
当今自然语言处理领域中的成功之路:Transformer模型
通过多层自注意力机制的堆叠和前馈神经网络(feed-forward neural network)的加入,Transformer模型能够更好地理解文本数据并进行高质量的预测。与传统的递归神经网络(如循环神经网络)不同,Transformer使用了全连接层和注意力机制,能够在保持序列信息的情况下更好地处理长序列的文本数据。更好地处理长序列:由于自注意力机制的引入,Transformer模型能够更好地
当今自然语言处理领域中最重要和最成功的模型之一是Transformer模型。它是一种基于自注意力机制的神经网络模型,最初由Google公司的研究人员提出,并被广泛应用于机器翻译、文本生成、情感分析等任务中。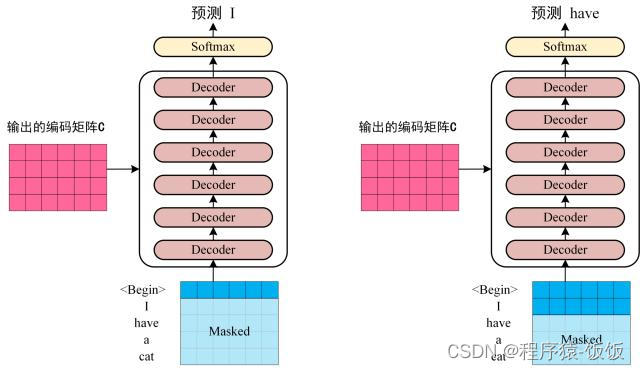
Transformer模型之所以被广泛使用,是因为它在自然语言处理任务中取得了相当不错的结果。与传统的递归神经网络(如循环神经网络)不同,Transformer使用了全连接层和注意力机制,能够在保持序列信息的情况下更好地处理长序列的文本数据。
关注威x公众H【Ai技术星球】回复(123)必领transformer相关z源
在Transformer中,最重要的组件是自注意力机制(self-attention)。自注意力机制通过将输入序列中每个位置的信息进行比较,从而让模型能够更好地理解序列中不同位置之间的关系。通过多层自注意力机制的堆叠和前馈神经网络(feed-forward neural network)的加入,Transformer模型能够更好地理解文本数据并进行高质量的预测。
除了自注意力机制和前馈神经网络,Transformer还引入了许多其他的技术,如残差连接(residual connections)和层归一化(layer normalization),从而使得Transformer更加稳定和高效。
与传统的序列模型相比,Transformer模型具有以下优势:
-
更好地处理长序列:由于自注意力机制的引入,Transformer模型能够更好地处理长序列的文本数据,避免了递归神经网络的梯度消失问题。
-
并行计算能力更强:Transformer模型可以将整个序列同时进行处理,因此在处理长序列数据时比递归神经网络更快。
-
更容易训练:由于使用了残差连接和层归一化等技术,Transformer模型的训练更加稳定和容易。
总之,Transformer模型是一种非常成功和强大的自然语言处理模型,已被广泛应用于机器翻译、文本生成、情感分析等任务中。随着深度学习技术的不断发展和完善,相信Transformer模型还将在自然语言处理领域中继续发挥其巨大的潜力。
链接容易和谐,配套z料+60G入门进阶AI资Y包+论文/学习/就业/竞赛指导+大牛技术解答 资源包:深度学习神经网络+CV计算机视觉学习(两大框架pytorch/tensorflow+源码课件笔记)+NLP等
关注威x公众H【Ai技术星球】回复(123)必领

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)