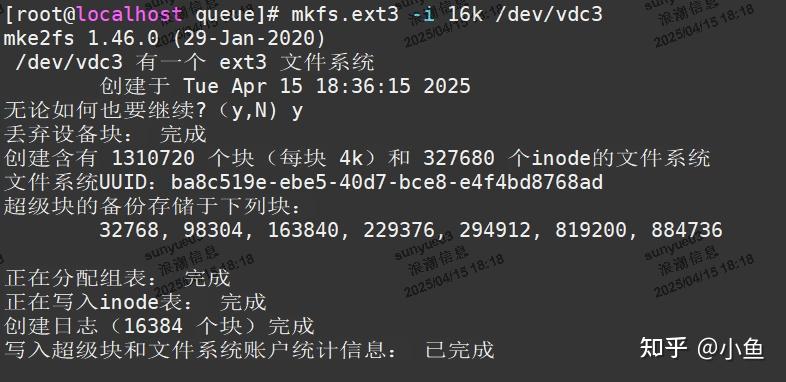
这是一个逻辑概念,即一个inode所对应的文件相应占用多大物理空间。mkfs.ext3 -i指定,可用文件系统文件大小平均值来设定,可减少磁盘寻址和元数据操作时间。
推荐值:

如:
reserved block
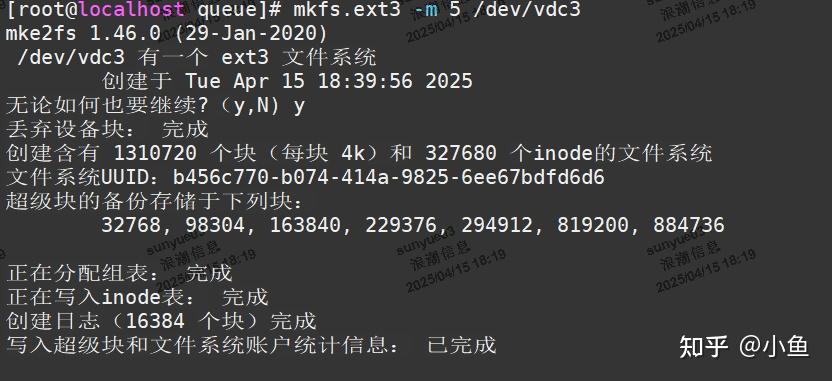
mkfs.ext3 -m指定,缺省为5%,可调小该值以增大部分可用存储空间。
如:
disable journal
对数据安全要求不高的应用(如web cache),可以关闭日志功能,以提高I/O性能。
tune2fs -O^has_journal /dev/vdc3

7.3 mount参数
| noatime, nodirtime | 访问文件目录,不修改访问文件元信息,对于频繁的小文件负载,可以有效提高性能。 |
|---|---|
| async | 异步I/O方式,提高写性能。 |
| data=writeback (if journal) | 日志模式下,启用写回机制,可提高写性能。数据写入顺序不再保护,可能会造成文件系统数据不一致性,重要数据应用慎用。 |
| barrier=0 (if journal) | barrier=1,可以保证文件系统在日志数据写入磁盘之后才写commit记录,但影响性能。重要数据应用慎用,有可能造成数据损坏。 |
可依据以上三块调优方向的方法并根据自身情况进行调整,来获得更高的I/O性能提升。


技术共进,成长同行——讯飞AI开发者社区
更多推荐

 23
23 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)