
SSD目标检测 python KERAS——银行卡号识别(上)
SSD目标检测 python KERAS——银行卡号识别(上)
·
1.1首先创建自己的数据集
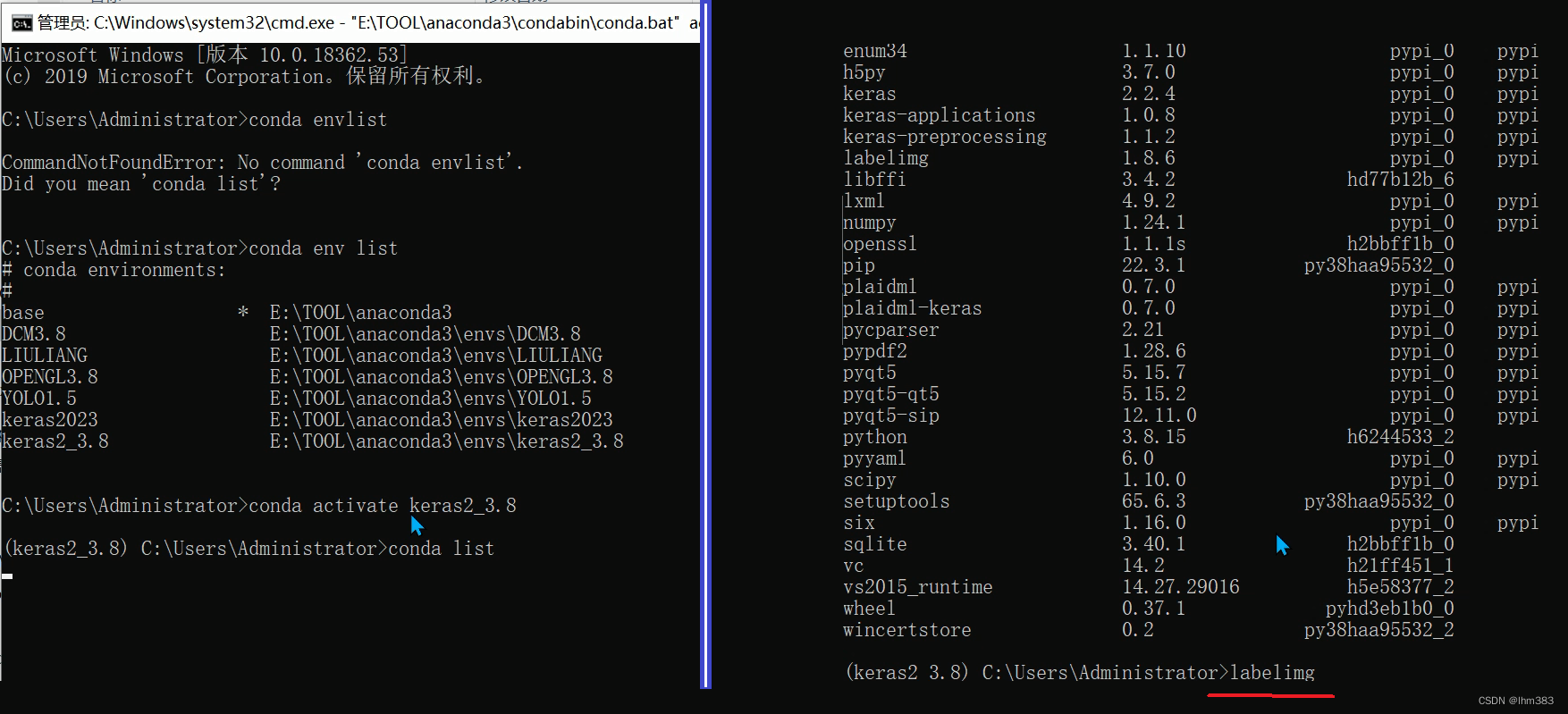
conda activate SSD_TEST001
pip install labelimg
labelimg输入labelimg后等待几分钟就会出来操作界面
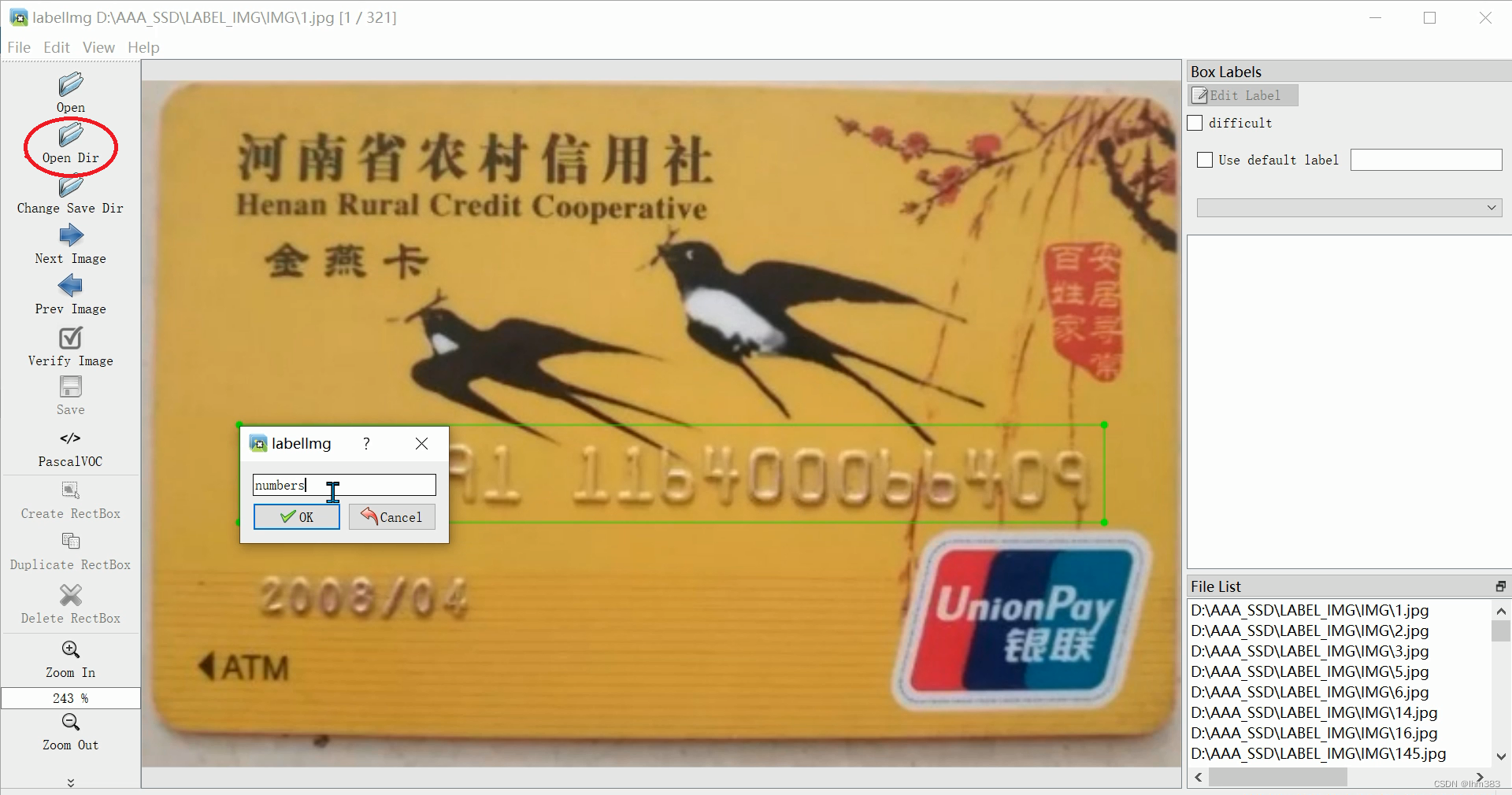
用anconda的labelimage制作数据集,会自动生成相关文件夹
Annotations文件夹放XML标签
ImageSets文件夹放训练集,验证集等的txt
JPEGImages文件夹放图片
1.2然后把图集和标签集放到datasets目录下
比如自己的总目录是BANKCARD,把BANKCARD放在datasets目录下
2调试代码
首先进入目录src\utils\data_management打开data_utils.py
第九行改成自己的类
import glob
import os
import cv2
import numpy as np
from tqdm import tqdm
def get_class_names(dataset_name='BANKCARD'):
class_names = ['background','numbers']
# if (set(dataset_name).issubset(['VOC2007', 'VOC2012'])
# or dataset_name == 'VOC2007' or dataset_name == 'VOC2012'):
# class_names = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',
# 'bottle', 'bus', 'car', 'cat', 'chair', 'cow',
# 'diningtable', 'dog', 'horse', 'motorbike', 'person',
# 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
#
# elif dataset_name == 'BANKCARD':
# class_names = ['numbers']
# else:
# raise Exception('Invalid dataset', dataset_name)
return class_names
然后找到src\trian.py运行就开始训练了,其中num_epochs = 1250表示训练多少次
import os
from keras.callbacks import CSVLogger, ModelCheckpoint, LearningRateScheduler
from keras.optimizers import SGD
from models import SSD300
from utils.boxes import create_prior_boxes, to_point_form
from utils.data_management import DataManager, get_class_names
from utils.data_generator import DataGenerator
from utils.training import MultiboxLoss, scheduler
model_name = 'SSD300_BANKCARD'
# hyper-parameters
batch_size = 8
num_epochs = 1250
alpha_loss = 1.0
learning_rate = 1e-3
momentum = .9
weight_decay = 5e-4
gamma_decay = 0.1
# scheduled_epochs = [155, 195, 235]
negative_positive_ratio = 3然后在trian.py的上一级目录trained_models文件夹的子文件夹SSD300_BANKCARD文件夹
会生成训练好的model。不是每训练一轮就保存model,而是model比上一轮精度高才会保存。每个model大概90M大小,所以训练好后把一开始那些低精度的model删除即可。
model_name = 'SSD300_BANKCARD'
model_path = '../trained_models/' + model_name + '/'
save_path = model_path + 'weights.{epoch:02d}-{val_loss:.2f}.hdf5'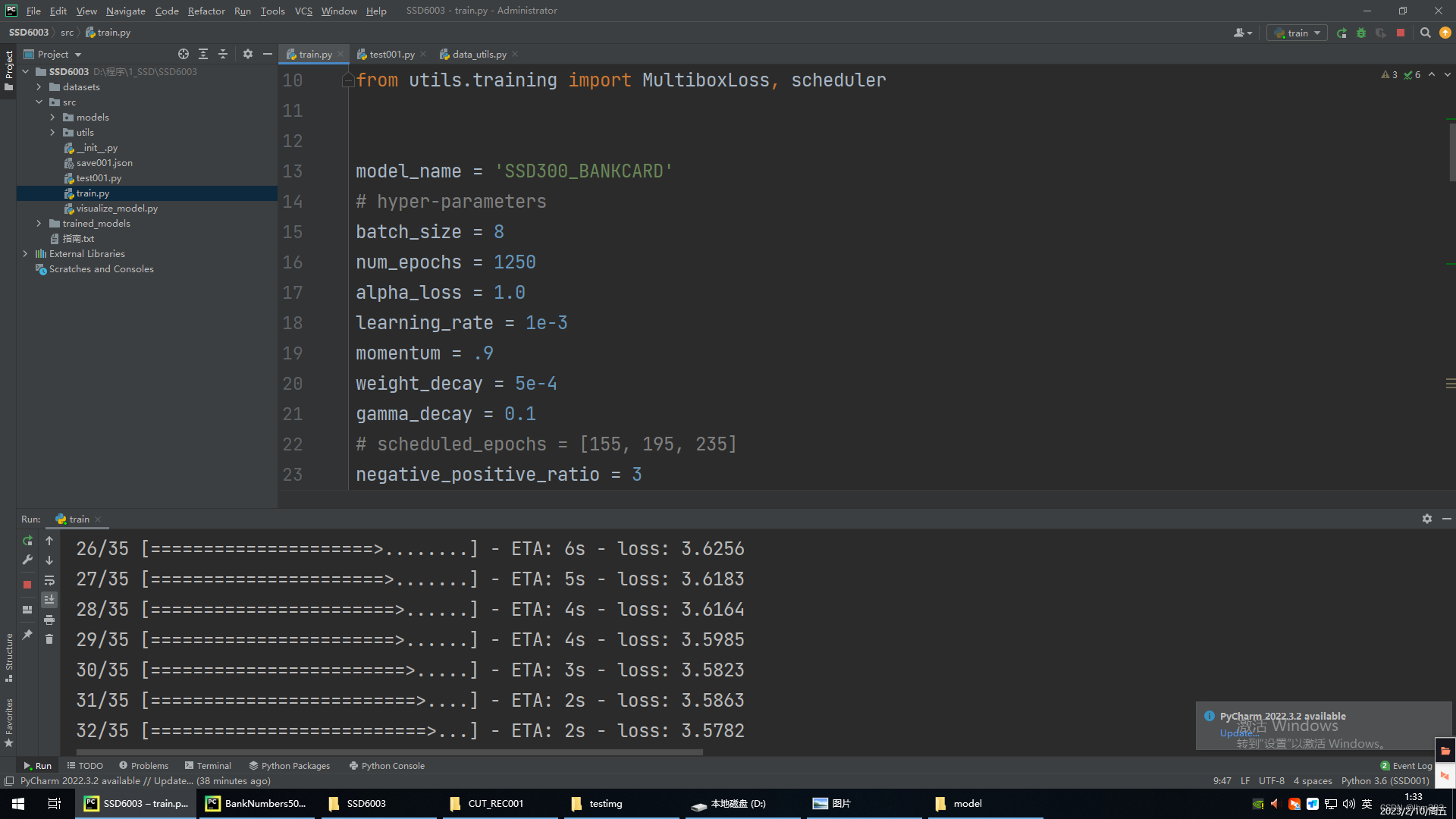 =====================================================================
=====================================================================
2识别
训练经过大概1天半的时间,识别率已经百分之90+了,加载model
weights_path = '../trained_models/SSD300_BANKCARD/weights.1250-0.09.hdf5'打开src/test001.py
把自己的图,放到路径下就可以识别了,fname是原图,rname是结果图
model = SSD300(weights_path=weights_path)
for jki in range(1,11):
# try:
# fname='l'
fname='D:/testimg/A ('+str(jki)+').jpg'
# fname='D:/project2023/bank003/datasets/BANKCARD/JPEGImages/'+str(jki)+'.jpg'
rename= 'D:/testimg/HB ('+str(jki)+').jpg'
print(jki)
frame = cv2.imread(fname)
# cv2.imshow('org',frame)
# cv2.waitKey(0)
image_array = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image_array = cv2.resize(image_array, (300, 300))
image_array = substract_mean(image_array)
image_array = np.expand_dims(image_array, 0)
predictions = model.predict(image_array)
detections = detect(predictions, prior_boxes)
print(detections)
plot_detections(detections, frame, 0.6,
arg_to_class, colors)
cv2.imshow(str(jki), frame)
cv2.imwrite(rename,frame)
print(jki)
# except:
# pass
cv2.waitKey()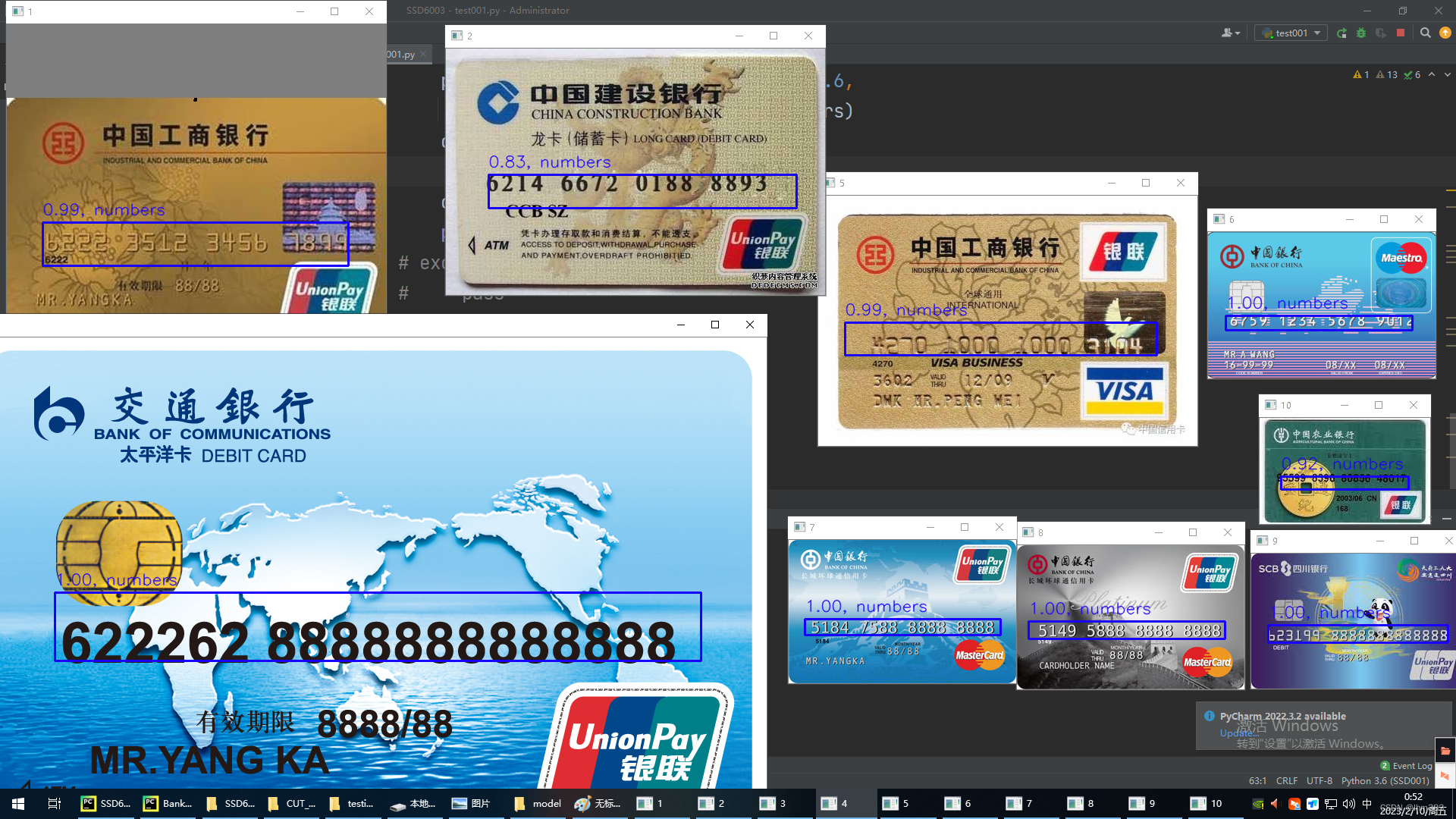

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)