
大数据Hadoop学习之——网页排名PageRank算法
一、算法说明PageRank即网页排名,也称佩奇排名(社会)。一些基本概念:1、网页入链:即投票,网页中对其他网页的超链接作为其他网页的入链,相当于对其他网页投一票;2、入链数量:如果一个网页获得其他网页的入链数量(投票)越多,说明该网页越重要;3、入链质量:即投票权值,入链的质量由投票的网页决定,初始化值所有网页都一样,可以设置为1。网页的超链接越多,投票的权值越低。4、阻尼系数d:也是佩奇定义
一、算法说明
PageRank即网页排名,也称佩奇排名(社会)。一些基本概念:
1、网页入链:即投票,网页中对其他网页的超链接作为其他网页的入链,相当于对其他网页投一票;
2、入链数量:如果一个网页获得其他网页的入链数量(投票)越多,说明该网页越重要;
3、入链质量:即投票权值,入链的质量由投票的网页决定,初始化值所有网页都一样,可以设置为1。网页的超链接越多,投票的权值越低。
4、阻尼系数d:也是佩奇定义的一个常数,用于反应超链接在人们日常访问方式中的占比,用于计算更真实的网页权重值,谷歌设置的阻尼系数为0.85。
5、网页权重pr值计算公式:pr = (1-d)/n + d*sum(tr)。d是阻尼系数,n是网页总数,tr是网页收到的投票权值。
6、经过n轮迭代计算,每个网页的新旧pr值的会越来越趋近于0,这时的pr值就越能反应网页之间的真实重要程度
如下,A、B、C、D四个网页,A拥有B和D的超链接,B拥有C超链接,C拥有A、B的超链接,D拥有B、C的超链接。
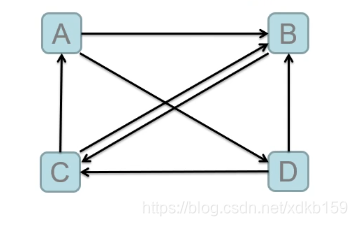
可以得到A获得C的半票,B获得A的半票、C的半票以及D的半片,C获得B的全票以及D的半票,D获得A的半票,用公式表示即:
tr(A) = 1/2 * pr(C)
tr(B) = 1/2 * pr(A) + 1/2 * pr(C) + 1/2 * pr(D)
tr(C) = pr(B) + 1/2 * pr(D)
tr(D) = 1/2 * pr(A)
可以看出,网页C获得的投票权值和最大,然后通过pr = (1-d)/n + d*sum(tr)公式计算各网页的pr值即可,这个计算过程可以一直迭代,网页的新旧pr值越接近,就越真实。
二、MapReduce分析
一、mapper映射输入数据集,输出以下两类数据:
1、当前网页拥有超链接的网页列表,以及当前网页的pr值;
2、当前网站对超链接网页列表各网页的投票,以及投票的权重。
二、reducer已网页为key,统计每个网页收到的投票值总和,然后计算pr值,最后输出本轮计算的结果
三、多轮迭代计算,根据设置好的新旧pr的差值计算是否停止迭代。
三、MapReduce实现
测试数据
A B D
B C
C A B
D B C
客户端
/**
* 网站pr计算公式:pr = (1-d)/n + d*sum(tr)
* d:阻尼系数,为0.85
* n:网站总数,这里即是记录条数
* tr:网站得到其他网站的投票权值
*/
public class PageRankDriver {
/**页面pr值差值范围,用于判断是否停止迭代*/
private static final double LIMIT = 0.001;
private static final double D = 0.85;
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(true);
//是否跨平台,如客户端在windows提交,需要设置成true做兼容,默认false
conf.set("mapreduce.app-submission.cross-platform", "true");
//配置程序运行平台,本地运行配置成local,分布式配置为yarn,分布式运行程序必须打成jar包
conf.set("mapreduce.framework.name", "local");
//最原始的网站数据
String inputFile = "/test/pagerank/input/page_data.txt";
FileSystem fs = FileSystem.get(conf);
//设置总到网站数
conf.setInt("pageNum", readFileLineNum(fs, inputFile));
//设置阻尼系数
conf.setDouble("zuniNumber", D);
int i = 0;
while (true) {
i++;
try {
//设置一个自定义配置,在mapreduce程序中读取,相当于传入一个入参
conf.setInt("runCount", i);
//输入格式化类的分隔符,初始化文件为空格,后续结果文件为制表符
String spiltStr = " ";
if (i != 1) {
inputFile = "/test/pagerank/output" + (i - 1) + "/part-r-00000";
spiltStr = "\t";
}
Path input = new Path(inputFile);
if (!fs.exists(input)) {
System.out.println("文件:" + inputFile + "不存在");
break;
}
//设置输入格式化类KeyValueTextInputFormat的分隔符,只分隔第一个,默认为/t
conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", spiltStr);
Job job = Job.getInstance(conf);
job.setJobName("pagerank-" + i);
job.setJarByClass(PageRankDriver.class);
//如果要本地提交分布式运行,不仅上面要配置yran,这里还需要配置打好的jar包的全路径
// job.setJar("/a/c/d.jar");
//设置输入格式化类,KeyValueTextInputFormat会将一行按照制表符分割,可通过参数设置分隔符
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setMapperClass(PageRankMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NetPage.class);
job.setReducerClass(PageRankReducer.class);
FileInputFormat.addInputPath(job, input);
Path output = new Path("/test/pagerank/output" + i);
FileOutputFormat.setOutputPath(job, output);
boolean flag = job.waitForCompletion(true);
if (flag) {
System.out.println("success.");
//从作业中取出计数器里的值,这个为每个页面的pr值的差值的总和
long sum = job.getCounters().findCounter(MyCounter.MY).getValue();
System.out.println("pr差值总和:" + sum);
double avgd = sum / 4000.0;
if (avgd < LIMIT) {
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 读取文件有多少行
*
* @param fs
* @param file
* @return
* @throws Exception
*/
public static int readFileLineNum(FileSystem fs, String file) throws Exception {
FSDataInputStream fsDataInputStream = fs.open(new Path(file));
InputStreamReader s = new InputStreamReader(fsDataInputStream);
BufferedReader reader = new BufferedReader(s);
int i = 0;
while (reader.ready()) {
i++;
reader.readLine();
}
return i;
}
}
客户端需要循环执行MapReduce,然后给pr的差值总和设定一个阀值,在作业中国设置一个计数器,当计数器值达到阀值便可以停止迭代。
并且需要再客户端传入一个参数,以便在程序中判断是第几次迭代,因为第一次迭代网页是没有pr值的,默认为1。
Mapper
public class PageRankMapper extends Mapper<Text, Text, Text, NetPage> {
/**当前页面*/
private final NetPage currPage = new NetPage(0);
/**关联网页*/
private final NetPage relPage = new NetPage(1);
private final Text mkey = new Text();
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
//输入数据样本有以下两种情况:
//key:A value:B D
//key:A:0.5 value:B D
//获取客户端设置的自定义参数
final int runCount = context.getConfiguration().getInt("runCount", 1);
if (runCount == 1) {
currPage.setPage(key.toString());
} else {
StringTokenizer st = new StringTokenizer(key.toString(), ":");
currPage.setPage(st.nextToken());
currPage.setPr(Double.parseDouble(st.nextToken()));
}
currPage.setRelationPage(value.toString());
mkey.set(currPage.getPage());
//第一类数据,当前网站对应的网站关系,以及当前网站的pr值
context.write(mkey, currPage);
String[] users = currPage.getRelationPage();
if (users != null && users.length > 0) {
double avgPr = currPage.getPr() / users.length;
for (int i = 0; i < users.length; i++) {
relPage.setPage(users[i]);
relPage.setPr(avgPr);
mkey.set(users[i]);
//第二类数据,当前网站对关联网站的投票,以及投票的权重
context.write(mkey, relPage);
}
}
}
}
Reducer
public class PageRankReducer extends Reducer<Text, NetPage, Text, Text> {
private final Text rkey = new Text();
private final Text rval = new Text();
@Override
protected void reduce(Text key, Iterable<NetPage> values, Context context) throws IOException, InterruptedException {
//输入数据样本也有两下两种:
//key A value A 1.0 B C 0
//key A value A 0.5 1
NetPage currPage = new NetPage();
double trSum = 0.0;
for (NetPage page : values) {
if (page.getPageType() == 0) {
//注意!!!reduce循环value的时候,不能将内部引用直接赋值给for循环外部用,
// reduce的迭代器不会新建对象,而是改变的原来引用的值,所以这里需要深度拷贝对象
// currPage = page;
currPage.setPage(page.getPage());
currPage.setPr(page.getPr());
currPage.setRelationPage(page.getRelationPage());
currPage.setPageType(page.getPageType());
} else {
//统计网站获得投票的权重总数值
trSum += page.getPr();
}
}
//获取网站总数
int pageNum = context.getConfiguration().getInt("pageNum", 1);
//获取阻尼系数,默认0.85
double d = context.getConfiguration().getDouble("zuniNumber", 0.85);
//根据公式计算新的pr值
double newPr = (1 - d) / pageNum + d * trSum;
//用新pr值和旧pr值计算差值
double c = newPr - currPage.getPr();
//放大1000倍,计算绝对值
int j = (int) (c * 1000);
//double强转int丢失小数位精度,0.8 -> 0,当j=0迭代停止,所以倍数
j = Math.abs(j);
//把值放到累加器中,计算pr差值所有网页的和
context.getCounter(MyCounter.MY).setValue(j);
rkey.set(currPage.getPage() + ":" + newPr);
rval.set(currPage.arrToStr());
context.write(rkey, rval);
}
}
输出结果集
A:0.4091210396728514 B D
B:0.6997982913818357 C
C:0.7920743121337889 A B
D:0.2304549036865234 B C
完整代码及测试数据详见码云:hadoop-test传送门
四、通过Spark算子实现
/**
* 网站pr计算公式:pr = (1-d)/n + d*sum(tr)
* d:阻尼系数,为0.85
* n:网站总数,这里即是记录条数
* tr:网站得到其他网站的投票权值
*/
public class PageRankSpark {
/**
* 页面pr值差值范围,用于判断是否停止迭代
*/
private static final double LIMIT = 0.001;
/**
* 阻尼系数d
*/
private static final double D = 0.85;
/**
* 网页初始pr为1
*/
private static final double INIT_PR = 1;
public static void main(String[] args) {
SparkSession ss = SparkSession.builder().master("local")
.appName("page_rank")
.getOrCreate();
JavaSparkContext jsc = new JavaSparkContext(ss.sparkContext());
/*@step1 加载网页数据*/
JavaRDD<String> textRdd = jsc.textFile("file:/bigdata/hadoop-test/input/pagerank/page_data.txt");
textRdd.cache();
//网页对应pr值的map
Map<String, Double> pagePr = new HashMap<>();
/*@step2 设置网页的初始化pr值*/
textRdd.map(new Function<String, String>() {
private static final long serialVersionUID = 964971064235782420L;
@Override
public String call(String v1) throws Exception {
return v1.split(" ")[0];
}
}).collect().forEach(p -> pagePr.put(p, INIT_PR));
/*@step3 广播网页的初始化pr值map*/
Broadcast<Map<String, Double>> broadcast = jsc.broadcast(pagePr);
//迭代计算
while (true) {
/*@step4 计算各网页的tr值*/
JavaPairRDD<String, Double> pageGetTrRdd = textRdd.flatMapToPair(new PairFlatMapFunction<String, String, Double>() {
private static final long serialVersionUID = -3369519627121102880L;
@Override
public Iterator<Tuple2<String, Double>> call(String s) throws Exception {
List<Tuple2<String, Double>> ret = new ArrayList<>();
String[] pages = s.split(" ");
for (int i = 1; i < pages.length; i++) {
ret.add(new Tuple2<>(pages[i], broadcast.value().get(pages[0]) / (pages.length - 1)));
}
return ret.iterator();
}
}).reduceByKey(Double::sum);
List<Tuple2<String, Double>> collect = pageGetTrRdd.collect();
int jTotal = 0;
for (Tuple2<String, Double> t : collect) {
/*@step5 重新计算网页的pr值*/
double newPr = (1 - D) / pagePr.size() + D * t._2;
System.out.println(t._1 + " - " + newPr);
/*@step6 计算新旧pr值的差值*/
double c = newPr - pagePr.get(t._1);
int j = Math.abs((int) (c * 1000));
jTotal += j;
/*@step7 重新设置网页的pr值*/
pagePr.put(t._1, newPr);
}
System.out.println("pr差值总和:" + jTotal);
double avgd = jTotal / 4000.0;
if (avgd < LIMIT) {
/*@step8 如果符合设置的差值范围要求,退出迭代计算*/
break;
}
}
}
}

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)