
牛津、上AI Lab重磅综述:Agentic RL,一文看懂AI智能体的进化路线图
本文系统梳理了智能体强化学习(Agentic RL)这一新兴领域,该领域将大型语言模型(LLM)从被动序列生成器转变为能在复杂动态环境中自主决策的智能体。研究通过马尔可夫决策过程(MDP)和部分可观察马尔可夫决策过程(POMDP)严格区分了Agentic RL与传统LLM强化学习,并提出了基于智能体核心能力(规划、工具使用等)和应用任务的双重分类法。论文指出强化学习是实现这些能力从静态模块转变为自
一、导读
本文系统性地梳理了智能体强化学习(Agentic Reinforcement Learning)这一新兴领域。随着大型语言模型(LLM)与强化学习(RL)的深度融合,研究范式正从将LLM视为被动的序列生成器,转变为将其塑造为能够在复杂动态世界中自主决策的智能体。当前研究面临术语不统一、评估标准不一致的挑战,导致难以进行系统性比较。为解决此问题,本文首先通过马尔可夫决策过程(MDP)和部分可观察马尔可夫决策过程(POMDP)的数学形式,严格区分了Agentic RL与传统的LLM-RL。在此基础上,论文提出了一个全面的双重分类法:一个围绕智能体的核心能力(如规划、工具使用、记忆、推理等),另一个则围绕具体应用任务。论文的核心论点是,强化学习是将这些能力从静态模块转变为自适应、鲁棒的智能体行为的关键机制。通过整合超过五百篇近期文献及相关开源资源,本综述清晰地勾勒了该领域的版图、挑战与未来机遇,为开发可扩展的通用人工智能代理指明了方向。
二、论文基本信息

基本信息
-
论文标题:The Landscape of Agentic Reinforcement Learning for LLMs: A Survey (LLM的智能体强化学习版图:一篇综述)
-
作者:Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, Yifan Zhou, Yang Chen, Chen Zhang, Yutao Fan, Zihu Wang, Songtao Huang, Yue Liao, Hongru Wang, Mengyue Yang, Heng Ji, Michael Littman, Jun Wang, Shuicheng Yan, Philip Torr, Lei Bai
-
作者单位:牛津大学、上海人工智能实验室、新加坡国立大学、伦敦大学学院等多个顶尖学术机构。
摘要精炼
本综述旨在正式定义并梳理Agentic RL这一新兴范式,它将LLM从被动的序列生成器重塑为在复杂动态世界中自主决策的智能体。研究的核心问题是,如何区别并构建这一新范式。为此,论文首先将传统LLM-RL的退化单步MDP与定义Agentic RL的时序扩展、部分可观察的POMDP进行了形式化对比。基于此,论文提出了一个双重分类法:一个围绕核心智能体能力(规划、工具使用、记忆、推理、自我提升和感知),另一个则围绕它们在不同任务领域的应用。论文的核心技术贡献在于,明确指出强化学习是激活这些能力,使其从静态启发式模块转变为自适应、鲁棒的智能体行为的关键。通过整合超过五百篇最新文献,并汇编了开源环境、基准和框架,本综述系统地描绘了这一快速发展领域的轮廓,并指出了构建可扩展通用AI智能体所面临的机遇与挑战。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/UjHCQ7OyigJ-daRK8zFlkA
https://mp.weixin.qq.com/s/UjHCQ7OyigJ-daRK8zFlkA
三、研究背景与相关工作
研究背景
LLM与RL的融合正在经历一场深刻的范式变革。早期方法(如传统的LLM-RL)将LLM视为静态的文本生成器,主要优化其单轮输出以符合人类偏好或在静态基准上取得高分。这种模式虽然在对齐和指令遵循方面取得了成功,但其根本局限性在于忽略了现实世界中序贯决策的本质。这些模型无法在动态、部分可观察的环境中进行长期规划、与工具交互或从经验中自适应学习。因此,研究界迫切需要一个新的理论框架来指导如何将LLM从被动的“文本发射器”转变为能够自主感知、推理、规划和行动的“智能体实体”。这正是本文提出Agentic RL范式的动机。
相关工作
作者将相关研究分为两大主线:
-
LLM智能体 (LLM Agents): 此类研究侧重于将LLM作为自主决策的核心,探索其架构、协作机制和进化路径。现有综述关注其推理、行动和交互的核心能力,特别是工具使用(如RAG和API调用)和规划策略(如plan-execute-reflect循环)。虽然这些工作探索了LLM“能做什么”,但它们通常缺乏一个统一的学习和优化框架。
-
用于LLM的强化学习 (RL for LLMs): 此类研究主要利用RL算法(如PPO、DPO)来对齐LLM的价值观或提升其在特定任务(如代码生成)上的性能。最突出的应用是基于人类反馈的强化学习(RLHF)及其变种。然而,这些方法大多仍停留在优化单轮输出质量的层面,并未将LLM置于一个连续的、与环境交互的决策循环中。
作者指出,尽管两个方向都取得了进展,但缺乏一个将两者结合的统一视角,即如何系统地使用RL来优化一个在序贯决策过程中运行的LLM智能体。这正是本综述试图填补的研究空白。
四、主要贡献与创新
-
形式化定义: 首次使用MDP和POMDP的数学语言,严格区分了Agentic RL与传统的偏好基强化微调(PBRFT),从理论上阐明了其作为序贯决策问题的本质。
-
双重分类法: 提出了一个全面的双重分类系统(如
图1所示)。第一个维度从能力视角出发,系统梳理了RL如何赋能规划、工具使用、记忆、推理、自我提升和感知等六大核心智能体能力(如图4所示);第二个维度从任务视角出发,详细阐述了Agentic RL在搜索、编码、数学、GUI导航等多个领域的具体应用(如图6所示)。
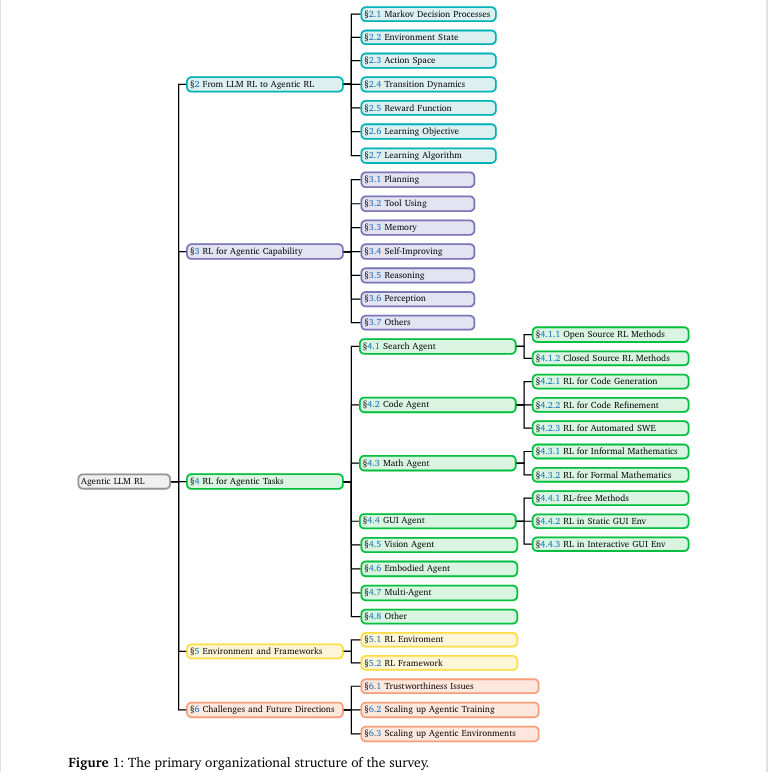
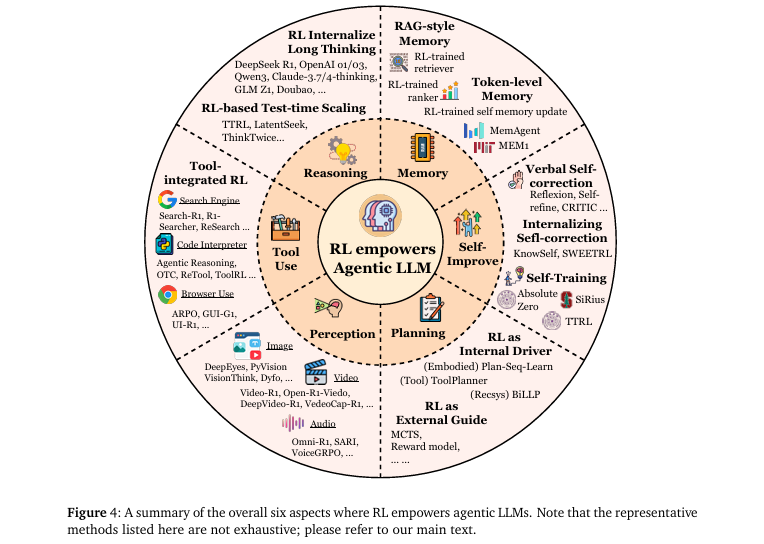
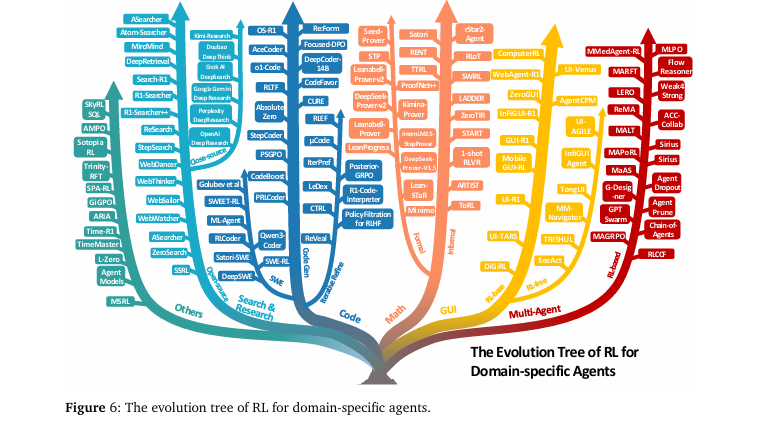
-
算法与资源整合: 系统性地梳理了Agentic RL中主流的RL算法家族(如PPO, DPO, GRPO),并对比了其代表性变体(如
表2所示)。同时,整合了支持智能体训练和评估的开源环境、基准测试和框架,为研究者提供了宝贵的实践指南。
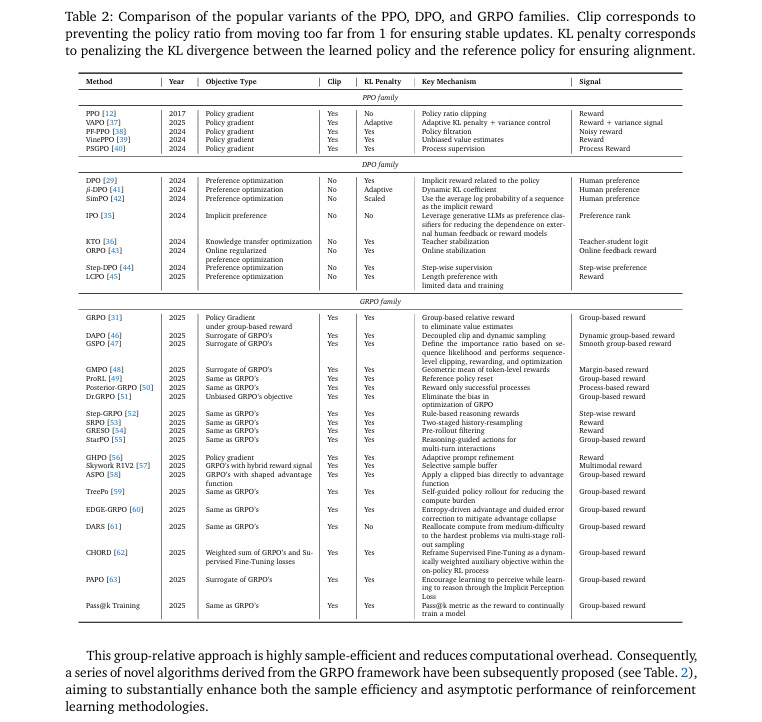
-
系统性综述: 综合分析了超过五百篇相关论文,为这个快速发展但定义尚显混乱的领域提供了一个清晰、连贯的知识图谱,并明确了未来的核心挑战与研究方向。
五、研究方法与原理
总体框架与核心思想
本文的核心思想是将Agentic RL确立为一个区别于传统LLM-RL的独立研究范式。其总体框架(概括于图3)将LLM智能体置于一个与动态环境交互的闭环中,该智能体由规划、推理、记忆、感知、工具使用和自我提升等模块构成。强化学习是优化此闭环系统的核心引擎。
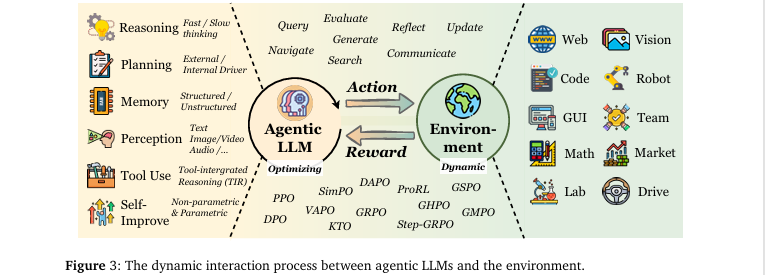
该方法的设计哲学是通过形式化对比来建立概念边界。作者没有提出一种新算法,而是通过数学建模(MDP/POMDP)来清晰地界定Agentic RL的范围。它将传统的、以对齐为目的的RFT(如RLHF)建模为退化的单步MDP,而将Agentic RL建模为时序扩展的POMDP。这种“鸟瞰式”的定义使得研究者能迅速理解Agentic RL的核心特征:它不是关于生成更好的单句回复,而是关于学习在不确定环境中执行长期任务的最优策略。
关键实现与评估原理
关键实现细节
本文的关键“实现”是其对PBRFT和Agentic RL的形式化区分,具体体现在MDP/POMDP元组的定义上。表1对此进行了详细对比。
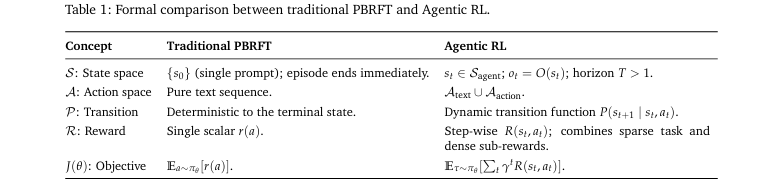
- PBRFT的实现 (退化MDP):
-
状态空间 只有一个初始状态
prompt,决策步长 。 -
动作空间 仅限于生成纯文本序列。
-
状态转移是确定性的,奖励 是对整个生成序列的单个标量评分。
-
- Agentic RL的实现 (POMDP):
-
状态空间 是动态演化的世界状态 ,智能体接收到的是部分观察 ,决策步长 。
-
动作空间 包含文本生成和结构化动作(如工具调用)。
-
状态转移是随机的,由环境动态决定。
-
奖励函数 可以是稀疏的任务完成信号,也可以是密集的步骤级子任务奖励。
-
核心评估原理与指标
本文的核心“评估”体现在对两种范式优化目标的根本性区别上。
-
PBRFT的目标函数旨在最大化单步生成的期望奖励,本质上是序列级别的奖励建模。
-
Agentic RL的目标函数旨在最大化长期折扣累积奖励,需要解决探索和长期信用分配问题。
为了实现这些目标,论文梳理了多种RL算法,如近端策略优化(PPO)、直接偏好优化(DPO)和新兴的组相对策略优化(GRPO)。表2详细对比了这些算法家族的变体,解释了它们在削减策略更新、KL惩罚和所需奖励信号类型上的不同设计,为研究者选择合适的优化算法提供了依据。
六、实验结果与分析
由于本文是一篇综述,它没有传统的数值实验。其核心“实验”是通过形式化分析来论证Agentic RL与传统PBRFT的范式差异。我们选择第2节的理论对比作为核心分析内容。
实验设置
-
核心设置: 对比偏好基强化微调 (PBRFT) 和 智能体强化学习 (Agentic RL) 两个理论框架。
-
评估指标: 构成决策过程的七个关键元素: 状态空间(S)、观察空间(O)、动作空间(A)、状态转移概率(P)、奖励函数(R)、任务时长(T)和折扣因子(γ)。
-
对比基线: 将PBRFT建模为一个退化的单步MDP。
-
关键参数: 任务时长 (Horizon) (1 vs T>1) 和 折扣因子 (Discount Factor) (不存在 vs 0<γ<1)。
核心实验与结论
-
实验目的: 该分析旨在从理论层面严格地区分Agentic RL与PBRFT的本质区别,证明前者是一个更通用的、处理序贯决策问题的框架。
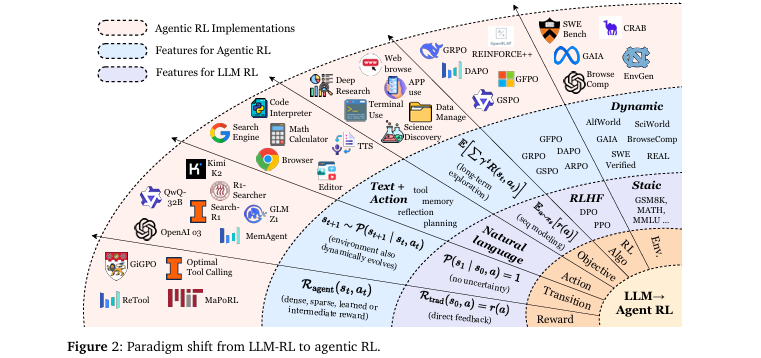
图2直观展示了这一范式变迁。
- 关键结果:
-
状态与交互: PBRFT处理的是一个静态、单步的交互(),从一个
prompt状态直接到终止状态。而Agentic RL处理的是一个动态、多步、部分可观察的交互(),智能体根据观察 在不断变化的状态 中行动。 -
动作空间: PBRFT的动作空间是纯文本。Agentic RL的动作空间更丰富,包括文本生成和调用工具的结构化动作。
-
奖励与目标: PBRFT的奖励是针对最终输出的单个标量,其目标是最大化单次期望奖励。Agentic RL的奖励可以是步骤级的,其目标是最大化整个交互过程的长期累积折扣奖励,这需要进行信用分配和探索。
-
-
作者结论: 作者基于此形式化分析得出结论:Agentic RL不仅仅是RL在LLM上的简单应用,而是一次根本性的范式转移。它将优化的焦点从“生成高质量的文本”转向了“学习在复杂环境中完成任务的有效策略”,从而为构建更自主、更通用的AI智能体奠定了理论基础。
七、论文结论与启示
总结
本综述成功地定义并系统化了Agentic RL这一新兴领域。论文首先通过MDP/POMDP的形式化方法,清晰地界定了Agentic RL与传统LLM-RL的理论边界,指明前者是处理多步、动态、部分可观察环境下序贯决策的通用框架。随后,论文构建了一个能力-任务双重分类法,全面梳理了RL如何赋能智能体的各项核心能力,并展示了其在多个应用领域的实践进展。最后,通过整合相关的算法、环境和基准,本文不仅为研究者提供了一个清晰的知识图谱,也为后续研究提供了坚实的起点,有力地推动了该领域从零散探索走向系统性发展。
展望
论文在第6节指出了该领域面临的开放性挑战和未来方向,主要包括:
- 可信度 (Trustworthiness):
-
安全性: Agentic RL因其与外部工具和环境的交互,引入了更复杂的攻击面(如间接提示注入)。RL的优化目标可能驱使智能体学习不安全的“捷径”行为(奖励黑客)。未来的研究需聚焦于沙盒化、设计更安全的奖励函数和对抗性训练。
-
幻觉与谄媚: RL可能加剧幻觉,因为模型会为了最终奖励而编造看似合理的中间步骤。同时,为了迎合人类偏好反馈,模型也可能产生“谄媚”行为。未来的方向包括开发过程感知的奖励模型和能够平衡客观性与用户偏好的训练机制。
-
- 扩展智能体训练 (Scaling up Agentic Training):
-
计算与效率: 延长RL训练能够显著提升智能体的推理能力,但计算成本巨大。未来的研究需探索更高效的RL算法和训练策略,例如在有限数据下实现泛化的方法。
-
数据与模型: 跨领域数据训练存在协同和冲突效应。如何精心策划多领域数据,以促进正向迁移并避免能力退化,是扩展训练规模的关键。
-
- 扩展智能体环境 (Scaling up Agentic Environment):
-
现有环境(如ALFWorld)对于训练通用智能体已显不足。未来的一个重要方向是环境本身的自适应演化,例如通过程序化内容生成(PCG)自动创造能弥补智能体能力短板的新任务,形成智能体与环境共同进化的“训练飞轮”。
-
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/UjHCQ7OyigJ-daRK8zFlkA
https://mp.weixin.qq.com/s/UjHCQ7OyigJ-daRK8zFlkA

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)