
[论文阅读] 人工智能 + 软件工程 | 深度解析可解释AI如何破解软件工程“黑盒”难题
摘要 本文综述了可解释人工智能(XAI)在软件工程(SE)中的应用研究。系统梳理了XAI的概念起源、核心定义及评估方法,重点分析了XAI在SE中的四大典型应用场景:恶意软件检测(SBMDS系统处理3.9万+样本)、高风险组件检测(改进OSR算法)、软件负载调配(Gil/Gil+工具)和二进制代码相似性分析(BINKIT基准+TIKNIB工具)。针对当前研究存在的客观评估稀缺、标准不统一等问题,提出
深度解析可解释AI如何破解软件工程“黑盒”难题
论文信息
| 信息类别 | 具体内容 |
|---|---|
| 论文原标题 | 基于可解释性人工智能的软件工程技术方法综述 |
| 主要作者 | 邢颖 |
| 研究机构 | 北京邮电大学人工智能学院(北京 100876) |
| DOI | 10.11896/jsjkx.221100159 |
| 发表期刊/年份 | Computer Science(计算机科学),2023年,第50卷第5期 |
| APA引文格式 | 邢颖. (2023). 基于可解释性人工智能的软件工程技术方法综述. Computer Science, 50(5), 4-11. |
一段话总结
邢颖团队的这篇综述聚焦“可解释性人工智能(XAI)与软件工程(SE)的结合”,首先阐述了XAI的起源(2004年提出概念,2016年DARPA推动项目)、核心定义(区分“可理解性”与“可解释性”,研究范围含IML)及评估方法(基于应用/人/功能的三类分类,指出客观评估稀缺的现状);接着分析AI在SE中的应用基础(SE起源、AI提升SE自动化的案例);随后重点拆解XAI在SE的四大典型场景——恶意软件检测(构建SBMDS系统处理3.9万+样本)、高风险组件检测(改进OSR算法提升准确性与可解释性)、软件负载调配(开发Gil/Gil+工具整合先验知识)、二进制代码相似性分析(建立BINKIT基准与TIKNIB工具);最后提出四大未来方向(客观评估方法、统一标准、细分应用、安全考量),为XAI在SE的落地提供系统参考。
思维导图
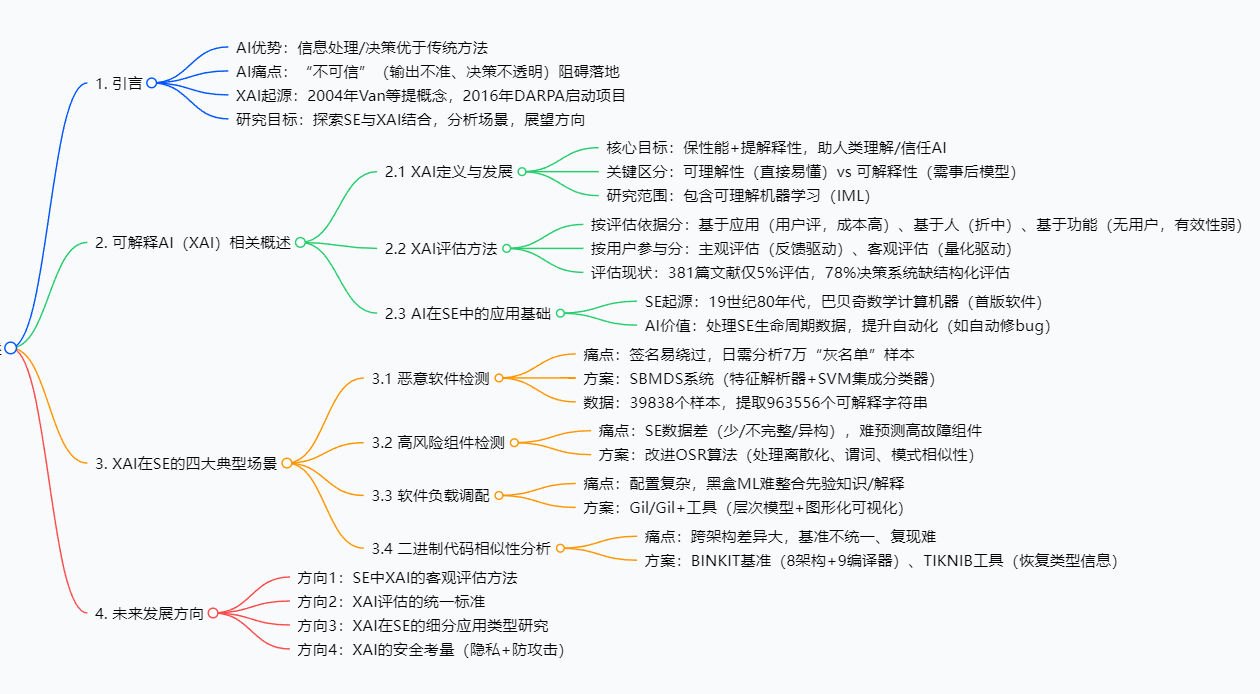
研究背景
要理解这篇综述的价值,得先搞懂“软件工程为什么需要可解释AI”——这背后是AI技术落地的“信任危机”与软件工程的“实际痛点”双重驱动。
首先,AI技术虽在信息处理、决策上比传统方法强,但它像个“闭着眼睛开处方的医生”:输出结果无法保证100%准确,决策过程更是“黑盒”——你不知道它为什么判定这个软件组件有风险,也不知道它怎么得出“这个配置最优”的结论。这种“不可信”在普通领域或许影响不大,但在软件工程中却成了大问题:比如自动驾驶软件的故障预测、金融系统的恶意软件检测,一旦AI判断失误且无法解释,可能引发安全事故或经济损失。2016年DARPA启动XAI项目,正是为了破解这种“黑盒困境”,让AI决策变得可理解、可信任。
其次,AI在软件工程中的应用越来越广,但“老毛病”也越来越明显:一方面,它过度依赖历史数据——如果历史数据里没有“某类新型恶意软件”的信息,AI就无法识别;另一方面,决策不透明让开发人员不敢用——比如AI说“这个测试用例最可能失败”,但说不出理由,开发人员怎么敢放弃其他测试用例?
举个生动的例子:金山杀毒实验室的分析师每天要处理约7万个“灰名单”样本(既不能确定是良性,也不能确定是恶意的程序),靠人工分析根本忙不过来,急需AI自动分类。但传统AI分类后,只能给出“是/否恶意”的结果,分析师没法知道“AI凭什么判断它是恶意的”——如果AI误判了一个正常软件,后果不堪设想。这就是软件工程的真实痛点:既需要AI提高效率,又需要AI给出“理由”,可解释XAI恰好能填补这个空白。
简单来说,软件工程的“效率需求”遇上AI的“信任短板”,催生了对“可解释AI+SE”的研究需求,这篇综述正是在这样的背景下,系统梳理了当前的研究现状与解决方案。
创新点
这篇综述的独特价值,在于它不是简单罗列文献,而是从“问题-方案-价值”的逻辑链出发,给出了兼具系统性与实用性的分析,核心创新点有三个:
-
首次系统聚焦SE中XAI的四大核心场景,且每个场景都给出“痛点-技术方案-数据验证”的完整闭环:不同于以往综述只谈XAI理论,这篇综述针对软件工程的“恶意软件检测、高风险组件检测、软件负载调配、二进制代码相似性分析”四大高频痛点,每个场景都匹配了具体的XAI技术(如SBMDS系统、改进OSR算法),还附上了样本量、准确率等数据(如恶意软件检测用3.9万+样本验证),让理论落地有了依据。
-
明确指出XAI评估的“短板”,并为SE场景提供评估方法选择依据:以往研究要么忽略XAI评估,要么只提一种方法,这篇综述不仅梳理了“基于应用/人/功能”三类评估方法,还分析了每种方法在SE中的适配性——比如“基于人的评估”比“基于应用”成本低,比“基于功能”更贴合开发人员需求,适合SE的快速迭代场景,为后续研究提供了评估方向。
-
破解二进制代码相似性分析的“两大难题”:基准不统一与解释性差:该领域此前没有通用基准,不同研究结果无法对比,且方法多为黑盒。综述中提到的BINKIT基准(含24万+二进制文件)是首个可复制、可扩展的BCSA基准,而TIKNIB工具通过“恢复类型信息”,不仅实现99%+准确率,还能解释“为什么这两段代码相似”,解决了领域长期存在的痛点。
研究方法和思路、实验方法
这篇综述采用“理论梳理-场景拆解-未来展望”的研究思路,具体步骤可拆分为四步,每个步骤都结合了文献调研与案例分析:
第一步:梳理XAI的理论基础(概念+评估)
- 方法:通过调研150+篇XAI相关文献(如DARPA项目报告、Yeung等的研究),明确XAI的定义(区分“可理解性”与“可解释性”)、起源(2004年Van等提出,2016年DARPA推动)及核心目标(保性能+提解释性)。
- 评估方法分析:整合文献[19](Doshi-Velez等)与文献[20](Vilone等)的分类框架,将评估方法分为“基于应用/人/功能”三类,并用数据说明现状(381篇文献仅5%评估)——此步骤无实验,侧重理论归纳。
第二步:分析AI在SE中的应用基础
- 方法:追溯SE的起源(19世纪80年代巴贝奇的机器),结合文献[23](Marcos等)的SE生命周期理论,说明SE的核心问题(项目估算、故障定位等);再通过谢涛团队、Feldt等的案例(如AI自动排序测试用例、修复bug),证明AI在SE中的价值——此步骤以案例分析为主,无定量实验。
第三步:拆解XAI在SE的四大典型场景(核心实验/方案部分)
每个场景都采用“痛点分析-文献调研-技术方案-数据验证”的流程,以两个关键场景为例:
场景1:恶意软件检测
- 痛点:传统签名方法易绕过,人工处理7万“灰名单”样本效率低。
- 方案:调研文献[47][48]的SBMDS系统,拆解为3步:
- 特征解析器:从39838个样本(8320良性+31518恶意)中提取963556个“可解释字符串”(反映攻击意图的API调用字符串);
- 特征选择:筛选与恶意软件类型相关的字符串;
- SVM集成分类器:解决单一SVM在大规模数据上的性能问题,实现分类与类型预测。
- 验证:系统在可扩展性、泛化性上表现优异,能解释“为何判定该样本为恶意”(通过可解释字符串追溯攻击意图)。
场景2:二进制代码相似性分析
- 痛点:跨架构/编译器的代码差异大,基准不统一,复现难。
- 方案:调研文献[107]的方案,拆解为2步:
- 构建BINKIT基准:涵盖8个架构、9个编译器、5个优化级别,生成243128个二进制文件、36256322个函数(来自51个真实软件包),并提供自动化脚本扩展;
- 开发TIKNIB工具:通过“恢复编译丢失的类型信息”,计算代码特征的相对差异,实现相似性分析。
- 验证:TIKNIB准确率达99%+,且能解释“相似性依据”,BINKIT解决了基准不统一问题。
第四步:展望未来方向
- 方法:结合前三步的分析,找出当前研究的空白(如客观评估少、无统一标准、安全风险未解决),提出四大未来方向——此步骤为理论推导,基于现有研究痛点归纳。
主要成果和贡献
这篇综述的成果可分为“理论成果”“应用成果”“数据成果”三类,每类都为软件工程与XAI领域带来了实实在在的价值:
| 成果类别 | 具体内容 | 核心价值(大白话总结) |
|---|---|---|
| 理论成果 | 1. 系统梳理XAI的定义、发展脉络,明确“可理解性”与“可解释性”的区分; 2. 归纳XAI的三类评估方法,分析各方法在SE中的适配性; 3. 提出SE与XAI结合的四大未来方向。 |
1. 让新手能快速搞懂“XAI是什么”“怎么评估XAI”; 2. 给研究人员指了路:知道未来该往哪个方向突破(如做客观评估方法)。 |
| 应用成果 | 1. 恶意软件检测:SBMDS系统实现自动化分类与解释,处理3.9万+样本; 2. 高风险组件检测:改进OSR算法,精准定位高故障组件; 3. 软件负载调配:Gil/Gil+工具整合先验知识,性能媲美黑盒ML; 4. 二进制代码相似性分析:TIKNIB工具准确率99%+,解决跨架构分析难题。 |
1. 开发人员有了可用的工具:比如用SBMDS自动分析“灰名单”,不用再人工熬夜; 2. 降低了XAI在SE中的落地门槛——给出现成的技术方案,不用从零研发。 |
| 数据成果 | 1. 恶意软件检测:39838个样本集(含4类恶意软件),提取963556个可解释字符串; 2. 二进制代码分析:BINKIT基准(24万+二进制文件,3600万+函数)。 |
1. 为后续研究提供了数据集:不用再自己找数据、标数据,节省时间; 2. BINKIT解决了“各研究结果无法对比”的问题,让领域能良性竞争。 |
开源信息:论文中未提及代码或数据集的公开地址,仅描述了数据内容与工具原理,推测目前暂未开源。
关键问题
问题1:可解释AI(XAI)到底能解决软件工程中AI的什么核心问题?
答:主要解决AI的“信任危机”——软件工程中的AI(如恶意软件检测AI、故障预测AI)虽能提高效率,但存在两个致命问题:一是“决策不透明”(不知道AI为什么这么判断),二是“无法追溯错误”(错了也不知道错在哪)。XAI通过提供“决策理由”(如用可解释字符串说明“该样本是恶意软件的依据”),让开发人员能理解、验证AI的判断,从而敢用、能用AI工具。
问题2:XAI在软件工程的四大场景中,哪个场景的解决方案最有落地价值?为什么?
答:二进制代码相似性分析的解决方案(BINKIT基准+TIKNIB工具)最有落地价值。因为此前该领域长期存在“两大死结”:一是没有通用基准,不同研究的结果没法对比,导致技术难进步;二是跨架构分析难(比如ARM架构的代码和x86架构的代码,AI没法判断相似性)。BINKIT基准解决了第一个死结,TIKNIB工具解决了第二个死结,且准确率达99%+,直接能用于漏洞检测、抄袭判断等实际工作,落地性极强。
问题3:当前XAI在软件工程中的评估方法,为什么“客观评估”这么少?未来该怎么改进?
答:客观评估少主要有两个原因:一是“可解释性”本身有很多概念性特性(如“用户对解释的满意度”),没法用数字量化;二是缺乏可靠的量化指标——比如不知道用“解释的长度”还是“解释的准确率”来衡量可解释性。未来改进方向有两个:一是针对SE的具体场景设计专属指标(如“恶意软件检测中,解释能帮助分析师修正错误的比例”);二是结合主观评估与客观指标,比如用“用户满意度”校准量化指标,让客观评估更贴合实际需求。
问题4:这篇综述指出的未来方向中,哪个方向对工业界最重要?为什么?
答:“软件工程中XAI的客观评估方法”对工业界最重要。因为工业界用AI工具讲究“高效、可验证”——主观评估(如组织专家评审)成本高、周期长,不适合快速迭代的软件开发流程。如果有了客观评估方法(比如用自动化指标判断XAI工具的解释质量),企业能快速筛选出好用的XAI工具,不用再花大量时间做人工测试,从而加速XAI在工业界的落地。
总结
邢颖团队的这篇综述是“可解释AI与软件工程结合”领域的重要参考资料,它没有停留在理论层面,而是从“问题-方案-未来”形成了完整的逻辑闭环:首先清晰阐述了XAI的理论基础(定义、评估),为读者搭建了知识框架;接着聚焦软件工程的四大核心痛点,给出了有数据支撑的XAI解决方案,让理论落地有了路径;最后指出当前研究的空白,为后续研究指明了方向。
对于开发人员来说,这篇综述提供了可直接参考的工具思路(如SBMDS、Gil+),能帮助解决实际工作中的效率问题;对于研究人员来说,它梳理了领域现状,明确了客观评估、统一标准等亟待突破的方向;对于整个领域来说,它推动了“可解释AI+SE”的规范化,为技术良性发展奠定了基础。
当然,综述也有局限性——未涉及XAI在SE其他场景(如代码生成、智能运维)的应用,且部分方案(如Gil+工具)缺乏工业界大规模验证的数据。但总体而言,这篇综述是连接XAI理论与软件工程实践的桥梁,对领域发展有重要的推动作用。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 106
106 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)