
使用kettle将1亿数据导入mysql
一、导入思路二、准备一份亿级数据t_user.txttxt中数据只有连个字段,用;隔开,如下0;程序不就是0和1_01;程序不就是0和1_12;程序不就是0和1_2...可以通过一下程序生成生成的文件大约4G主要mysql所在的磁盘预留足够空间,由于有binlog日志和数据,所以大约会占用15G。三、建立数据库表t_user四、运行kettle1.在左侧转换,点击新建,在核心对象的【输入】中选择文
·
一、导入思路
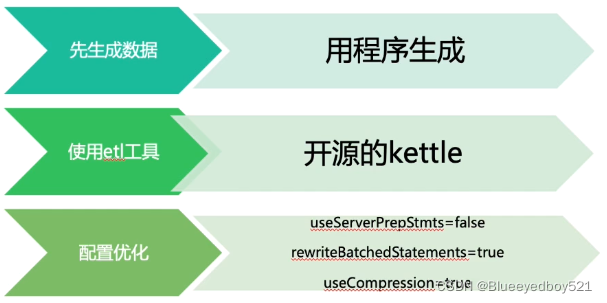
二、准备一份亿级数据t_user.txt
txt中数据只有连个字段,用;隔开,如下
0;程序不就是0和1_0
1;程序不就是0和1_1
2;程序不就是0和1_2
.
.
.
可以通过一下程序生成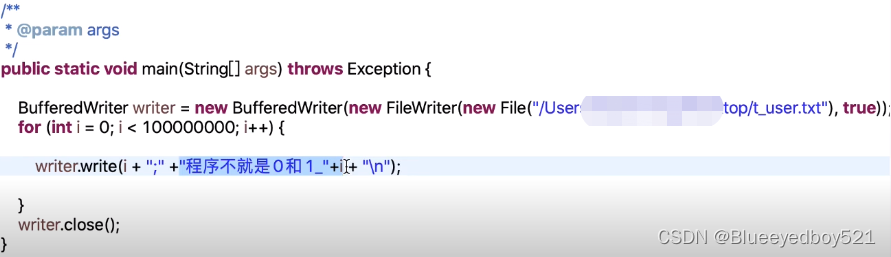
生成的文件大约4G
主要mysql所在的磁盘预留足够空间,由于有binlog日志和数据,所以大约会占用15G。
三、建立数据库表t_user

四、运行kettle
1.在左侧转换,点击新建,在核心对象的【输入】中选择文本,然后拖入右侧工作面
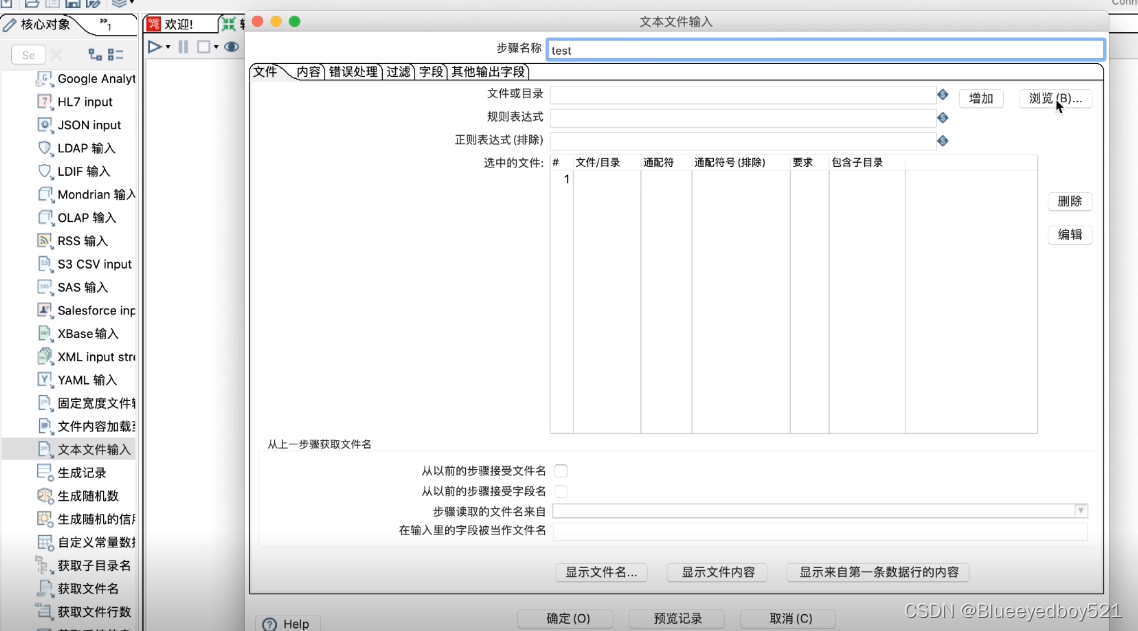
浏览选择文件t_user.txt,并且点击增加,添加到选中的文件
2.配置字段

3. 选择【输出】点击表输出,拖入到右侧工作面,配置mysql连接
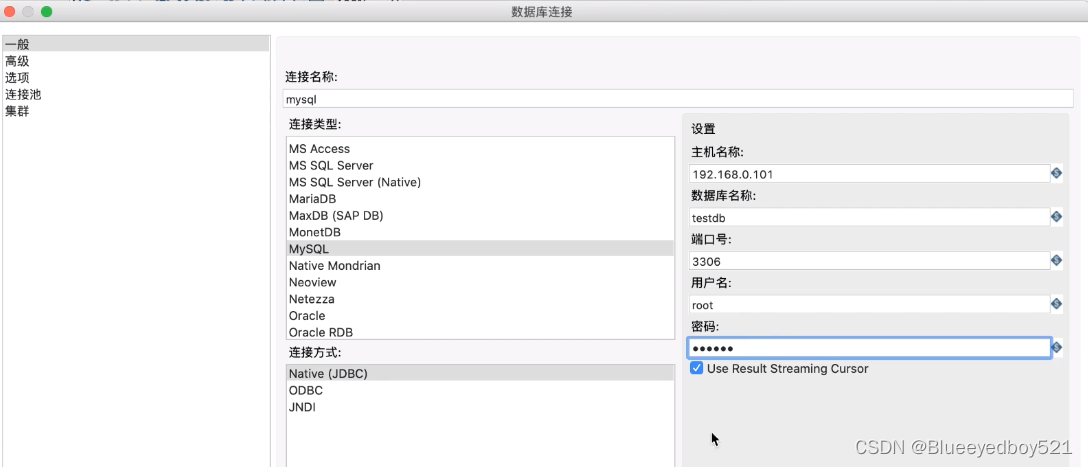
3. 配置表输出
1)、选择目标表t_user
2)、配置提交记录数10000,表示每一万提交一次事务
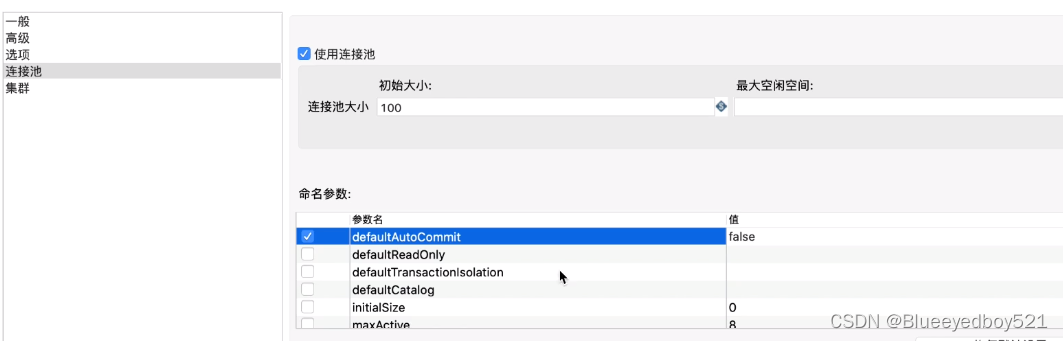
3)、配置连接池,初始化100,命令参数,配置默认提交是false;其他保持默认
4)、配置选项,关闭预编译等
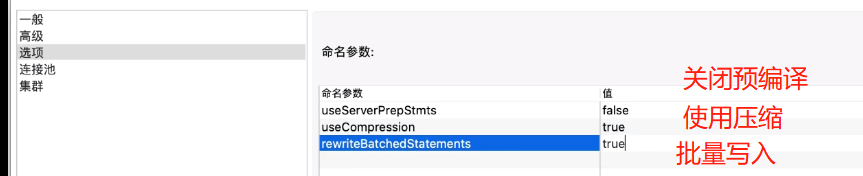
useServerPrepStmts:false;关闭预编译
useCompression:true;使用压缩
rewriteBatchedStatements:true;批量写入
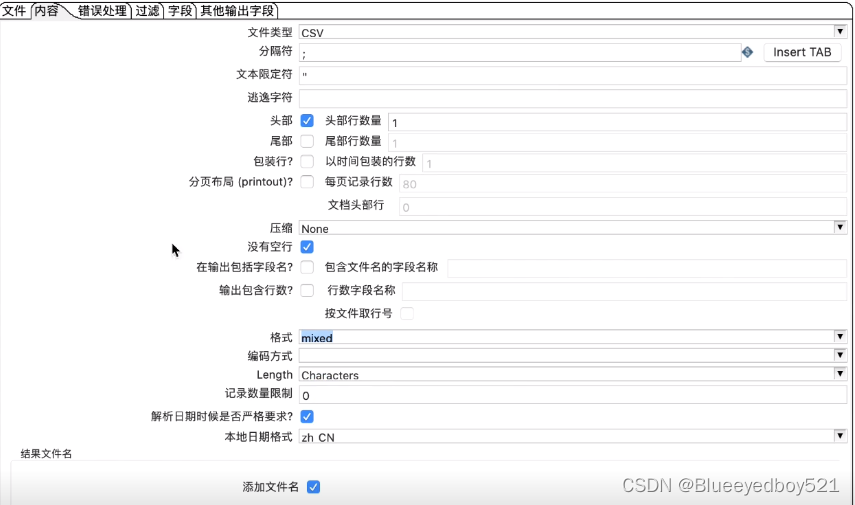
4. 输入配置中切换到内容
- 配置分隔符;
- 模式设置mixed
5. 表输出设置线程数量
在表输出点击右键【改变开始复制的数量】设置10
6. 建立数据流向
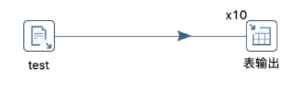
7.启动迁移
可以发现多线程,mac测试15分钟左右导完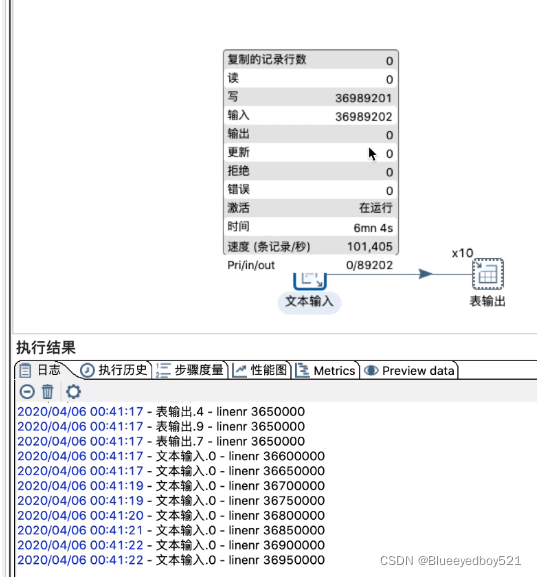
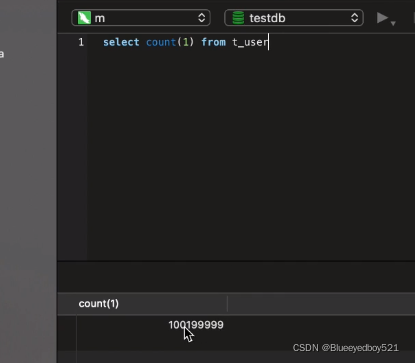
8.查询

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)