
数学建模系列_随机森林
数学建模备赛内容62 随机森林模型基本原理_哔哩哔哩_bilibili什么是随机森林随机森林是一种集成学习方法,通过组合多个决策树来解决分类和回归问题。每棵树都是根据随机选择的训练数据和特征构建的,最终的预测结果是基于多个树的投票(分类问题)或平均(回归问题)得出的。随机森林具有良好的泛化能力、鲁棒性和高效性,适用于各种机器学习任务。本质属于集成学习方法、由多棵决策树组成,每棵决策树都是一个分类器
数学建模系列_随机森林
文章目录
【前言】
数学建模备赛内容
【回顾】
【简介】
什么是随机森林
随机森林是一种集成学习方法,通过组合多个决策树来解决分类和回归问题。每棵树都是根据随机选择的训练数据和特征构建的,最终的预测结果是基于多个树的投票(分类问题)或平均(回归问题)得出的。随机森林具有良好的泛化能力、鲁棒性和高效性,适用于各种机器学习任务。
【正文】
(一)理论部分
1. 随机森林的定义与特征
定义:
本质属于集成学习方法、由多棵决策树组成,每棵决策树都是一个分类器,将多个分类器的结果进行投票。

特征:
(1)具有极高的准确率
(2)能够使用在大数据上
(3)不需要降维
(4)能够评估重要性

2. 集成学习
(1)定义
集成学习(Ensemble Learning)是一种机器学习技术,它旨在通过结合多个弱学习器(或基本模型)的预测结果来提高整体预测的准确性和鲁棒性。集成学习的核心思想是将多个模型的意见汇总起来,以产生更强大的集成模型,从而降低过拟合的风险,提高泛化能力,并在各种机器学习任务中表现出色。

(2)特点与原理
- 弱学习器:集成学习通常使用弱学习器作为基本模型,这些模型可能相对简单,其性能略高于随机猜测。弱学习器可以是决策树、逻辑回归、神经网络的一层等。
- 多样性:集成学习通过确保每个弱学习器具有一定程度的多样性,即它们的预测错误不完全重叠。这可以通过不同的训练数据、不同的特征子集、不同的模型或不同的训练算法来实现。
- 集成方法:集成学习采用不同的集成方法来结合弱学习器的预测结果。常见的集成方法包括投票法(Voting)、Bagging、Boosting、随机森林等。每种方法都有不同的组合策略,例如平均、投票、加权平均等。
- 降低方差:通过将多个模型的预测结果结合起来,集成学习可以降低模型的方差,从而提高模型的鲁棒性。这有助于减少模型对训练数据中的噪声和变化的敏感性。
- 提高性能:通过集成多个弱学习器的意见,集成学习可以显著提高整体性能,特别是在复杂任务和大规模数据集上。
- 适用性广泛:集成学习可用于各种机器学习任务,包括分类、回归、特征选择、异常检测等。
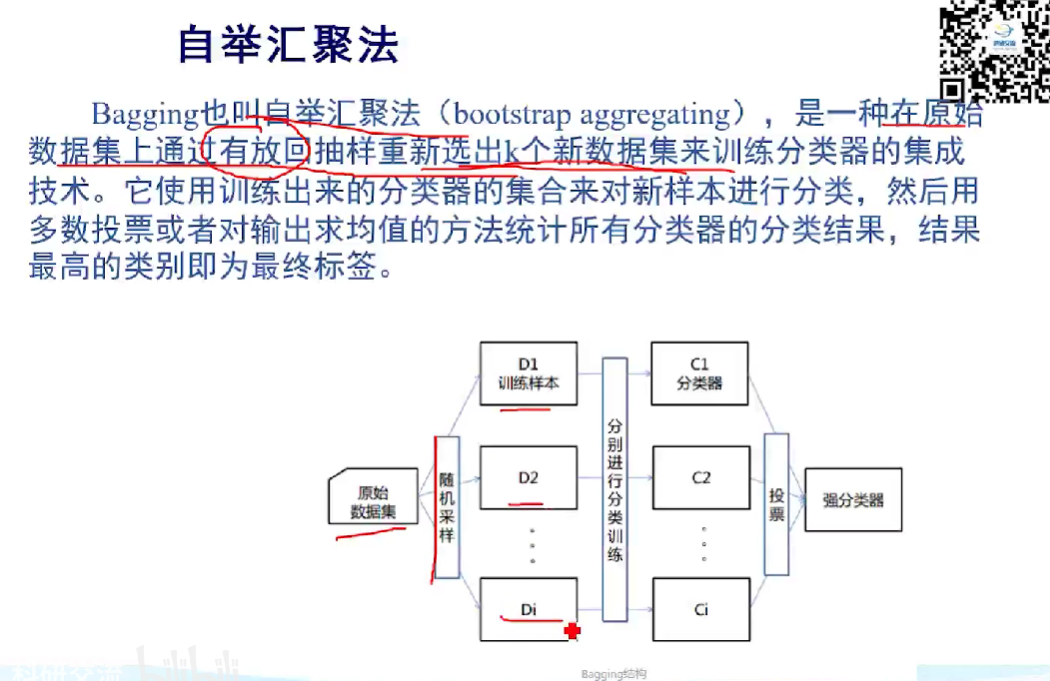
补充:自举汇聚法(Bagging)
Bagging的步骤如下:
Bootstrap 抽样:从原始训练数据集中随机有放回地抽取多个子数据集,每个子数据集的大小通常与原始数据集相同,但它们的样本是随机选择的。这意味着一些样本可能在多个子数据集中出现,而一些样本可能根本不出现。
独立模型训练:使用每个子数据集独立地训练一个弱学习器或基本模型(通常是决策树、逻辑回归等)。由于每个子数据集都是随机抽样的,因此每个模型都是基于不同的样本集训练的,具有一定的差异性。
预测组合:对于分类问题,Bagging 通过对多个子模型的分类结果进行多数投票来确定最终的分类结果。对于回归问题,Bagging 通过对多个子模型的回归结果进行平均来得出最终的回归值。
Bagging 的优势包括:
- 减少模型的方差:通过组合多个模型的预测结果,Bagging 可以减少单个模型的方差,提高模型的鲁棒性和泛化能力。
- 防止过拟合:由于每个子模型都是在不同的数据子集上训练的,Bagging 有助于减少模型对训练数据中的噪声和局部特征的过拟合。
- 并行化:每个子模型的训练是独立的,因此 Bagging 很容易并行化,提高了训练效率。
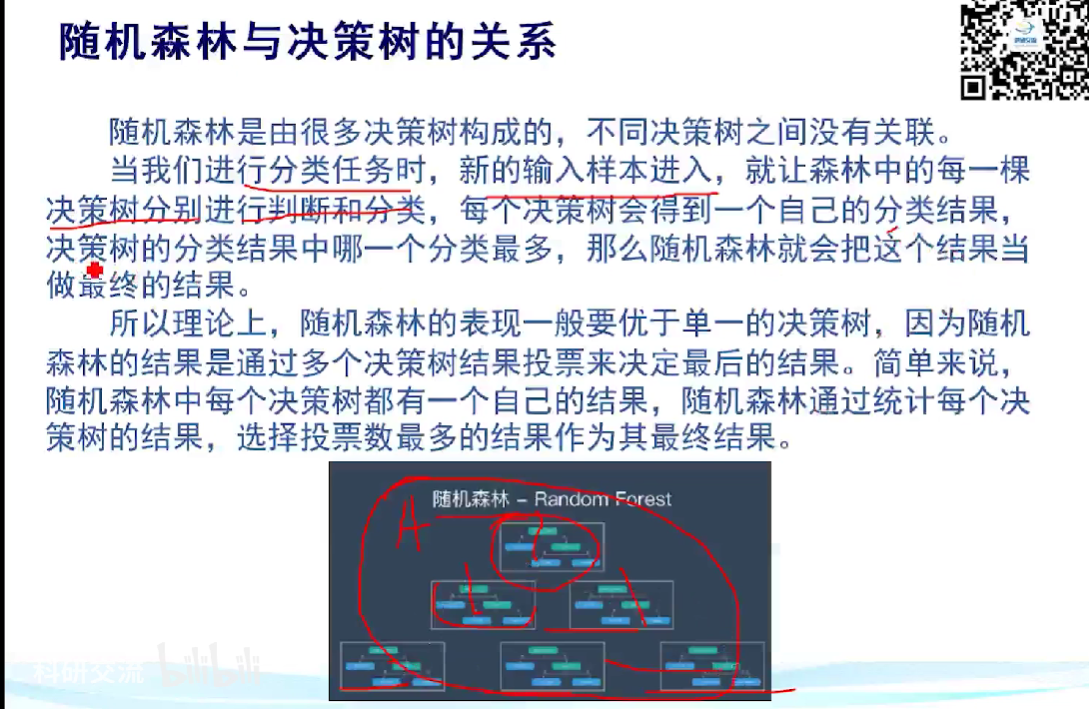
3. 随机森林与决策树的关系
随机森林由多个决策树组成,不同决策树之间没有关系,通过统计多个决策树并投票得到最终结果。
回顾:数学建模系列_决策树
4. 构造随机森林的步骤
(1)主要步骤
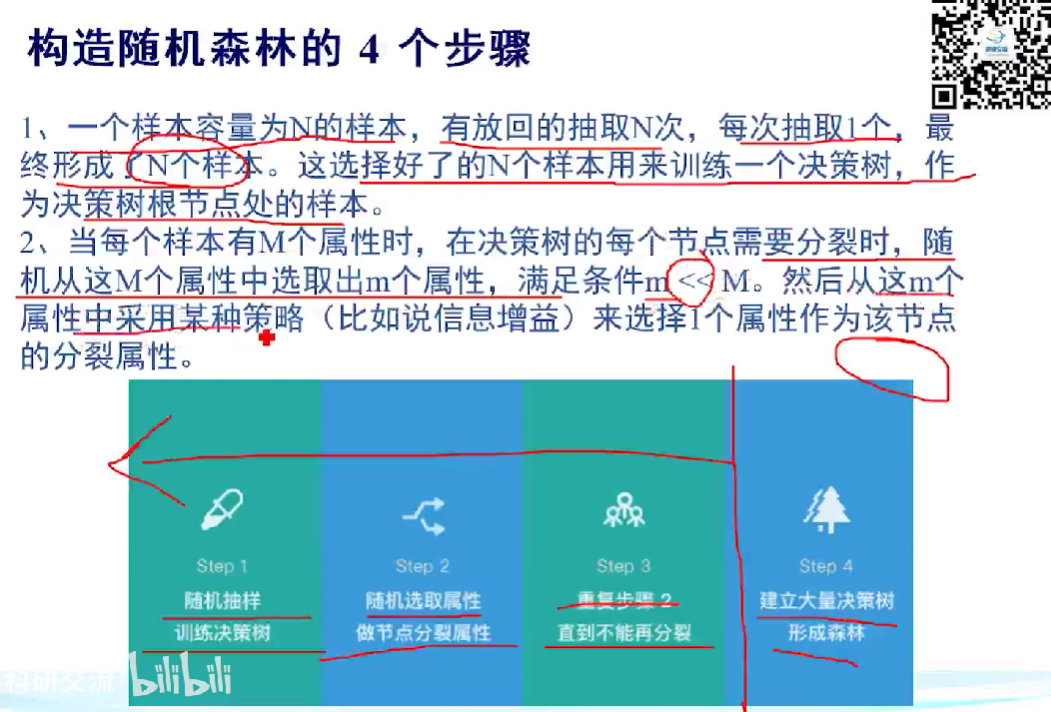

(2)详细步骤
- 收集训练数据集:首先,收集包含特征和相应标签的训练数据集。这些数据将用于随机森林的训练。
- Bootstrap 抽样:从训练数据集中使用自助法(Bootstrap Sampling)随机有放回地抽取多个子数据集。这些子数据集的大小通常与原始数据集相同,但它们的样本是随机选择的,有些样本可能在多个子数据集中出现,而有些可能不出现。
- 构建决策树:针对每个子数据集,独立地构建一棵决策树。通常使用特定的决策树算法(如CART)来训练每棵树,但在这里的关键是,每个决策树只使用子数据集的一部分样本和一部分特征进行训练。这种随机性确保了每棵树都是不同的。
- 集成多棵树:在构建足够多的决策树后,将它们组合起来形成随机森林。对于分类问题,通常采用多数投票法(Majority Voting),即通过统计每棵树的分类结果来确定最终的分类结果。对于回归问题,通常采用平均法,即取多棵树的回归结果的平均值。
- 评估性能:使用验证数据集或交叉验证等方法来评估随机森林的性能。可以使用一些指标如准确度、均方根误差(RMSE)等来评估模型的性能。
- 调整参数:根据性能评估的结果,可以调整随机森林的参数,如树的数量、每棵树的最大深度、特征采样比例等,以优化模型的性能。
- 使用随机森林:一旦构建好随机森林模型并满意性能,就可以将其应用于新的未见数据进行分类或回归预测。
- 可选的特征重要性评估:随机森林可以提供特征的重要性评估,帮助识别哪些特征对于模型的预测最重要。这可以用于特征选择或问题理解。
5. 随机森林的优缺点:
(1)优点:
- 无需降维、无需特征筛选
- 可以判断特征重要程度
- 容易并行处理
(2)缺点:
- 对于不平衡的数据,容易过拟合
- 取值划分较多的属性会对随机森林产生较大的影响
例如:身份证号/手机号码,取值划分较大且没有依据,随机森林对此类数据产出的属性权值是不可信的。
(二)实践操作
1. 应用于特征筛选
随机森林可以对特征的重要性进行评估

(1)影响因素:
-
两棵树的相关性
-
每棵树的分类能力

(2)以UCI Raisin数据集为例
导入相关包
import numpy as np
import pandas as pd
from ucimlrepo import fetch_ucirepo
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
获取UCI Raisin数据集
# fetch dataset
raisin = fetch_ucirepo(id=850)
# data (as pandas dataframes)
X = raisin.data.features
y = raisin.data.targets
# metadata
print(raisin.metadata)
# variable information
print(raisin.variables)
查看输入属性与输出属性
X.info()
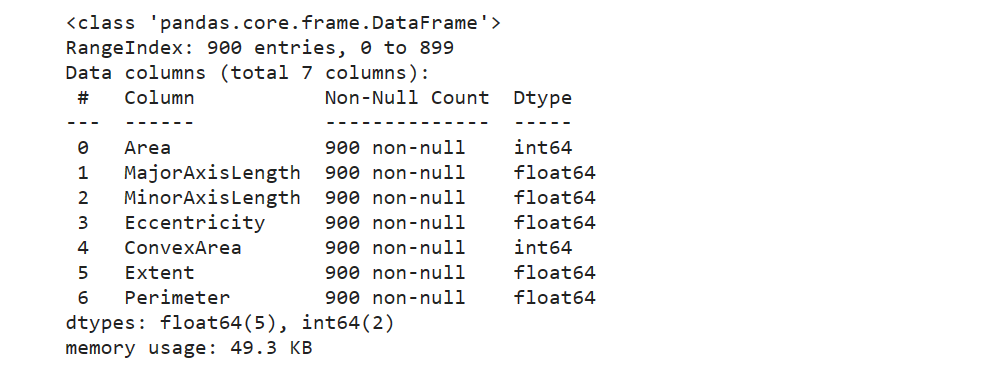
y.info()
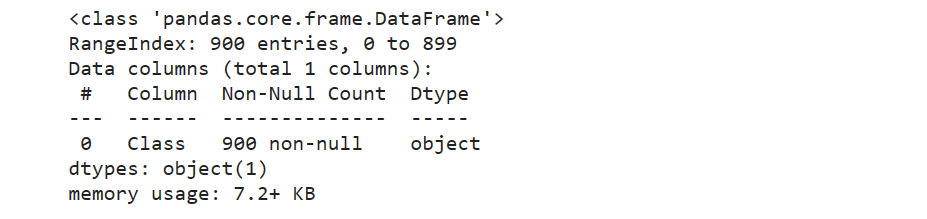
发现是object数据类型,进行字典编码
def change_object_cols(se):
value = se.unique().tolist()
value.sort()
return se.map(pd.Series(range(len(value)), index=value)).values
y['Class'] = change_object_cols(y['Class'])
y.info()
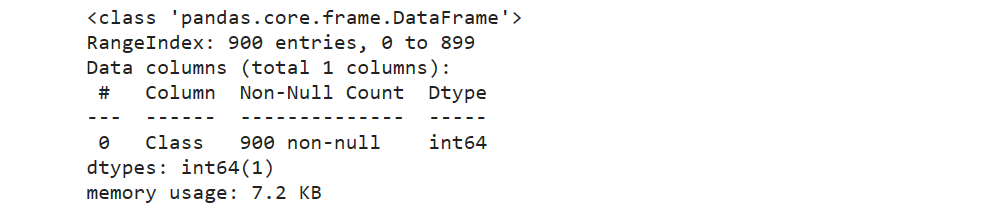
全部转换为0、1编码
y['Class'].values
将数据集分为训练集与测试集,放入随机森林模型中进行训练
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
y_train = y_train.values.ravel()
rf = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=1)
rf.fit(x_train, y_train)
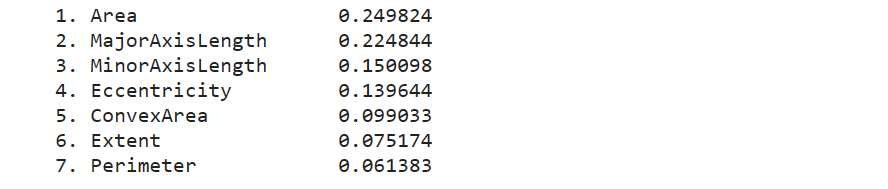
输出特征重要性排序
imp = rf.feature_importances_
indices = np.argsort(imp)[::-1]
for f in range(x_train.shape[1]):
print("%2d. %-*s %f" % (f + 1, 20, x_train.columns[f], imp[indices[f]]))
2. 应用于分类任务
以kaggle上的Titanic比赛数据集为例,此处代码仅作演示,完整流程请参考Kaggle_Titanic比赛
使用随机森林分类器进行建模
RandomizedSearchCV 的参数空间
n_estimators: 树的数量。这是随机森林中决策树的数量。增加树的数量通常会提高模型的性能和稳健性,但也会增加计算成本和时间。min_samples_leaf: 叶节点最少样本数。这是每个叶子节点(树的最底部节点)所需的最小样本数。增加这个参数的值会使模型变得更加保守,可以减少过拟合的风险。min_samples_split: 分裂内部节点所需的最小样本数。这是树在继续分裂一个内部节点之前所需的最小样本数。增加这个值可以防止模型学习过于复杂的树结构,也有助于防止过拟合。max_depth: 树的最大深度。这是树可以增长的最大深度。限制树的深度有助于减少模型的复杂性,避免过拟合。max_features: 寻找最佳分割时要考虑的特征数量。它决定了在分割一个节点时,随机森林会考虑多少个特征。可以是整数(直接指定数量),浮点数(作为总特征数的比例),“auto”(等于sqrt(n_features)),“sqrt”(同“auto”),“log2”(等于log2(n_features))。class_weight: 类别的权重。这个参数用于处理类别不平衡的问题。如果设置为“balanced”,算法将自动根据输入数据中的类频率为每个类别分配权重。“balanced_subsample” 类似于 “balanced”,但是权重是基于每棵树的数据样本计算的,而不是整个数据集。
# 在建模时,去除PassengerId与Survived字段
features = train.columns.tolist()
features.remove('PassengerId')
features.remove('Survived')
# 定义随机搜索的参数范围
random_grid = {
'n_estimators': np.arange(1, 20, 1),
'max_features': ['auto', 'sqrt'],
'max_depth': np.arange(1, 10, 1),
'min_samples_split': np.arange(30, 100, 5),
'min_samples_leaf': np.arange(30, 100, ),
'class_weight': ['balanced', 'balanced_subsample']
}
# 初始化随机森林分类器
rf = RandomForestClassifier()
# 随机搜索对象
rf_random = RandomizedSearchCV(rf, random_grid, n_iter=400, cv=2, verbose=2, n_jobs=-1, scoring='accuracy')
# 拟合随机搜索模型
rf_random.fit(train[features].values, train['Survived'].values)
# 查看最佳参数组合
print(rf_random.best_score_)
print(rf_random.best_params_)

# 假设 RandomizedSearchCV 的输出为 rf_random.best_params_ = {'n_estimators': 18, 'min_samples_split': 70, ...}
param_grid = {
'n_estimators': [17, 18, 19],
'max_features': [rf_random.best_params_['max_features']],
'max_depth': [rf_random.best_params_['max_depth'] - 1, rf_random.best_params_['max_depth'], rf_random.best_params_['max_depth'] + 1],
'min_samples_split': [rf_random.best_params_['min_samples_split'] - 1, rf_random.best_params_['min_samples_split'], rf_random.best_params_['min_samples_split'] + 1],
'min_samples_leaf': [rf_random.best_params_['min_samples_leaf'] - 1, rf_random.best_params_['min_samples_leaf'], rf_random.best_params_['min_samples_leaf'] + 1],
'class_weight': [rf_random.best_params_['class_weight']]
}
# 网格搜索对象
rf_grid = GridSearchCV(rf, param_grid, cv=2, n_jobs=-1, verbose=2, scoring='accuracy')
# 拟合网格搜索模型
rf_grid.fit(train[features].values, train['Survived'].values)
# 查看最佳参数组合
print(rf_grid.best_score_)
print(rf_grid.best_params_)

使用最佳超参的随机森林模型对test表进行预测
rf_grid.best_estimator_.predict(test[features])

3. 应用于回归任务
待补充

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)