
Spark Sql(DataFrame 创建与保存、Mysql 数据库的读取与写入、Hive 数据仓库的读取与写入)
1. maybe a semicolon is missing before `value toDF'?2. DataFrame 创建与保存3. Mysql 数据库的读取与写入4. Hive 数据仓库的读取与写入
·
一、DataFrame 创建与保存
package sql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
case class Person(name: String, age: Long)
object CreateAndSaveDataFrame {
def main(args: Array[String]): Unit ={
val spark = SparkSession.builder().getOrCreate() // SparkSession 对象
import spark.implicits._ // 使支持 RDDs 转换为DataFrames及后续sql操作
// ### 创建 DataFrame ###
// 1、读取 json 数据创建 DataFrame
println("---------------------")
val dfA = spark.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
dfA.show()
dfA.printSchema()
dfA.select(dfA("name")).show() // 选择列
dfA.filter(dfA("age") > 20).show() // 条件过滤
dfA.groupBy("age").count().show() // 分组聚合
dfA.sort(dfA("age").desc).show() // 排序
dfA.sort(dfA("age").desc, dfA("name").asc) // 多列排序
dfA.select(dfA("name").as("username"), dfA("age")).show()
// 2、RDD 转换创建 DataFrame
println("-------------------")
// 2.1 利用反射机制推断 RDD schema 从而创建 df
// case class Person(name: String, age: Long) =====> error possible cause: maybe a semicolon is missing before `value toDF'?:because "spark.implicits._"
val dfB = spark.sparkContext.textFile(
"file:///usr/local/spark/examples/src/main/resources/people.txt"
).map(_.split(",")).map(
attributes => Person(attributes(0), attributes(1).trim.toInt)
).toDF() // if have not "spark.implicits._", "toDF()" and "createOrReplaceTempView()" will can't be use
dfB.createOrReplaceTempView("people") // 注册为临时表
val dfC = spark.sql("select name,age from people where age > 20")
dfC.map(r => "Name:"+r(0)+","+"Age:"+r(1)).show()
// 2.2 构造 schema 并应用在 RDD 从而创建 df
val schema_str = "name age"
val fields = schema_str.split(" ").map(
field => StructField(field, StringType, nullable = true)
)
val schema = StructType(fields)
val rdd = spark.sparkContext.textFile(
"file:///usr/local/spark/examples/src/main/resources/people.txt"
).map(_.split(",")).map(
attributes => Row(attributes(0),attributes(1).trim)
) // org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] // Row对象只是对基本数据类型(比如整型或字符串)的数组的封装
val dfD = spark.createDataFrame(rdd, schema)
dfD.createOrReplaceTempView("people")
val dfD_ = spark.sql("select name,age from people")
dfD_.show()
// 3. 读取 parquet 文件创建 DataFrame
val dfE = spark.read.parquet("file:///usr/local/spark/examples/src/main/resources/users.parquet")
// ### 保存 DataFrame ###
// Method 1
dfA.select("name", "age").write.format("csv").save(
"file:///usr/local/spark/mycode/newpeople.csv"
) // write.format()支持输出 json,parquet, jdbc, orc, libsvm, csv, text(仅支持一列)等格式文件
// Method 2
dfA.rdd.saveAsTextFile("file:///usr/local/spark/mycode/newpeople.txt")
// Method 3
dfE.write.parquet("file:///usr/local/spark/mycode/newpeople.parquet")
}
}
运行结果: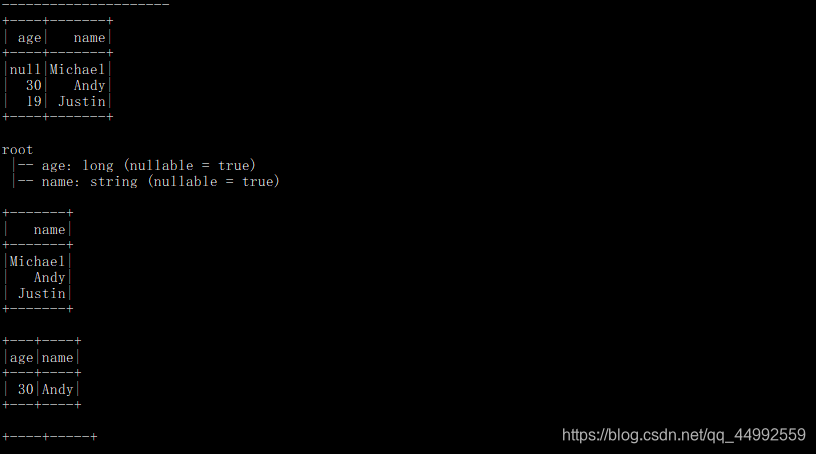
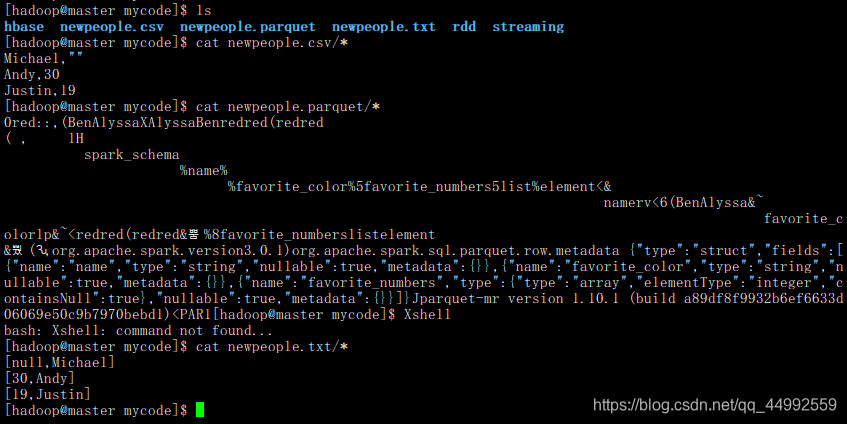
注:
parquet文件乱码是正常的
不要将case class定义在main 方法中与import spark.implicits._、toDF一起使用>>>

二、Mysql 数据库的读取与写入
import org.apache.spark.sql.SparkSession
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
object ReadWriteMysql {
def main(args: Array[String]): Unit ={
val spark = SparkSession.builder().getOrCreate() // SparkSession 对象
// Read
val df = spark.read.format("jdbc").option(
"url","jdbc:mysql://master:3306/sparktest"
).option("driver","com.mysql.jdbc.Driver").option(
"user","root"
).option("password","Hive@2020").option(
"dbtable","student"
).load()
df.show()
// Write
val rdd = spark.sparkContext.parallelize(
Array("5 ABC 12", "6 XYZ 102")
).map(_.split(" "))
val schema = StructType(
List(
StructField("id", IntegerType, nullable = true),
StructField("name", StringType, nullable = true),
StructField("age", IntegerType, nullable = true),
)
)
val rowRdd = rdd.map(s => Row(s(0).toInt,s(1).trim, s(2).toInt))
val df_ = spark.createDataFrame(rowRdd, schema)
val p = new Properties()
p.put("user", "root")
p.put("password", "Hive@2020")
p.put("driver", "com.mysql.jdbc.Driver")
df_.write.mode("append").jdbc(
"jdbc:mysql://master:3306/sparktest", "sparktest.student", p
)
}
}
运行结果:
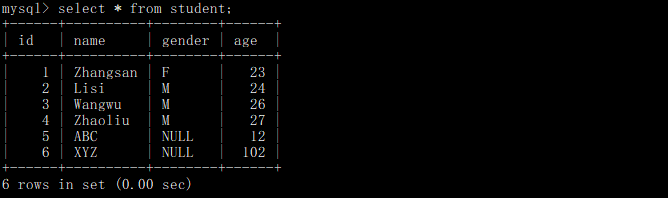
三、Hive 数据仓库的读取与写入
import org.apache.spark.sql.SparkSession
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
object ReadWriteHive {
def main(args: Array[String]): Unit ={
val spark = SparkSession.builder().appName("Spark Hive Test").enableHiveSupport().getOrCreate()
// Read
spark.sql("select * from sparktest.student").show()
// Write
val rdd = spark.sparkContext.parallelize(
Array("5 ABC F 12", "6 XYZ M 102")
).map(_.split(" "))
val schema = StructType(
List(
StructField("id", IntegerType, nullable = true),
StructField("name", StringType, nullable = true),
StructField("gender", StringType, nullable = true),
StructField("age", IntegerType, nullable = true),
)
)
val rowRdd = rdd.map(s => Row(s(0).toInt,s(1).trim, s(2).trim, s(3).toInt))
val df_ = spark.createDataFrame(rowRdd, schema)
df_.createOrReplaceTempView("temp")
spark.sql("insert into sparktest.student select * from temp")
}
}
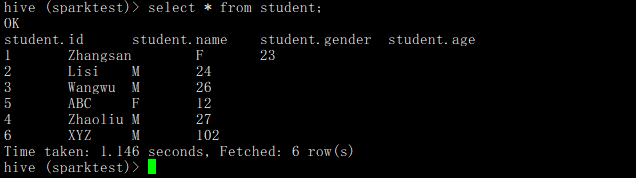
运行结果: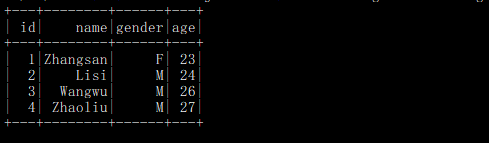

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)