
大数据之旅——hadoop篇之MapReduce(3)
hadoop之MapReduce
·
大数据之旅——hadoop篇之MapReduce(3)
6. 并行度机制
6.1 MapTask的并行度
MapTask的并行度指的是map阶段有多少个并行的task共同处理任务,它影响到整个job的处理速度。
MapTask并行度的决定机制叫做逻辑规划。
客户端提交job之前会对待处理数据进行逻辑切片,形成逻辑规划文件,每个逻辑切片最终对应启动一个maptask。
逻辑规划机制由FileInputFormat类的getSplits方法完成。
逻辑规划结果写入规划文件(job.split),在客户端提交Job之前,把规划文件提交到任务准备区,供后续使用。

6.2 ReduceTask并行度机制
Reducetask并行度同样影响整个job的执行并发度和执行效率,与maptask的并发数由切片数决定不同,Reducetask数量的决定是可以直接手动设置。 job.setNumReduceTasks(N);
注意Reducetask数量并不是任意设置,还要考虑业务逻辑需求,如果数据分布不均匀,有可能在reduce阶段产生数据倾斜。
7. 核心工作机制
7.1 MapTask工作机制详解
7.1.1 流程图
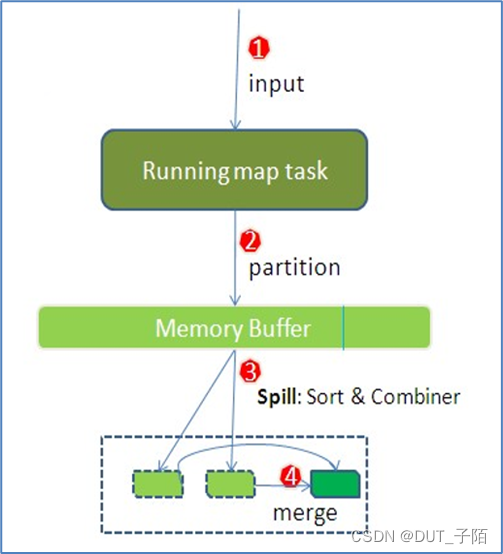
- 输入文件被逻辑切分为多个split文件,通过LineRecordReader按行读取内容给map(用户自己实现的)进行处理;
- 数据被map处理结束之后交给OutputCollector收集器,对其结果key进行分区(HashPartitioner),然后写入内存缓冲区,当缓冲区快满的时候(80%)需要将缓冲区的数据以一个临时文件的方式spill溢出到磁盘;
- 最后再对磁盘上产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。

7.1.2 步骤详述
步骤一:

步骤二:

步骤三:

步骤四:

7.2 ReduceTask工作机制详解
7.2.1 流程图
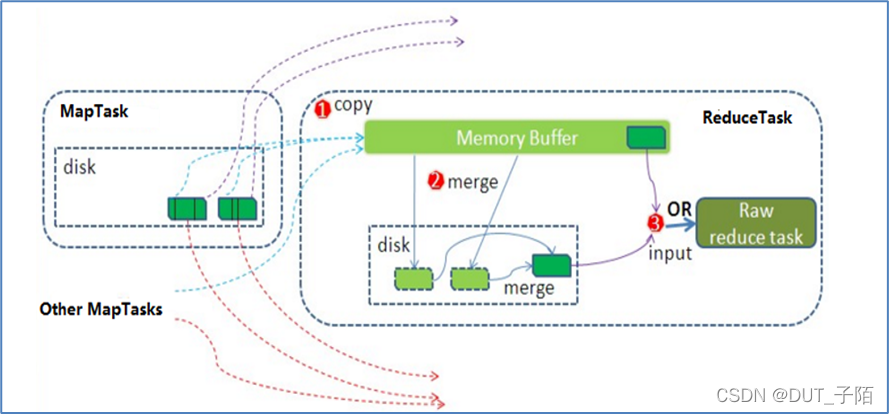
- Reduce大致分为copy、sort、reduce三个阶段,重点在前两个阶段。
- copy阶段包含一个eventFetcher来获取已完成的map列表,由Fetcher线程去copy数据,在此过程中会启动两个merge线程,分别为inMemoryMerger和onDiskMerger,分别将内存中的数据merge到磁盘和将磁盘中的数据进行merge。
- 待数据copy完成之后,开始进行sort阶段,sort阶段主要是执行finalMerge操作,纯粹的sort阶段。
- 完成之后就是reduce阶段,调用用户定义的reduce函数进行处理。
7.2.2 步骤详述
步骤一:

步骤二:

步骤三:

7.3 MapReduce Shuffle机制
Shuffle概念
| 在MapReduce中,Shuffle是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。 |
| shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。 |
| 一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。 |
Map端Shuffle

Reducer端shuffle

MapReduce Shuffle的局限性(被诟病的地方)

7.4 MapTask切片机制


由于文件在HDFS上进行存储的时候,物理上会进行分块存储,可能会导致文件内容的完整性被破坏。为了避免这个问题,在实际读取split数据的时候,每个maptask会进行读取行为的调整。
- 每个maptask都多处理下一个split的第一行数据;
- 除了第一个,每个maptask都舍去自己的第一行数据不处理。
7.5 环形缓冲区(Circular buffer)


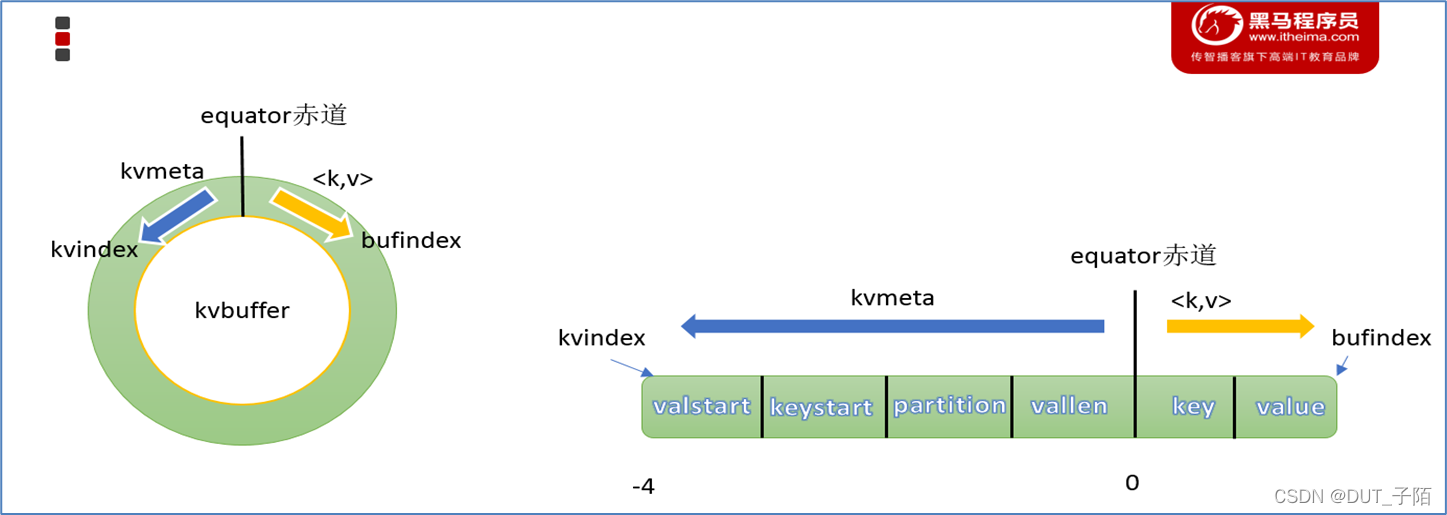

7.6 Map阶段的一些重点过程
溢写(Spill)

排序(Sort)

合并(Merge)

规约( Combiner)

7.7 Reducer阶段的一些重点过程
Copy线程(拉取数据)

合并(Merge)

排序(Sort)


技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)