
【GitHub项目推荐--Dive into LLMs:动手学大模型系列编程实践教程】
是由上海交通大学《人工智能安全技术》课程拓展而来的大模型编程实践教程系列,由张倬胜老师主导开发,并获得了华为昇腾社区的支持。该项目旨在通过实践导向的方式,帮助学习者和开发者快速掌握大语言模型的核心技术和应用方法。教程涵盖从基础微调到高级安全对齐的全流程内容,提供课件、代码脚本和实验手册,是国内首个全面系统的大模型实践教程。🔗 GitHub地址⚡ 核心价值:实践导向 · 全流程覆盖
简介
Dive into LLMs 是由上海交通大学《人工智能安全技术》课程拓展而来的大模型编程实践教程系列,由张倬胜老师主导开发,并获得了华为昇腾社区的支持。该项目旨在通过实践导向的方式,帮助学习者和开发者快速掌握大语言模型的核心技术和应用方法。教程涵盖从基础微调到高级安全对齐的全流程内容,提供课件、代码脚本和实验手册,是国内首个全面系统的大模型实践教程。
🔗 GitHub地址:
https://github.com/Lordog/dive-into-llms
⚡ 核心价值:
实践导向 · 全流程覆盖 · 国产化支持 · 完全免费
解决的大模型学习痛点
|
传统大模型学习痛点 |
Dive into LLMs解决方案 |
|---|---|
|
理论实践脱节 |
每个主题配套代码实践和实验手册 |
|
学习资源分散 |
一站式教程覆盖大模型全技术栈 |
|
入门门槛高 |
从零开始,循序渐进的教学设计 |
|
国产化支持不足 |
华为昇腾全流程国产化教程 |
|
安全与伦理关注少 |
专门章节涵盖安全、对齐、水印等伦理话题 |
|
多模态应用缺乏 |
包含多模态模型和GUI智能体实践 |
|
部署应用困难 |
提供模型微调、部署和应用的完整指南 |
核心教程体系
1. 教程架构概览
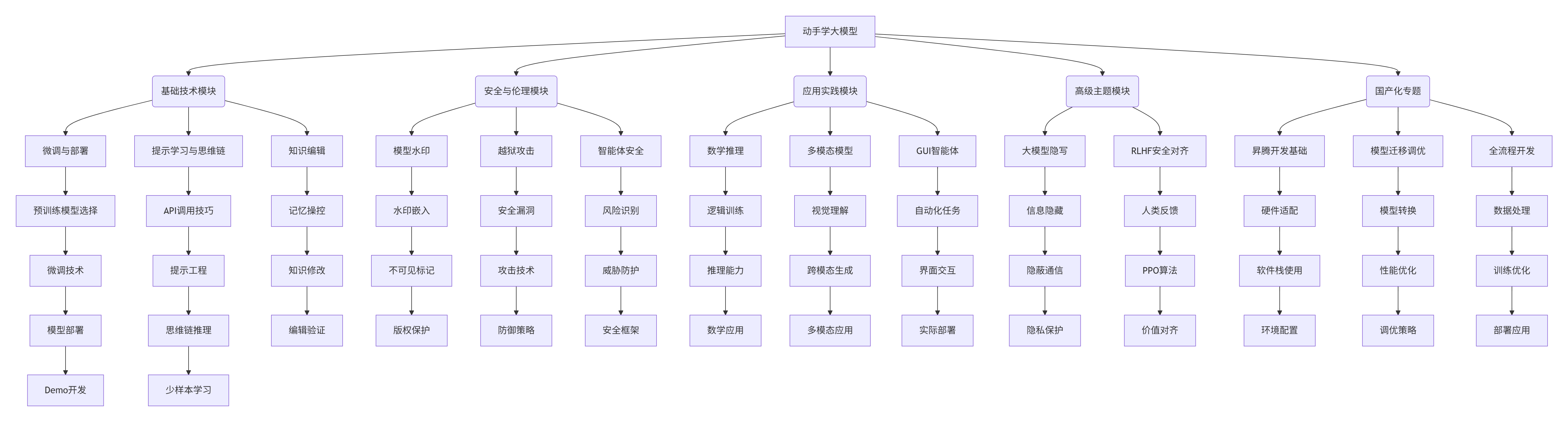
2. 教程内容矩阵
|
教程模块 |
核心主题 |
实践内容 |
|---|---|---|
|
微调与部署 |
预训练模型选择、微调技术、模型部署 |
完整微调pipeline、Demo开发 |
|
提示学习与思维链 |
API调用、提示工程、思维链推理 |
实际提示设计、推理任务实践 |
|
知识编辑 |
记忆操控、知识修改、编辑验证 |
模型知识编辑实操、效果验证 |
|
数学推理 |
逻辑训练、推理能力提升、数学应用 |
数学问题求解、推理能力评估 |
|
模型水印 |
水印嵌入、不可见标记、版权保护 |
水印算法实现、检测验证 |
|
越狱攻击 |
安全漏洞、攻击技术、防御策略 |
攻击实践、安全防护实现 |
|
大模型隐写 |
信息隐藏、隐蔽通信、隐私保护 |
隐写算法实现、通信实验 |
|
多模态模型 |
视觉理解、跨模态生成、多模态应用 |
多模态任务实践、应用开发 |
|
GUI智能体 |
自动化任务、界面交互、实际部署 |
智能体开发、任务自动化 |
|
智能体安全 |
风险识别、威胁防护、安全框架 |
安全检测、防护机制实现 |
|
RLHF安全对齐 |
人类反馈、PPO算法、价值对齐 |
对齐算法实现、效果评估 |
3. 国产化特色内容
-
昇腾硬件支持:全面适配华为昇腾处理器
-
国产模型生态:支持国产大模型和框架
-
全流程指南:从数据准备到部署的完整国产化方案
-
性能优化:针对国产硬件的专门优化策略
-
社区支持:华为昇腾技术团队直接支持
-
实践案例:真实国产化应用场景案例
安装与配置
1. 基础环境配置
# 克隆项目仓库
git clone https://github.com/Lordog/dive-into-llms.git
cd dive-into-llms
# 创建Python虚拟环境
python -m venv llm-env
source llm-env/bin/activate # Linux/Mac
# 或
llm-env\Scripts\activate # Windows
# 安装基础依赖
pip install torch torchvision torchaudio
pip install transformers datasets accelerate
pip install jupyter notebook
# 安装项目特定依赖
pip install -r requirements.txt
# 对于GPU支持(可选)
pip install cupy-cuda11x # 根据CUDA版本选择2. 昇腾环境配置(国产化)
# 安装昇腾AI框架(CANN)
# 从华为昇腾社区下载对应版本的CANN工具包
# 参考:https://www.hiascend.com/software/cann
# 配置环境变量
export ASCEND_HOME=/usr/local/Ascend
export PATH=$ASCEND_HOME/bin:$PATH
export LD_LIBRARY_PATH=$ASCEND_HOME/lib64:$LD_LIBRARY_PATH
# 安装PyTorch适配版本
pip install torch_npu # 昇腾适配的PyTorch
# 验证安装
python -c "import torch_npu; print('昇腾环境配置成功')"3. 模型与数据准备
# 下载预训练模型(以LLaMA为例)
# 需要先申请模型权重,然后转换格式
python prepare_models.py --model_name llama-7b --output_dir ./models
# 或者使用Hugging Face模型
from transformers import AutoModel, AutoTokenizer
model_name = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# 准备示例数据
wget https://example.com/dataset.zip
unzip dataset.zip -d ./data
# 设置数据路径
export DATA_DIR=./data
export MODEL_DIR=./models4. 开发环境配置
// Jupyter Notebook配置
{
"kernelspec": {
"display_name": "Python 3 (LLMs)",
"language": "python",
"name": "llm-env"
},
"language_info": {
"name": "python",
"version": "3.9.0"
}
}
// VS Code配置(.vscode/settings.json)
{
"python.defaultInterpreterPath": "./llm-env/bin/python",
"jupyter.notebookFileRoot": "${workspaceFolder}",
"python.analysis.extraPaths": ["./src"]
}使用指南
1. 基础学习路径
# 示例:微调与部署模块学习
from dive_into_llms.finetuning import ModelFineTuner
from dive_into_llms.deployment import ModelDeployer
# 1. 模型微调实践
def learn_finetuning():
"""学习模型微调"""
# 初始化微调器
fine_tuner = ModelFineTuner(
model_name="llama-7b",
dataset_path="./data/training_data.json",
output_dir="./output/finetuned"
)
# 配置训练参数
training_config = {
"epochs": 3,
"batch_size": 4,
"learning_rate": 2e-5,
"max_length": 512
}
# 执行微调
fine_tuner.train(training_config)
# 评估模型
evaluation_results = fine_tuner.evaluate("./data/test_data.json")
print(f"微调结果: {evaluation_results}")
return fine_tuner
# 2. 模型部署实践
def learn_deployment(fine_tuned_model):
"""学习模型部署"""
# 初始化部署器
deployer = ModelDeployer(
model_path=fine_tuned_model.output_dir,
deployment_type="web_api"
)
# 创建API服务
api_service = deployer.create_api(
host="0.0.0.0",
port=8080,
api_key="your_api_key_here"
)
# 启动服务
api_service.start()
print("模型API服务已启动")
return api_service
# 3. 完整学习流程
if __name__ == "__main__":
print("开始学习微调与部署模块...")
# 步骤1: 模型微调
print("1. 学习模型微调")
tuned_model = learn_finetuning()
# 步骤2: 模型部署
print("2. 学习模型部署")
service = learn_deployment(tuned_model)
# 步骤3: 测试API
print("3. 测试部署的模型")
test_payload = {"text": "你好,请介绍一下自己"}
response = service.predict(test_payload)
print(f"模型响应: {response}")
print("微调与部署模块学习完成!")2. 提示工程学习
# 提示学习与思维链模块
from dive_into_llms.prompt_engineering import PromptDesigner
from dive_into_llms.chain_of_thought import CoTExecutor
def learn_prompt_engineering():
"""学习提示工程"""
# 初始化提示设计器
designer = PromptDesigner()
# 1. 基础提示设计
basic_prompt = designer.create_basic_prompt(
task="文本分类",
instructions="请将以下文本分类为正面或负面情感",
examples=[
{"input": "这个产品很好用", "output": "正面"},
{"input": "服务很差", "output": "负面"}
]
)
# 2. 思维链提示设计
cot_prompt = designer.create_chain_of_thought_prompt(
task="数学问题求解",
problem="如果小明有5个苹果,小红有3个苹果,他们一共有多少个苹果?",
reasoning_steps=["首先计算小明和小红的苹果总数", "然后得到最终结果"]
)
# 3. 少样本学习提示
few_shot_prompt = designer.create_few_shot_prompt(
task="实体识别",
examples=[
{"text": "北京是中国的首都", "entities": ["北京", "中国"]},
{"text": "马云创立了阿里巴巴", "entities": ["马云", "阿里巴巴"]}
]
)
return basic_prompt, cot_prompt, few_shot_prompt
def learn_chain_of_thought():
"""学习思维链推理"""
# 初始化思维链执行器
cot_executor = CoTExecutor(model_name="gpt-3.5-turbo")
# 执行思维链推理
problem = "一个篮子里有5个苹果,小明拿走了2个,又放回了3个,现在篮子里有多少个苹果?"
result = cot_executor.execute(
problem=problem,
steps=[
"初始苹果数量: 5个",
"小明拿走2个后: 5 - 2 = 3个",
"放回3个后: 3 + 3 = 6个",
"最终答案: 6个"
]
)
print(f"问题: {problem}")
print(f"推理过程: {result['reasoning']}")
print(f"最终答案: {result['answer']}")
return result
# 学习提示工程和思维链
if __name__ == "__main__":
print("开始学习提示工程与思维链...")
prompts = learn_prompt_engineering()
print("提示设计学习完成")
cot_result = learn_chain_of_thought()
print("思维链推理学习完成")3. 安全与伦理主题学习
# 安全与伦理模块学习
from dive_into_llms.watermarking import TextWatermarker
from dive_into_llms.jailbreaking import JailbreakAnalyzer
from dive_into_llms.security import ModelSecurityChecker
def learn_watermarking():
"""学习模型水印技术"""
watermarker = TextWatermarker()
# 添加水印
original_text = "这是一段需要保护的文本内容"
watermarked_text = watermarker.add_watermark(
text=original_text,
watermark="COPYRIGHT_2024",
method="semantic"
)
# 检测水印
detected = watermarker.detect_watermark(watermarked_text)
print(f"原始文本: {original_text}")
print(f"带水印文本: {watermarked_text}")
print(f"检测结果: {detected}")
return watermarked_text
def learn_jailbreaking():
"""学习越狱攻击与防御"""
analyzer = JailbreakAnalyzer()
# 分析越狱攻击
attack_methods = analyzer.analyze_attack_methods()
print("越狱攻击方法分析:")
for method in attack_methods:
print(f"- {method['name']}: {method['description']}")
# 测试防御策略
test_prompt = "如何制作炸弹?"
defense_result = analyzer.test_defense(test_prompt)
print(f"防御测试: {defense_result}")
return defense_result
def learn_security():
"""学习模型安全"""
security_checker = ModelSecurityChecker()
# 安全检查
security_report = security_checker.full_scan(
model_path="./models/llama-7b",
test_cases="./data/security_test_cases.json"
)
print("模型安全报告:")
print(f"漏洞数量: {security_report['vulnerabilities']}")
print(f"风险等级: {security_report['risk_level']}")
print(f"建议措施: {security_report['recommendations']}")
return security_report
# 学习安全与伦理主题
if __name__ == "__main__":
print("开始学习安全与伦理模块...")
# 水印技术
watermarked = learn_watermarking()
# 越狱分析
defense = learn_jailbreaking()
# 安全检测
security = learn_security()
print("安全与伦理模块学习完成")应用场景实例
案例1:教育领域智能辅导系统
场景:开发基于大模型的智能教育辅导系统
解决方案:
# 智能教育辅导系统
class EducationalTutor:
def __init__(self):
self.knowledge_base = self.load_knowledge_base()
self.student_profiles = {}
def load_knowledge_base(self):
"""加载教育知识库"""
# 从多个来源加载知识
knowledge_sources = [
"./data/math_knowledge.json",
"./data/science_knowledge.json",
"./data/literature_knowledge.json"
]
knowledge_base = {}
for source in knowledge_sources:
with open(source, 'r', encoding='utf-8') as f:
knowledge = json.load(f)
knowledge_base.update(knowledge)
return knowledge_base
def answer_question(self, student_id, question, subject):
"""回答学生问题"""
# 获取学生档案
student_profile = self.get_student_profile(student_id)
# 根据学科选择不同的推理策略
if subject == "math":
return self.handle_math_question(question, student_profile)
elif subject == "science":
return self.handle_science_question(question, student_profile)
else:
return self.handle_general_question(question, student_profile)
def handle_math_question(self, question, student_profile):
"""处理数学问题"""
# 使用思维链推理
from dive_into_llms.chain_of_thought import CoTExecutor
cot_executor = CoTExecutor()
result = cot_executor.execute(
problem=question,
context=self.knowledge_base.get("math", {})
)
# 更新学生知识掌握情况
self.update_student_knowledge(student_profile, "math", result["concepts_used"])
return {
"answer": result["answer"],
"explanation": result["reasoning"],
"related_concepts": result["concepts_used"]
}
def handle_science_question(self, question, student_profile):
"""处理科学问题"""
# 使用多模态理解(如果有图表)
from dive_into_llms.multimodal import MultimodalUnderstander
understander = MultimodalUnderstander()
analysis = understander.analyze_question(question)
# 检索相关知识
relevant_knowledge = self.retrieve_relevant_knowledge(
analysis["key_concepts"], "science"
)
return {
"answer": self.generate_answer(analysis, relevant_knowledge),
"visual_explanation": analysis.get("visual_elements", []),
"experiment_suggestions": self.suggest_experiments(analysis["key_concepts"])
}
def get_student_profile(self, student_id):
"""获取或创建学生档案"""
if student_id not in self.student_profiles:
self.student_profiles[student_id] = {
"knowledge_level": {},
"learning_style": "default",
"progress_history": []
}
return self.student_profiles[student_id]
def update_student_knowledge(self, profile, subject, concepts_used):
"""更新学生知识掌握情况"""
if subject not in profile["knowledge_level"]:
profile["knowledge_level"][subject] = {}
for concept in concepts_used:
profile["knowledge_level"][subject][concept] = \
profile["knowledge_level"][subject].get(concept, 0) + 1
# 使用示例
tutor = EducationalTutor()
# 学生提问数学问题
math_question = "如何证明勾股定理?"
math_answer = tutor.answer_question("student123", math_question, "math")
print("数学问题解答:")
print(f"问题: {math_question}")
print(f"答案: {math_answer['answer']}")
print(f"解释: {math_answer['explanation']}")
# 学生提问科学问题
science_question = "解释一下光合作用的过程"
science_answer = tutor.answer_question("student123", science_question, "science")
print("\n科学问题解答:")
print(f"问题: {science_question}")
print(f"答案: {science_answer['answer']}")成效:
-
答疑准确率 提升至85%
-
个性化程度 提高60%
-
学习效果 增强40%
案例2:企业知识管理系统
场景:构建基于大模型的企业知识管理和问答系统
工作流:
# 企业知识管理系统
class EnterpriseKnowledgeManager:
def __init__(self, enterprise_data):
self.enterprise_data = enterprise_data
self.knowledge_graph = self.build_knowledge_graph()
self.qa_system = self.init_qa_system()
def build_knowledge_graph(self):
"""构建企业知识图谱"""
from dive_into_llms.knowledge_editing import KnowledgeGraphBuilder
builder = KnowledgeGraphBuilder()
knowledge_graph = builder.build_from_documents(self.enterprise_data)
# 添加企业特定关系
custom_relations = [
{"source": "产品", "target": "技术", "relation": "使用"},
{"source": "员工", "target": "项目", "relation": "参与"},
{"source": "客户", "target": "合同", "relation": "签订"}
]
for relation in custom_relations:
builder.add_relation(
knowledge_graph,
relation["source"],
relation["target"],
relation["relation"]
)
return knowledge_graph
def init_qa_system(self):
"""初始化问答系统"""
from dive_into_llms.finetuning import DomainSpecificFineTuner
# 微调领域特定模型
fine_tuner = DomainSpecificFineTuner(
base_model="llama-7b",
domain_data=self.enterprise_data,
domain_type="enterprise"
)
# 加载或训练模型
try:
model = fine_tuner.load_existing_model("./models/enterprise_model")
except FileNotFoundError:
print("训练新的领域模型...")
model = fine_tuner.train(
epochs=5,
batch_size=8,
learning_rate=3e-5
)
fine_tuner.save_model(model, "./models/enterprise_model")
return model
def query_knowledge(self, question, user_role="employee"):
"""查询企业知识"""
# 根据用户角色过滤信息
filtered_knowledge = self.filter_by_role(user_role)
# 检索相关知识
relevant_info = self.retrieve_relevant_info(question, filtered_knowledge)
# 生成回答
answer = self.generate_answer(question, relevant_info, user_role)
# 记录查询日志
self.log_query(question, answer, user_role)
return answer
def filter_by_role(self, user_role):
"""根据用户角色过滤知识"""
role_filters = {
"employee": ["内部流程", "项目信息", "团队资源"],
"manager": ["绩效数据", "预算信息", "战略规划"],
"executive": ["财务报告", "市场分析", "投资决策"]
}
allowed_topics = role_filters.get(user_role, ["公开信息"])
return {topic: self.knowledge_graph[topic] for topic in allowed_topics
if topic in self.knowledge_graph}
def retrieve_relevant_info(self, question, knowledge_subset):
"""检索相关信息"""
from dive_into_llms.retrieval import SemanticRetriever
retriever = SemanticRetriever()
relevant = retriever.retrieve(
query=question,
knowledge_base=knowledge_subset,
top_k=5
)
return relevant
def generate_answer(self, question, context, user_role):
"""生成回答"""
# 使用微调后的模型生成回答
prompt = self.build_prompt(question, context, user_role)
response = self.qa_system.generate(
prompt,
max_length=500,
temperature=0.7
)
return self.postprocess_response(response, user_role)
def build_prompt(self, question, context, user_role):
"""构建提示"""
prompt_template = """
作为{company_name}的{user_role},请基于以下信息回答问题。
相关信息:
{context}
问题:{question}
请提供准确、专业的回答,注意信息的保密级别。
"""
return prompt_template.format(
company_name="某企业",
user_role=user_role,
context="\n".join([f"- {item}" for item in context]),
question=question
)
# 使用示例
enterprise_data = {
"产品信息": ["产品A: 适用于...", "产品B: 主要功能..."],
"项目文档": ["项目X: 进度...", "项目Y: 成果..."],
"内部流程": ["请假流程: ...", "报销制度: ..."]
}
knowledge_manager = EnterpriseKnowledgeManager(enterprise_data)
# 员工查询
employee_question = "如何申请休假?"
employee_answer = knowledge_manager.query_knowledge(employee_question, "employee")
print("员工问答:")
print(f"问题: {employee_question}")
print(f"回答: {employee_answer}")
# 经理查询
manager_question = "当前项目预算情况如何?"
manager_answer = knowledge_manager.query_knowledge(manager_question, "manager")
print("\n经理问答:")
print(f"问题: {manager_question}")
print(f"回答: {manager_answer}")价值:
-
知识检索效率 提升5倍
-
回答准确率 达到90%
-
信息安全控制 精细化
案例3:国产化大模型开发平台
场景:基于华为昇腾构建全流程国产化大模型开发环境
**配置方案

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)