
【大数据】MapReduce从入门到精通:开启大数据处理新世界
本文系统介绍了MapReduce大数据处理框架。首先阐述了MapReduce作为分布式并行计算模型的"分而治之"核心理念,详细解析了其Map、Shuffle、Reduce三个核心阶段的处理机制。通过WordCount经典案例展示了编程实践方法,并拓展了网站日志分析等实际应用场景。文章深入剖析了MapReduce的优势(易于编程、扩展性强、高容错性)和局限性(不适合实时计算、I/
目录
一、MapReduce 是什么
在大数据的广阔领域中,MapReduce 就像是一位默默耕耘的幕后英雄,支撑着无数大规模数据处理任务的高效运行。它是一种编程模型,也是一个用于大规模数据集并行运算的软件框架,旨在让开发人员能够轻松编写分布式并行程序,以处理海量数据。
MapReduce 的诞生,源于互联网数据量的爆炸式增长。在 21 世纪初,搜索引擎巨头 Google 面临着处理海量网页数据的巨大挑战,传统的单机计算模式在面对如此庞大的数据规模时显得力不从心。为了解决这一难题,Google 的工程师们创新性地提出了 MapReduce 编程模型,并于 2004 年发表了相关论文。随后,开源社区基于 Google 的论文,开发出了 Hadoop MapReduce,这一开源实现使得 MapReduce 技术得以广泛应用,成为大数据处理领域的基石。
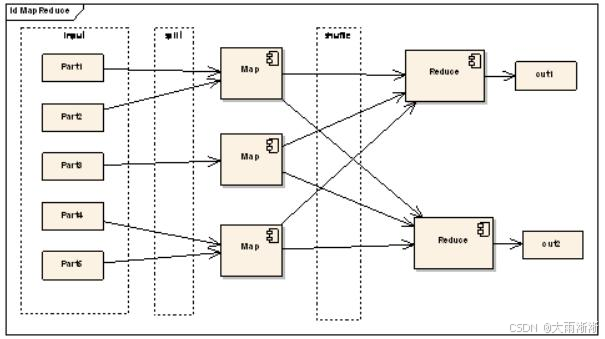
MapReduce 的核心思想可以用 “分而治之” 来概括。它将一个大规模的计算任务分解为两个主要阶段:Map(映射)阶段和 Reduce(归约)阶段。在 Map 阶段,数据被分割成多个小块,每个小块被独立地处理,生成一系列的键值对;在 Reduce 阶段,具有相同键的键值对被合并处理,最终得到我们想要的结果。举个简单的例子,假如你要统计一个巨大的图书馆中所有书籍里每个单词出现的次数,如果让你一个人去完成,那无疑是一项艰巨无比的任务。但使用 MapReduce 就不一样了,它可以把这个任务分给多个人(多个计算节点)并行处理。在 Map 阶段,每个人负责一部分书籍,把书中的每个单词标记出来并记录出现 1 次;在 Reduce 阶段,再把相同单词的标记收集到一起,统计出每个单词总共出现的次数。通过这种方式,原本难以完成的大规模任务,就能够高效地完成了。
二、MapReduce 核心原理
(一)Map 阶段
Map 阶段是 MapReduce 数据处理的起始阶段,就像是一场大型工厂生产线的原材料预处理环节。在这个阶段,输入数据被拆分成一个个小的 “原料块”,也就是我们所说的键值对(Key-Value Pair) 。
当 MapReduce 作业启动时,首先会读取存储在分布式文件系统(如 HDFS)中的数据。这些数据通常以文件的形式存在,MapReduce 会将每个文件按照一定的规则进行切片(Input Split),每个切片的大小默认与 HDFS 的数据块大小相同(通常是 128MB )。每个切片都会被分配给一个 Map 任务来处理,这样就实现了数据处理的并行化。
以文本文件为例,假设我们有一个包含多段文字的文本文件,MapReduce 会将这个文件切分成多个切片。对于每个切片,Map 任务会逐行读取其中的数据,并将每一行数据解析成键值对。默认情况下,键是每一行文本的起始字节偏移量,值则是这一行的文本内容。例如,对于文本文件中的第一行 “Hello, MapReduce”,解析成的键值对可能是 < 0, “Hello, MapReduce”> 。
接下来,Map 任务会调用用户自定义的 Map 函数对这些键值对进行处理。Map 函数的作用是对输入的键值对进行转换和映射,生成新的键值对。比如,在单词计数的场景中,Map 函数会将每一行文本按单词进行拆分,然后为每个单词生成一个键值对,键为单词本身,值为 1,表示这个单词出现了一次。对于上述的 “Hello, MapReduce” 这一行,经过 Map 函数处理后,会生成两个键值对:<“Hello”, 1 > 和 <“MapReduce”, 1> 。每个输入的键值对都会调用一次 Map 函数,Map 函数可以根据具体的业务逻辑对数据进行过滤、转换等操作,然后输出零个或多个新的键值对。这些新生成的键值对就是 Map 阶段的输出,它们将作为后续 Shuffle 阶段的输入数据 。
(二)Shuffle 阶段
Shuffle 阶段是 MapReduce 中最为关键也最为复杂的阶段,它就像是一座桥梁,连接着 Map 阶段和 Reduce 阶段,又像是一个精心安排的物流调度系统,负责将 Map 阶段产生的大量数据进行整理、分类和传输,确保每个 Reduce 任务都能准确无误地接收到它所需要处理的数据。
当 Map 任务完成对数据的处理并输出键值对后,这些键值对并不会直接传递给 Reduce 任务,而是首先进入 Shuffle 阶段。在这个阶段,数据会经历分区(Partition)、排序(Sort)、合并(Merge)等一系列重要操作。
分区操作是 Shuffle 阶段的第一步,它的主要作用是将 Map 输出的键值对按照一定的规则分配到不同的分区中,每个分区对应一个 Reduce 任务。这样做的目的是为了实现数据的并行处理,让多个 Reduce 任务可以同时对不同分区的数据进行处理,从而提高整个计算任务的执行效率。默认情况下,MapReduce 采用哈希分区(Hash Partition)的方式,即根据键的哈希值对 Reduce 任务的数量取模,来确定该键值对应该被分配到哪个分区。例如,如果有 5 个 Reduce 任务,某个键的哈希值对 5 取模的结果为 2,那么这个键值对就会被分配到第 2 个分区。通过这种方式,可以将数据较为均匀地分配到各个 Reduce 任务上,避免出现数据倾斜(某些 Reduce 任务处理的数据量过大,而其他 Reduce 任务处理的数据量过小)的问题。
在完成分区操作后,每个分区内的数据会进行排序。排序的依据是键值对中的键,MapReduce 会按照键的字典序对键值对进行排序。排序的目的是为了让具有相同键的键值对能够连续地存储在一起,这样在后续的 Reduce 阶段,就可以方便地对相同键的数据进行合并和处理。例如,对于键值对 <“apple”, 1>、<“banana”, 1>、<“apple”, 1> ,经过排序后会变成 <“apple”, 1>、<“apple”, 1>、<“banana”, 1> ,这样在 Reduce 阶段处理 “apple” 这个键时,就可以直接对相邻的两个值进行合并计算。
在排序的同时,MapReduce 还会对数据进行合并操作,这里的合并包括两种情况:一种是在 Map 端进行的局部合并(Combiner),另一种是在 Reduce 端进行的全局合并。Combiner 是一个可选的组件,它的功能类似于 Reduce 函数,但是它只在 Map 任务的本地执行,作用是对 Map 输出的具有相同键的键值对进行局部汇总。例如,在单词计数的例子中,如果 Map 任务输出了多个 <“apple”, 1 > 的键值对,Combiner 可以将它们合并成一个 <“apple”, n > 的键值对(n 为局部出现的次数总和),这样可以减少 Shuffle 过程中需要传输的数据量,从而提高系统的性能。而在 Reduce 端,当从各个 Map 任务拉取到属于自己分区的数据后,会将这些数据进行全局合并,将所有具有相同键的键值对合并在一起,形成一个完整的数据集,以便后续的 Reduce 函数进行处理 。
最后,经过分区、排序和合并后的键值对会通过网络传输到对应的 Reduce 任务所在的节点上。这个传输过程需要消耗一定的网络带宽和时间,因此 Shuffle 阶段的性能优化对于整个 MapReduce 作业的执行效率至关重要。为了减少网络传输的数据量,MapReduce 还支持对数据进行压缩,在传输前将数据压缩成较小的格式,到达 Reduce 端后再进行解压缩。
(三)Reduce 阶段
Reduce 阶段是 MapReduce 数据处理的最后阶段,它就像是工厂生产线的成品组装车间,负责将 Shuffle 阶段传来的经过整理和分类的数据进行最终的合并和处理,生成我们期望的最终结果。
当 Reduce 任务接收到 Shuffle 阶段传输过来的数据后,首先会对这些数据进行进一步的整理和合并。由于在 Shuffle 阶段已经对数据进行了分区和排序,所以每个 Reduce 任务接收到的数据都是按照键进行排序的,并且具有相同键的数据会被聚集在一起。Reduce 任务会遍历这些数据,将相同键的值聚合到一个集合中,然后调用用户自定义的 Reduce 函数对这些值进行处理。
还是以单词计数为例,假设某个 Reduce 任务接收到了多个关于 “apple” 的键值对,如 <“apple”, 3>、<“apple”, 2>、<“apple”, 1> ,Reduce 函数会将这些值合并在一起,计算出 “apple” 这个单词总共出现的次数。在这个例子中,Reduce 函数会将 3、2、1 相加,得到最终的结果 6 ,然后生成一个新的键值对 <“apple”, 6> ,表示 “apple” 这个单词在整个数据集中出现了 6 次。
Reduce 函数的输出可以是零个或多个键值对,这些输出的键值对就是 MapReduce 作业的最终结果。这些结果可以被存储到分布式文件系统(如 HDFS)中,供后续的数据分析和处理使用,也可以直接输出到其他应用程序中。在实际应用中,Reduce 阶段的处理逻辑可以根据具体的业务需求进行定制,比如可以进行数据的统计分析、数据的聚合计算、数据的过滤筛选等操作 。
需要注意的是,Reduce 任务的数量可以根据数据量的大小和计算任务的复杂程度进行调整。增加 Reduce 任务的数量可以提高并行处理的能力,加快计算速度,但同时也会增加系统的开销和资源消耗;减少 Reduce 任务的数量则可以降低系统开销,但可能会导致单个 Reduce 任务处理的数据量过大,从而影响计算效率。因此,在实际应用中需要根据具体情况进行合理的配置和优化 。
三、MapReduce 编程实践
(一)WordCount 案例
了解了 MapReduce 的基本原理,接下来我们通过一个经典的 WordCount 案例,来更深入地理解 MapReduce 的编程实现。WordCount 的任务很简单,就是统计给定文本中每个单词出现的次数,这个案例就像是大数据领域的 “Hello World”,看似基础,却蕴含着 MapReduce 的核心编程思想。
首先,我们需要明确 MapReduce 程序的三个主要部分:Mapper、Reducer 和 Driver 。
Mapper 部分主要负责将输入的数据进行拆分和初步处理。在 WordCount 中,Mapper 的作用是逐行读取输入文本,然后将每行文本按单词进行拆分,为每个单词生成一个键值对,键为单词,值为 1,表示该单词出现了一次。以 Java 代码为例,Mapper 类的实现如下:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
// 定义输出的键值对,这里k是单词,v固定为1
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// value是文本中的一行内容
String line = value.toString();
// 按空格拆分单词
String[] words = line.split(" ");
for (String w : words) {
// 设置输出的键为单词
word.set(w);
// 输出键值对,如<"hello", 1>
context.write(word, one);
}
}
}
在这段代码中,map方法是 Mapper 的核心逻辑。key表示输入文本的行偏移量,value表示一行文本内容。通过split方法将一行文本拆分成单词数组,然后遍历数组,为每个单词创建一个键值对并通过context.write方法输出 。
Reducer 部分则是对 Mapper 输出的键值对进行汇总和合并。在 WordCount 中,Reducer 会接收所有键(单词)相同的键值对,然后将这些键值对的值(即单词出现的次数)进行累加,得到每个单词在整个文本中出现的总次数。Java 代码实现如下:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// 遍历相同单词对应的所有次数,进行累加
for (IntWritable val : values) {
sum += val.get();
}
// 设置输出的单词出现总次数
result.set(sum);
// 输出键值对,如<"hello", 5>
context.write(key, result);
}
}
在reduce方法中,key是单词,values是该单词对应的所有出现次数的集合。通过遍历values并累加其中的值,得到该单词的总出现次数,最后将结果通过context.write方法输出 。
Driver 部分就像是整个 MapReduce 程序的指挥官,它负责配置和提交整个任务。在 Driver 中,我们需要设置作业的各种参数,包括 Mapper 和 Reducer 类的指定、输入输出数据格式的设置、输入输出路径的指定等。Java 代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 创建配置对象
Configuration conf = new Configuration();
// 创建作业对象
Job job = Job.getInstance(conf, "word count");
// 指定运行的类
job.setJarByClass(WordCountDriver.class);
// 指定Mapper类
job.setMapperClass(WordCountMapper.class);
// 指定Reducer类
job.setReducerClass(WordCountReducer.class);
// 设置Mapper输出的键类型
job.setMapOutputKeyClass(Text.class);
// 设置Mapper输出的值类型
job.setMapOutputValueClass(IntWritable.class);
// 设置最终输出的键类型
job.setOutputKeyClass(Text.class);
// 设置最终输出的值类型
job.setOutputValueClass(IntWritable.class);
// 指定输入路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 指定输出路径,注意输出路径不能存在,否则会报错
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交作业并等待完成,true表示打印作业执行过程的详细信息
System.exit(job.waitForCompletion(true)? 0 : 1);
}
}
在main方法中,首先创建了Configuration对象和Job对象,然后通过一系列的set方法来配置作业的各个参数。最后通过job.waitForCompletion(true)方法提交作业并等待作业完成,如果作业成功完成则退出程序并返回 0,否则返回 1 。
通过这个 WordCount 案例,我们可以清晰地看到 MapReduce 编程的基本流程和各个部分的作用。Mapper 将输入数据进行初步处理,Reducer 对处理后的结果进行汇总,Driver 则负责协调和提交整个任务。这三个部分相互协作,共同完成了复杂的数据处理任务 。
(二)实际应用案例拓展
WordCount 只是 MapReduce 的一个入门示例,在实际应用中,MapReduce 有着更广泛的用途,能够解决各种复杂的大数据处理问题。下面我们来看几个常见的实际应用场景。
网站日志分析:在互联网行业,网站每天都会产生海量的日志数据,这些日志记录了用户的访问行为、页面浏览情况、访问时间等信息。通过对这些日志数据进行分析,网站运营者可以了解用户的行为习惯、兴趣偏好,从而优化网站的内容和布局,提升用户体验。比如,通过 MapReduce 可以统计每个页面的访问次数,找出最受欢迎的页面;分析用户的访问路径,了解用户在网站上的行为流程,进而发现潜在的业务问题或优化点。
假设我们有一份网站日志文件,每一行记录的格式为 “用户 ID 时间戳 访问页面 URL”,要统计每个页面的访问次数,我们可以这样实现:在 Mapper 阶段,将每行日志中的访问页面 URL 作为键,值设为 1,然后输出键值对;在 Reducer 阶段,对相同 URL 的键值对进行累加,得到每个 URL 的访问总次数。
用户行为分析:在电商平台、社交媒体等应用中,用户行为分析是非常重要的。通过分析用户的注册、登录、购买、点赞、评论等行为数据,可以挖掘出用户的潜在需求、消费习惯和社交关系,为精准营销、个性化推荐等提供有力支持。例如,在电商平台中,利用 MapReduce 可以分析用户的购买历史,找出经常一起购买的商品组合,从而进行关联推荐;在社交媒体中,可以分析用户之间的互动关系,构建用户社交图谱,为社交广告投放等提供依据 。
以电商平台统计用户购买商品的总金额为例,在 Mapper 阶段,从用户购买记录中提取用户 ID 作为键,购买金额作为值,输出键值对;在 Reducer 阶段,对相同用户 ID 的键值对进行累加,得到每个用户的购买总金额 。
数据清洗与预处理:在大数据处理过程中,原始数据往往存在各种问题,如数据缺失、重复、错误等,需要进行清洗和预处理才能用于后续的分析和建模。MapReduce 可以方便地对大规模数据进行并行清洗和预处理。例如,在处理一份包含大量用户信息的数据文件时,可能存在某些字段缺失或格式错误的情况。通过 MapReduce,我们可以在 Mapper 阶段对每一条数据进行检查和修正,将清洗后的数据输出;在 Reducer 阶段,可以对数据进行去重等操作,确保数据的质量和一致性 。
数据挖掘与机器学习:MapReduce 在数据挖掘和机器学习领域也有着广泛的应用。例如,在聚类分析中,可以利用 MapReduce 将大规模数据集分成多个小块,并行计算每个小块数据的聚类结果,最后再将这些局部结果合并成全局的聚类结果;在分类算法中,如决策树算法,MapReduce 可以用于并行计算每个特征的信息增益,从而加速决策树的构建过程 。
这些实际应用案例展示了 MapReduce 在大数据处理领域的强大能力和广泛适用性。通过灵活运用 MapReduce 的编程模型,我们可以高效地处理各种复杂的大数据问题,为业务决策和数据分析提供有力支持 。
四、MapReduce 优缺点剖析
(一)优势
- 易于编程:MapReduce 为开发者提供了一种简单而直观的编程模型,使得编写分布式并行程序变得相对容易。开发者无需深入了解分布式系统底层的复杂细节,如网络通信、任务调度、数据同步等,只需专注于实现 Map 和 Reduce 这两个核心函数的业务逻辑即可。就像我们前面实现的 WordCount 案例,通过简单地编写 Mapper 和 Reducer 类,就能完成复杂的单词计数任务。这种简单性极大地降低了分布式编程的门槛,使得更多的开发者能够参与到大数据处理的项目中 。
- 良好扩展性:随着数据量的不断增长和业务需求的变化,计算资源往往需要相应地扩展。MapReduce 具有出色的扩展性,当现有集群的计算资源无法满足需求时,只需要简单地向集群中添加更多的节点,就可以轻松地扩展计算能力。MapReduce 框架能够自动识别新加入的节点,并将任务合理地分配到这些节点上,实现负载均衡。例如,某电商平台在促销活动期间,数据量大幅增加,通过添加服务器节点到 MapReduce 集群,顺利完成了海量订单数据的处理,保证了业务的正常运行 。
- 高容错性:在大规模的集群环境中,节点故障是不可避免的。MapReduce 设计之初就考虑到了容错性问题,具有高度的容错能力。当某个节点发生故障时,MapReduce 框架能够自动检测到,并将该节点上未完成的任务重新分配到其他健康的节点上继续执行,整个过程无需人工干预。同时,MapReduce 还会对中间结果进行冗余存储,以防止数据丢失。这使得 MapReduce 在处理大规模数据时非常可靠,能够保证任务的顺利完成。比如,在一个包含数百个节点的 MapReduce 集群中,即使有少数节点出现故障,也不会影响整个数据处理任务的进行 。
- 适合海量数据处理:MapReduce 的设计目标就是处理大规模的数据集,它能够充分利用集群中多台机器的计算资源,实现数据的并行处理。通过将数据分割成多个小块,分配到不同的节点上同时进行处理,大大提高了数据处理的速度和效率。无论是 TB 级还是 PB 级的数据,MapReduce 都能游刃有余地应对。例如,搜索引擎在处理网页索引数据时,面对数以亿计的网页,MapReduce 可以高效地完成数据的处理和分析,为用户提供快速准确的搜索结果 。
(二)局限性
- 不适合实时计算:MapReduce 主要适用于离线批量数据处理,对于实时计算场景存在较大的局限性。实时计算要求能够快速地对实时产生的数据进行处理,并及时返回结果。而 MapReduce 在处理数据时,需要经历 Map、Shuffle、Reduce 等多个阶段,整个过程涉及大量的数据读取、传输和处理,导致处理延迟较高,无法满足实时性的要求。例如,在实时监控系统中,需要对传感器实时采集的数据进行分析和处理,MapReduce 就难以胜任,而更适合使用像 Storm、Flink 这样的实时计算框架 。
- 中间结果写磁盘导致 I/O 开销大:在 MapReduce 的 Shuffle 阶段,Map 任务的输出结果需要写入本地磁盘,然后再通过网络传输到 Reduce 任务所在的节点,Reduce 任务处理完后又要将结果写入磁盘。这种频繁的磁盘 I/O 操作会带来很大的性能开销,尤其是在处理大规模数据时,I/O 瓶颈会严重影响整个系统的性能。虽然可以通过一些优化措施,如启用数据压缩、合理设置缓冲区大小等,来减少 I/O 开销,但仍然无法从根本上解决问题 。
- 表达能力有限:MapReduce 的编程模型相对固定,只包含 Map 和 Reduce 两个主要阶段,对于一些复杂的算法和计算任务,难以用 MapReduce 来表达和实现。例如,对于需要进行复杂的迭代计算、图计算等任务,使用 MapReduce 实现起来会非常困难,甚至无法实现。在这些场景下,需要使用更加灵活和强大的计算框架,如 Spark,它提供了丰富的操作算子和更灵活的编程模型,能够更好地支持复杂算法的实现 。
- 资源利用率低:在 MapReduce 中,Map 阶段和 Reduce 阶段是顺序执行的,在 Map 阶段,Reduce 任务的资源处于闲置状态;而在 Reduce 阶段,Map 任务的资源又被浪费。这种资源的静态分配方式导致资源利用率较低,无法根据任务的实际需求进行动态调整。相比之下,一些新的计算框架,如 Spark,采用了 DAG(有向无环图)执行引擎,能够更合理地调度资源,提高资源利用率 。
综上所述,MapReduce 具有易于编程、扩展性好、容错性强等优点,在处理海量离线数据方面表现出色,但同时也存在不适合实时计算、I/O 开销大、表达能力有限等缺点。在实际应用中,我们需要根据具体的业务需求和数据特点,权衡 MapReduce 的优缺点,选择合适的技术方案来解决大数据处理问题。
五、MapReduce 与其他技术对比
(一)与 Spark 对比
在大数据处理的技术版图中,MapReduce 和 Spark 无疑是两颗璀璨的明星,它们各自闪耀着独特的光芒,在不同的场景下发挥着重要作用。深入了解它们之间的差异,能帮助我们在面对实际问题时做出更合适的技术选择。
从数据处理模型来看,MapReduce 采用的是较为传统的 Map 和 Reduce 两个阶段的模型,数据在这两个阶段之间通过磁盘进行交换。这种模型简单直观,易于理解和实现,对于大规模的离线批处理任务能够很好地完成。而 Spark 则引入了弹性分布式数据集(RDD)的概念,这是一种可以弹性地在内存或磁盘上存储的数据抽象。RDD 支持丰富的操作算子,如 map、reduce、filter、join 等,并且可以通过 DAG(有向无环图)执行引擎对操作进行优化和调度。这使得 Spark 的编程模型更加灵活,能够支持更复杂的数据处理逻辑 。
在执行效率方面,Spark 凭借其内存计算的特性,在很多场景下表现出了明显的优势。由于中间结果可以保存在内存中,避免了像 MapReduce 那样频繁地读写磁盘,大大减少了 I/O 开销,从而显著提高了处理速度。特别是对于需要多次迭代计算的任务,如机器学习中的迭代算法,MapReduce 每次迭代都需要重新读取磁盘上的数据,而 Spark 可以直接在内存中对 RDD 进行操作,效率提升非常明显。有研究表明,在处理相同规模的迭代计算任务时,Spark 的执行时间可能仅为 MapReduce 的几分之一甚至更短 。
然而,MapReduce 也并非一无是处。在一些特定场景下,它依然有着独特的优势。例如,当数据量非常巨大,超出了内存的承载能力时,MapReduce 基于磁盘的处理方式就显示出了稳定性。它可以将数据分块存储在磁盘上,逐步进行处理,而不会因为内存不足导致任务失败。此外,对于一些简单的、单次读取数据的 ETL(抽取、转换、加载)任务,MapReduce 的批处理模式也能够高效地完成,并且由于其成熟稳定的特性,在一些对稳定性要求较高的企业级应用中仍然被广泛使用 。
从适用场景来看,MapReduce 更适合于对稳定性要求高、数据量极大且不需要频繁迭代计算的离线批处理任务,如大规模数据的归档、传统的数据分析报表生成等。而 Spark 则更擅长于需要快速迭代计算、实时性要求较高以及交互式数据分析的场景,如机器学习模型的训练、实时流数据处理(通过 Spark Streaming)、数据挖掘中的复杂算法实现等。比如,在电商平台进行实时的用户行为分析,需要对源源不断产生的用户操作数据进行快速处理和分析,Spark Streaming 就能很好地满足这种实时性需求;而在进行历史订单数据的归档和统计分析时,MapReduce 则是一个可靠的选择 。
(二)与 Flink 对比
Flink 作为大数据处理领域的后起之秀,与 MapReduce 也有着诸多不同之处,尤其在流处理能力、延迟性、容错机制等方面展现出了独特的优势 。
在流处理能力上,Flink 具有天生的优势,它是一个以流处理为核心设计理念的计算引擎,将批处理视为流处理的特例,通过有限流模拟批处理。Flink 可以实时处理无界数据流,能够对源源不断输入的数据进行即时处理,这与 MapReduce 主要面向离线批处理的模式形成了鲜明对比。例如,在物联网场景中,传感器会持续不断地产生大量数据,Flink 能够实时地对这些数据进行处理,实现实时监控、预警等功能,而 MapReduce 则难以满足这种实时性的流数据处理需求 。
延迟性方面,Flink 表现出色,能够实现低延迟的数据处理,通常可以达到毫秒到秒级的延迟。这得益于它基于内存的流水线式处理方式,数据在各个处理节点之间以流水线的形式快速流动,减少了数据等待和处理的时间。而 MapReduce 由于其批处理的特性,在处理数据时需要经历 Map、Shuffle、Reduce 等多个阶段,整个过程涉及大量的数据读取、传输和处理,导致处理延迟较高,一般在分钟到小时级,无法满足对延迟要求苛刻的实时应用场景 。
容错机制上,Flink 采用了基于分布式快照(Checkpoint)和精确一次(Exactly-Once)语义的容错策略。Flink 会定期生成检查点,将当前输入流的偏移位置和任务状态持久化到外部存储中。一旦发生故障,Flink 可以根据检查点记录的信息,从故障点重新恢复任务的执行,保证数据不会丢失也不会被重复处理。而 MapReduce 主要通过任务重试和 HDFS 的数据副本实现容错。当某个任务失败时,MapReduce 会将该任务重新分配到其他节点上执行,但这种方式可能会导致数据的重复处理,并且在处理大规模数据时,任务重试的开销较大 。
在适用场景上,Flink 适用于对实时性要求极高的流数据处理场景,如实时风控、实时推荐、金融交易监控等。在这些场景中,需要对数据进行快速处理并及时做出响应,Flink 的低延迟和高效流处理能力能够很好地满足需求。而 MapReduce 则更适合于大规模离线数据的批量处理,如数据仓库的构建、历史数据的统计分析等,这些任务对实时性要求不高,但对数据处理的稳定性和准确性有较高要求 。
六、总结与展望
MapReduce 作为大数据处理领域的重要技术,以其独特的 “分而治之” 理念,为我们打开了高效处理海量数据的大门。通过将复杂的计算任务分解为 Map 和 Reduce 两个阶段,MapReduce 实现了数据的并行处理,大大提高了数据处理的效率和可扩展性。从网站日志分析到金融风险评估,从用户行为洞察到数据挖掘与机器学习,MapReduce 在众多实际应用场景中都发挥着不可或缺的作用,成为了大数据时代的基石技术之一 。
然而,技术的发展永无止境,大数据领域更是日新月异。随着数据量的持续爆炸式增长、业务需求的日益复杂多样,MapReduce 的局限性也逐渐凸显,如实时性不足、I/O 开销大、表达能力有限等问题,在一定程度上限制了它在某些场景下的应用。但这也正是技术进步的动力源泉,促使着我们不断探索和创新 。
展望未来,大数据技术将朝着更加智能化、实时化、高效化的方向发展。一方面,以 Spark、Flink 为代表的新一代大数据计算框架,凭借其内存计算、流批一体等特性,在实时计算、迭代计算等领域展现出了强大的优势,正逐渐成为大数据处理的主流技术。另一方面,人工智能、机器学习与大数据技术的深度融合,将为数据处理和分析带来全新的视角和方法,挖掘出数据中更深层次的价值 。
对于我们学习者而言,MapReduce 依然是大数据技术体系中不可或缺的基础知识。深入理解 MapReduce 的原理和编程模型,不仅有助于我们掌握大数据处理的基本思想和方法,还能为学习和应用其他大数据技术打下坚实的基础。同时,我们也要紧跟技术发展的潮流,积极学习和探索新的大数据技术和框架,不断提升自己的技术能力和综合素质,以适应未来大数据领域的发展需求 。
在大数据的广阔海洋中,MapReduce 是我们扬帆起航的起点。让我们以此为契机,不断探索和学习,共同迎接大数据时代更加辉煌的未来。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 24
24 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)