
基于XGBoost的网络游戏流失玩家预测算法
本项目旨在构建一个基于XGBoost的网络游戏流失玩家预测算法。通过分析玩家的游戏行为数据(如总游戏时长、每月消费金额、游戏次数等特征),预测玩家是否会流失。流失预测是游戏运营中的一个关键任务,能够帮助运营团队识别潜在流失玩家,并采取相应的干预措施,提高玩家留存率。本项目构建了一个基于XGBoost的网络游戏流失玩家预测算法,涵盖了从数据预处理、模型训练、评估到可视化的重要步骤。通过该模型,游戏运
·
基于XGBoost的网络游戏流失玩家预测算法开发文档
1. 项目概述
本项目旨在构建一个基于XGBoost的网络游戏流失玩家预测算法。通过分析玩家的游戏行为数据(如总游戏时长、每月消费金额、游戏次数等特征),预测玩家是否会流失。流失预测是游戏运营中的一个关键任务,能够帮助运营团队识别潜在流失玩家,并采取相应的干预措施,提高玩家留存率。
2. 项目目标
- 构建一个流失预测模型:利用玩家的历史数据,预测玩家是否流失。
- 使用XGBoost算法:XGBoost(Extreme Gradient Boosting)是一种高效的梯度提升树模型,广泛应用于二分类任务。
- 评估模型性能:使用常见的评估指标(如准确率、ROC AUC、分类报告)评估模型效果。
- 可视化特征重要性:展示模型中各个特征的重要性,帮助理解模型。
3. 系统架构
- 数据准备:通过随机生成的玩家行为数据集来训练和测试模型。
- 数据预处理:对数据进行缺失值处理、特征选择和数据拆分。
- 模型训练与评估:使用XGBoost模型进行训练,并通过准确率、ROC AUC等评估指标对模型进行评估。
- 输出与可视化:输出评估结果,绘制特征重要性图表。
4. 环境要求
- 编程语言:Python 3.x
- 依赖库:
- pandas:数据处理
- numpy:数学计算
- xgboost:机器学习模型
- scikit-learn:模型评估
- matplotlib:可视化
- 安装依赖:
pip install pandas numpy xgboost scikit-learn matplotlib
5. 数据结构
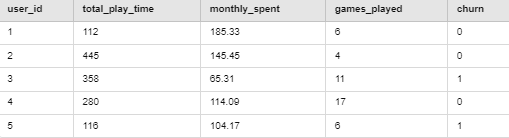
数据集包含以下字段:

示例数据(前5条记录):
6. 数据生成
为了测试模型,我们使用了随机生成的数据,包括游戏时长、消费金额、游戏次数以及流失标签。流失标签是通过一定的规则随机生成的,例如,消费较低或游戏时长较低的玩家更可能流失。
生成的数据保存为game_player_data.csv文件,包含1000条数据。
数据生成代码:
import pandas as pd import numpy as np # 设置随机种子,以确保结果可复现 np.random.seed(42) # 生成示例数据 num_samples = 100 # 输出100条数据 .......
7. 主要代码结构与功能
1. 数据加载与预处理
def load_data(file_path):
if os.path.exists(file_path):
data = pd.read_csv(file_path)
print("数据加载成功!")
return data
........
2. 模型训练
def train_xgboost(X_train, y_train):
xgb_model = xgb.XGBClassifier(
.......
3. 模型评估
def evaluate_model(xgb_model, X_test, y_test):
y_pred = xgb_model.predict(X_test)
y_pred_prob = xgb_model.predict_proba(X_test)[:, 1]
......
4. 主程序
def main():
print("欢迎使用XGBoost流失玩家预测系统")
......
8. 模型评估指标
- 准确率(Accuracy):预测正确的样本占所有样本的比例。
- ROC AUC(Receiver Operating Characteristic Area Under Curve):衡量分类模型区分正负样本能力的指标,值越高,模型性能越好。
- 分类报告(Classification Report):包括精确率、召回率、F1分数等指标,评估分类模型的全面性能。
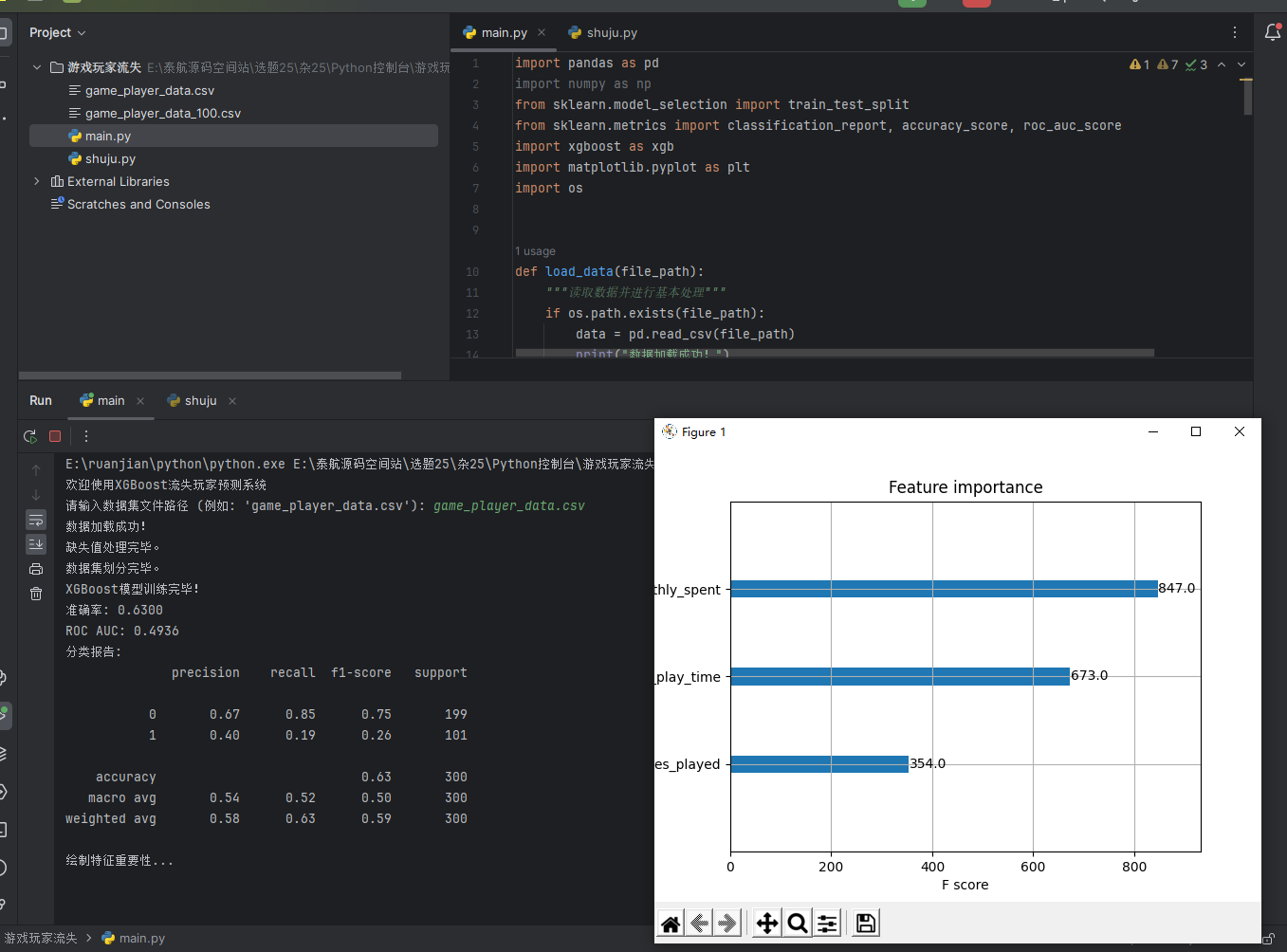
9. 可视化特征重要性
使用xgboost.plot_importance()方法绘制特征重要性图,帮助理解模型依据哪些特征进行预测。特征重要性可以帮助分析哪些特征对玩家流失预测最具影响力。
10. 总结
本项目构建了一个基于XGBoost的网络游戏流失玩家预测算法,涵盖了从数据预处理、模型训练、评估到可视化的重要步骤。通过该模型,游戏运营团队可以有效地预测玩家流失,及时采取干预措施,提高玩家留存率。
具体项目演示效果:

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 32
32 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)