
目标检测系列2——yolov1原理与实现
YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。现在YOLO已经发展到v5版本,不过新版本也是在原有版本基础上不断改进演化的,yolo1 原理1.1 基础知识1.2 yolo原理1.2.1 分类原理1.2.2 yolo0.1版本1.2.3 yolo0.5版本1.2.4 yolo0.8版本1.2.5 yolo1
YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。现在YOLO已经发展到v5版本,不过新版本也是在原有版本基础上不断改进演化的,本文重点讲解Yolo v1算法细节。v1相比v2、v3以及其他物体检测算法,思路简单清晰,非常适合物体检测初学者上手。即使没有过任何物体检测相关知识,只需要一点卷积神经网络基础,便可以看懂Yolo v1。
yolo
1 背景原理
1.1 基础知识
(1)卷积过程中特征图的大小在变化,但是相对位置不变,位置信息得以保留,256×256图中a物体在b物体的右边,经过下采样变成64×64后,a物体还在b物体的右边。
(2)一个512个通道的128×128的特征图中,宽W和高H就代表着位置信息,像素点位置代表特定位置的信息,512的通道就代表512的信息,比如第3行第4列的点一共有512个像素信息。宽高只提供位置信息,通道提供特征信息,几个通道就代表某一点有几个特征信息。位置为(3,4)的像素点一共有512个特征信息,也就是512个值,将这些值排列起来,得到一个512个数的向量,得到这个像素点的信息,每个数代表特殊含义,比如类别,颜色,位置等,具体含义跟任务有关。
(3)每个通道的数是一个矩阵
(4)一个7×7的特征图的一个像素点对应原始图像的一大片区域,也就是感受野。
1.2 yolo原理
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。
1.2.1 分类原理
分类只能输出一个类别,对于20分类,得到softmax就是1×20的向量,20个数代表20个置信度(或者说是概率,但是置信度和概率还不一样),20个数总和为1,20个数那个最大就是哪类。
1.2.2 yolo0.1版本
yolo0.1版本
受到分类的启发,1个长为20的向量得到图像的一个信息,输入哪个类。
那如果得到49(7×7)个长为20的向量不久能得到49个目标的类别了吗?当然可以,
得到7×7×20的20个通道的二维向量,就是有49个像素点,有20个通道,代表20个类属于哪一类,就能得到49个目标的类别了。
1.2.3 yolo0.5版本
yolo0.5版本
在yolo0.1版本的基础上,发现一个问题,如果1个像素点上只是背景值,不包括那20个类,那怎么办?

增加一个维度不就解决了,yolo0.1版本得到7×7×20的20个通道的二维向量,那现在得到7×7×21的21个通道的二维向量,前20个通道还是代表20个类属于哪一类,第21个通道的信息代表包不包含背景值,包含就是1,不包含就是0,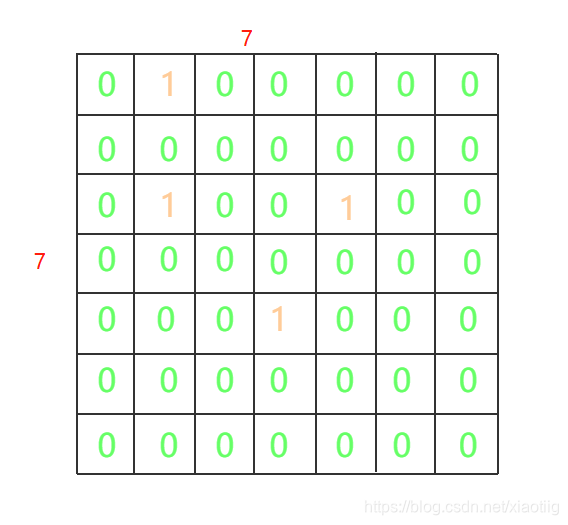
1.2.4 yolo0.8版本
yolo0.8版本
在yolo0.5的基础上增加X,Y,W,H4个目标的坐标信息
得到一个【7,7,25】的3维数组,前两个表示位置信息,后面的25表示特征信息,25=20+4+1,20个类,4个目标的位置信息x、y、w、h,最后的1代表是不是有目标。
实际上到这里已经就可以实现目标检测了
注意yolo0.1版本、yolo0.5版本和yolo0.8版本初属虚构,为了更好的理解和推导整个过程。
1.2.5 yolo1.0版本
1.2.6 问题
(1)如果目标大于49个呢?那就无法输出了,这就是之后要改进的。
(2)如果一个像素存在两个目标呢,yolov1最后的输出的每个像素只能识别一个目标,这就是之后要改进的。
1.3 介绍
yolo是Jeseph Redmon2015年的作品

YOLO是计算机视觉领域最知名的目标检测算法之一,也因为开源被业界广泛采用。作者Joseph Redmon曾凭借该算法获得过2016年CVPR群众选择奖(People’s Choice Award)、2017年CVPR最佳论文荣誉奖(Best Paper Honorable Mention)
2020年2月23日消息,YOLO算法作者Joseph Redmon在个人Twitter上宣布,将停止一切CV研究,原因是自己的开源算法已经用在军事和隐私问题上。这对他的道德造成了巨大的考验。
YOLO及其改进算法在学术圈被广泛引用,Redmon三篇一作相关论文yolov1\v2\v3总引用量已经超过1万。这样一位极具影响力的学者突然宣布退出,不免令学术界感到震撼。Fast.ai创始人Jeremy Howard就表达了自己的感受:“我之前从来没见过这种事。”一位法国科技公司的CTO表示,对Redmon的信念表示敬意。Redmon过去张扬的个性可能为他今天的决定埋下了伏笔。
Jeseph Redmon毕业于美国米德尔伯里学院计算机科学专业,辅修数学。2013年进入华盛顿大学计算机专业攻读硕士学位,继而攻读博士学位,直到2019年。在此期间,他和导师Ali Farhadi共同提出并改进了YOLO算法。他的主要研究范围是目标检测、图像分类和模型压缩。Redmon宣布退出CV领域研究,基本上等于将来要另起炉灶。
Joseph Redmon过去的实习经历也金光闪闪。他曾在谷歌大脑实习,研究实时机器人抓握检测。之后进入AI2(也就是后来的XNOR.ai)实习,提出了二元逼近卷积神经网络XNOR-Net,该算法能够减少在移动设备上进行图像分类所需的计算量。
Redmon本人还登上过TED讲台,介绍快速识别物体的CV算法。
原文链接:https://www.xianjichina.com/special/detail_440552.html
1.4 主要特点
YOLO主要特点是:
速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
泛化能力强。
Yolo v1整体框架结构比较简单清晰,它是用回归做物体检测的开山之作,有些细节需要多加注意!
2 yolo框架
一共三步:
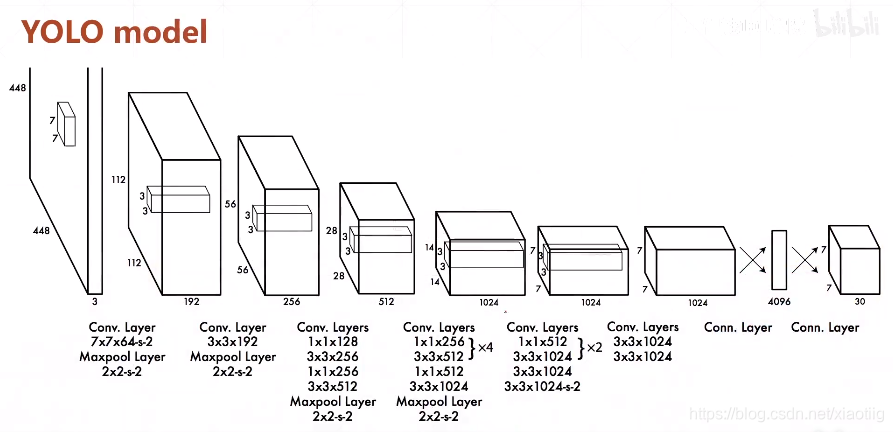
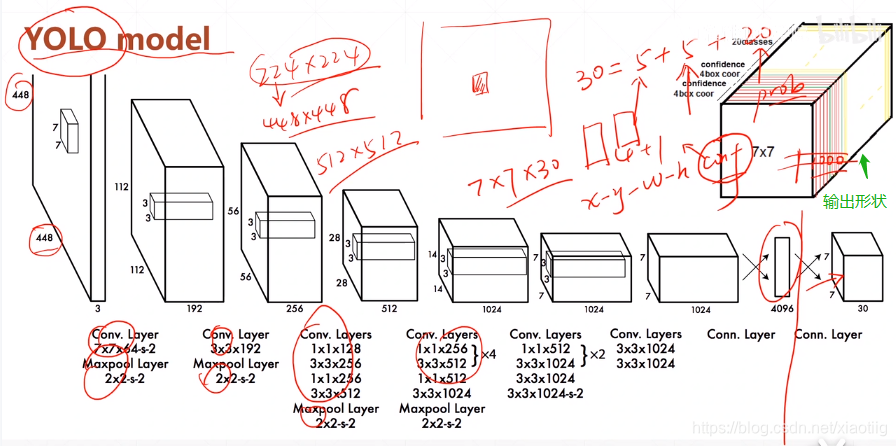
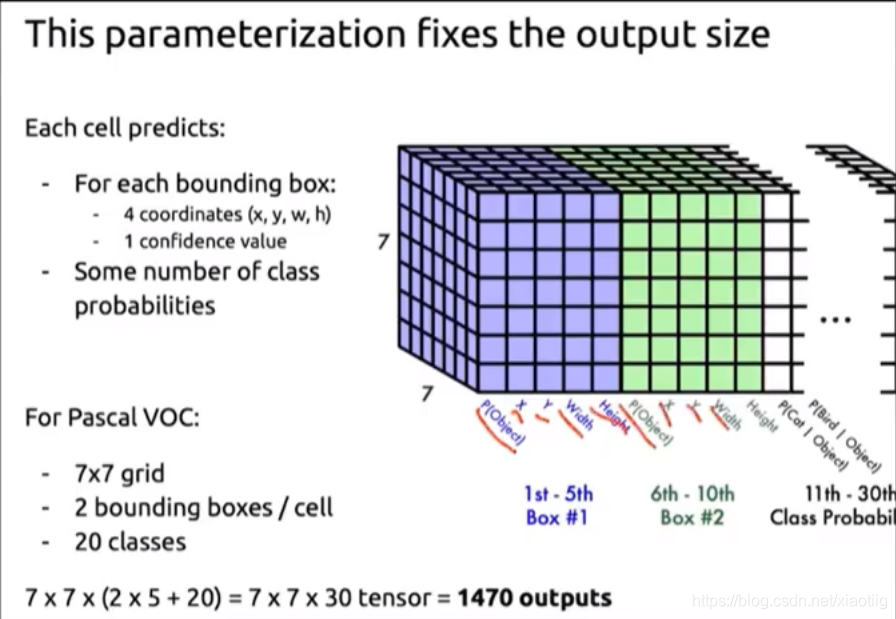
直接上结构图,输入图像大小为448448,经过若干个卷积层与池化层,变为771024张量(图一中倒数第三个立方体),最后经过两层全连接层,输出张量维度为7730,这就是Yolo v1的整个神经网络结构,和一般的卷积物体分类网络没有太多区别,最大的不同就是:分类网络最后的全连接层,一般连接于一个一维向量,向量的不同位代表不同类别,而这里的输出向量是一个三维的张量(77*30)。上图中Yolo的backbone网络结构,受启发于GoogLeNet,也是v2、v3中Darknet的先锋。本质上来说没有什么特别,没有使用BN层,用了一层Dropout。除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数。网络结构没有特别的东西,不再赘述。
2.1 7*7的含义
77是指图片被分成了77个格子,如下所示:

在Yolo中,如果一个物体的中心点,落在了某个格子中,那么这个格子将负责预测这个物体。这句话怎么理解,用上图举例,设左下角格子假设坐标为(1,1),小狗所在的最小包围矩形框的中心,落在了 (2,3) 这个格子中。那么77个格子中,(2,3) 这个格子所对应的物体置信度标签为1,而那些没有物体中心点落进来的格子,对应的物体置信度标签为0。这个设定就好比该网络在一开始,就将整个图片上的预测任务进行了分工,一共设定77个按照方阵列队的检测人员,每个人员负责检测一个物体,大家的分工界线,就是看被检测物体的中心点落在谁的格子里。当然,是77还是99,是上图中的参数S,可以自己修改,精度和性能会随之有些变化。
2.2 30的含义
刚才设定了49个检测人员,那么每个人员负责检测的内容,就是这里的30(注意,30是张量最后一维的长度)。在Yolo v1论文中,30是由(4+1)×2+20得到的。其中4+1是矩形框的中心点坐标x,y,长宽 w,h 以及是否属于被检测物体的置信度c;2是一个格子共回归两个矩形框,每个矩形框分别产生5个预测值( x,y,w,h,c);20代表预测20个类别。这里有几点需要注意:
-
每个方格(grid) 产生2个预测框,2也是参数,可以调,但是一旦设定为2以后,那么每个方格只产生两个矩形框,最后选定置信度更大的矩形框作为输出,也就是最终每个方格只输出一个预测矩形框。最后经过筛选只得到一个框。
-
每个方格只能预测一个物体。虽然可以通过调整参数,产生不同的矩形框,但这只能提高矩形框的精度。所以当有很多个物体的中心点落在了同一个格子里,该格子只能预测一个物体。也就是格子数为7*7时,该网络最多预测49个物体。
3.如上述原文中提及,在强行施加了格点限制以后,每个格点只能输出一个预测结果,所以该算法最大的不足,就是对一些邻近小物体的识别效果不是太好,例如成群结队的小鸟。
c就是confidence
bounding box就是回归框
2.3 loss的计算:
看到这里读者或许会有疑问,Yolo里的每个格点,是怎么知道该预测哪个物体的?这就是神经网络算法的能力。首先拿到一批标注好的图片数据集,按照规则打好标签,之后让神经网络去拟合训练数据集。训练数据集中的标签是通过人工标注获得,当神经网络对数据集拟合的足够好时,那么就相当于神经网络具备了一定的和人一样的识别能力。
loss计算:
目标值就是25个数,预测值也是25个数,进行损失函数计算。
图5 损失函数
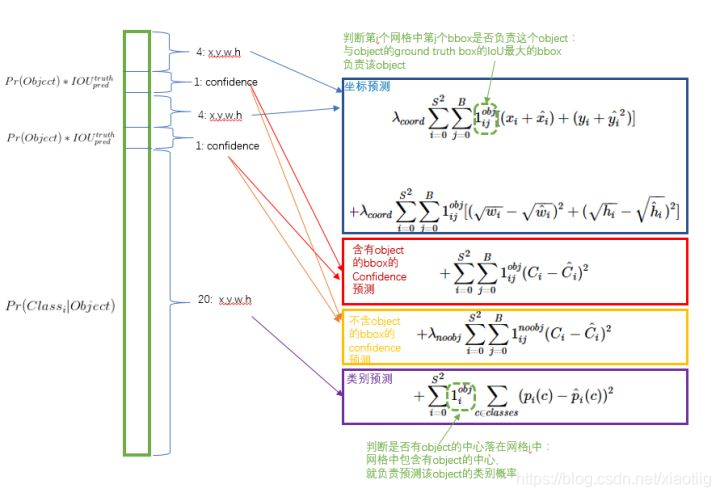
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。而sum-square error loss中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。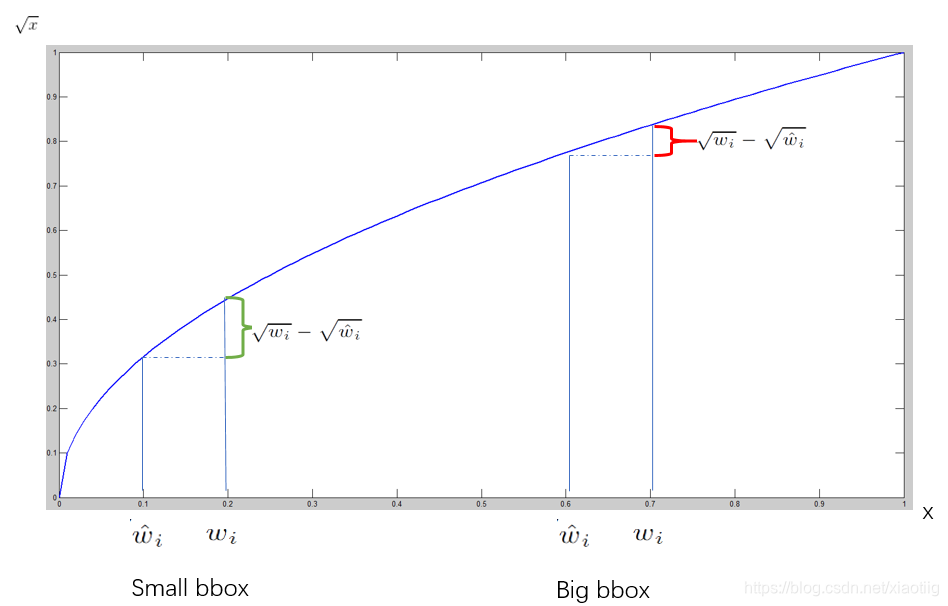
2.4 一些小技巧
2.4.1回归offset代替直接回归坐标
(x,y) 不直接回归中心点坐标数值,而是回归相对于格点左上角坐标的位移值。例如,第一个格点中物体坐标为 (2.3,3.6),另一个格点中的物体坐标为(5.4,6.3),这四个数值让神经网络暴力回归,有一定难度。所以这里的offset是指,既然格点已知,那么物体中心点的坐标一定在格点正方形里,相对于格点左上角的位移值一定在区间[0, 1)中。让神经网络去预测(0.3,0.6) 与 (0.4,0.3)会更加容易,在使用时,加上格点左上角坐标(2,3)、(5,6)即可。
2.4.2 同一格点的不同预测框有不同作用
前文中提到,每个格点预测两个或多个矩形框。此时假设每个格点预测两个矩形框。那么在训练时,见到一个真实物体,我们是希望两个框都去逼近这个物体的真实矩形框,还是只用一个去逼近?或许通常来想,让两个人一起去做同一件事,比一个人做一件事成功率要高,所以可能会让两个框都去逼近这个真实物体。但是作者没有这样做,在损失函数计算中,只对和真实物体最接近的框计算损失,其余框不进行修正。这样操作之后作者发现,一个格点的两个框在尺寸、长宽比、或者某些类别上逐渐有所分工,总体的召回率有所提升。
(这里还没有理解)
2.4.3 使用非极大抑制生成预测框
通常来说,在预测的时候,格点与格点并不会冲突,但是在预测一些大物体或者邻近物体时,会有多个格点预测了同一个物体。此时采用非极大抑制技巧,过滤掉一些重叠的矩形框。但是mAP提升并没有显著提升。(非极大抑制,物体检测的老套路,这里不再赘述)
2.4.4 推理时将p×c作为输出置信度
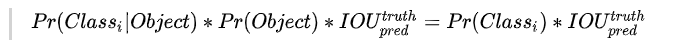
在推理时,使用物体的类别预测最大值p乘以预测框的最大值c,作为输出预测物体的置信度。这样也可以过滤掉一些大部分重叠的矩形框。输出检测物体的置信度,同时考虑了矩形框与类别,满足阈值的输出更加可信。

得到每个bbox的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
3 效果
如下性能的硬件环境都是GPU Titan X:
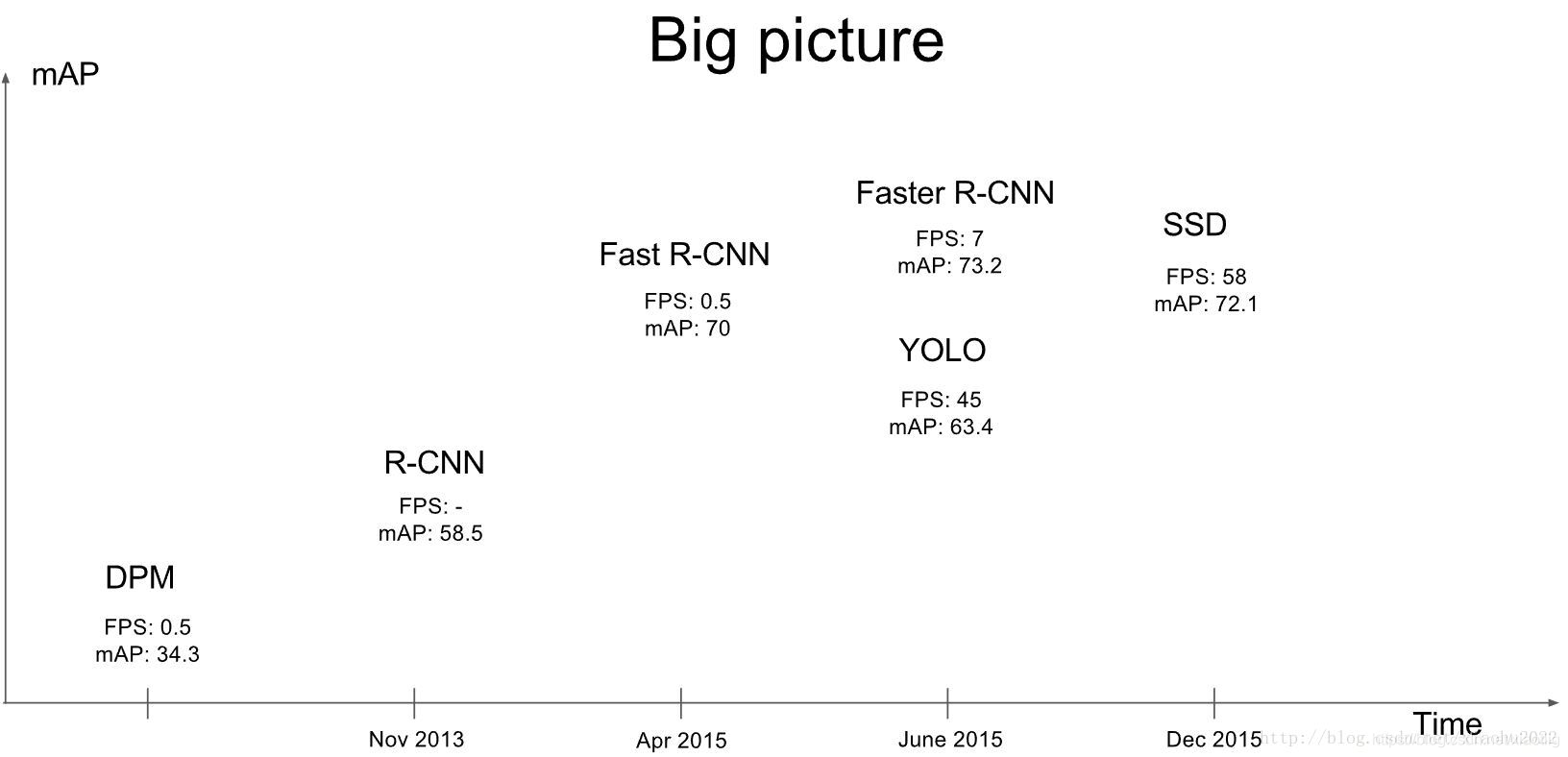
backbone同为VGG-16,Yolo比Faster R-CNN少了将近7点mAP,但是速度变为三倍,Fast Yolo和Yolo相比,少11点mAP,但是速度可以达到155张图片每秒。后续的Yolo v3中,准确率和速度综合再一次提升,所以v1的性能不再过多分析。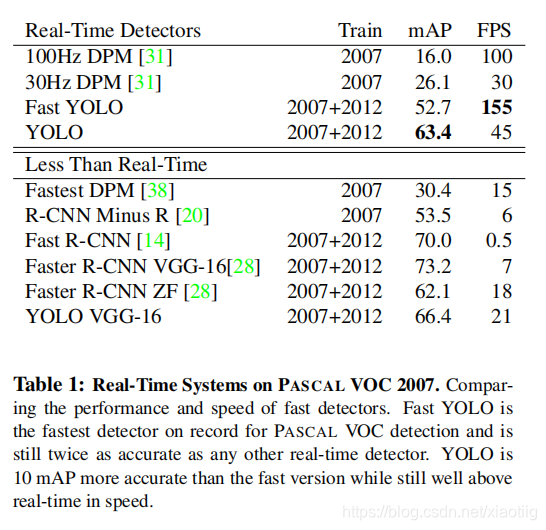
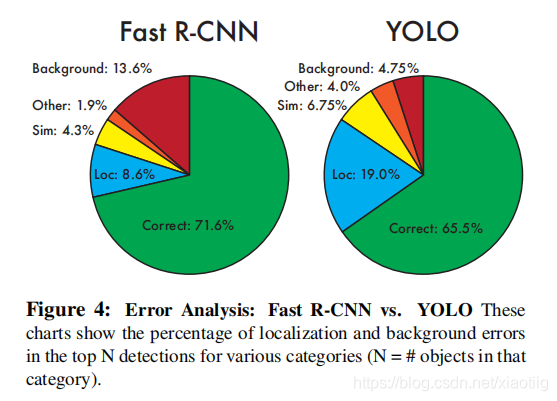

其中,Yolo的Localization错误率更高,直接对位置进行回归,确实不如滑窗式的检测方式准确率高。但是Yolo对于背景的误检率更低,由于Yolo在推理时,可以“看到”整张图片,所以能够更好的区分背景与待测物体。作者提到Yolo对于小物体检测效果欠佳,不过在v2与v3中都做了不少改进。
4 代码实现
5 参考文献
yolo系列论文下载网址:
https://zhuanlan.zhihu.com/p/136382095
2020 年 4 月 23 日YOLOv4 发布,2020 年 6 月 10 日YOLOv5发布。
Yolov5的作者并没有发表论文,因此只能从代码角度进行分析。
Yolov5代码:github.com/ultralytics/
yolov1的讲解:
https://zhuanlan.zhihu.com/p/70387154
本文的许多部分来自这篇文章
这个视频讲解很详细:
https://www.bilibili.com/video/BV14E411G7ev?p=3
下面这个讲解的很细:
https://blog.csdn.net/qq_30815237/article/details/91949543
对本文所参考资料的作者表示感谢!
谢谢

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 3
3 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)