
python连接阿里云ODPS常用操作
【代码】python连接阿里云ODPS常用操作。
·
python连接阿里云ODPS常用操作
1、安装python库
pip install pyodps==0.12.2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
2、基本操作
1、连接阿里云ODPS
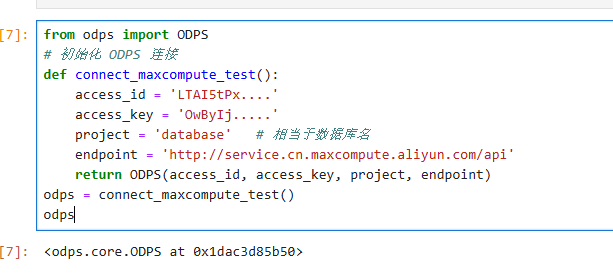
from odps import ODPS
# 初始化 ODPS 连接
def connect_maxcompute_test():
access_id = 'LTAI5tPx....'
access_key = 'OwByIj.....'
project = 'databa' # 相当于数据库名
endpoint = 'http://service.cn.maxcompute.aliyun.com/api'
return ODPS(access_id, access_key, project, endpoint)
odps = connect_maxcompute_test()
odps
2、创建表
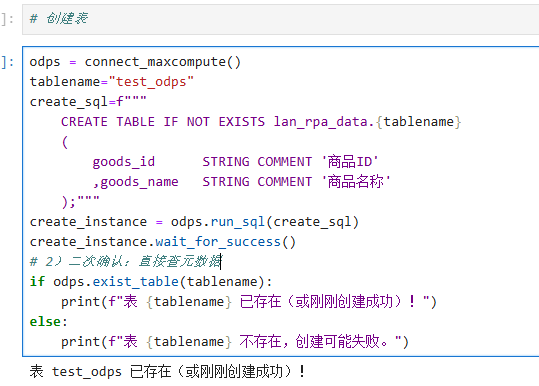
odps = connect_maxcompute()
tablename="test_odps"
create_sql=f"""
CREATE TABLE IF NOT EXISTS lan_rpa_data.{tablename}
(
goods_id STRING COMMENT '商品ID'
,goods_name STRING COMMENT '商品名称'
);"""
create_instance = odps.run_sql(create_sql)
create_instance.wait_for_success()
# 2)二次确认:直接查元数据
if odps.exist_table(tablename):
print(f"表 {tablename} 已存在(或刚刚创建成功)!")
else:
print(f"表 {tablename} 不存在,创建可能失败。")
3、删除表
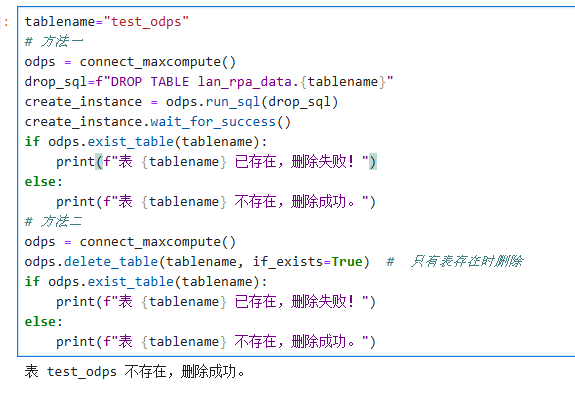
tablename="test_odps"
# 方法一
drop_sql=f"DROP TABLE lan_rpa_data.{tablename}"
odps = connect_maxcompute()
create_instance = odps.run_sql(drop_sql)
create_instance.wait_for_success()
if odps.exist_table(tablename):
print(f"表 {tablename} 已存在,删除失败!")
else:
print(f"表 {tablename} 不存在,删除成功。")
# 方法二
odps = connect_maxcompute()
odps.delete_table(tablename, if_exists=True) # 只有表存在时删除
if odps.exist_table(tablename):
print(f"表 {tablename} 已存在,删除失败!")
else:
print(f"表 {tablename} 不存在,删除成功。")
4、清空表
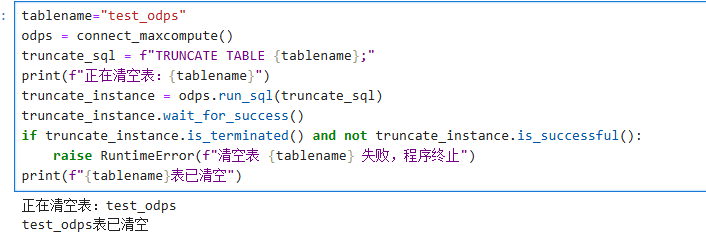
tablename="test_odps"
odps = connect_maxcompute()
truncate_sql = f"TRUNCATE TABLE {tablename};"
print(f"正在清空表:{tablename}")
truncate_instance = odps.run_sql(truncate_sql)
truncate_instance.wait_for_success()
if truncate_instance.is_terminated() and not truncate_instance.is_successful():
raise RuntimeError(f"清空表 {tablename} 失败,程序终止")
print(f"{tablename}表已清空")
5、 查看表行数
tablename="test_odps"
odps = connect_maxcompute()
table_cnt = odps.get_table(tablename)
row_count = table_cnt.to_df().count() # 读取总条数
count_int = int(row_count.execute())
print(f"表:{tablename},总行数为 {str(count_int)}")
if count_int != 0:
raise RuntimeError(f"{tablename} 清空后数据条数为 {row_count},不为0") # 抛异常并停止运行
print(f"{tablename}表已清空")

6、获取项目下的所有表信息
odps = connect_maxcompute()
table_list = odps.list_tables()
tablename="test_odps"
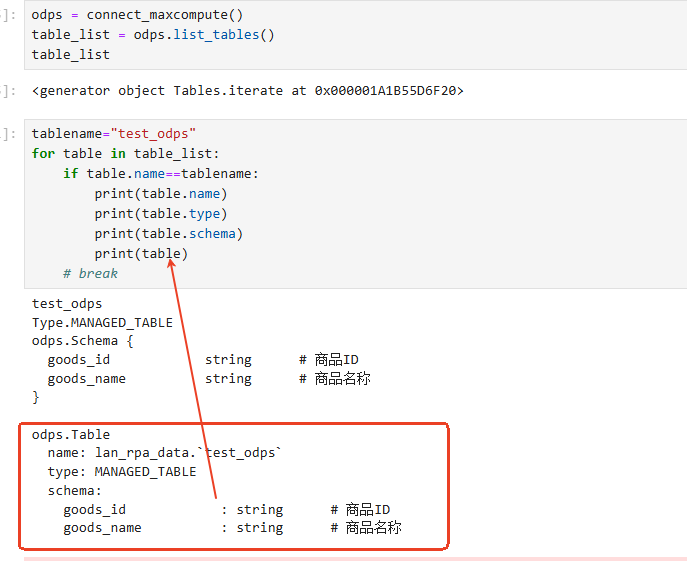
for table in table_list:
if table.name==tablename:
print(table.name)
print(table.type)
print(table.schema)
print(table)
7、新加列
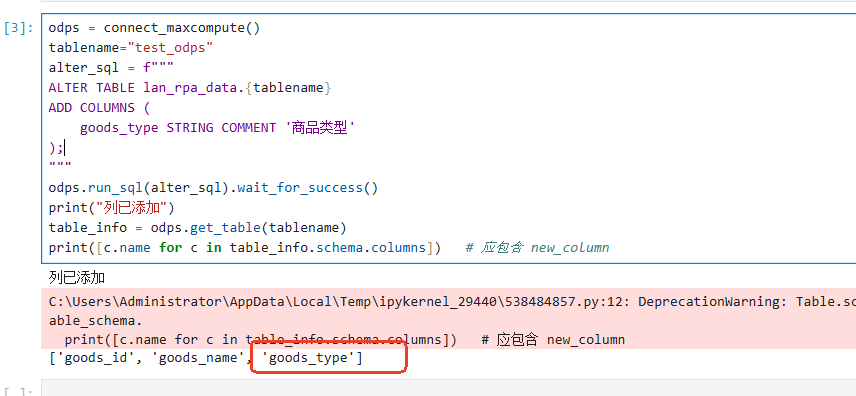
odps = connect_maxcompute()
tablename="test_odps"
alter_sql = f"""
ALTER TABLE lan_rpa_data.{tablename}
ADD COLUMNS (
goods_type STRING COMMENT '商品类型'
);
"""
odps.run_sql(alter_sql).wait_for_success()
print("列已添加")
table_info = odps.get_table(tablename)
print([c.name for c in table_info.schema.columns]) # 应包含 new_column
8、数据写入【整体代码】
import pandas as pd
from odps import ODPS
# 初始化 ODPS 连接
def connect_maxcompute_test():
access_id = 'LTAI5tPx....'
access_key = 'OwByIj.....'
project = 'databa' # 相当于数据库名
endpoint = 'http://service.cn.maxcompute.aliyun.com/api'
return ODPS(access_id, access_key, project, endpoint)
def check_schema_compatibility(df, target_table):
target_schema = {col.name: col.type for col in target_table.schema.columns}
# 检查缺失字段
missing_in_target = set(df.columns) - set(target_schema.keys())
missing_in_source = set(target_schema.keys()) - set(df.columns)
# 收集所有不兼容字段
incompatible_fields_name=[]
incompatible_fields_type = []
# 检查字段类型兼容性
for col in df.columns:
if col in target_schema:
try:
if not _is_type_compatible(str(df[col].dtype), target_schema[col]):
incompatible_fields_type.append(f"字段 '{col}': 本地类型={df[col].dtype}, 数仓类型={target_schema[col]}")
except Exception as e:
incompatible_fields_type.append(f"字段 '{col}' 类型检查出错: {str(e)}")
# 如果有不兼容情况,准备错误信息
error_msgs = []
if missing_in_target:
incompatible_fields_name.append(f"本地表有但目标表没有的字段: {sorted(missing_in_target)}")
if missing_in_source:
incompatible_fields_name.append(f"目标表有但本地表没有的字段: {sorted(missing_in_source)}")
if incompatible_fields_type:
error_text="类型不兼容的字段:\n" + "\n".join(incompatible_fields_type)
print(error_text)
raise ValueError("\n".join(incompatible_fields_type))
def _is_type_compatible(df_type, odps_type):
type_map = {
'int64': ['bigint', 'int'],
'float64': ['double', 'float'],
'object': ['string', 'varchar']
}
for pandas_t, odps_types in type_map.items():
if df_type == pandas_t and odps_type in odps_types:
return True
return str(df_type) == str(odps_type)
df=pd.read_excel(f"data/test.xlsx",dtype={"goods_id": str})
# df.head(3)
tablename="test_odps"
odps = connect_maxcompute()
# 检查表是否存在
if not odps.exist_table(tablename):
raise ValueError(f"目标表 {tablename} 不存在,拒绝自动创建临时表!")
target_table = odps.get_table(tablename)
# 校对字段类型,防止因字段类型不一致报错
check_schema_compatibility(df, target_table)
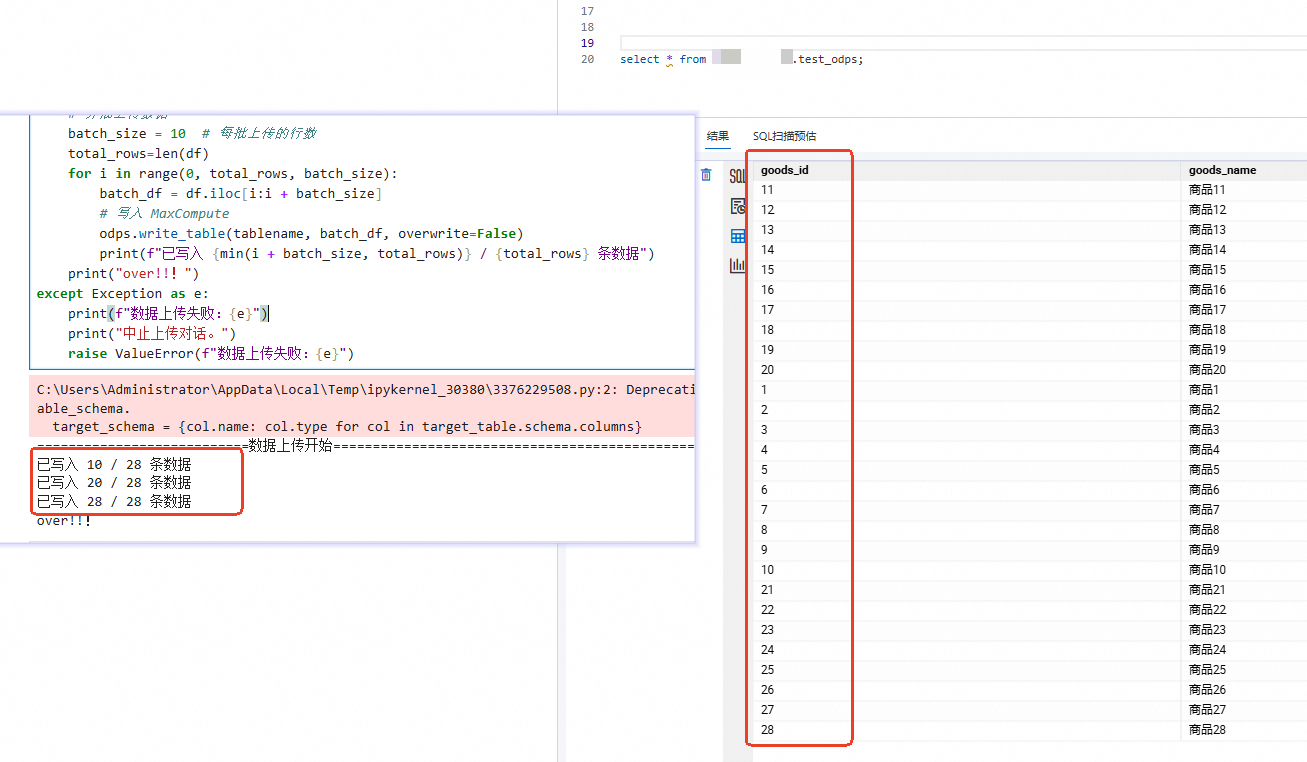
print("===========================数据上传开始===============================================")
try:
# 分批上传数据
batch_size = 10 # 每批上传的行数
total_rows=len(df)
for i in range(0, total_rows, batch_size):
batch_df = df.iloc[i:i + batch_size]
# 写入 MaxCompute
odps.write_table(tablename, batch_df, overwrite=False)
print(f"已写入 {min(i + batch_size, total_rows)} / {total_rows} 条数据")
print("over!!!")
except Exception as e:
print(f"数据上传失败:{e}")
print("中止上传对话。")
raise ValueError(f"数据上传失败:{e}")

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)