
目标检测系列7——目标追踪
这里写目录标题一级目录一级目录
1 目标追踪
视觉目标(单目标)跟踪任务就是在给定某视频序列初始帧的目标大小与位置的情况下,预测后续帧中该目标的大小与位置。
输入初始化目标框,在下一帧中产生众多候选框(Motion Model),提取这些候选框的特征(Feature Extractor),然后对这些候选框评分(Observation Model),最后在这些评分中找一个得分最高的候选框作为预测的目标(Prediction A),或者对多个预测值进行融合(Ensemble)得到更优的预测目标。
本质上就是使用两张连续帧的图像,其中一个作为基准,另一个作为目标区域,前者提供一个目标模板,在目标区域中进行相似性匹配,匹配到相似度最大的区域,寻找两张图象的相似位置。将第二张图像的目标进行画框。
单纯的检测(无追踪)https://video.zhihu.com/video/1125741340193050624?autoplay=false&useMSE=
含目标追踪的结果
https://video.zhihu.com/video/1125741502307233792?autoplay=false&useMSE=
可以看到,加入追踪后的检测框极其稳定,输出结果更平滑,几乎不存在抖动,同时还给出了不同物体的label,和同一类型物体的不同的id信息,既对不同物体做了区分,又对同一类型物体做了区分,即实现了多目标追踪
1.1 研究内容
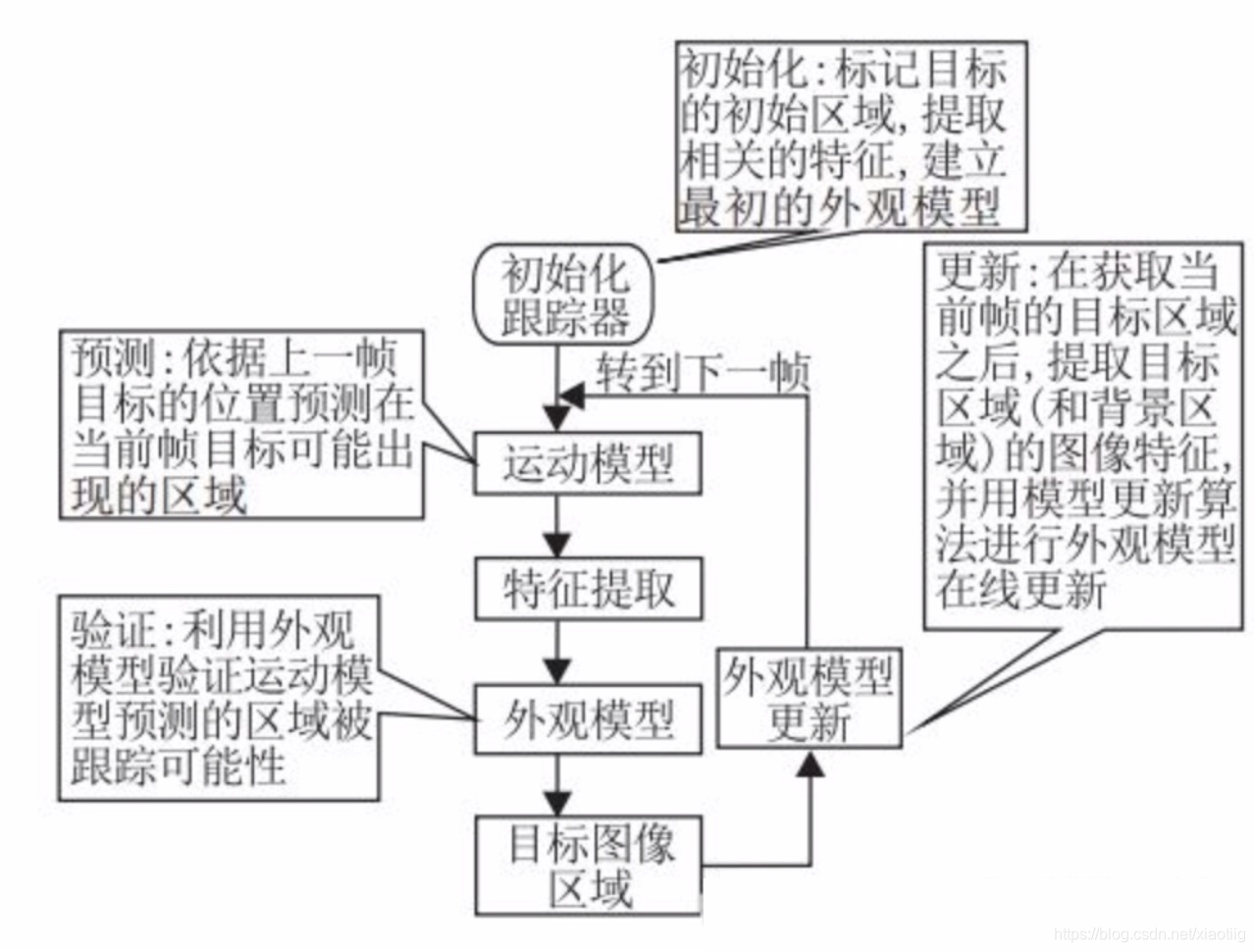
1.2 算法分类

目标跟踪最近几年发展迅速,以基于相关滤波(Correlation Filter)和卷积神经网络(CNN)的跟踪方法已经占据了目标跟踪的大半江山。如下图给出的2014-2017年以来表现排名靠前的一些跟踪方法。可以看到前三名的方法不是基于相关滤波的方法就是基于卷积神经网络的方法,或是两者结合的方法。视觉目标跟踪方法根据观测模型是生成式模型或判别式模型可以被分为生成式方法(Generative Method)和判别式方法(Discriminative Method)。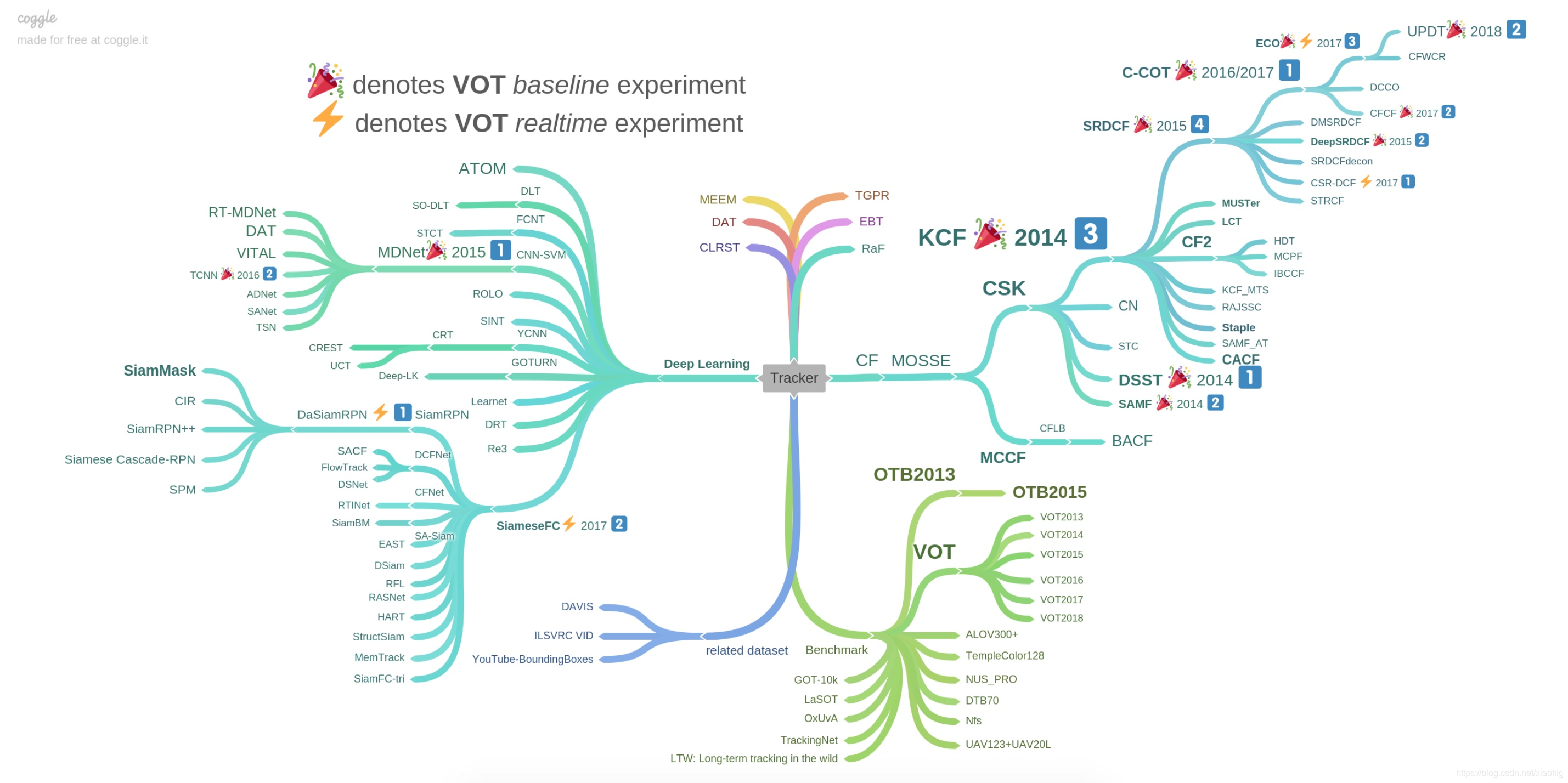

1.3 挑战

除了上述几个常见的挑战外,还有一些其他的挑战性因素:多尺度,光照(illumination),低分辨率(Low Resolution),运动模糊(Motion Blur),快速运动(Fast Motion),超出视野(Out of View),旋转(Rotation)等。所有的这些挑战因数共同决定了目标跟踪是一项极为复杂的任务。
2数据集

3 评价指标
对于多目标跟踪,最主要的评价指标就是MOTA。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)