
【半监督图像分类】 2017-Mean-Teacher NIPS
今天我们来学习半监督学习的第2篇文章Mean-TeacherMean-Teacher是对这篇论文Temporal Ensembling for Semi-Supervised Learning做的改进一致性判定正是描述了其中一个属性,那就是一个表现很好的模型应该对输入数据以及他的某些变形表现稳定。比如人看到了。那半监督学习也是一样,我们想要我们的模型表现良好,表现和上限通过大量有标签数据训练的一样
2017-Mean-Teacher NIPS
论文题目:Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
论文链接:https://arxiv.org/abs/1703.01780
论文代码:https://github.com/CuriousAI/mean-teacher
我的代码:https://github.com/fakerlove1/2017-NIPS-MeanTeacher-Cifar10
发表时间:2017年3月
引用:Tarvainen A, Valpola H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results[J]. Advances in neural information processing systems, 2017, 30.
引用数:2644
1. 简介
1.1 简介
今天我们来学习半监督学习的第2篇文章Mean-Teacher
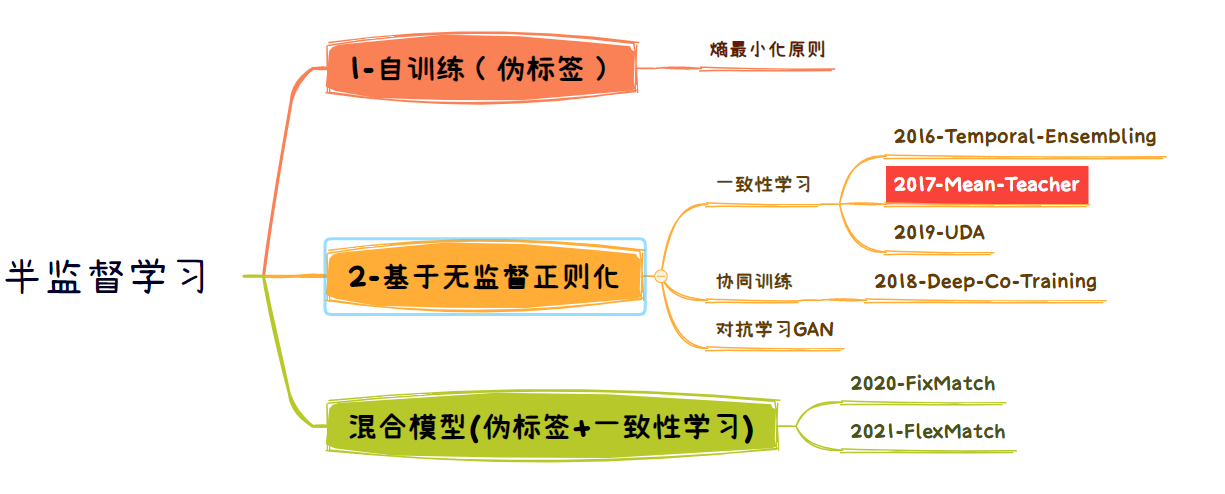
Mean-Teacher是对这篇论文Temporal Ensembling for Semi-Supervised Learning做的改进
1.2 前提准备
一致性判定正是描述了其中一个属性,那就是一个表现很好的模型应该对输入数据以及他的某些变形表现稳定。比如人看到了一匹马的照片,不管是卡通的,还是旋转的,人都能准确的识别出这是一匹马。那半监督学习也是一样,我们想要我们的模型表现良好,表现和上限通过大量有标签数据训练的一样(足够鲁棒),那么我们的模型也应该拥有这个属性,即对输入数据的某种变化鲁棒,此类方法代表方法为Teacher-student Model, CCT模型等等,对应的半监督学习假设就是平滑性假设。
2. 网络
2.1 模型整体架构
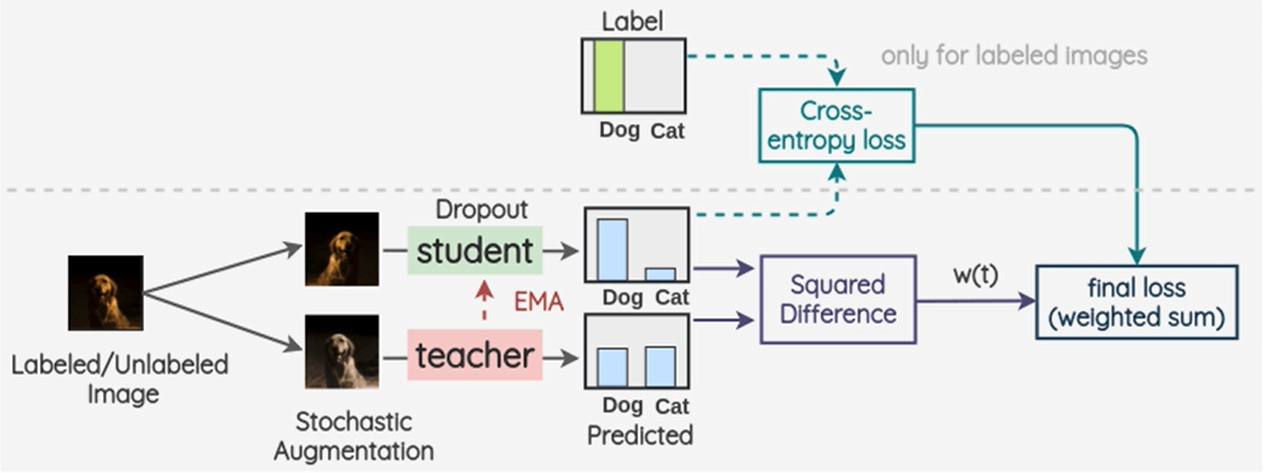
-
一个batch里面会同时
有标签图像和无标签图像。然后对一个batch 做两次数据增强。生成2组图片。 -
分别送入student 模型与Teacher模型。送入student模型里面的
有标签数据与真实标签做crossentropy-loss损失计算。 -
然后让Teacher模型出来的所有预测与 student模型出来的所有预测,做
mse-loss。为一致性损失 -
最终的损失
loss=crossentropy_loss+mse_loss。然后开始更新参数。student模型是正常更新。 -
但是Teacher模型是 使用EMA的方式。就是下面的公式
θ t ′ = α θ t − 1 ′ + ( 1 − α ) θ t \theta_{t}^{\prime}=\alpha \theta_{t-1}^{\prime}+(1-\alpha) \theta_{t} θt′=αθt−1′+(1−α)θt
啥意思呢???Teacher模型= α \alpha α%的Teacher模型参数+( 1 − α 1-\alpha 1−α)的student模型参数
2.2 思路
模型的核心思想:模型即充当学生,又充当老师。作为老师,用来产生学生学习时的目标,作为学生,利用老师模型产生的目标来学习。
为了克服Temporal Ensembling的局限性,我们建议平均模型权重而不是预测。教师模式是连续学生模式的平均值,因此我们叫它Mean teacher。与直接使用最终的权重相比,将模型权重平均到训练步骤会产生更准确的模型,在训练中可以利用这一点来构建更好的目标。教师模型使用学生模型的EMA权重,而不是与学生模型共享权重。同时,由于权值平均改善了所有层的输出,而不仅仅是顶层输出,目标模型有更好的中间表示。
3. 代码
一共3个文件
3.1 定义数据集
import numpy as np
from PIL import Image
import torchvision
import torch
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
class TransformTwice:
def __init__(self, transform):
self.transform = transform
def __call__(self, inp):
out1 = self.transform(inp)
out2 = self.transform(inp)
return out1, out2
cifar10_mean = (0.4914, 0.4822, 0.4465) # equals np.mean(train_set.train_data, axis=(0,1,2))/255
cifar10_std = (0.2471, 0.2435, 0.2616) # equals np.std(train_set.train_data, axis=(0,1,2))/255
def get_cifar10(root, n_labeled, batch_size=16, K=1,
transform_train=None, transform_test=None,
download=True, ):
"""
:param root: cifra保存的路径
:param n_labeled: 需要视频label的数量
:param transform_train: train的数据增强
:param transform_val: val的数据增强
:param download: 是否下载,默认是True
:return:
"""
if transform_train is None:
transform_train = TransformTwice(transforms.Compose([
transforms.RandomResizedCrop(32, scale=(0.75, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ColorJitter(0.1, 0.1, 0.1),
transforms.ToTensor(),
transforms.Normalize(cifar10_mean, cifar10_std),
]))
if transform_test is None:
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(cifar10_mean, cifar10_std),
])
# 加载原始数据集
base_dataset = torchvision.datasets.CIFAR10(root, train=True, download=download)
# 区分有标签数据与无标签数据。
train_labeled_idxs, train_unlabeled_idxs = train_split(base_dataset.targets, int(n_labeled / 10))
# 有标签数据集
train_labeled_dataset = CIFAR10_labeled(root, train_labeled_idxs, train=True, transform=transform_train)
# 无标签数据集
train_unlabeled_dataset = CIFAR10_unlabeled(root, train_unlabeled_idxs, train=True,
transform=transform_train)
# 验证集
# val_dataset = CIFAR10_labeled(root, val_idxs, train=True, transform=transform_val, download=True)
test_dataset = CIFAR10_labeled(root, train=False, transform=transform_test, download=True)
print(f"#Labeled: {len(train_labeled_idxs)} #Unlabeled: {len(train_unlabeled_idxs)} ")
train_labeled_dataloader = DataLoader(train_labeled_dataset, batch_size=batch_size, shuffle=True, drop_last=True,
num_workers=4)
train_unlabeled_dataloader = DataLoader(train_unlabeled_dataset, batch_size=batch_size * K, shuffle=True,
drop_last=True, num_workers=4)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
return train_labeled_dataloader, train_unlabeled_dataloader, test_dataloader
def train_split(labels, n_labeled_per_class):
"""
:param labels: 全部的标签数据
:param n_labeled_per_class: 每个标签的数目
:return: 有标签索引,无标签索引
"""
labels = np.array(labels)
train_labeled_idxs = []
train_unlabeled_idxs = []
for i in range(10):
idxs = np.where(labels == i)[0]
np.random.shuffle(idxs)
train_labeled_idxs.extend(idxs[:n_labeled_per_class])
train_unlabeled_idxs.extend(idxs[n_labeled_per_class:])
np.random.shuffle(train_labeled_idxs)
np.random.shuffle(train_unlabeled_idxs)
return train_labeled_idxs, train_unlabeled_idxs
def train_val_split(labels, n_labeled_per_class):
"""
:param labels: 全部标签数据
:param n_labeled_per_class: 每个标签的类
:return: 有标签数据索引,无标签索引,验证集索引
"""
labels = np.array(labels)
train_labeled_idxs = []
train_unlabeled_idxs = []
val_idxs = []
for i in range(10):
idxs = np.where(labels == i)[0]
np.random.shuffle(idxs)
train_labeled_idxs.extend(idxs[:n_labeled_per_class])
train_unlabeled_idxs.extend(idxs[n_labeled_per_class:-500])
val_idxs.extend(idxs[-500:])
np.random.shuffle(train_labeled_idxs)
np.random.shuffle(train_unlabeled_idxs)
np.random.shuffle(val_idxs)
return train_labeled_idxs, train_unlabeled_idxs, val_idxs
class CIFAR10_labeled(torchvision.datasets.CIFAR10):
def __init__(self, root, indexs=None, train=True,
transform=None, target_transform=None,
download=False):
super(CIFAR10_labeled, self).__init__(root, train=train,
transform=transform, target_transform=target_transform,
download=download)
if indexs is not None:
self.data = self.data[indexs]
self.targets = np.array(self.targets)[indexs]
# self.data = transpose(normalize(self.data))
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
img, target = self.data[index], self.targets[index]
img = Image.fromarray(img)
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
class CIFAR10_unlabeled(CIFAR10_labeled):
def __init__(self, root, indexs, train=True,
transform=None, target_transform=None,
download=False):
super(CIFAR10_unlabeled, self).__init__(root, indexs, train=train,
transform=transform, target_transform=target_transform,
download=download)
self.targets = np.array([-1 for i in range(len(self.targets))])
if __name__ == '__main__':
train_labeled_dataloader, train_unlabeled_dataloader, test_dataloader = get_cifar10("./data", 4000, batch_size=4)
# label_iter = iter(train_labeled_dataloader)
# unlabel_iter = iter(train_unlabeled_dataloader)
# (img1, img2), target_label = next(label_iter)
# (img1_ul, img2_ul), target_no_label = next(unlabel_iter)
#
# input1 = torch.cat([img1, img1_ul])
# input2 = torch.cat([img2, img2_ul])
#
# torchvision.utils.save_image(input1, "1.jpg")
# torchvision.utils.save_image(input2, "2.jpg")
3.2 定义网络
import logging
import torch
import torch.nn as nn
import torch.nn.functional as F
logger = logging.getLogger(__name__)
def mish(x):
"""Mish: A Self Regularized Non-Monotonic Neural Activation Function (https://arxiv.org/abs/1908.08681)"""
return x * torch.tanh(F.softplus(x))
class PSBatchNorm2d(nn.BatchNorm2d):
"""How Does BN Increase Collapsed Neural Network Filters? (https://arxiv.org/abs/2001.11216)"""
def __init__(self, num_features, alpha=0.1, eps=1e-05, momentum=0.001, affine=True, track_running_stats=True):
super().__init__(num_features, eps, momentum, affine, track_running_stats)
self.alpha = alpha
def forward(self, x):
return super().forward(x) + self.alpha
class BasicBlock(nn.Module):
def __init__(self, in_planes, out_planes, stride, drop_rate=0.0, activate_before_residual=False):
super(BasicBlock, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes, momentum=0.001)
self.relu1 = nn.LeakyReLU(negative_slope=0.1, inplace=True)
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes, momentum=0.001)
self.relu2 = nn.LeakyReLU(negative_slope=0.1, inplace=True)
self.conv2 = nn.Conv2d(out_planes, out_planes, kernel_size=3, stride=1,
padding=1, bias=False)
self.drop_rate = drop_rate
self.equalInOut = (in_planes == out_planes)
self.convShortcut = (not self.equalInOut) and nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride,
padding=0, bias=False) or None
self.activate_before_residual = activate_before_residual
def forward(self, x):
if not self.equalInOut and self.activate_before_residual == True:
x = self.relu1(self.bn1(x))
else:
out = self.relu1(self.bn1(x))
out = self.relu2(self.bn2(self.conv1(out if self.equalInOut else x)))
if self.drop_rate > 0:
out = F.dropout(out, p=self.drop_rate, training=self.training)
out = self.conv2(out)
return torch.add(x if self.equalInOut else self.convShortcut(x), out)
class NetworkBlock(nn.Module):
def __init__(self, nb_layers, in_planes, out_planes, block, stride, drop_rate=0.0, activate_before_residual=False):
super(NetworkBlock, self).__init__()
self.layer = self._make_layer(
block, in_planes, out_planes, nb_layers, stride, drop_rate, activate_before_residual)
def _make_layer(self, block, in_planes, out_planes, nb_layers, stride, drop_rate, activate_before_residual):
layers = []
for i in range(int(nb_layers)):
layers.append(block(i == 0 and in_planes or out_planes, out_planes,
i == 0 and stride or 1, drop_rate, activate_before_residual))
return nn.Sequential(*layers)
def forward(self, x):
return self.layer(x)
class WideResNet(nn.Module):
def __init__(self, num_classes, depth=28, widen_factor=2, drop_rate=0.0):
super(WideResNet, self).__init__()
channels = [16, 16 * widen_factor, 32 * widen_factor, 64 * widen_factor]
assert ((depth - 4) % 6 == 0)
n = (depth - 4) / 6
block = BasicBlock
# 1st conv before any network block
self.conv1 = nn.Conv2d(3, channels[0], kernel_size=3, stride=1,
padding=1, bias=False)
# 1st block
self.block1 = NetworkBlock(
n, channels[0], channels[1], block, 1, drop_rate, activate_before_residual=True)
# 2nd block
self.block2 = NetworkBlock(
n, channels[1], channels[2], block, 2, drop_rate)
# 3rd block
self.block3 = NetworkBlock(
n, channels[2], channels[3], block, 2, drop_rate)
# global average pooling and classifier
self.bn1 = nn.BatchNorm2d(channels[3], momentum=0.001)
self.relu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
self.fc = nn.Linear(channels[3], num_classes)
self.channels = channels[3]
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight,
mode='fan_out',
nonlinearity='leaky_relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1.0)
nn.init.constant_(m.bias, 0.0)
elif isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
nn.init.constant_(m.bias, 0.0)
def forward(self, x):
out = self.conv1(x)
out = self.block1(out)
out = self.block2(out)
out = self.block3(out)
out = self.relu(self.bn1(out))
out = F.adaptive_avg_pool2d(out, 1)
out = out.view(-1, self.channels)
return self.fc(out)
def build_wideresnet(depth, widen_factor, dropout, num_classes):
logger.info(f"Model: WideResNet {depth}x{widen_factor}")
return WideResNet(depth=depth,
widen_factor=widen_factor,
drop_rate=dropout,
num_classes=num_classes)
if __name__ == '__main__':
x = torch.randn(1, 3, 32, 32)
model = build_wideresnet(depth=28, widen_factor=2, dropout=0.1, num_classes=10)
y = model(x)
print(y.shape)
3.3 utils 工具包
import os
import logging
import sys
from logging import handlers
from torch.optim.lr_scheduler import _LRScheduler, StepLR
import numpy as np
import torch
def mkpath(path):
if not os.path.exists(path):
os.makedirs(path)
# 日志级别关系映射
level_relations = {
'debug': logging.DEBUG,
'info': logging.INFO,
'warning': logging.WARNING,
'error': logging.ERROR,
'crit': logging.CRITICAL
}
def _get_logger(filename, level='info'):
# 创建日志对象
log = logging.getLogger(filename)
# 设置日志级别
log.setLevel(level_relations.get(level))
# 日志输出格式
fmt = logging.Formatter('%(asctime)s %(thread)d %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
# 输出到控制台
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(fmt)
# 输出到文件
# 日志文件按天进行保存,每天一个日志文件
file_handler = handlers.TimedRotatingFileHandler(filename=filename, when='D', backupCount=1, encoding='utf-8')
# 按照大小自动分割日志文件,一旦达到指定的大小重新生成文件
# file_handler = handlers.RotatingFileHandler(filename=filename, maxBytes=1*1024*1024*1024, backupCount=1, encoding='utf-8')
file_handler.setFormatter(fmt)
log.addHandler(console_handler)
log.addHandler(file_handler)
return log
class PolyLR(_LRScheduler):
def __init__(self, optimizer, max_iters, power=0.9, last_epoch=-1, min_lr=1e-6):
self.power = power
self.max_iters = max_iters # avoid zero lr
self.min_lr = min_lr
super(PolyLR, self).__init__(optimizer, last_epoch)
def get_lr(self):
return [max(base_lr * (1 - self.last_epoch / self.max_iters) ** self.power, self.min_lr)
for base_lr in self.base_lrs]
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3):
assert num_step > 0 and epochs > 0
if warmup is False:
warmup_epochs = 0
def f(x):
"""
根据step数返回一个学习率倍率因子,
注意在训练开始之前,pytorch会提前调用一次lr_scheduler.step()方法
"""
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
# warmup过程中lr倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
else:
# warmup后lr倍率因子从1 -> 0
# 参考deeplab_v2: Learning rate policy
return (1 - (x - warmup_epochs * num_step) / ((epochs - warmup_epochs) * num_step)) ** 0.9
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)
class Cosine_LR_Scheduler(object):
def __init__(self, optimizer, warmup_epochs=10, warmup_lr=1e-6,
num_epochs=100, base_lr=0.01, final_lr=1e-6, iter_per_epoch=1000):
"""
学习率设置
:param optimizer: 优化器
:param warmup_epochs: 热身epoch,
:param warmup_lr: 热身学习率
:param num_epochs: 一共的epoch
:param base_lr: 基础学习率
:param final_lr: 最后学习率
:param iter_per_epoch: 每个epoch的iter
"""
self.base_lr = base_lr
warmup_iter = iter_per_epoch * warmup_epochs
warmup_lr_schedule = np.linspace(warmup_lr, base_lr, warmup_iter)
decay_iter = iter_per_epoch * (num_epochs - warmup_epochs)
cosine_lr_schedule = final_lr + 0.5 * (base_lr - final_lr) * (
1 + np.cos(np.pi * np.arange(decay_iter) / decay_iter))
self.lr_schedule = np.concatenate((warmup_lr_schedule, cosine_lr_schedule))
self.optimizer = optimizer
self.iter = 0
self.current_lr = 0
def step(self):
for param_group in self.optimizer.param_groups:
lr = param_group['lr'] = self.lr_schedule[self.iter]
self.iter += 1
self.current_lr = lr
return lr
def get_lr(self):
return self.current_lr
3.4 训练
from __future__ import print_function
import argparse
import math
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from easydict import EasyDict
from tensorboardX import SummaryWriter
from torch.autograd import Variable
from timm.optim import create_optimizer_v2, optimizer_kwargs
from timm.scheduler import create_scheduler
from cifar10 import get_cifar10
from wideresnet import build_wideresnet
from utils import _get_logger, Cosine_LR_Scheduler
from copy import deepcopy
from tqdm import tqdm
def update_ema_variables(model, model_teacher, alpha):
# Use the true average until the exponential average is more correct
# alpha = min(1.0 - 1.0 / float(global_step + 1), alpha)
for param_t, param in zip(model_teacher.parameters(), model.parameters()):
param_t.data.mul_(alpha).add_(param.data, alpha=1 - alpha)
return model, model_teacher
def consistency_loss(logits_w1, logits_w2):
logits_w2 = logits_w2.detach()
assert logits_w1.size() == logits_w2.size()
return F.mse_loss(torch.softmax(logits_w1, dim=-1), torch.softmax(logits_w2, dim=-1), reduction='mean')
def train(model, ema_model, label_loader, unlabel_loader, test_loader, args):
model.train()
ema_model.train()
label_iter = iter(label_loader)
cur_itrs = 0
ce_loss = nn.CrossEntropyLoss(ignore_index=-1)
acc = 0.0
ema_acc = 0.0
optimizer = torch.optim.SGD(model.parameters(), lr=args.lr, momentum=0.9,
weight_decay=args.weight_decay)
lr_scheduler = Cosine_LR_Scheduler(optimizer, warmup_epochs=10, num_epochs=args.epochs, base_lr=args.lr,
iter_per_epoch=args.step_size)
while True:
for idx, ((img1_ul, img2_ul), target_no_label) in enumerate(tqdm(unlabel_loader)):
cur_itrs += 1
try:
(img1, img2), target_label = next(label_iter)
except StopIteration:
label_iter = iter(label_loader)
(img1, img2), target_label, = next(label_iter)
batch_size_labeled = img1.shape[0]
input1 = Variable(torch.cat([img1, img1_ul]).to(args.device))
input2 = Variable(torch.cat([img2, img2_ul]).to(args.device))
target = Variable(target_label.to(args.device))
optimizer.zero_grad()
output = model(input1)
# forward pass with mean teacher
# torch.no_grad() prevents gradients from being passed into mean teacher model
with torch.no_grad():
ema_output = ema_model(input2)
unsup_loss = consistency_loss(output, ema_output)
out_x = output[:batch_size_labeled]
sup_loss = ce_loss(out_x, target)
warm_up = float(np.clip((cur_itrs) / (args.unsup_warm_up * args.total_itrs), 0., 1.))
loss = sup_loss + warm_up * args.lambda_u * unsup_loss # 损失为 有标签的交叉熵损失+ 一致性损失(基于平滑性假设,一个模型对于 一个输入及其变形应该保持一致性)
loss.backward()
optimizer.step()
lr_scheduler.step()
lr = optimizer.param_groups[0]["lr"]
args.writer.add_scalar('train/loss', loss.item(), cur_itrs)
args.writer.add_scalar('train/lr', lr, cur_itrs)
args.writer.add_scalar('train/warm_up', warm_up, cur_itrs)
model, ema_model = update_ema_variables(model, ema_model, args.ema_m) # 更新模型
if cur_itrs % args.step_size == 0:
args.logger.info(
"Train cur_itrs: [{}/{} ({:.0f}%)]\t loss:{:.6f}\t warm_up:{:.6f}".format(
cur_itrs,
args.total_itrs,
100. * cur_itrs / args.total_itrs,
loss.item(),
warm_up,
))
tmp_acc = test(model, test_loader=test_loader, args=args, )
args.writer.add_scalar('acc', tmp_acc, cur_itrs)
if tmp_acc > acc:
acc = tmp_acc
# 保存模型
torch.save({
"cur_itrs": cur_itrs,
"model": model,
"ema_model": ema_model,
"optimizer": optimizer,
"best_acc": acc
}, args.model_save_path)
tmp_acc = test(ema_model, test_loader=test_loader, args=args)
args.writer.add_scalar('ema_acc', tmp_acc, cur_itrs)
if tmp_acc > ema_acc:
ema_acc = tmp_acc
if cur_itrs > args.total_itrs:
return
def test(model, test_loader, args):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(args.device), target.to(args.device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
acc = 100. * correct / len(test_loader.dataset)
args.logger.info('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)'.format(
test_loss, correct, len(test_loader.dataset),
acc))
model.train()
return acc
def main():
args = EasyDict()
args.total_itrs = 2 ** 20
args.step_size = 5000 # 每 step_size 步骤 保存一次数据
args.epochs = args.total_itrs // args.step_size + 1
args.label = 4000 # 使用有标签的数量
args.lambda_u = 50
args.unsup_warm_up = 0.4
args.ema_m = 0.999
args.datasets = "cifar10"
args.num_classes = 10
args.seed = 0 # 随机种子
args.batch_size = 64 # 有标签的batchsize
args.K = 3 # 无标签的batchsize是 有标签的K 倍
args.device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
args.lr = 0.03
args.opt = "sgd"
args.weight_decay = 0.0005
args.momentum = 0.9
args.datapath = "./data"
args.save_path = "checkpoint/12-19-mean-teacher"
root = os.path.dirname(os.path.realpath(__file__))
args.save_path = os.path.join(root, args.save_path)
args.model_save_path = os.path.join(args.save_path, "mean_teacher_model.pth")
args.writer = SummaryWriter(args.save_path)
args.logger = _get_logger(os.path.join(args.save_path, "log.log"), "info")
model = build_wideresnet(widen_factor=3, depth=28, dropout=0.1, num_classes=args.num_classes).to(args.device)
ema_model = deepcopy(model)
# model=nn.DataParallel()
# 设置ema_model不计算梯度
for name, param in ema_model.named_parameters():
param.requires_grad = False
# 设置随机种子。
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
np.random.seed(args.seed)
# 50000个样本,只使用4000label
# mean-teacher
# 4000label acc=90%
# 2000label acc=87%
# 1000label acc=83%
# 500 label acc=58%
# 250 label acc=52%
label_loader, unlabel_loader, test_loader = get_cifar10(root=args.datapath, n_labeled=args.label,
batch_size=args.batch_size, K=args.K)
args.logger.info("label_loader length: {}".format(len(label_loader) * args.batch_size))
args.logger.info("unlabel_loader length: {}".format(len(unlabel_loader) * args.batch_size * args.K))
args.logger.info("test_loader length: {}".format(len(test_loader)))
args.logger.info("length: {}".format(args.total_itrs // len(unlabel_loader)))
train(model=model, ema_model=ema_model,
label_loader=label_loader, unlabel_loader=unlabel_loader, test_loader=test_loader, args=args)
# mean_teacher = build_wideresnet(widen_factor=3, depth=28, dropout=0.1, num_classes=10).to(device)
# optimizer = create_optimizer_v2(model, **optimizer_kwargs(cfg=arg))
# lr_scheduler, num_epochs = create_scheduler(arg, optimizer)
# for epoch in range(num_epochs):
# train(model, mean_teacher, device, label_loader, unlabel_loader, lr_scheduler, optimizer, epoch, num_epochs,
# logger)
# test(model, device, test_loader, logger)
# test(mean_teacher, device, test_loader, logger)
# # 保存模型
# torch.save(model, "mean_teacher_cifar10.pt")
if __name__ == '__main__':
main()
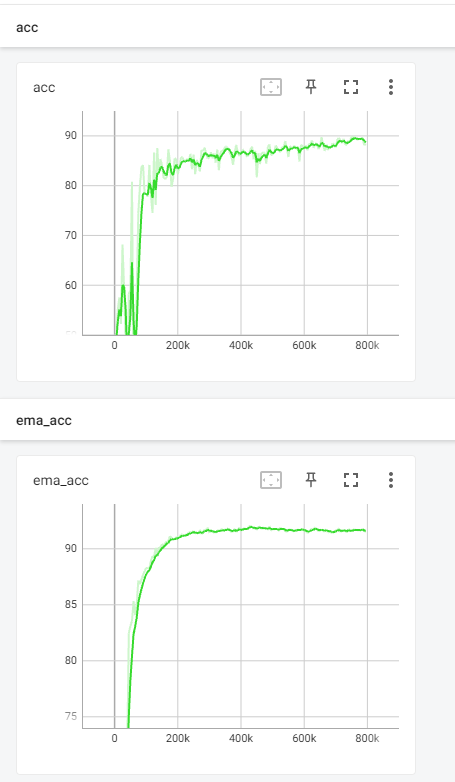
3.5 结果
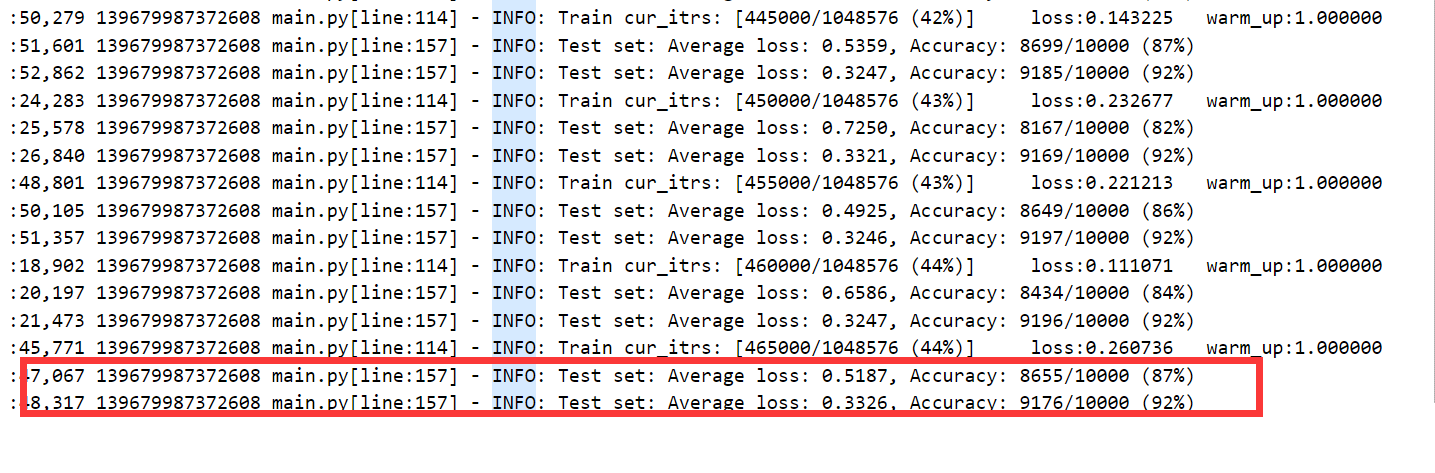
查看tensorbordX结果如下。符合论文结果
参考资料

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 3
3 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)