
Spark大数据-Dstream概述
Dstream概述工作机制输入数据流的input Dstream和receiver挂接起来。1.创建输入Dstream定义输入源,文件流,kafka,rdd队列流。2.转换和输出操作定义流计算过程。3.StreamingContext.start()、awaitTermination()等待处理结束(发生错误结束)、stop()手动结束。// 创建StreamingContext...
·
Dstream概述
工作机制
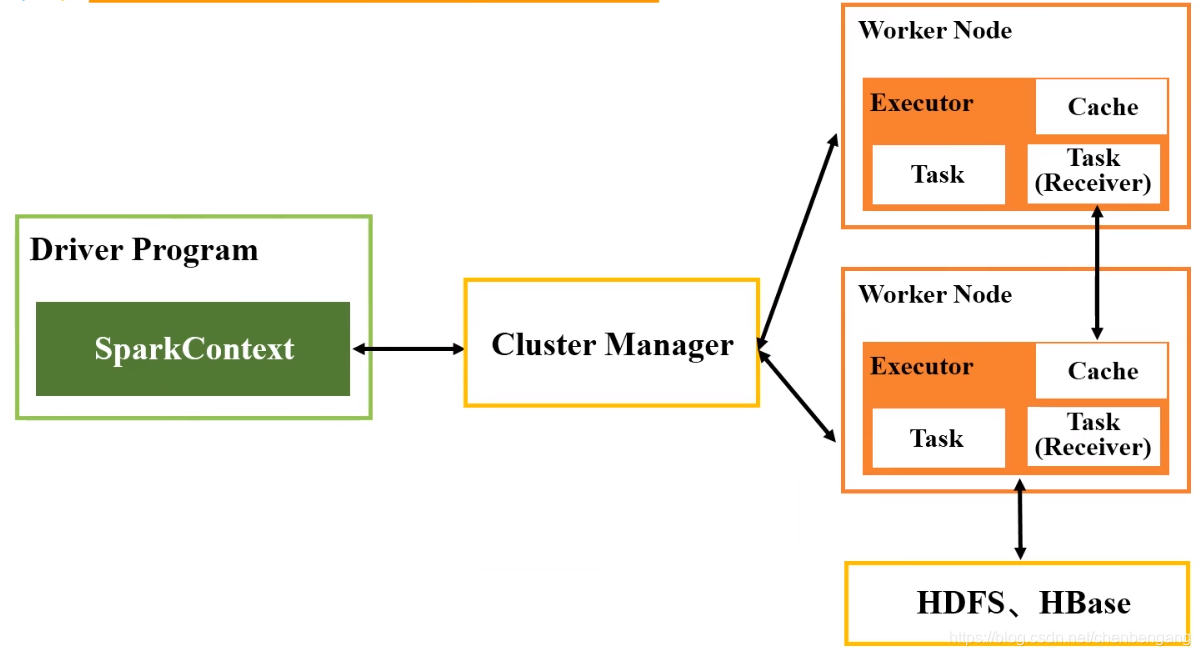
- 输入数据流的input Dstream和receiver挂接起来。
- 1.创建输入Dstream定义输入源,文件流,kafka,rdd队列流。
- 2.转换和输出操作定义流计算过程。
- 3.StreamingContext.start()、awaitTermination()等待处理结束(发生错误结束)、stop()手动结束。
// 创建StreamingContext对象
import org.apache.spark._
import org.apache.spark.streaming._
// 本地模式下启动两个线程,创建ssc,一个监听一个处理
val conf = new SparkConf().setAppName("FileDStream").setMaster("local[2]")
val ssc=new StreamingContext(conf,Seconds(20))
// 定义Dstream的输入源,套接字流、文件流、kafka流、rdd队列流
// 此处为文件流
val lines=ssc.textFileStream("file:///home/chenbengang/ziyu_bigdata/quick_learn_spark/logfile")
// 转换和输出操作,分析程序
val words=lines.flatMap(_.split(" "))
val wordCounts=words.map(word => (word,1)).reduceByKey((x,y)=>x+y)
wordCounts.print()
// 启动
ssc.start()
// 实际上,当你输入这行回车后,Spark Streaming就开始进行循环监听,下面的ssc.awaitTermination()是无法输入到屏幕上的,
// 但是,为了程序完整性,这里还是给出ssc.awaitTermination(),在合适的时候结束。stop手动借结束
ssc.awaitTermination()
// 无法监听历史文件,只能监听新增的文件

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)