
python 爬虫(起点)网络小说
1 先确定要爬取的小说是get 请求换是post 请求1.1先在网站上打开一篇小说:1.2 f12 进去开发者模式1.3 切换到NetWork 发现有一个空白,可以点击左侧的小说内容点击之后可以看到显示内容了如下然后点击一下,可以看到请求的方式了确认是get 请求之后,先确认电脑上是否下载2个工具 requests(负责连接网站处理http 协议) 和 bs4(bs4负责将网页变成结构化数据)没有
·
1 先确定要爬取的小说是get 请求换是post 请求
1.1先在网站上打开一篇小说:
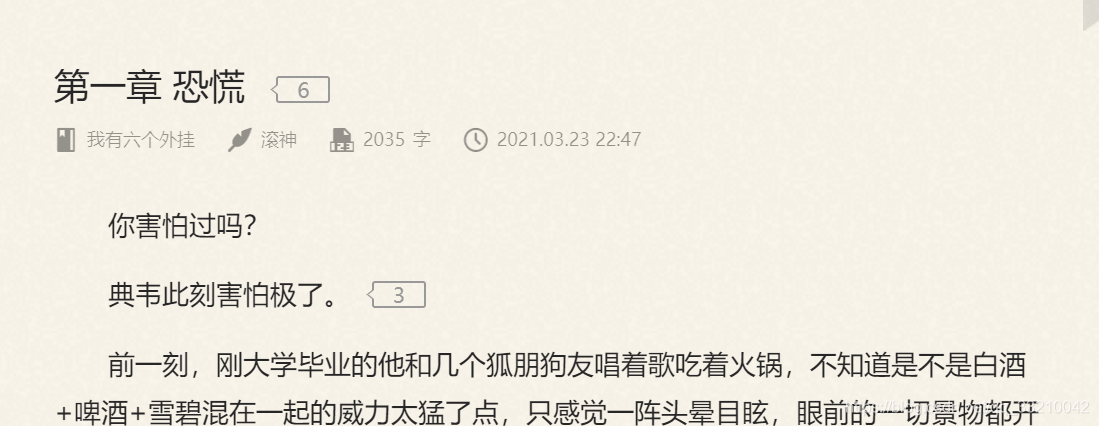
1.2 f12 进去开发者模式
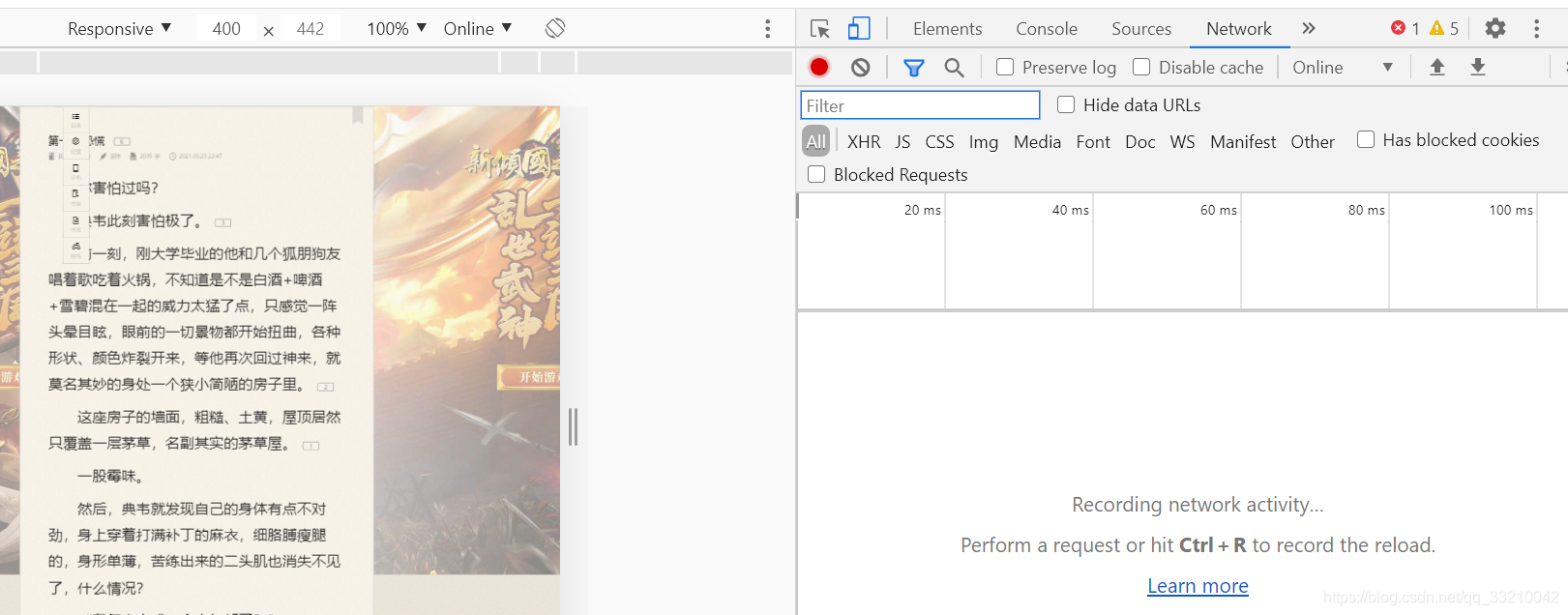
1.3 切换到NetWork 发现有一个空白,可以点击左侧的小说内容
NetWork 中间有没有连接的,我是重新打开然后重新f12 查看
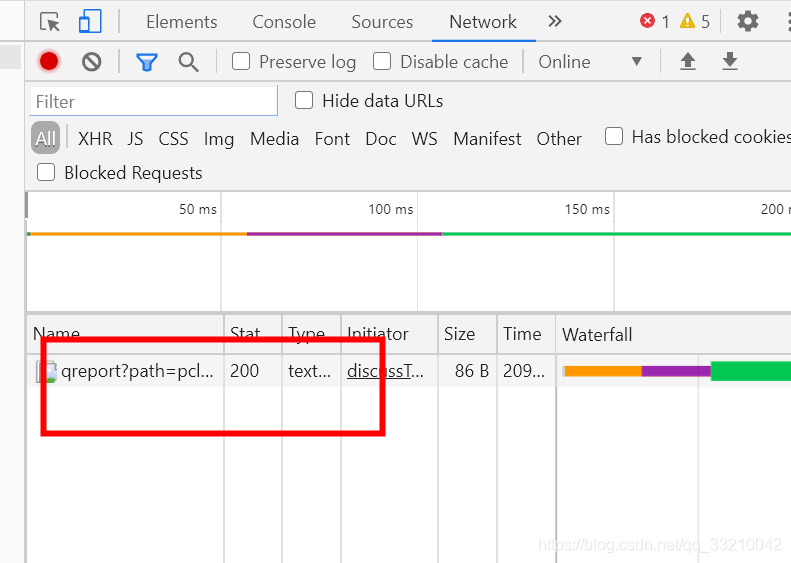
一般都是可以看到Name 下面有连接的
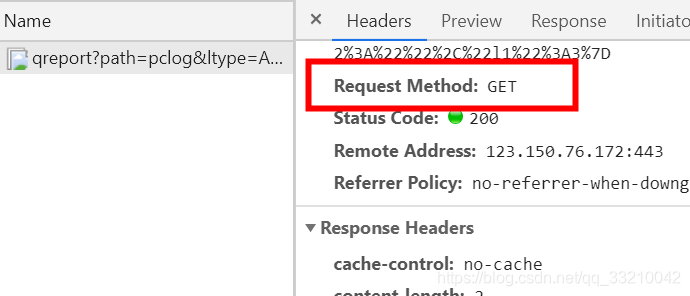
确认是get 请求之后,先确认电脑上是否下载2个工具 requests(负责连接网站处理http 协议) 和 bs4(bs4负责将网页变成结构化数据)
没有的话可以下载 终端中使用 pip install requests , pip install beautifulsoup4 下载,或者使用其他工具easy_install 下载
准备好之后开始写代码,
下面代码都有注释,代码很少就不多说了,
# 负责连接网站处理http 协议
import requests
# bs4负责将网页变成结构化数据
from bs4 import BeautifulSoup
def getContent():
# 定义一个url
url = "https://read.qidian.com/chapter/tlBx1lEZoo3djrstIrF5-w2/-hwjPfM_yFT6ItTi_ILQ7A2"
# 获取网页的url
req_url = requests.get(url)
# 获取网页html信息
req_html = req_url.text
# bs4 处理
bs_obj = BeautifulSoup(req_html, "html.parser")
# find_all 匹配 div 和 class
texts = bs_obj.find_all("div", class_="read-content j_readContent")
# 使用text属性 过滤文字
print(texts[0].text)
if __name__ == "__main__":
getContent()运行效果如下


技术共进,成长同行——讯飞AI开发者社区
更多推荐

 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)