
【python】2019数学建模国赛C题机场数据爬取程序
文章目录前提目标网站思路代码前提需要的python库requests(非自带)openpyxl(非自带)retime需要保证同目录文件夹下存在XZ_Air.xlsx文件,且存在名为Shee1的表目标网站新政机场公众号提供的数据接口:http://www.whalebj.com/xzjc/default.aspx提示:运行程序请尽量加大时间间隔,避免给目标服务...
·
- 网站接口关了,程序作废,可做学习使用(2021.8.4)
前提
- 需要的python库
requests(非自带)
openpyxl(非自带)
re
time
- 需要保证同目录文件夹下存在
XZ_Air.xlsx文件,且存在名为Shee1的表
目标网站
新政机场公众号提供的数据接口:
http://www.whalebj.com/xzjc/default.aspx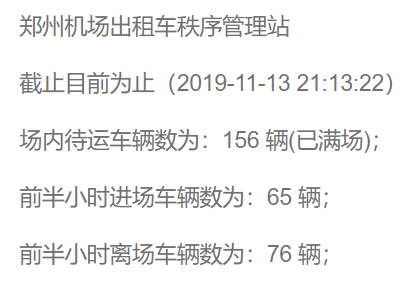
提示:
运行程序请尽量加大时间间隔,避免给目标服务器造成服务压力。(目前应该没什么事,国赛那几天服务器的压力挺大的,目测有不少队伍在爬取目标网站数据)。
思路
- 指定循环间隔,静态网页抓取
- 正则表达式匹配数据
- 按顺序提取匹配的数据
- 将提取的数据保存到
excel文件
代码
'''
如需运行本程序,需要保证同目录文件夹下存在XZ_Air.xlsx文件,且存在名为Shee1的表
运行本程序需要联网,运用了requests,openpyxl两个第三方库
如果没有安装第三方库,需要使用pip install xxx的形式在命令行中安装名为xxx的库
此程序利用正则表达式对返回页面进行数据提取
'''
#coding=utf-8
import requests
import time
import re
import openpyxl
#请求头
myheader = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0",
"Host": "www.whalebj.com"
}
#请求地址
link = 'http://www.whalebj.com/xzjc/default.aspx'
#xls存储函数
def xlswrite(datas):
wb = openpyxl.load_workbook('XZ_Air.xlsx') #读入存储文件
ws = wb['Sheet1'] #存储表名
row = ws.max_row #获取现有行数
print('r:'+str(row)) #打印行数
row = row + 1 #行数加1
#存储本行数据
j = 0
for data in datas:
idx = str(chr(ord('A') + j)) + str(row)
ws[idx] = data
j = j + 1
#保存文件
wb.save('XZ_Air.xlsx')
#读取web数据函数
def get_d():
r = requests.get(link, headers=myheader, timeout=10)
data = []
#正则匹配相关数据
matchObj = re.search(r'[0-9]+-[0-9]+-[0-9]+ [0-9]+:[0-9]+:[0-9]+', r.text)
data.append(matchObj[0])
matchObj1 = re.findall(r'[0-9]+(?= )', r.text)
#添加剩余数据
for i in range(3):
data.append(matchObj1[i+1])
#打印数据
print(data)
#写入xls文档
xlswrite(data)
#进入循环
while(1):
get_d()
#时间间隔(s)
time.sleep(59.5)

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)