
RAG大模型的基础入门
大模型通常指包含数十亿甚至数千亿参数的模型,通过大模型数据和计算资源训练,能够处理复杂任务并生成高质量结果RAG是一种结合了检索和生成的人工智能模型,它通过检索外部知识来增强生成的回答为了改善大模型输出在时效性。可靠性与准确性方面的不足,以便让其在更广泛的空间大展拳脚。RAG是一种被广泛研究与应用的优化架构,截止目前,RAG在大量的场景中展现了自己强大的适应性和生命力。
一、大模型的定义与特点
大模型是指参数量巨大,结构复杂的机器学习模型,通常基于深度学习技术,尤其是自然语言处理(NLP)、计算机视觉(CV)等领域表现突出
①定义:
大模型通常指包含数十亿甚至数千亿参数的模型,通过大模型数据和计算资源训练,能够处理复杂任务并生成高质量结果
②特点:
①参数量大:大模型拥有数十亿到数千亿的参数,能够捕捉数据中的复杂模式和细微特征
②训练数据规模大:需要海量数据进行训练,通常覆盖互联网文本、图像音频等
③计算资源需求高:训练和推理过程依赖高性能计算设备,如GPU,耗时长,成本高
④泛化能力强:经过大模型训练后,大模型在多种任务上表现出色,具备较强的学习能力
... ...
典型的RAG应用:GPT、VISION、CLIP
大模型凭借其强大的处理能力和广泛的应用前景,推动了人工智能的发展,但也面临资源消耗,下面结合图片来为大家简单介绍大模型
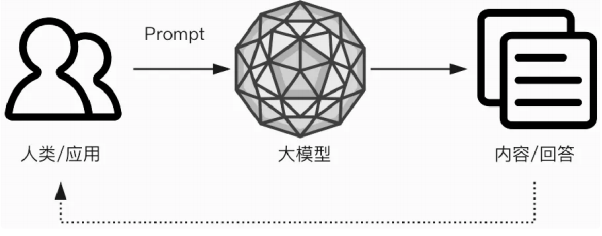
该图展示了一个信息处理与反馈的基本流程,通常用于描述人工智能(AI)系统中的交互过程
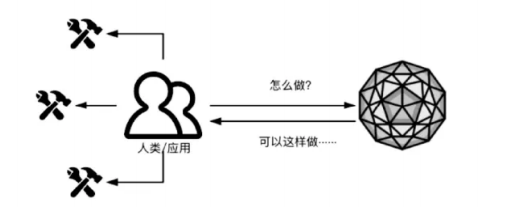
该图进一步阐述了人类或应用程序与大模型人工智能模型之间的交互过程,并且强调了反馈和迭代的重要性
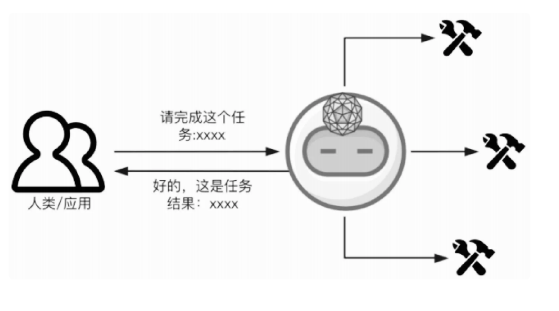
该图展示了一个任务分配和执行的流程,其中涉及到人类或应用程序与人工智能模型的交互
③主要不足:
尽管大模型在人工智能领域取得了显著成就,但是大模型真的是无所不能的吗?
①资源消耗巨大 ②数据依赖性 ③可解释性差 ④泛化能力有限
⑤伦理安全问题 ⑥部署与维护复杂 ⑦经济和社会影响 ⑧模型规模与效率的平衡
二、了解RAG
①什么是RAG
RAG是一种结合了检索和生成的人工智能模型,它通过检索外部知识来增强生成的回答
为了改善大模型输出在时效性。可靠性与准确性方面的不足,以便让其在更广泛的空间大展拳脚。
RAG是一种被广泛研究与应用的优化架构,截止目前,RAG在大量的场景中展现了自己强大的适应性和生命力
RAG的基本思想:将传统的生成式大模型与实时信息检索技术相结合,为大模型补充来写外部的相关数据与上下文,以帮助大模型生成更丰富、更准确、更可靠的内容。这允许大模型在生成内容时可以依赖实时与个性化的数据和知识,而不只是依赖训练知识
在这里也用一个图来描述外部知识来增强大型人工智能模型的流程
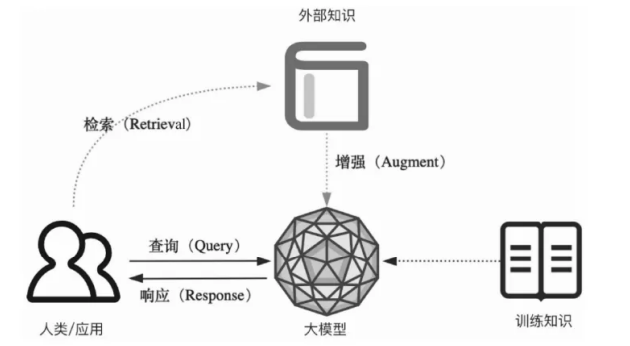
②RAG应用的经典架构与流程
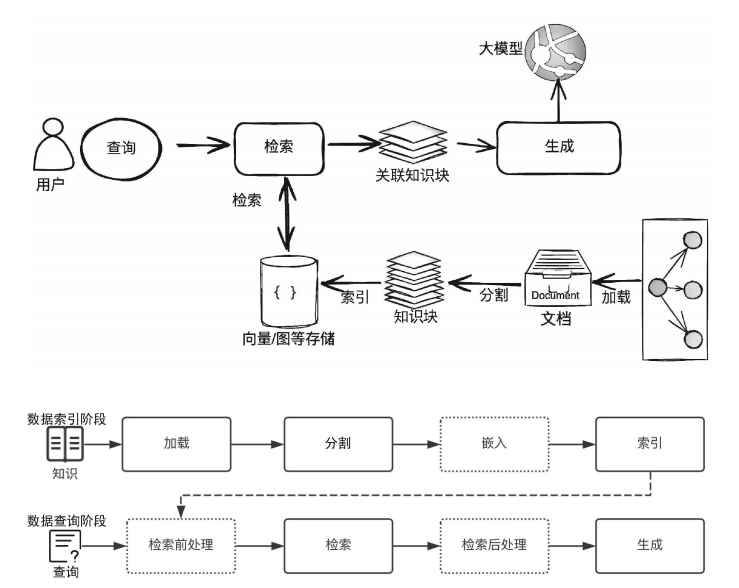
在通常情况下,可以把开发一个简单的RAG应用从整体上分为数据索引(Indexing)与数据查询(Query)两个大的阶段,在每个阶段都包含不同的处理阶段
③数据索引阶段
既然RAG的核心之一是通过“检索”来增强生成,那么首先需要准备可以检索的内容。最常用的是基于关键词的检索,比如传统的搜索引擎或者关系数据库,通过关键词的匹配程度来对知识库中的信息进行精确或模糊的检索,但是在大模型RAG应用中,最常见的检索方式是借助基于向量的语义检索来获得相关的数据块,并根据其相似度排序,最后输出最相关的前K个数据(简称top_k)。因此,向量存储索引就成了RAG应用中最常见的索引形式
| 向量是一种数学表示⽅法,它将⽂本、图像、⾳频等复杂信息转换为⾼维空间中的点,每个维度都代
表⼀种特征或属性。这种转换使得计算机可以理解和处理这些信息,因为它们都是连续的多个数值。
向量保留了词汇之间的语义关系。例如,相似的词在向量空间中距离较近,这样就可以进⾏语义相似
度计算或进⾏聚类分析。
⾃然语⾔处理中⽤于把各种形式的信息转换成向量表示的模型叫嵌入模型。基于向量的语义检索就是
通过计算查询词与已有信息向量的相似度(如余弦相似度),找出与查询词在语义上最接近的信息
|
数据索引阶段通常包含以下几个关键阶段:
①加载(Loading):RAG 应用需要的知识可能以不同的形式与模态存在,可以是结构化的、半结构化的、非结构化的、存在于互联网上或者企业内部的、普通⽂档或者问答对。因此,对这些知识,需要 能够连接与读取内容
②分割(Splitting):为了更好地进行检索,需要把较⼤的知识内容(⼀个 Word/PDF 文档、⼀个 Excel 文档、⼀个网页或者数据库中的表等)进行分割,然后对这些分割的知识块(通常称为Chunk)进行索引
③嵌入(Embedding):如果你需要开发 RAG 应⽤中最常见的向量存储索引,那么需要对分割后的知识块做嵌入
④索引(Indexing):对于向量存储索引来说,需要将嵌入阶段生成的向量存储到内存或者磁盘中做持久化存储。在实际应用中,通常建议使用功能全面的向量数据库(简称向量库)进行存储与索引。向量库会提供强大的向量检索算法与管理接口,这样可以很方便地对输入问题进行语义检索
④数据查询阶段
在数据索引准备完成后,RAG应用在数据查询阶段的两大核心阶段是检索与生成(也称为合成)
(1)检索(Retrieval):检索的作用是借助数据索引(比如向量存储索引),从存储库(比如向量库)中检索出相关知识块,并按照相关性进行排序,经过排序后的知识块将作为参考上下文用于后面的生成
(2)生成(Generation):生成的核心是大模型,可以是本地部署的大模型,也可以是基于API访问的远程大模型,生成器根据检索阶段输出的相关知识块与⽤户原始的查询问题,借助精⼼设计的Prompt,生成内容并输出结果
②检索后处理:与检索前处理相对应,这是在完成检索后对检索出的相关知识块做必要补充处理的阶段,比如,对检索的结果借助更专业的排序模型与算法进行重排序或者过滤掉⼀些不符合条件的知识块等,使得最需要、最合规的知识块处于上下文的最前端,这有助于提高大模型的输出质量

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)