
[TMI 2024]BrainMass: Advancing Brain Network Analysis for Diagnosis With Large-Scale Self-Supervised
计算机-人工智能-大型预训练fMRI分类

论文代码:https://github.com/podismine/BrainMass
目录
2.3.2. Self-Supervised Learning
2.4.2. Pseudo Functional Connectivity Augmentation
2.4.3. Brain Network Transformer Encoder
2.4.5. Latent Representation Alignment
2.6.1. Brain Disorder Diagnosis Performance
2.6.2. Sensitive Analysis and Ablation Studies
2.6.3. Generalizability and Few/Zero-Shot Evaluation
1. 心得
(1)我受不了了,我刚学这领域就看的这一作的论文怎么现在还在看啊!ptsd了,大家怎么越来越强
2. 论文逐段精读
2.1. Abstract
①挑战:医学数据少且高异质性
②解决方法:自监督无需大量标记,且作者引入30个数据集,包含46,686 名参与者的 70,781 个样本
2.2. Introduction
①除了大型数据集以外,还引入了随机丢弃时间点构成的伪功能连接 (pFC)来进行数据增强
②有八个内部诊断任务和七个外部诊断任务(太强了)
2.3. Related Works
2.3.1. Brain Network Study
①列举一些相关脑网络分析的模型
2.3.2. Self-Supervised Learning
①介绍了其他任务下的无监督模型
②基于fMRI的模型如BrainGSL效果一般
2.4. Method
2.4.1. Preliminaries
①大脑网络:,
是ROI个数
②诊断映射:
③整体框架:
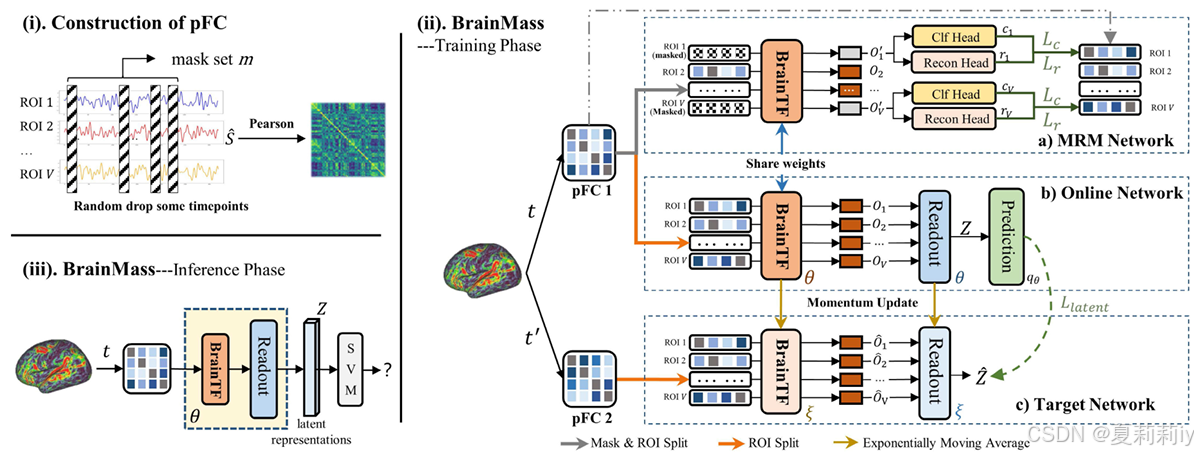
2.4.2. Pseudo Functional Connectivity Augmentation
①对于原始的fmri time series: ,
是时间点
②从中mask一些时间点得到
,用
来计算伪功能连接矩阵(pFC)
2.4.3. Brain Network Transformer Encoder
①计算注意力:
其中是注意力层数,
是自注意力头个数
2.4.4. Masked ROI Modelling
①对于最上层的MRM网络,随机掩码掉一些token(应该是一行)然后替换为可学习嵌入
②两层的MLP分类头应用InfoNCE损失:
这是让同一个ROI下被掩码的特征与加工的特征更相似,不同ROI特征差距更大(这叫分类孙书记好奇怪,为什么不叫对比损失)
③三层的MLP重建头应用重建损失:
2.4.5. Latent Representation Alignment
①原始矩阵通过自注意力会得到:
②读出函数把变成
③作者要让同一个被试的两个pFC通过网络后很相似,用Prediction来对齐:
④损失:
⑤把正方形降维为
2.4.5. Optimization
①损失函数:
2.5. Experiments
2.5.1. Datasets
①数据统计:
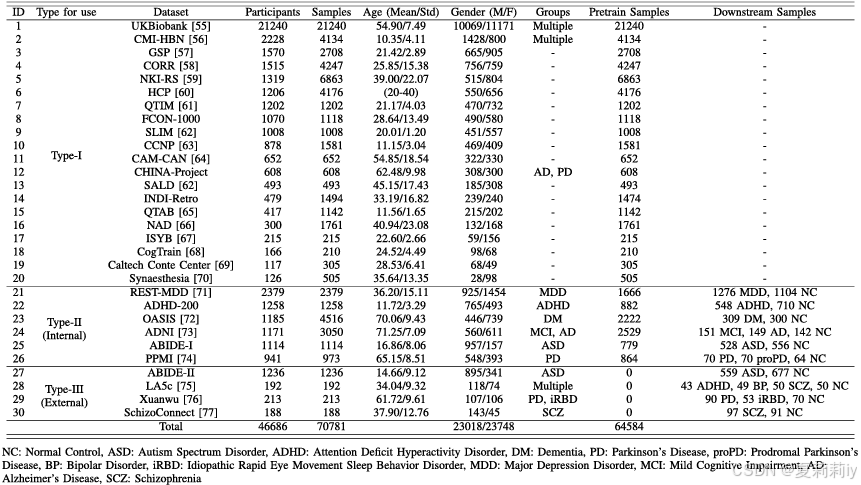
其中I类用于预训练,II类的70%用于预训练,30%用于验证和评估,III类用于评估泛化性
2.5.2. Evaluation
~
2.5.3. Data Preprocessing
①预处理管道:可配置连接组分析管道(C-PAC)
②功能连接:皮尔逊
③脑图谱:Schaefer 100
2.5.4. Implementation Details
①优化器:Adam
②学习率:在10个热身期内从3e-5增加到3e-4,权重衰减为5e-5
③批量:256
④Epoch: 2000
⑤衰减率:
⑥⭐全场坐下!实验是在配备 64 个 NVIDIA Tesla V100 GPU 的平台上进行的,每次训练分配 8 个 GPU。每次预训练大约需要 150 小时。
⑦Transfomer层:32
⑧Transformer头:20
⑨前馈神经网络的隐藏特征:4096
⑩损失参数:(5??不是0.5吗怎么这么大)
⑪重复验证次数:10
2.5.5. Metrics
~
2.6. Results
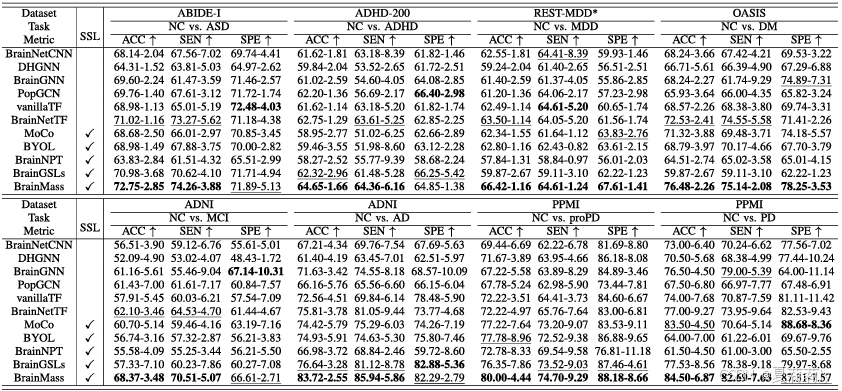
2.6.1. Brain Disorder Diagnosis Performance
①内部数据集上的测试结果:
2.6.2. Sensitive Analysis and Ablation Studies
①损失项消融:

②Dropout rate消融:
③模型配置消融:
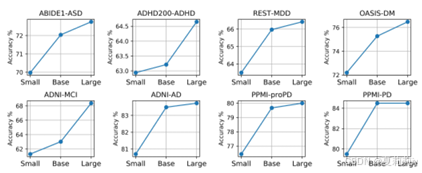
小模型、基本模型和大模型分别配备 8、16 和 32 个 Transformer 层、5、10 和 20 个注意力头,以及 1024、2048 和 4096 个 FFN 功能。它们的总参数分别为 14.4 M、25.4 M 和 67.0 M。
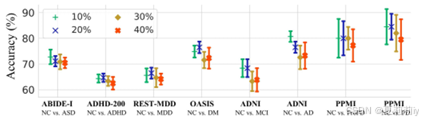
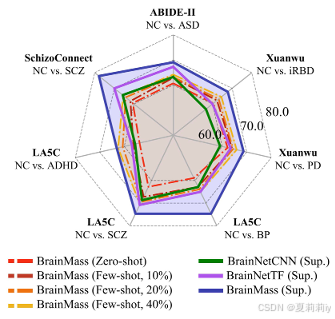
2.6.3. Generalizability and Few/Zero-Shot Evaluation
①在外部任务上的泛化性评估:
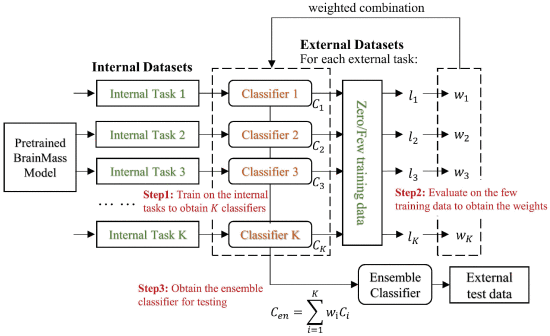
②少样本和零样本的运作流程:
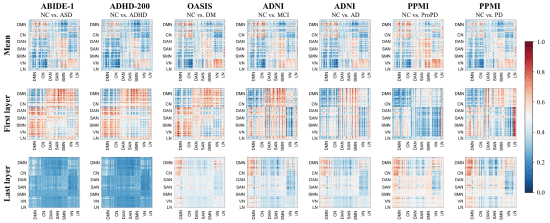
2.6.4. Biological Explanation
①七个内部任务的功能连接注意力图:
②大脑网络的多变量分析带来的十个最关键脑区:
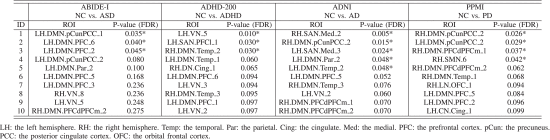
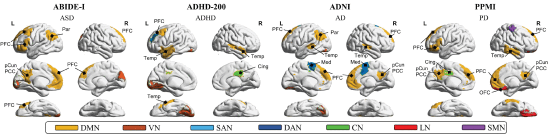
③关键脑区可视化:
2.7. Discussion
①可以尝试别的微调办法
②可以纳入多模态
2.8. Conclusion
~

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 29
29 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)