
【语音事件检测--论文翻译】Towards duration robust weakly supervised sound event detection 面向持续时间鲁棒弱监督声音事件检测
此外,性能良好的分段级定位模型以粗略的尺度输出预测(例如1秒),阻碍了它们在包含以下内容的数据集上的部署短事件(<1秒)。我们提出的模型,我们进一步称之为CDur(CRNN持续时间,见表I),由五层CNN组成随后是门控循环单元(GRU)。声音事件检测(SED)是标记的任务音频事件的缺失或存在及其对应给定音频片段内的间隔。虽然SED可以使用监督机器学习,其中训练数据被完全标记通过访问每个事件的时间戳
【论文】论文
【源码】https://github.com/RicherMans/CDur
摘要:
声音事件检测(SED)是标记的任务音频事件的缺失或存在及其对应给定音频片段内的间隔。虽然SED可以使用监督机器学习,其中训练数据被完全标记通过访问每个事件的时间戳和持续时间,我们的工作侧重于弱监督声音事件检测(WSSED),其中关于事件持续时间的先验知识是不可用的。
该领域最近的研究侧重于提高特定数据集在特定评估指标方面的分段和事件级定位性能。具体来说,表现良好事件级本地化需要完全标记的开发子集获得事件持续时间估计,这将带来巨大的好处
本地化性能。此外,性能良好的分段级定位模型以粗略的尺度输出预测(例如1秒),阻碍了它们在包含以下内容的数据集上的部署短事件(<1秒)。这项工作提出了一个稳健的持续时间CRNN(CDur)框架,旨在实现竞争力在细分市场和事件级本地化方面的表现。本文提出了一种新的后处理策略,命名为“三重阈值”并研究了两种数据增强方法以及范围内的标签平滑方法WSSED。我们的模型评估是在DCASE2017上完成的2018年任务4数据集和URBAN-SED。我们的模型表现优异
DCASE2018和URBAN-SED数据集的其他方法而不需要事先了解持续时间。特别是,我们
该模型具有与强标签相似的性能URBAN-SED数据集上的监督模型。最后,消融
实验表明,如果不进行后处理,我们的模型本地化性能下降明显低于其他方法。
方法框架: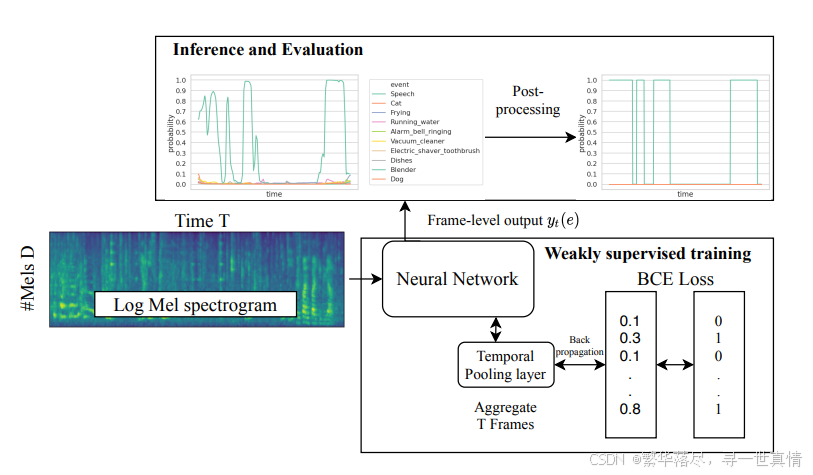

我们的方法框架如图1所示,其中具有时间池和子采样的骨干CRNNlayers在训练过程中学习剪辑级事件概率。对于推理,我们提出了三重阈值来增强持续时间稳健性。我们提出的模型,我们进一步称之为CDur(CRNN持续时间,见表I),由五层CNN组成随后是门控循环单元(GRU)。模型是
基于[5]中的结果,对其进行了修改以进一步提高性能。具体来说,CDur利用双卷积块和三个子采样阶段,而不是五个子采样阶段。此外,我们的模型通过利用batchnorm、卷积、激活块结构获得了实质性的收益,特别是在与Leaky整流线性单元(LeakyReLU)配对。这个CNN前端提取的抽象表示是
然后由具有128个隐藏单元的双向GRU进行处理。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 8
8 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)