
使用jieba测试分词并且增加自定义字典
使用jieba测试分词并且增加自定义字典
·
1、github下载源码
https://github.com/fxsjy/jieba
也可以直接用pip安装
pip install jieba
2、拷贝测试代码测试
稍微修改了下文件路径方面的代码,路径如下
import time
import sys
sys.path.append("../")
import jieba
jieba.initialize()
# 输入需要分词的文件路径
url = "test/data/zrbzdz.txt"
content = open(url,"r",encoding='utf-8-sig').read()
t1 = time.time()
words = "/ ".join(jieba.cut(content))
t2 = time.time()
tm_cost = t2-t1
# 输出分词后的文件路径
log_f = open("test/data/output/1.log","wb")
log_f.write(words.encode('utf-8'))
log_f.close()
print('cost ' + str(tm_cost))
print('speed %s bytes/second' % (len(content)/tm_cost))
这边测试了5万多条标准地名地址数据
速度还是挺快的,大概只要13秒
结果肯定有些地方是不如人意的,毕竟是地名地址数据,看这里就有问题了
下一步添加自定义字典
3、添加自定义字典
如果用单个添加,感觉不太方便,用load_userdict方法添加,如果数据量大的话,又太慢,所以直接添加到结巴分词自身词库"dict.txt"当中。
github源码路径在这里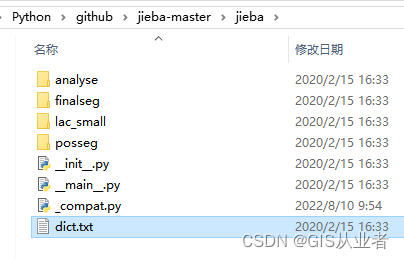
python安装路径在这里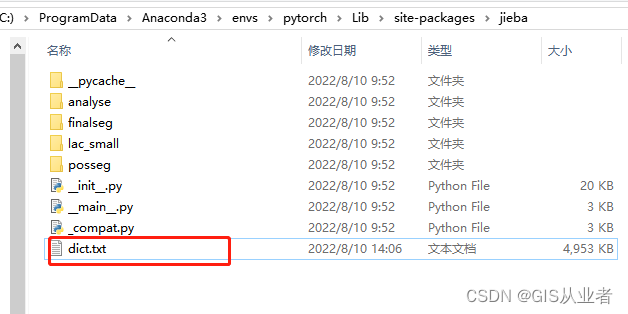
(1)、打开把自己的字典添加进去就行,注意格式
词 词频 词性
我这边词频和词性大概写的
福基岗村 3 n
(2)、添加后保存
(3)、删除jieba.cache
每次执行脚本,会提示加载的jieba.cache路径,我们先把它删除
(4)、重新执行脚本
脚本没变,结果变了,说明我们自定义的字典起作用了,有其它词数据可以一直加进去

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)