
李宏毅NLP-10-语音分离
摘要 本文系统介绍了语音分离技术,重点分析说话人分离任务。语音分离包含语音增强(降噪)和说话人分离(分离重叠语音)两个方向。说话人分离任务需从混合音频中分离出独立说话人信号,研究集中于单麦克风、双说话人场景,并需解决训练与测试说话人不同的泛化问题。文章详细阐述了评估指标(SNR、SI-SDR、PESQ、STOI)及其优缺点,特别是SI-SDR通过信号投影解决了SNR的幅度作弊问题。针对说话人分离的
Speech Separation

从混合音频中分离出目标说话者的语音,滤除其他声音干扰的能力。人类能在拥挤、嘈杂的环境中,专注于单个说话者的声音,这描述了 鸡尾酒会效应:即使周围有音乐、交谈、噪音等多种声音,人类仍能 “筛选” 出想听的语音(比如在派对上和朋友对话时,自动忽略背景噪音)。
机器如何模仿人类,从混合音频中分离目标语音?(比如解决会议录音中 “多说话者重叠” 的识别难题。)
Speech Enhancement
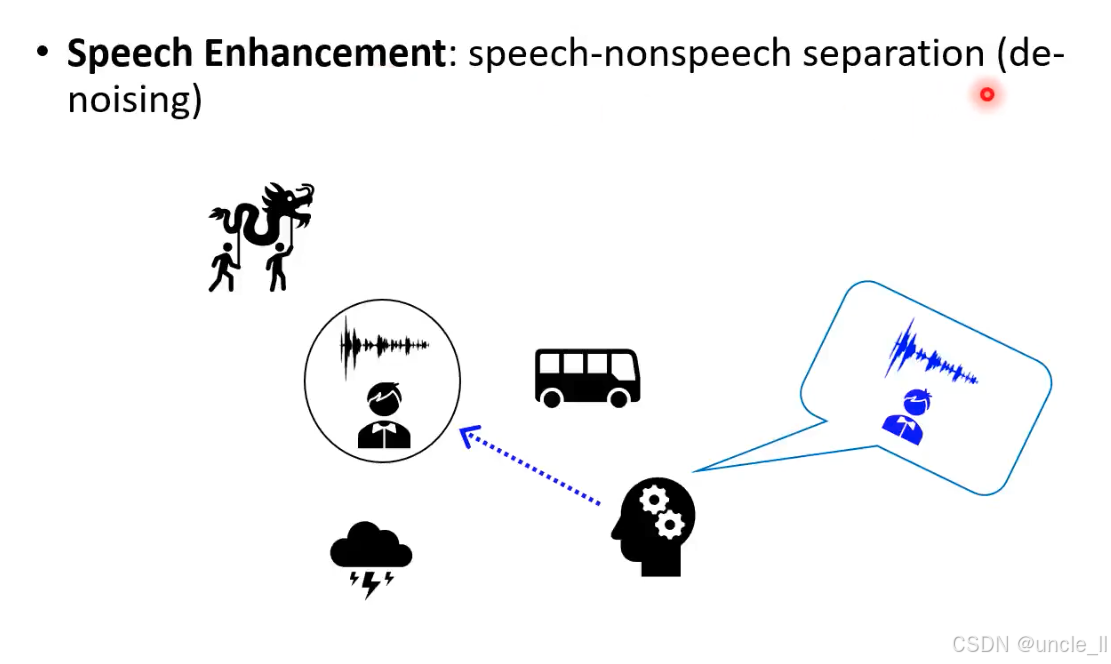
Speech Enhancement(语音增强)” 的核心任务 “语音 - 非语音分离(降噪) 。提升语音信号质量的技术,核心是 分离 “语音” 和 “非语音噪音”(de-noising,降噪)。让机器像人类大脑一样,从混合音频中 “提纯” 出可理解的语音,滤除环境噪音、干扰声等。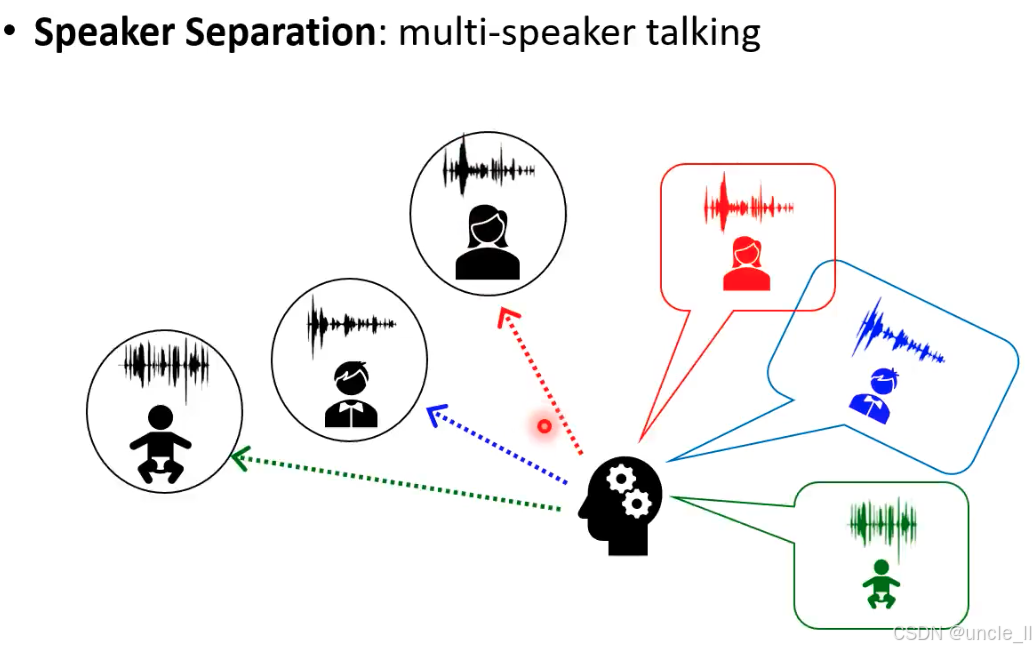
Speaker Separation(说话人分离):从多说话者同时发声的混合音频中,分离出每个说话人独立的语音信号。
场景:会议讨论(多人同时发言)、家庭对话(父母 + 孩子同时说话)、社交场合(多人交谈)等。
Speaker Separation
说话人分离(Speaker Separation)” 的核心任务设定,从输入输出特性、应用场景到技术约束,逐层解析如下:
- 核心流程:混合音频 → 分离单说话人音频
- 输入(Mixed audio):
红色 + 蓝色叠加的波形,代表 两个说话人同时发声的混合音频(时间上完全重叠)。 - 处理模块(Speaker Separation):
接收混合音频,输出 两个独立的说话人音频(红色和蓝色波形,分别对应两个说话人)。 - 输出特性:
Input and output have the same length(输入和输出长度相同),且Seq2seq is not needed(无需序列到序列模型)。- 原因:说话人分离是 “同长度信号转换”(时间维度不变,仅分离不同说话人的时频成分),而非 “长度可变的序列映射”(如语音识别将音频转文字,长度不同)。
- 任务约束(Bullet Points 解析)
图中列出三个关键设定,界定了该任务的研究范围:
(1)Focusing on Two speakers
- 含义:任务聚焦于 分离两个说话人 的场景(简化版问题,延伸可扩展到多说话人,但二分离是基础)。
- 价值:降低复杂度,便于模型学习 “如何区分两个不同说话人的时频特征”,是多说话人分离的基础。
(2)Focusing on Single microphone
- 含义:仅用 单个麦克风 采集混合音频,而非多麦克风阵列。
- 挑战:
多麦克风可利用空间信息(如说话人方位)辅助分离,而单麦克风只能从 时频特征、声纹差异 区分说话人,难度更高(更贴近真实场景:手机录音、会议单麦采集等)。
(3)Speaker independent: training and testing speakers are completely different
- 含义:训练集和测试集的说话人完全不同(模型从未见过测试集的说话人)。
- 目标:让模型学习 通用的 “说话人区分能力”,而非记忆特定说话人的声纹(泛化到 unseen speakers)。
- 对比:若训练和测试用同一批说话人,模型可能 “作弊”(记住声纹),而非真正学习分离逻辑。

说话人分离任务中 “训练数据的合成方法”,核心逻辑是 “通过人工叠加单说话人音频,低成本生成混合音频训练数据”
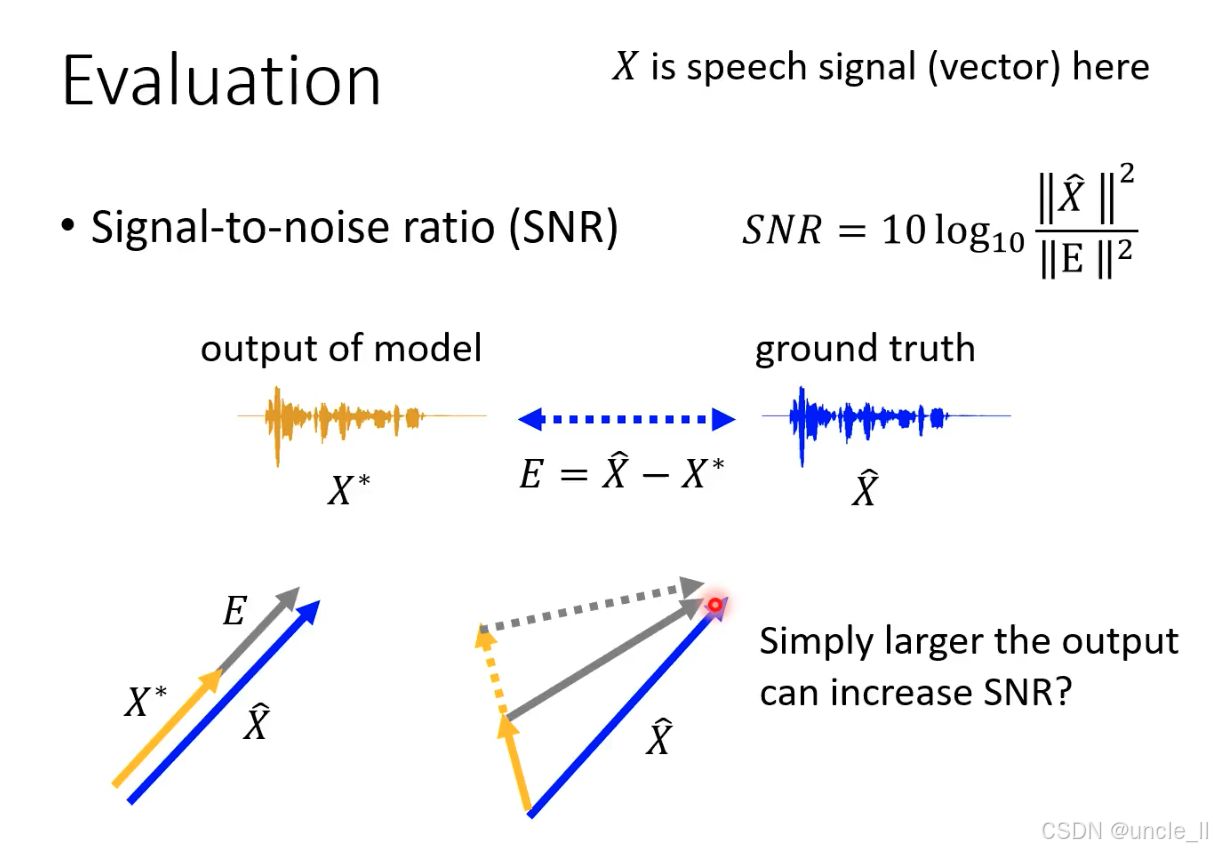
语音信号评估指标 —— 信噪比(SNR)
信号能量与误差能量的比值,单位为分贝(dB)。值越大,说明模型输出越接近真实信号(误差越小)。
SNR 的局限性:“幅度作弊” 问题
Simply larger the output can increase SNR? 揭示了 SNR 的核心缺陷:
“幅度放大” 的陷阱
假设模型故意放大输出信号XXX的幅度(如橙色向量变长,接近蓝色向量的幅度),会发生:
- 分子不变,分母分母变小。两者共同作用下,SNR 会升高—— 但这是 “虚假提升”:模型可能只是放大了输出的幅度,而信号的相位、细节并未匹配真实信号。
这种 “幅度作弊” 会导致:
- 听觉失真:模型输出幅度正确,但波形细节错误(如相位不对),人耳听感仍差。
- 下游任务失效:若用于语音识别(ASR),幅度正确但内容错误的信号会严重降低识别率。
所以SNR不是一个很好的评估方法。
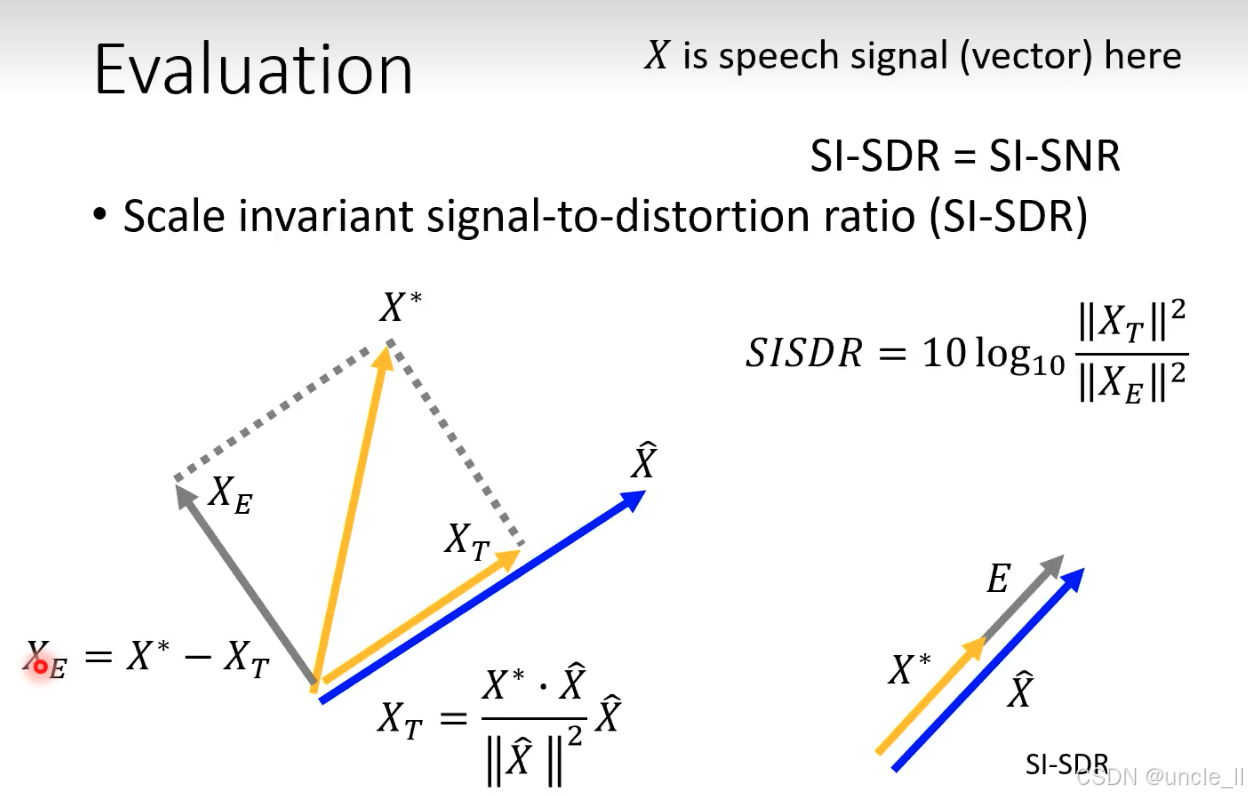
尺度不变信号失真比(SI-SDR,也称为 SI-SNR)
SI-SDR 通过 信号分解 + 投影,消除 “尺度缩放” 对评估的干扰,只关注信号的 结构一致性(如相位、波形形态)。将信号质量评估从 “能量对比” 升级为 “结构对比”,彻底解决了传统 SNR 的 “尺度作弊” 问题,更精准地衡量语音处理模型的实际效果。
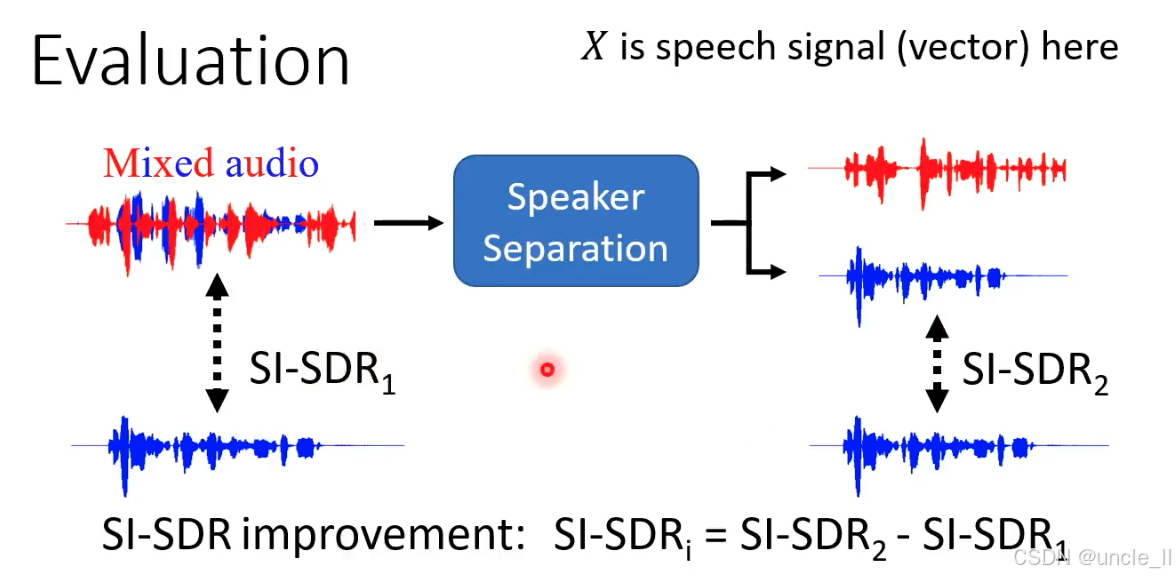
说话人分离系统的 SI-SDR 评估
SI-SDR₁:混合音频 vs 真实参考
- 混合音频(含干扰)与其中一个真实参考信号的 SI-SDR。
- 衡量 混合状态下目标语音的质量(因含干扰,结构一致性差,故
SI-SDR₁值低)。
SI-SDR₂:分离输出 vs 真实参考
- 分离模型输出的语音与对应真实参考信号的 SI-SDR。
- 衡量 分离后目标语音的质量(干扰减少,结构更接近真实信号,故
SI-SDR₂值高)。
核心指标:SI-SDR 提升量(SI-SDRᵢ)
SI−SDRi=SI−SDR2−SI−SDR1SI-SDR_i=SI-SDR_2 − SI-SDR_1SI−SDRi=SI−SDR2−SI−SDR1
模型分离后,目标语音相对于混合状态的质量提升幅度。另外还有其他的方法,比如感知语音质量评估(PESQ)和短时客观可懂度(STOI):
-
PESQ:评估语音信号的感知质量(即人耳主观感受到的清晰度、自然度)。
- 分数范围:−0.5(最差)到4.5(最优)。
- 典型参考:
- 4.0以上:接近无失真的高质量语音(如高清通话);
- 3.0~4.0:良好质量,轻微失真但不影响理解;
- 2.0~3.0:可接受质量,有明显失真但内容可懂;
- 低于2.0:质量较差,难以清晰理解。
- 典型参考:
- 技术特点:通过模拟人耳听觉系统,对比原始语音与处理后语音的差异,综合考虑响度、频率响应、时间波形失真等因素,结果与人类主观评分高度相关。
- 分数范围:−0.5(最差)到4.5(最优)。
-
STOI:评估语音信号的可懂度(即语音内容被正确理解的程度)。
- 分数范围:0(完全不可懂)到1(完全可懂)。
- 典型参考:
- 0.8以上:高可懂度,几乎所有内容可被理解;
- 0.5~0.8:中等可懂度,部分词汇可能混淆;
- 低于0.5:低可懂度,大部分内容无法识别。
- 典型参考:
- 技术特点:聚焦语音的短时频谱包络特征(与语义理解密切相关),通过计算原始语音与处理后语音在短时帧上的相关性来量化可懂度,对噪声、 reverberation(混响)等干扰的鲁棒性较强。
- 分数范围:0(完全不可懂)到1(完全可懂)。

说话人分离任务中的 “置换问题(Permutation Issue),即模型输出的分离语音可能与真实说话人标签错位的现象。输出标签与真实说话人无法稳定对应
- 场景:当输入混合音频包含多个说话人(如图中 “male + female” 的混合语音)时,模型输出的分离结果(X1X_1X1、X2X_2X2)可能出现标签置换—— 第一次分离时X1X_1X1对应女性、X2X_2X2对应男性,第二次分离时x1x_1x1却对应男性、X2X_2X2对应女性。
- 矛盾:模型训练需要稳定的 “输入 - 输出标签对应”,但置换问题导致输出标签随机切换,直接使用 L1/L2 损失函数会误导训练(模型可能因标签错位而学习错误映射)。
解决的方法有一些,先讲解deep cluster方法: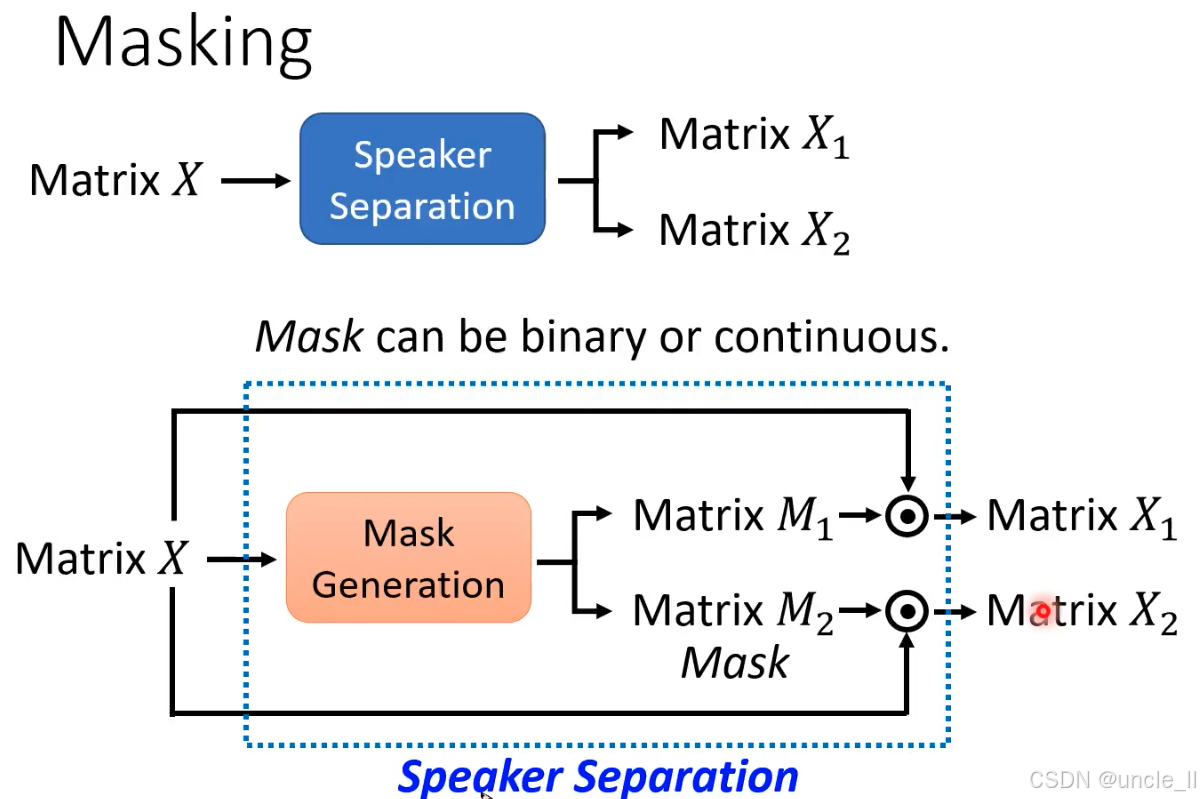
说话人分离(Speaker Separation)中基于 “掩码(Masking)” ,**通过生成掩码矩阵从混合音频中分离出不同说话人的语音。 **
- 整体流程:从混合音频矩阵到分离结果
- 输入:混合音频的时频矩阵 X(如通过 STFT 将音频转换为 “时间 - 频率” 二维矩阵,每个元素代表特定时刻和频率的能量)。
- 输出:两个分离后的说话人音频矩阵 X1 和 X2(对应不同说话人)。
- 核心逻辑:通过 “掩码生成” 模块创建掩码矩阵 M1 和 M2,分别与混合矩阵 X 相乘,过滤出目标说话人的能量成分,抑制其他说话人。
- 掩码生成(Mask Generation):分离的关键
- 掩码的作用:掩码矩阵M的每个元素取值范围通常为 0~1,用于 “保留” 或 “抑制” 混合矩阵中对应位置的能量:
- 若 Mt,f=1M_{t,f}=1Mt,f=1(接近 1):表示时频点 (t,f) 的能量属于目标说话人,应保留;
- 若 Mt,fM_{t,f}Mt,f=0(接近 0):表示该能量属于干扰说话人,应抑制。
- 掩码类型:
- 二值掩码(Binary Mask):元素非 0 即 1,强制划分每个时频点属于某一说话人(如理想二值掩码 IBM);
- 连续掩码(Continuous Mask):元素取值为 0~1 的连续值(如软掩码 Soft Mask),更灵活地表示归属概率(如 0.8 表示 80% 概率属于目标说话人)。
- 分离过程:掩码与混合矩阵的乘积
- 数学表达:分离出的说话人音频矩阵 X1=X⊙M1,X2=X⊙M2(⊙ 表示逐元素相乘):
- 混合矩阵 X 同时输入 “掩码生成” 模块;
- 模块输出两个掩码矩阵 M1 和 M2;
- 每个掩码与 X 相乘,得到仅包含对应说话人能量的矩阵 X1 和 X2;
- 最终通过逆 STFT 将 X1、X2 转换回时域音频波形。
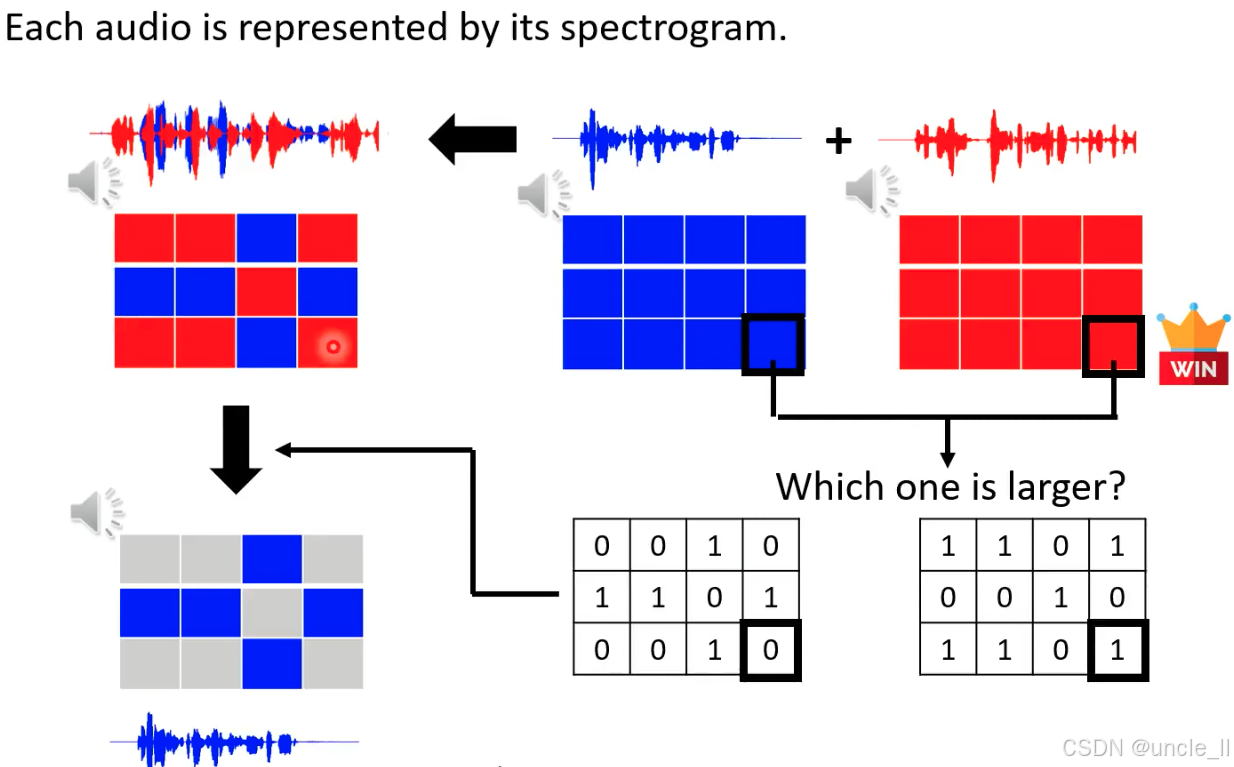
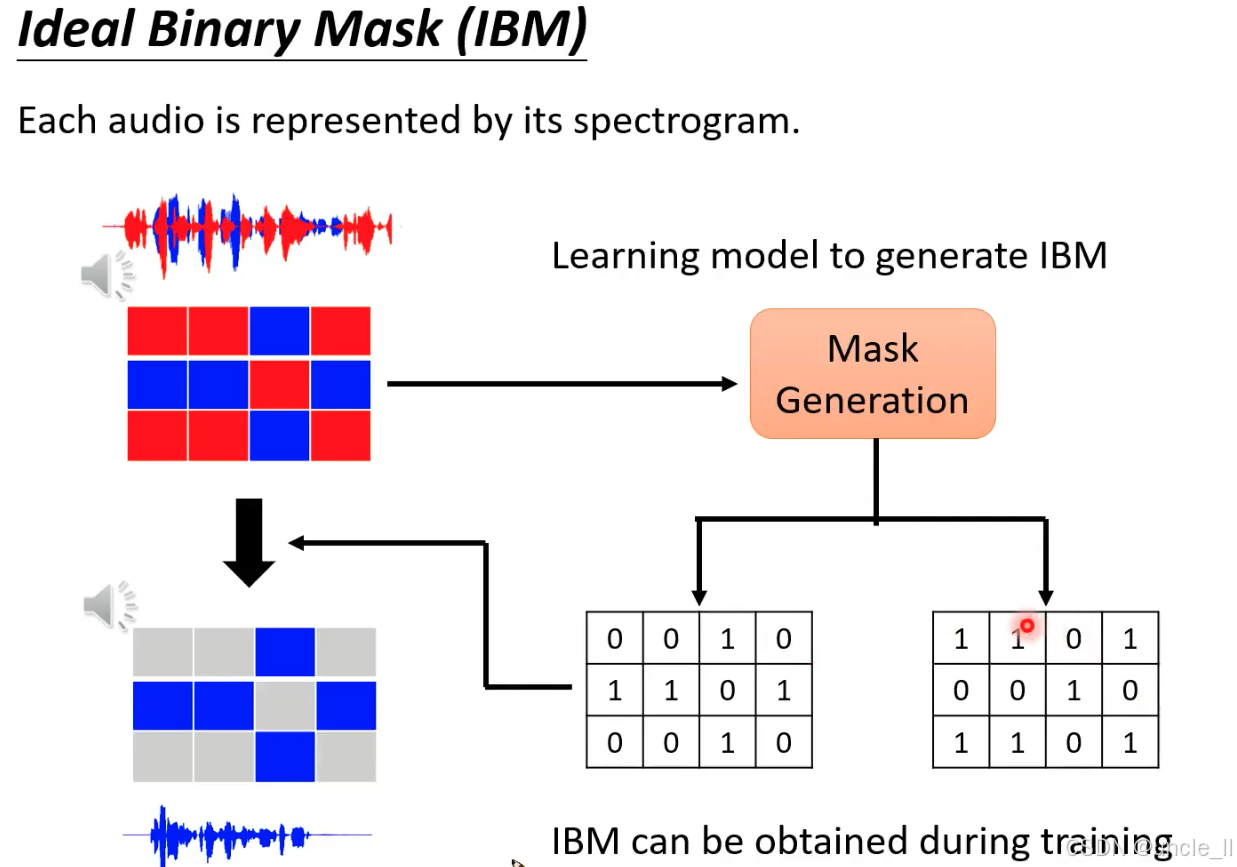
哪个位置元素大就选哪个,能够过滤掉别的声音。idea binary mask 可以在训练阶段得到;
通过设计时频域的 “筛选器”(掩码矩阵),从混合音频中 “剥离” 出不同说话人的语音成分,是实现单通道说话人分离的关键思想。
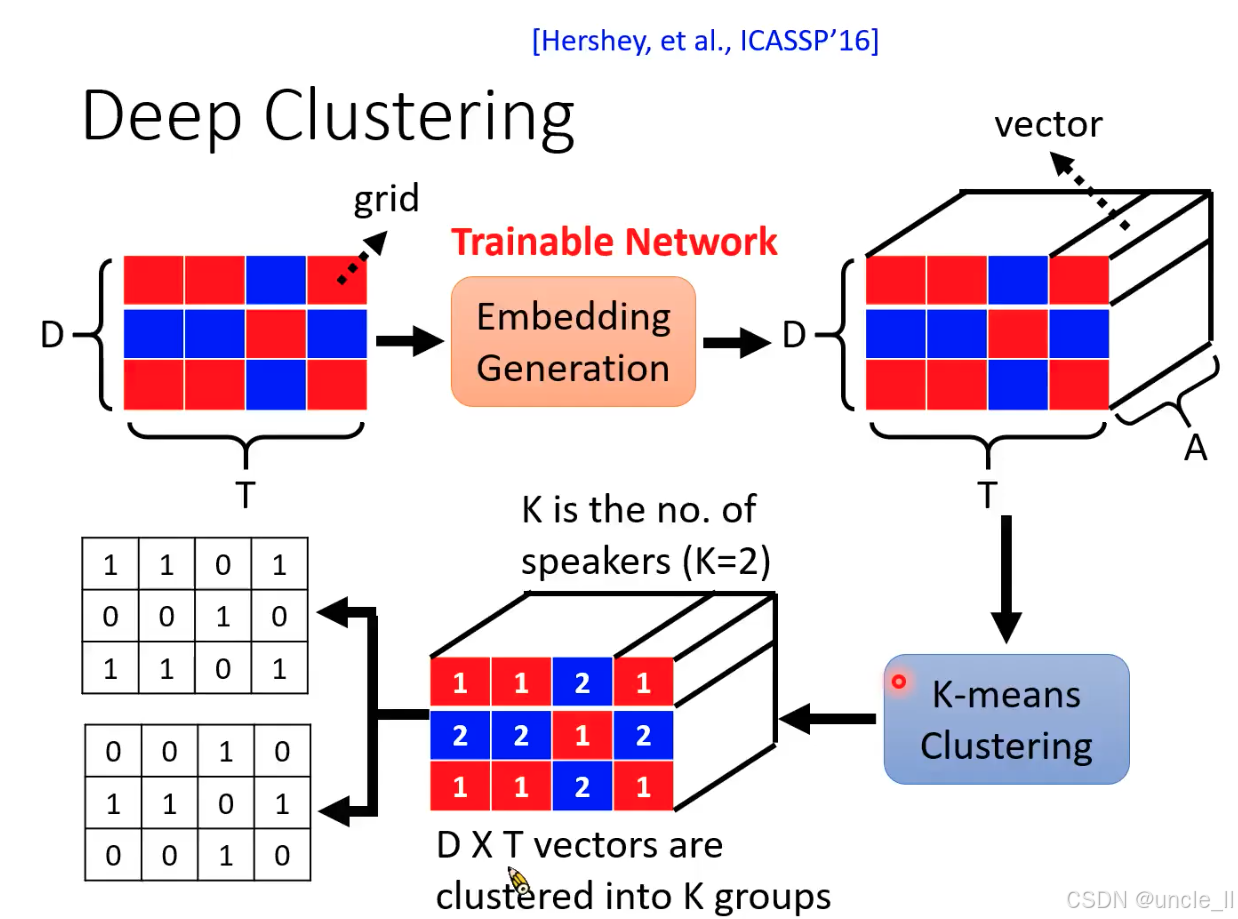
Deep Clustering(深度聚类)的核心流程,由 Hershey 等人在 ICASSP 2016 年提出。该算法通过将混合音频的时频单元聚类为不同说话人,实现单通道说话人分离。
- 核心思想:时频单元的嵌入与聚类
混合音频的时频矩阵(如 STFT 结果)中,每个时频点(时间TTT× 频率DDD)的能量可能来自不同说话人。Deep Clustering 的目标是:
- 将属于同一说话人的时频点 “聚为一类”,属于不同说话人的时频点 “分为不同类”;
- 通过深度学习生成时频点的嵌入向量(Embedding),使同类向量距离近、异类向量距离远,再用 K-means 聚类得到分离掩码。
- 流程拆解:从时频矩阵到分离掩码
(1)输入:混合音频的时频网格(Grid)
- 红色 / 蓝色网格代表混合音频的时频矩阵(维度DDD×TTT,DDD= 频率轴,TTT= 时间轴);
- 每个格子(时频点)的颜色模拟能量分布,但此时无法区分属于哪个说话人(需后续聚类)。
(2)嵌入生成(Embedding Generation):将时频点映射为高维向量
- 作用:通过神经网络(如 LSTM、CNN)将每个时频点(DDD×1 特征)转换为高维嵌入向量(维度AAA,如图中 “vector” 箭头所示);
- 关键:嵌入向量需满足 “同一说话人的时频点向量相似,不同说话人的向量差异大”(通过训练实现);
- 输出:DDD×TTT个嵌入向量(每个时频点对应一个向量),构成右侧的三维张量(DDD×TTT×AAA)。
(3)K-means 聚类:划分说话人类别
- 输入:DDD×TTT个嵌入向量(展平为二维向量集合);
- 聚类过程:用 K-means 算法将向量聚为KKK类(KKK= 说话人数量,图中K=2K=2K=2);
- 输出:聚类标签矩阵(右侧立方体中红色数字 “1”“2”),每个时频点被标记为属于说话人 1 或 2。
(4)生成二值掩码(Binary Mask)
- 映射规则:根据聚类标签,将属于说话人 1 的时频点标记为 1(白色格子),其他为 0(黑色格子),得到说话人 1 的掩码;同理生成说话人 2 的掩码(图中左侧两个二值矩阵);
- 分离操作:掩码与混合时频矩阵相乘,保留目标说话人时频能量,实现语音分离。
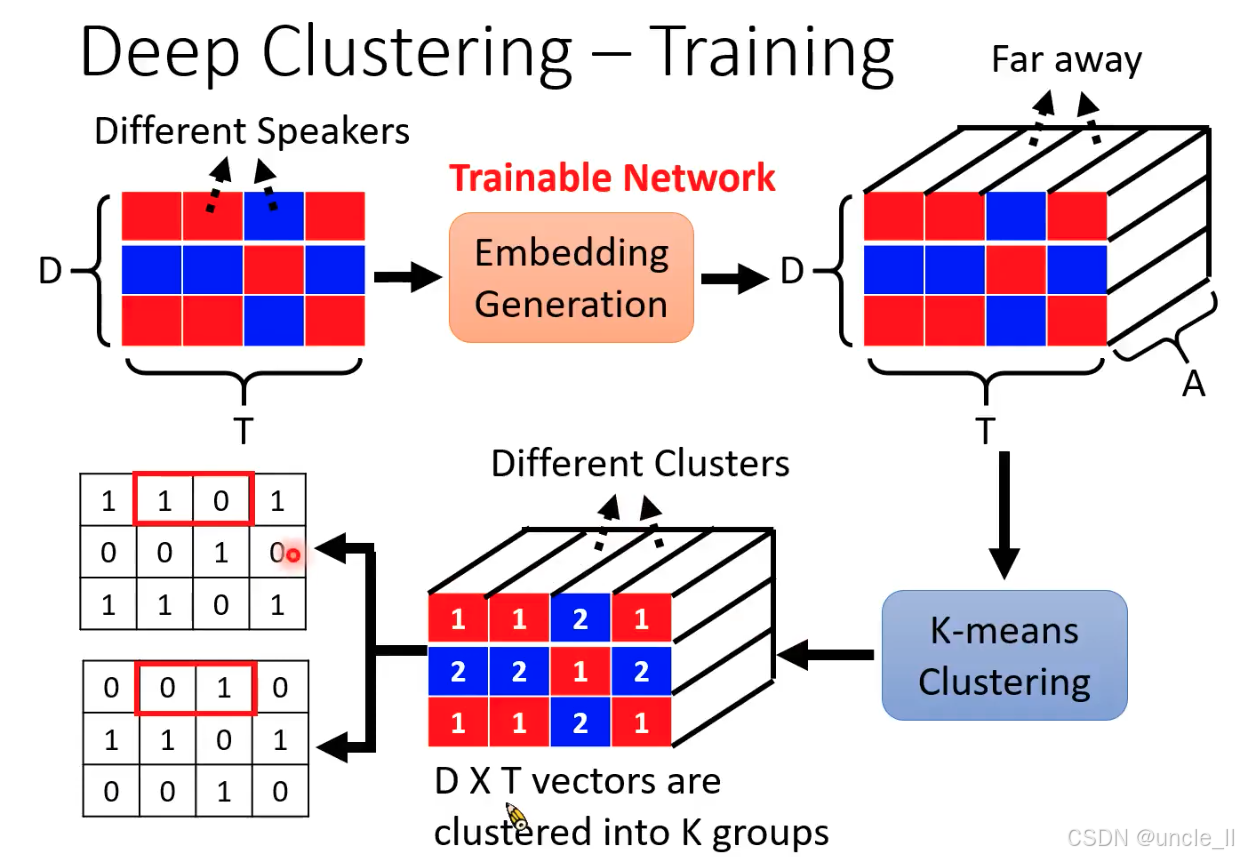
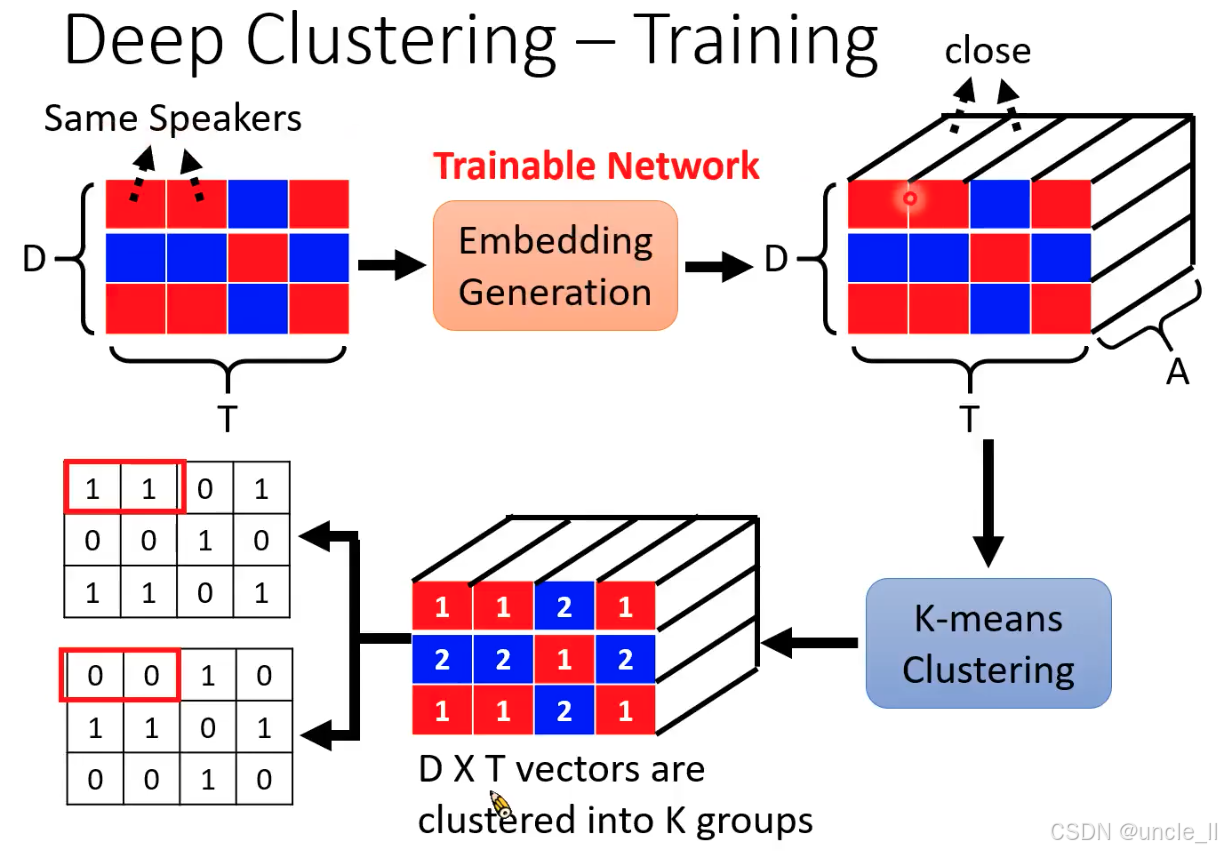
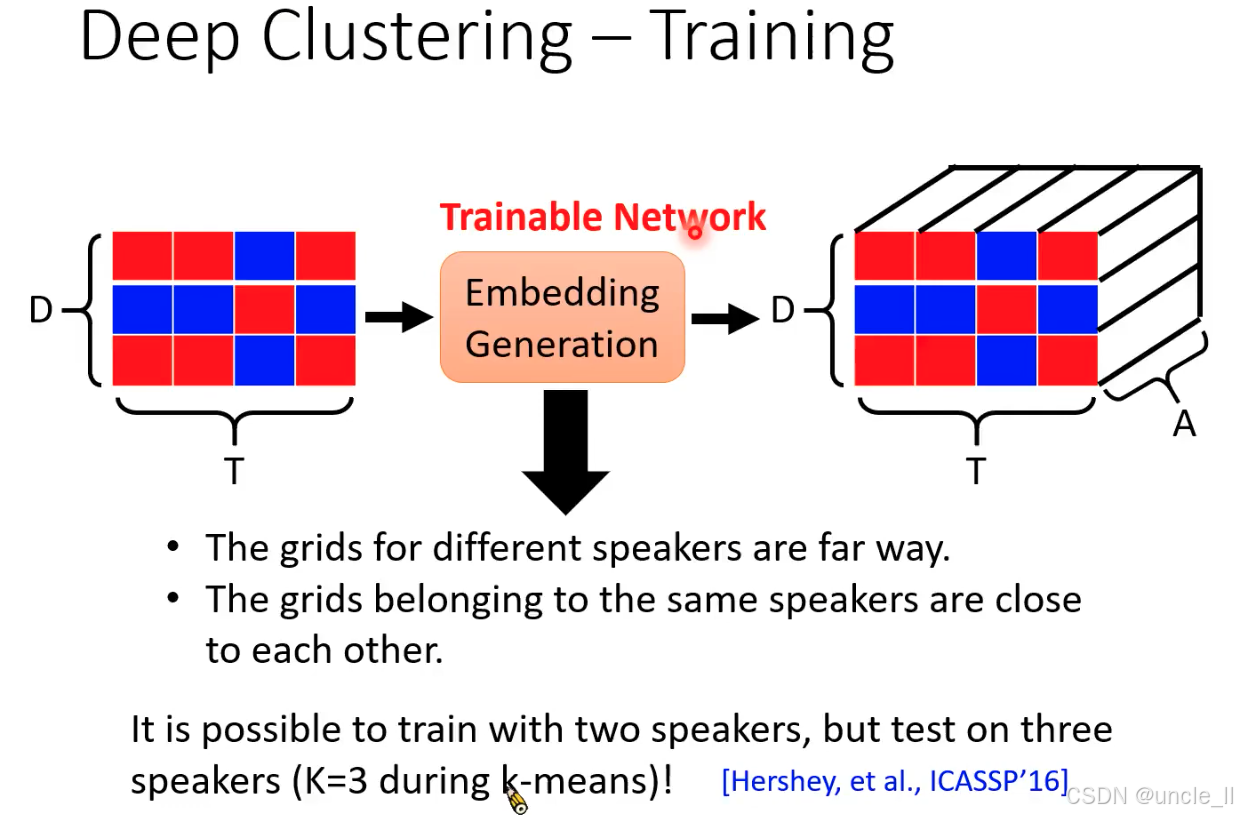
Deep Clustering 首次将深度学习嵌入 + 无监督聚类结合用于语音分离,开创了 “时频点聚类” 的新范式。其核心贡献是通过嵌入向量将 “分离问题” 转化为 “聚类问题”,为后续端到端语音分离模型(如 ConvTasNet)奠定了思想基础。
PIT
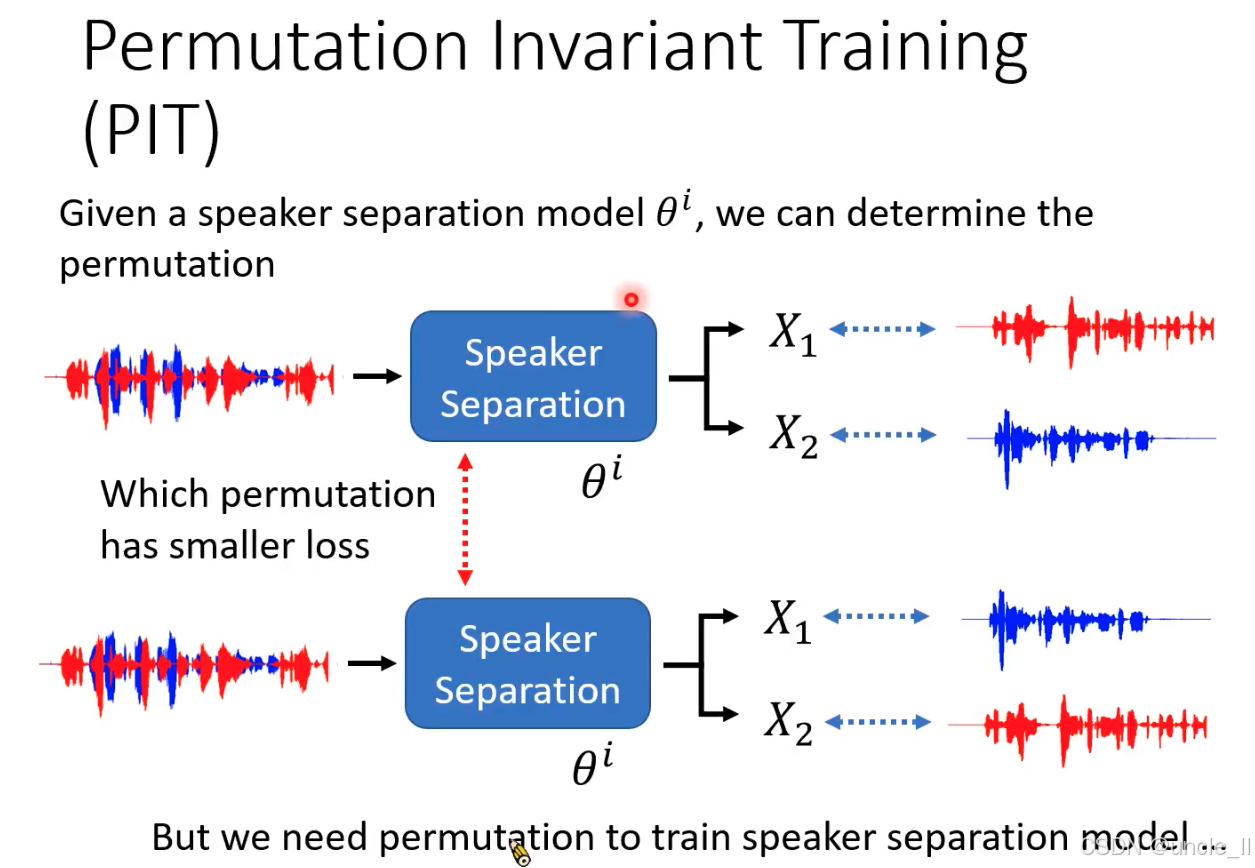
- 问题背景:置换问题对训练的干扰
当模型输入混合音频(如红色 + 蓝色波形,含两个说话人)时,输出的分离结果(X1X_1X1、X2X_2X2)可能出现两种标签对应关系:
-
情况 1:X1X_1X1对应红色波形(说话人 A),X2X_2X2对应蓝色波形(说话人 B);
-
情况 2:X1X_1X1对应蓝色波形(说话人 B),X2X_2X2对应红色波形(说话人 A)。
若直接固定标签(如强制X1X_1X1对应 A),模型会因情况 2 的 “标签错位” 计算错误损失,导致训练目标混乱。
- PIT 的核心思想:动态选择最优标签匹配
PIT 通过 “寻找最小损失的标签置换” 解决上述问题,核心流程:
-
模型输出所有可能的置换结果:对KKK个说话人,生成K!K!K!种标签与输出的配对方式(图中K=2K=2K=2,故有 2 种置换);
-
计算每种置换的损失:如对比X1X_1X1-A/X2X_2X2-B(情况 1)和X1X_1X1-B/X2X_2X2-A(情况 2)的损失(如 SI-SDR 损失);
-
选择损失最小的置换作为 “正确匹配”:将该置换对应的损失作为当前训练样本的损失,用于反向传播更新模型参数。
通过对比两种置换的损失,自动选择损失更小的配对方式,确保模型学习到 “与标签顺序无关” 的分离能力。
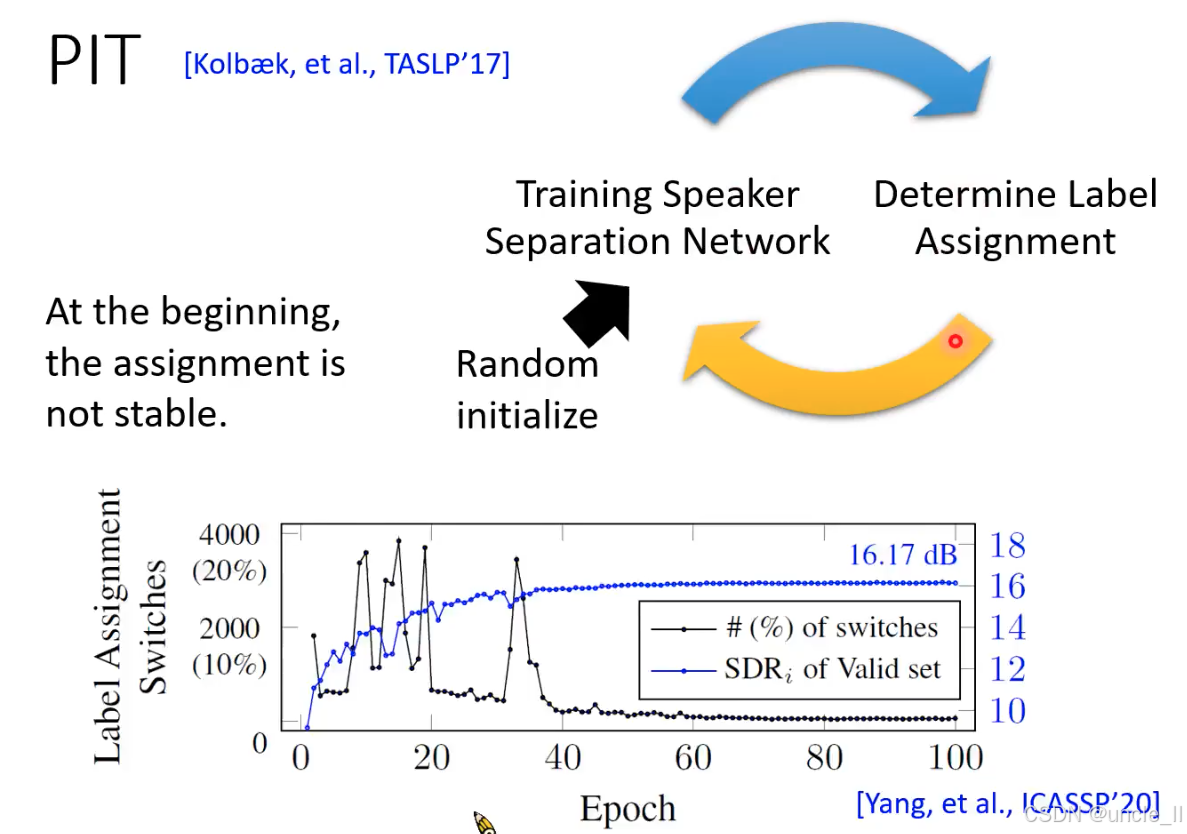
-
稳定分配→性能提升:标签分配稳定后,模型能持续优化目标说话人的分离精度,导致验证集的 SDRi(SDR 改善量)逐步上升;
-
性能提升→更稳定分配:分离精度提高进一步降低错误标签配对的可能性,形成良性循环。
-
训练初期(0-20 epoch):标签切换频繁(>10%),SDRi 波动较大且增长缓慢 —— 模型因目标不明确难以有效学习;
-
训练中期(20-60 epoch):标签切换快速下降至 0%,SDRi 同步快速提升 —— 模型通过 PIT 机制找到稳定的标签映射,开始针对性优化;
-
训练后期(60+ epoch):标签切换为 0,SDRi 趋于饱和 —— 模型已收敛到最优分离性能。
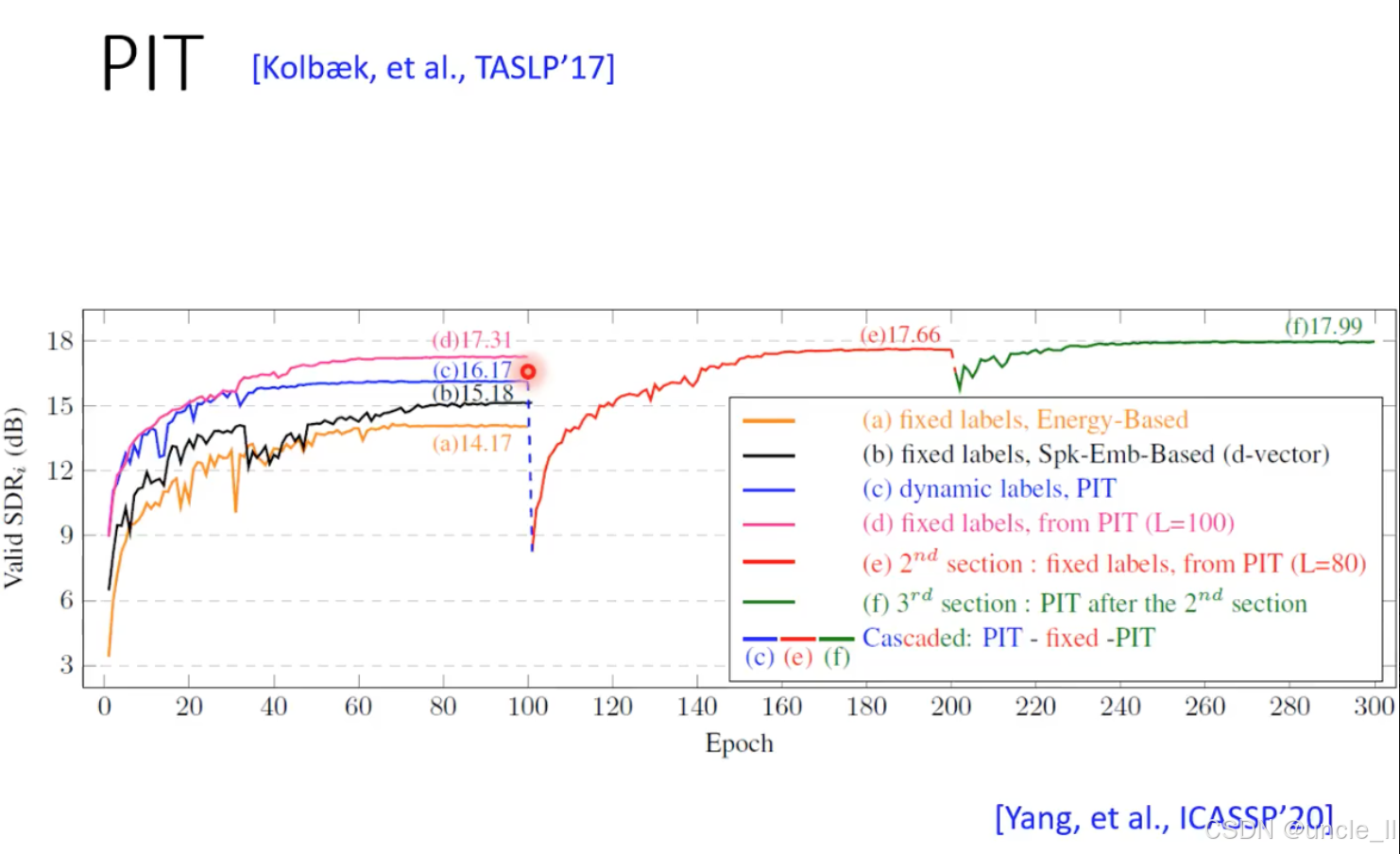
动态标签分配是 PIT 性能的关键
- PIT(动态标签)显著优于固定标签策略:
- 标准 PIT(c)比最佳固定标签策略(b)SDRi 提升 2.13 dB;
- 固定 PIT 收敛后的标签(e)会因数据分布变化导致性能崩溃,而动态 PIT(c)能持续适应。
- 标签稳定性与泛化性的平衡:
- 级联 PIT(f)通过 “先固定后动态” 的方式,既利用了稳定标签的快速收敛,又保留了动态调整的泛化能力,最终性能最优(17.99 dB)。
- PIT 的鲁棒性:
- 所有 PIT 相关策略(c、d、f)的 SDRi 均超过 16 dB,且训练过程稳定,验证了动态标签分配对解决置换问题的有效性。
TasNet
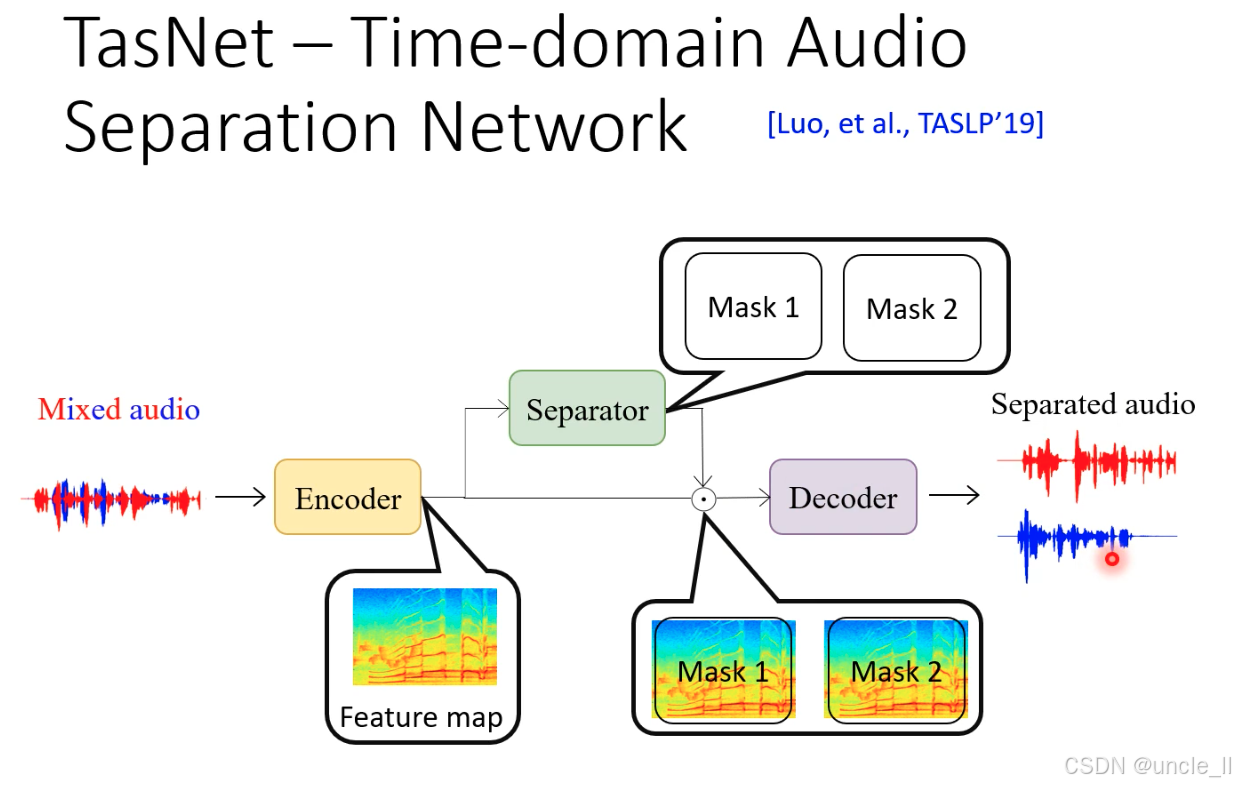
TasNet 的输入是混合音频波形(Mixed audio),输出是分离后的多个说话人音频波形(Separated audio),核心由三部分组成:编码器(Encoder)、分离器(Separator) 和解码器(Decoder)。
(1)编码器(Encoder):将时域波形转换为特征映射
- 输入:单通道混合音频时域波形(采样率通常为 8kHz 或 16kHz)。
- 操作:通过1D 卷积层将原始波形分割为重叠的时域片段(称为 “语音原子”),并映射到高维特征空间,生成特征映射(Feature map)(维度为时间 × 特征通道)。
- 作用:保留原始时域信号的细粒度信息,避免传统 STFT 时频转换带来的相位失真和频谱泄露问题。
(2)分离器(Separator):生成掩码并过滤特征
- 输入:编码器输出的特征映射。
- 核心模块:由双向 LSTM或Transformer等深度网络组成,学习区分不同说话人的特征模式,输出与说话人数量对应的掩码(Mask 1、Mask 2)(每个掩码维度与特征映射一致)。
- 掩码类型:通常为实值掩码(元素取值 0~1),表示每个特征通道属于目标说话人的概率。
- 过滤操作:特征映射与掩码逐元素相乘,得到每个说话人对应的特征子空间(如 Mask 1 过滤出说话人 1 的特征,Mask 2 过滤出说话人 2 的特征)。
(3)解码器(Decoder):从特征映射重建时域波形
- 输入:分离器输出的每个说话人的特征子空间。
- 操作:通过转置卷积层(Transposed Convolution)将高维特征映射逆转换为时域波形,得到分离后的音频信号(红色和蓝色波形)。
- 优势:端到端重建时域信号,避免时频域转换中 “相位恢复” 这一难题,直接优化听觉感知相关的损失函数(如 SI-SDR)。
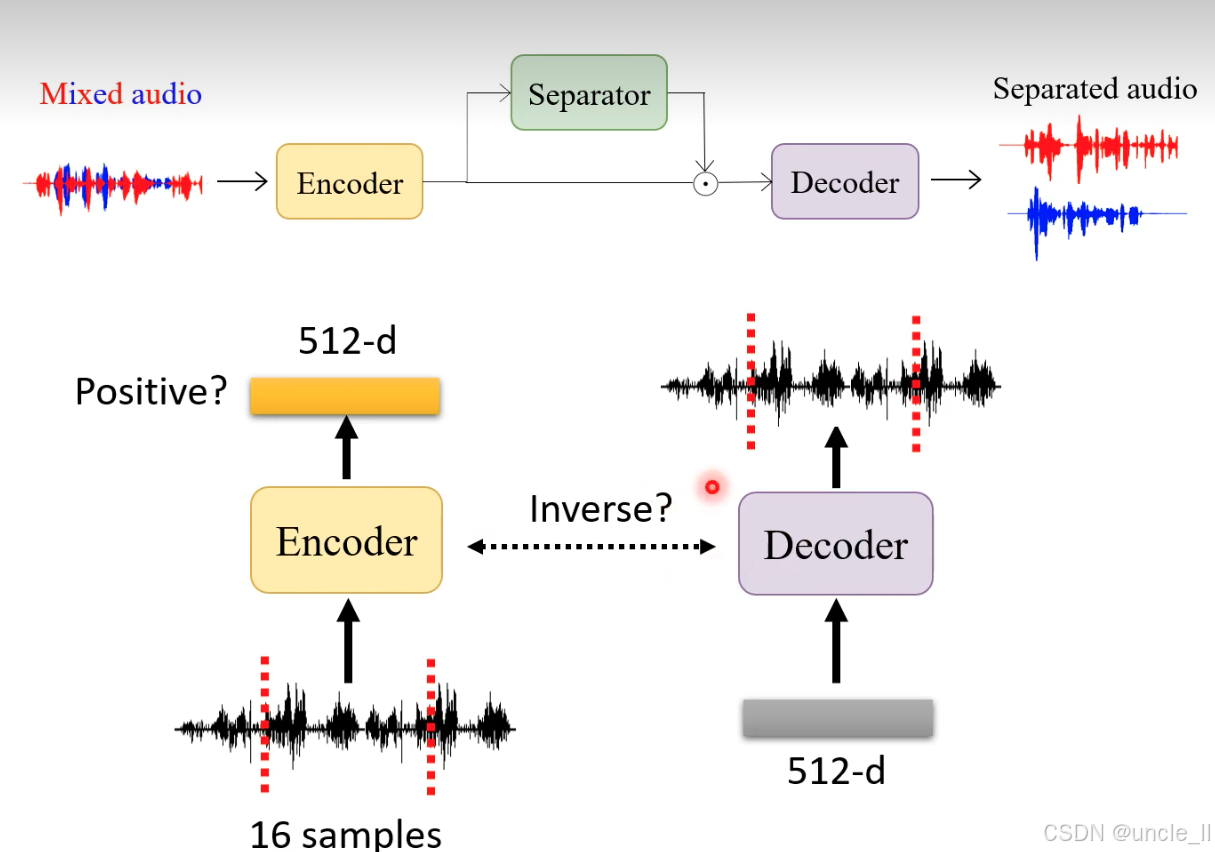
短音频片段的编码 - 解码循环
- 输入:16 个采样点的短音频片段(黑色波形,红虚线标记范围)。
- 编码(Encoder):将 16 采样点压缩为512 维向量(橙色矩形,维度远低于原始采样点数量,实现 “压缩”)。
- 解码(Decoder):从 512 维向量重建时域波形(紫色模块,输出黑色波形)。
- 验证指标:
- Positive?:特征向量是否包含 “正向” 音频信息(如是否可区分语音与噪声);
- Inverse?:解码波形与原始波形的相似度(如 MSE 损失、听觉感知一致性)。
encoder产生的结果是512维的向量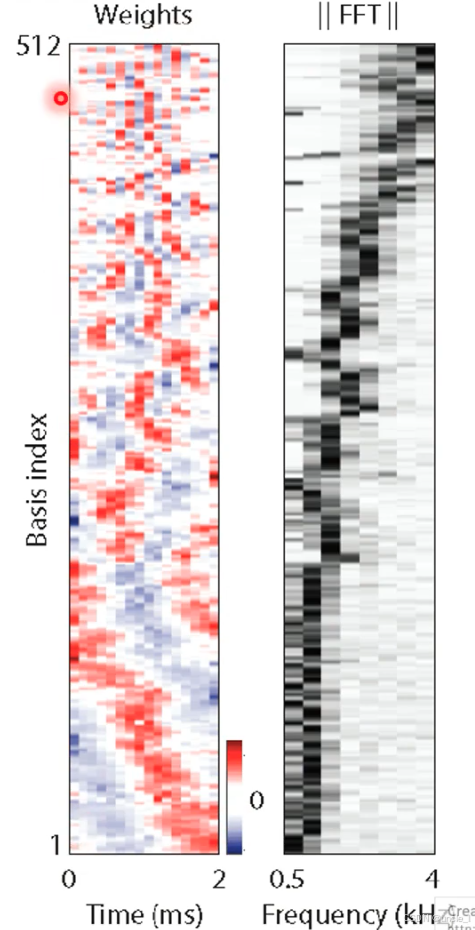
对不同频率的进行编码,有一些是高频的,有一些是低频的。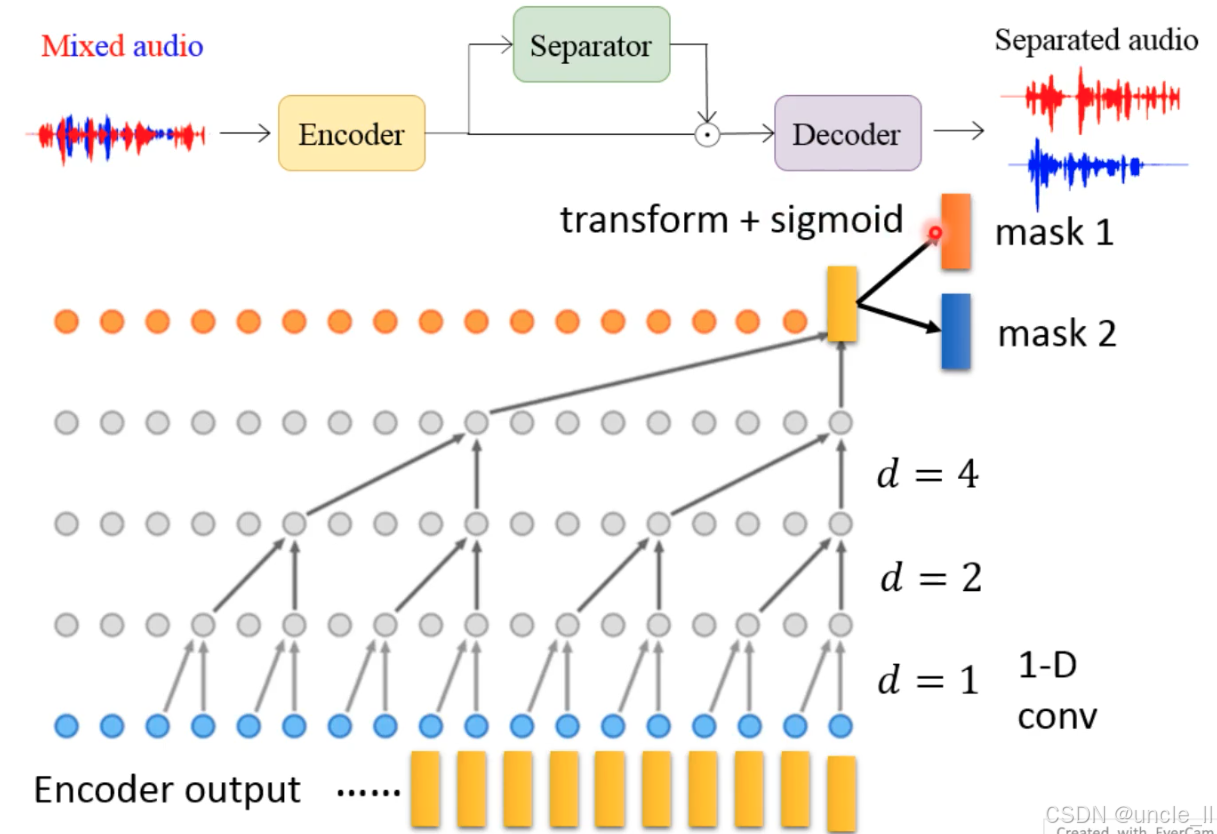
分离器的 1D 卷积金字塔设计
(1)核心目标:从编码器特征中学习 “说话人区分掩码”
- 编码器输出的特征(黄色矩形,维度为时间 × 通道)→ 经多层 1D 卷积(灰色节点)→ 压缩为高维特征 → 生成两个掩码(mask 1、mask 2)。
(2)1D 卷积金字塔的层级结构
- 层级与感受野(d):
- 每层卷积的扩张率(dilation rate, d) 分别为 1、2、4(图中标注
d=1d=2d=4)。 - 扩张卷积(Dilated Convolution)让每层卷积覆盖的时间范围指数级扩大(如 d=4 时,单个卷积核覆盖 4×2=8 个时间步),实现 “大感受野” 捕捉长时依赖(如跨句子的说话人特征)。
- 每层卷积的扩张率(dilation rate, d) 分别为 1、2、4(图中标注
- 特征聚合:
- 每层灰色节点代表卷积后的特征,通过跳跃连接(灰色箭头) 聚合多层特征(低层细粒度 + 高层长时依赖)。
(3)掩码生成:transform + sigmoid
- transform:将聚合后的高维特征通过全连接层映射为与掩码维度匹配的向量。
- sigmoid:将输出值压缩到
[0,1]区间,确保掩码为 “概率值”(1 = 保留该时频点,0 = 抑制)。
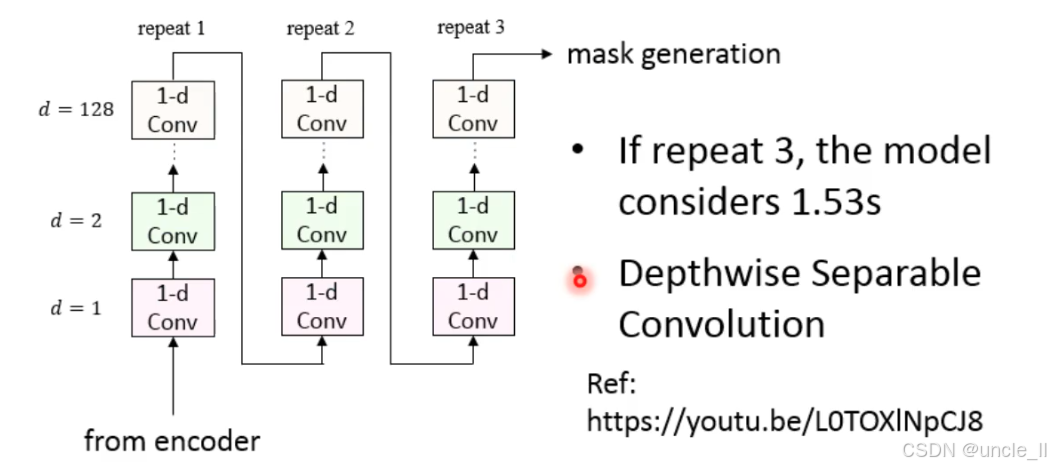
通过堆叠相同结构的卷积链,进一步扩大有效感受野,最终覆盖 1.5 秒语音
- 深度可分离卷积:将卷积拆分为两步:
- Depthwise 卷积:对每个输入通道单独应用卷积(如 1×3 卷积核仅处理 1 个通道);
- Pointwise 卷积:用 1×1 卷积融合不同通道的特征。
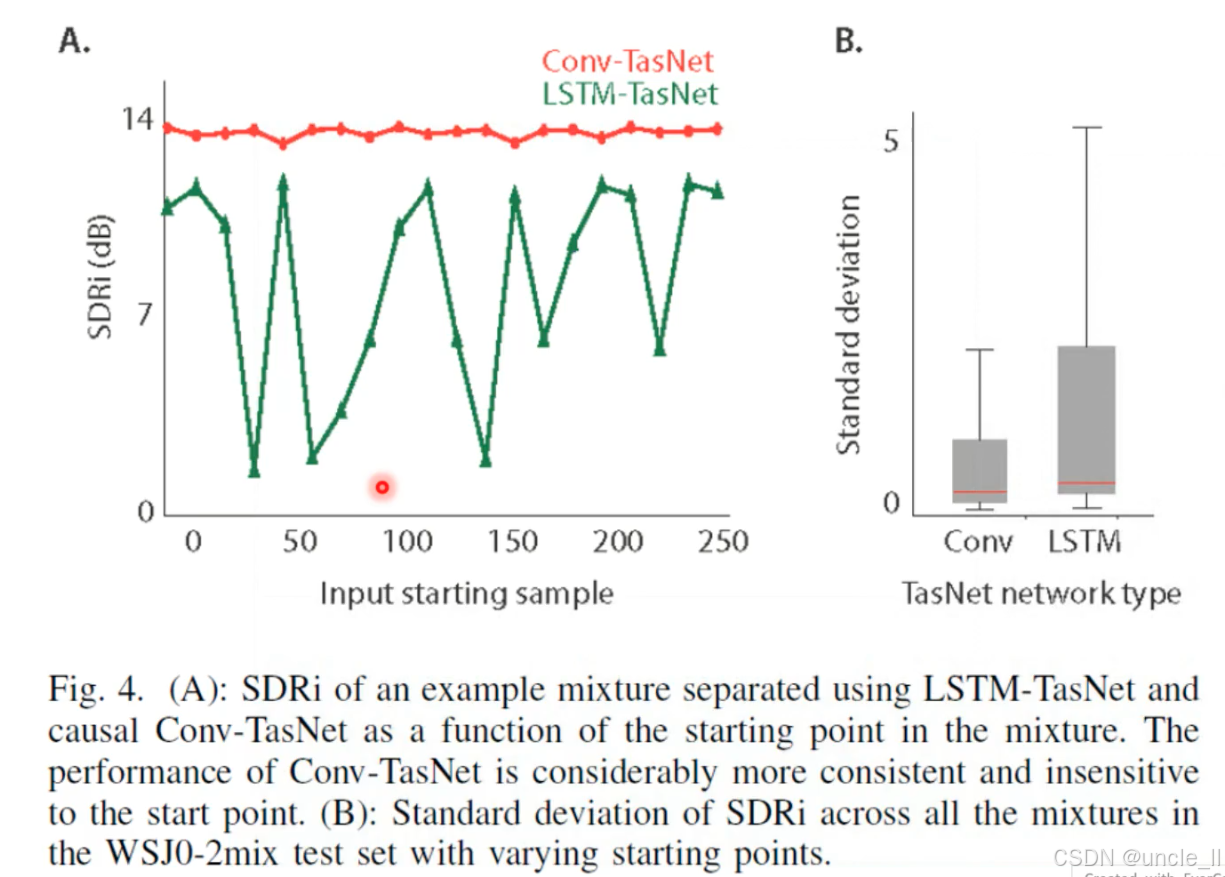
这张图对比了 Conv-TasNet(卷积版) 和 LSTM-TasNet(循环版) 在语音分离任务中的稳定性,核心结论是:卷积结构的分离性能更稳定,对输入起始点不敏感。
- 卷积结构对输入起始位置不敏感,无论从哪里截断音频,分离质量一致。
- 循环网络(LSTM)依赖长时上下文,输入起始位置变化会破坏上下文连续性,导致分离质量剧烈波动。
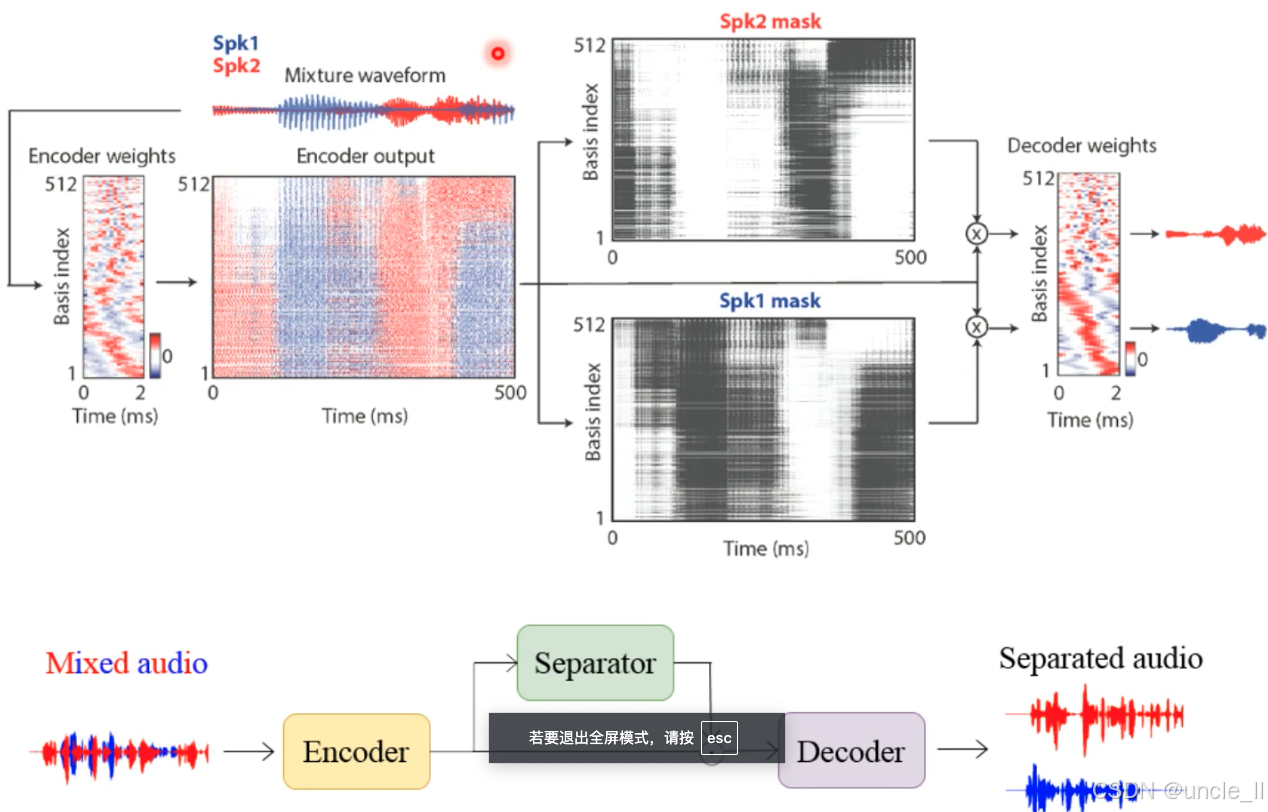
输入混合音频(红蓝波形)→ Encoder(编码器) 提取特征 → Separator(分离器) 生成掩码 → Decoder(解码器) 重建分离音频(红蓝波形)
这张表格清晰展示了语音分离模型的 “性能演进史”—— 从传统聚类到时域卷积,再到自监督学习,ΔSI-SDR 从 10 dB 级提升到 20 dB 级。
其他情况
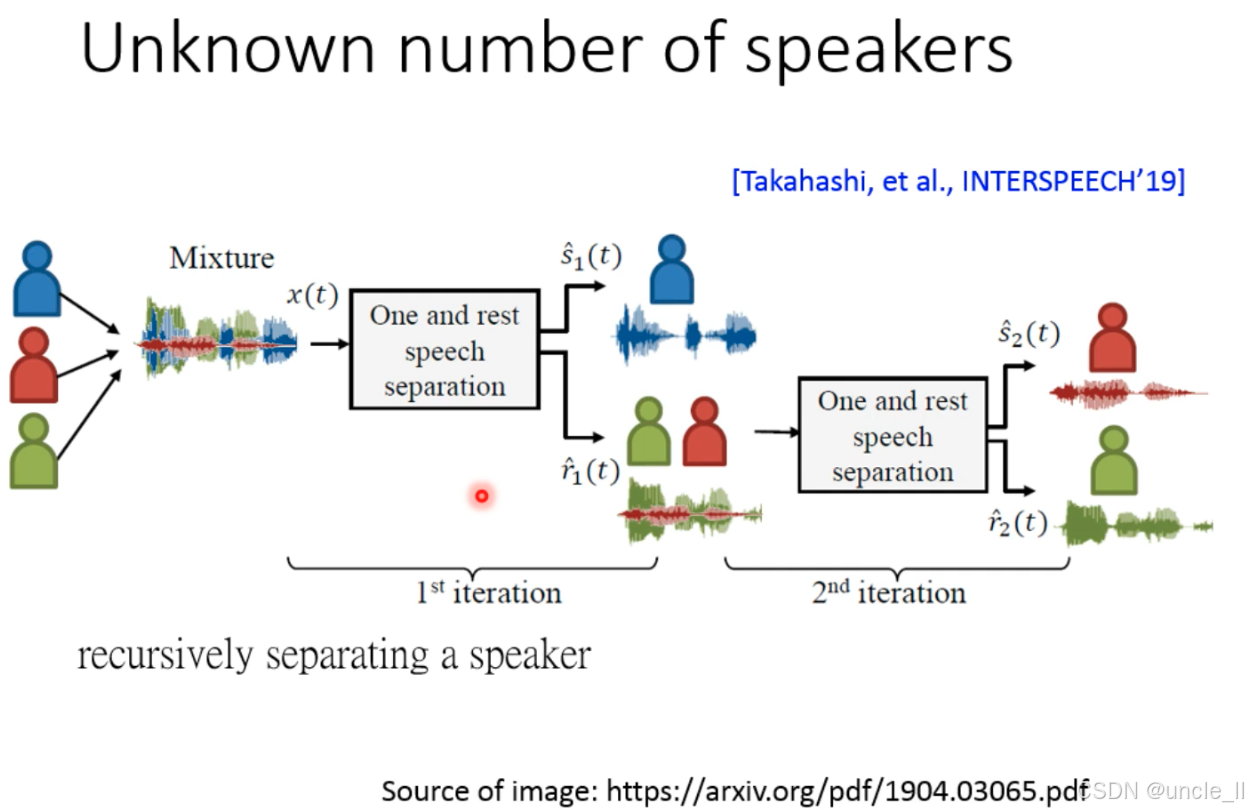
未知说话人数量场景下的语音分离方法,核心是通过递归分离(Recursive Separation) 逐步提取每个说话人的语音
传统语音分离模型(如 TasNet、Deep Clustering)需要预先知道说话人数量(K)(如 K=2 时训练分离两个说话人)。但实际场景中(如会议、直播),说话人数量动态未知,无法预先设定 K,需新方法。
(1)“One and rest” 分离模块
- 输入:混合音频 x(t)(含 N 个说话人,N 未知)。
- 输出:
- 一个说话人的纯净语音 (如蓝色人形对应的语音);
- 剩余说话人的混合语音(绿色 + 红色人形对应的混合语音)。
(2)递归迭代
- 第 1 次迭代(1st iteration):
从总混合音频中分离出 1 个说话人(蓝色),剩余混合音频进入下一轮。 - 第 2 次迭代(2nd iteration):
对剩余混合音频(绿色 + 红色)再次用 “One and rest” 分离,提取第 2 个说话人(红色),剩余混合音频(绿色)进入下一轮(可继续迭代直到无剩余语音)。
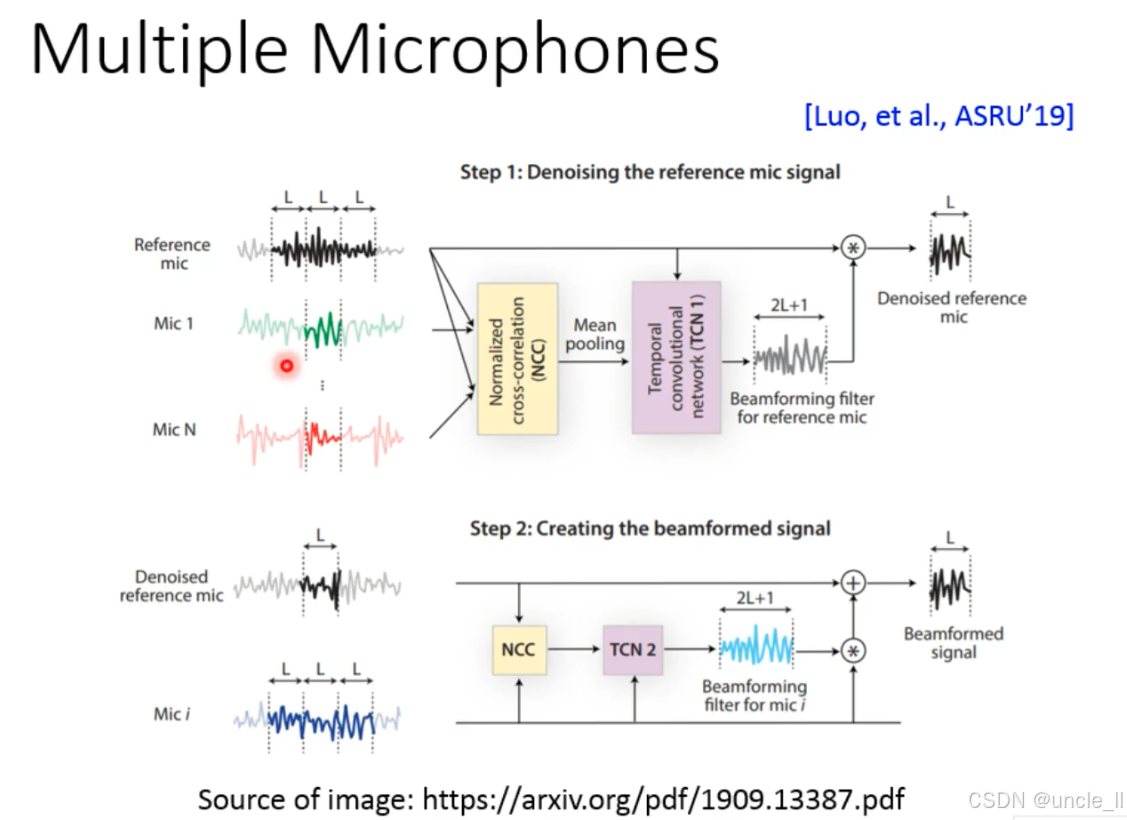
**“NCC+TCN” 多麦克风协同框架 **,突破了传统波束形成的 “固定规则” 限制,通过深度学习自适应学习降噪和增强模式,实现复杂环境下的语音纯净提取。核心是用多麦克风的 “空间相关性” 和 TCN 的 “时序学习能力”,让波束形成更智能、更鲁棒。
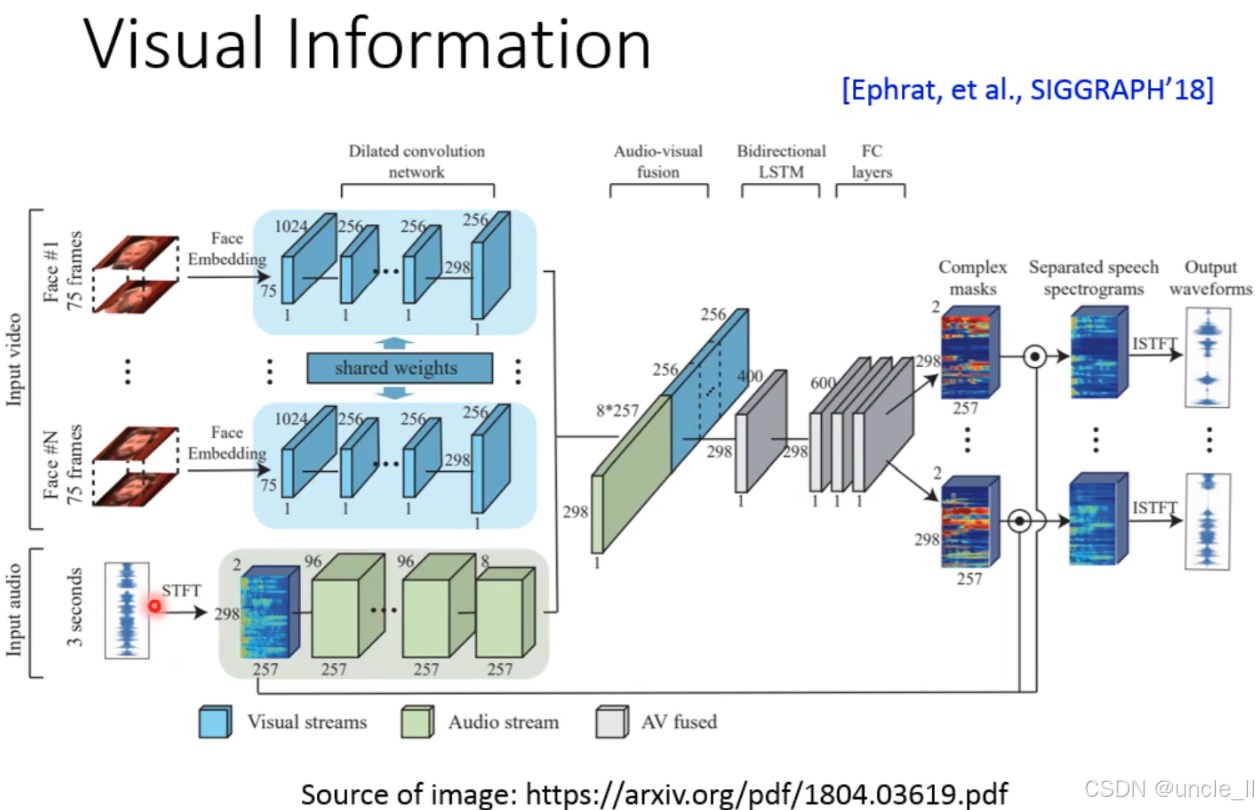
视听融合(Audio-Visual Fusion)的语音分离框架,核心是结合人脸视觉信息和音频信息,提升多说话人场景下的分离效果,由 Ephrat 等人在 SIGGRAPH 2018 提出。以下是分层解析:
一、核心目标:视听协同分离多说话人语音
- 问题:纯音频分离易受混响、噪声干扰,加入人脸视觉信息(如说话人身份、唇动同步性)可辅助区分不同说话人。
- 输入:
- 视觉流(Input video):多个说话人的面部视频(Face #1~#N);
- 音频流(Input audio):混合语音(含多个说话人)。
- 输出:分离后的纯净语音波形(Output waveforms)。
二、流程拆解:视觉流与音频流的融合
(1)视觉流处理(Visual Streams)
- 输入:每个说话人的面部视频(75 帧 / 人脸)→ 提取人脸嵌入(Face Embedding)(75 维特征,代表面部身份 / 特征)。
- 扩张卷积网络(Dilated Convolution Network):
用共享权重(shared weights)的卷积层,学习人脸的时序特征(如唇动、表情变化),输出 298 维视觉特征。
(2)音频流处理(Audio Stream)
- 输入:3 秒混合音频 → 短时傅里叶变换(STFT)→ 生成时频谱(298×257 维)。
- 卷积网络:
用卷积层提取音频的频谱特征(257 维→96 维→8 维),输出 298 维音频特征。
(3)视听融合(AV Fused)
- 融合方式:视觉特征(298 维)+ 音频特征(298 维)→ 拼接后通过双向 LSTM捕捉时序依赖 → 全连接层(FC layers)优化特征。
- 生成掩码(Complex masks):
输出与说话人数量对应的掩码(图中 2 个掩码),用于分离时频谱。
(4)语音重建(Separated speech waveforms)
- 掩码作用:掩码与混合时频谱逐点相乘 → 分离出每个说话人的时频谱 → 逆短时傅里叶变换(ISTFT)→ 重建时域波形。

一、核心问题:优化目标的分歧
语音增强(Speech Enhancement)和说话人分离(Speaker Separation)的结果,最终使用者可能是人或机器,需针对性优化:
- 为人耳(for human):追求 “人能听懂、听着舒服”;
- 为机器(for machine):追求 “机器下游任务(如 ASR、说话人验证)表现好”。
二、为人耳的优化(for human)
(1)关注指标
- Quality(质量):语音的主观听感(如是否有杂音、失真);
- Intelligibility(可懂度):人能否理解语音内容(如嘈杂环境下的对话)。
(2)传统优化方法
- 指标:STOI(短时客观可懂度)、PESQ( perceptual evaluation of speech quality ,语音质量感知评估)。
- 难题:这些指标不可微分(Non-differentiable),无法直接用于端到端训练(需设计代理损失)。
三、为机器的优化(for machine)
(1)关注下游任务
- ASR(自动语音识别):机器将语音转文字的准确率;
- Speaker Verification(说话人验证):机器判断 “是否为目标说话人” 的准确率。
(2)优化思路
- 直接优化下游系统的性能(如 ASR 的 WER、说话人验证的 EER),让语音增强 / 分离的结果更适配机器需求。

- Denoise Wavnet [Rethage, et al., ICASSP’18]
- 核心:基于 WaveNet 架构的端到端时域降噪模型,直接从含噪语音波形生成纯净语音。
- 创新:使用扩张因果卷积捕捉长时语音依赖,无需时频转换(如 STFT),避免相位失真。
- 应用:单通道语音降噪(如手机通话、录音降噪)。
- Chimera++ [Wang, et al., ICASSP’18]
- 核心:改进 Chimera 网络,结合深度聚类(Deep Clustering)和时频掩码(Time-Frequency Masking),实现多说话人分离。
- 创新:引入 “吸引子(Attractor)” 机制动态聚合相似时频点,提升分离精度。
- 应用:2-3 人混合语音分离(如会议录音分离)。
- Phase Reconstruction Model [Wang, et al., ICASSP’19]
- 核心:解决传统分离中 “相位信息丢失” 问题,提出基于深度学习的相位重建方法。
- 创新:用循环网络(RNN)从幅度谱预测相位谱,或直接学习复数掩码(含幅度 + 相位)。
- 价值:相位准确重建可显著提升分离语音的自然度(降低 “金属音” 失真)。
- Deep Complex U-Net: Complex masking [Choi, et al., ICLR’19]
- 核心:首个全复数域 U-Net 模型,直接在复数时频谱上进行掩码操作(含实部 + 虚部)。
- 创新:复数卷积层保留相位信息,生成复数掩码而非传统实值掩码,分离性能超越实数域方法。
- 应用:语音分离、音乐源分离(需精确相位信息的场景)。
- Deep CAS A: Make CAS A great again! [Liu, et al., TASLP’19]
- 核心:将传统计算听觉场景分析(CASA)的 “分组 - 跟踪” 逻辑用深度学习实现,端到端优化。
- 创新:模拟人类听觉系统的 “语音分组” 机制,提升低信噪比(SNR)下的鲁棒性。
- 性能:在 WSJ0-2mix 数据集上实现 17.7 dB ΔSI-SDR,超越早期 Conv-TasNet。
- Wavesplit: state-of-the-art on benchmark corpus WSJ0-2mix [Zeghidour, et al., ArXiv’20]
- 核心:基于自监督学习的语音分离模型,通过 “对比学习” 预训练语音特征,再微调分离任务。
- 创新:无需人工标注,从海量无标签语音中学习通用特征,迁移到分离任务性能显著提升。
- SOTA 性能:WSJ0-2mix 数据集上 ΔSI-SDR 达 19.0 dB,结合动态混合数据增强后达 20.4 dB。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 23
23 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)