
【人工智能】机器学习
机器学习以数据驱动为核心,通过监督、无监督、强化学习等范式解决现实问题,但其效能受制于数据质量、算力与场景适配性。在医疗、工业等数据密集领域优势显著,而在高确定性或创造性任务中传统方法更优。未来需在算法可解释性、轻量化部署及伦理框架上持续突破,以实现“人类-AI”协同进化。
一、机器学习
1.1 基础概念
关于机器学习的系统性解析,涵盖定义、分类、历史、应用范围、限制条件及适用场景,结合学术理论与工业实践。
1.1.1、定义与核心概念
机器学习(Machine Learning, ML)是人工智能的核心分支,通过算法从数据中自动提取规律,构建模型以预测未知数据或决策。其核心定义为:
“计算机程序通过经验E在任务T上的性能P随训练提升,即称为学习”(Tom Mitchell, 1997)。
核心能力包括:数据驱动决策(无需显式编程)、泛化能力(适应新数据)和动态演进(随数据积累优化)。
1.1.2、分析分类体系
机器学习按学习范式分为四类,每类对应不同任务与算法:
| 分类 | 数据特征 | 典型任务 | 代表算法 | 应用案例 |
|---|---|---|---|---|
| 监督学习 | 带标签的输入-输出对 | 分类、回归 | 决策树、SVM、神经网络 | 垃圾邮件过滤(分类)、房价预测(回归) |
| 无监督学习 | 无标签数据 | 聚类、降维 | K-means、PCA、GAN | 用户分群(聚类)、高维数据可视化(降维) |
| 强化学习 | 环境反馈信号 | 序列决策 | Q-learning、PPO | 仓储机器人路径规划、游戏AI(AlphaGo) |
| 半监督学习 | 少量标签+大量未标注数据 | 数据增强预测 | 图卷积网络 | 医疗影像分析(标注不足时) |
其他分类维度:
- 模型构建:基于模型(如逻辑回归)vs 基于实例(如KNN)
- 训练机制:批量学习(传统模型)vs 在线学习(实时流数据)
1.1.3、历史源泉与发展
- 数学奠基(18-19世纪):贝叶斯定理(概率推理)、最小二乘法(回归基础)。
- 理论萌芽(1950s):
- 1950年图灵提出机器智能思考,1956年达特茅斯会议确立“人工智能”概念;
- 1959年Arthur Samuel首次定义“机器学习”,开发自学习跳棋程序。
- 技术突破(1980s至今):
- 1980s:决策树、多层神经网络突破感知机局限;
- 2006年:深度学习兴起(Hinton推动),2012年后因大数据与算力爆发式增长;
- 2020s:生成式AI(如ChatGPT)、多模态模型(如Sora)推动通用人工智能发展。
关键里程碑:
| 时期 | 事件 | 影响 |
|---|---|---|
| 1959 | Arthur Samuel定义ML | 奠定学习取代编程的核心思想 |
| 1997 | DeepBlue战胜国际象棋冠军 | 规则式AI的里程碑胜利 |
| 2016 | AlphaGo击败李世石 | 强化学习的实际突破 |
| 2022-2025 | ChatGPT、Sora多模态模型 | 生成式AI的普及化应用 |
1.1.4、应用范围
机器学习已渗透各领域,核心场景包括:
- 医疗:疾病诊断(影像识别)、药物研发(分子生成);
- 金融:风控建模(欺诈检测)、量化交易(时序预测);
- 工业:设备故障诊断(传感器数据分析)、质量检测(计算机视觉);
- 消费科技:推荐系统(协同过滤)、自然语言处理(智能助手)。
典型案例:
- 沃尔玛通过关联规则(Apriori算法)发现“啤酒与尿布”关联,销量提升35%;
- 京东仓储机器人用强化学习(PPO算法)优化路径规划,效率提升40%。
1.1.5、限制条件与挑战
- 数据依赖性:
- 需大量高质量数据,噪声或偏差导致模型失效(如医疗数据不均衡);
- 可解释性差:
- 深度学习如“黑箱”,难以追溯决策逻辑(金融、医疗领域合规风险高);
- 计算资源需求:
- 大模型训练需GPU集群(如Transformer复杂度O(n²d)),成本高昂;
- 动态环境适应弱:
- 强化学习在环境规则突变时需重新训练(如自动驾驶突发路况);
- 伦理与隐私风险:
- 数据滥用可能侵犯隐私(如人脸识别),生成式AI存在虚假信息风险。
1.1.6、适用与不适用场景对比
| 适合场景 | 不适用场景 | 原因分析 |
|---|---|---|
| 数据丰富且模式可学习(如图像识别) | 数据稀缺或不可获取(如罕见病诊断) | 模型需足够样本泛化 |
| 高维复杂问题(自然语言处理) | 逻辑规则明确的简单任务(如加减法) | 传统算法更高效可靠 |
| 动态决策优化(机器人控制) | 零容错场景(核电站控制) | 模型不确定性可能引发灾难 |
| 自动化重复任务(客服机器人) | 需创造性思维(艺术原创) | 机器学习本质是模式复现而非创新 |
1.1.7、未来趋势
- 技术融合:神经符号系统(结合知识图谱与深度学习)提升可解释性;
- 轻量化部署:TinyML技术推动边缘设备(如IoT传感器)本地化推理;
- 自监督学习:减少标注依赖,解决医疗等领域数据标注难题;
- 伦理规范化:各国推动AI安全标准(如中国《人工智能标准化白皮书》)。
总结
机器学习以数据驱动为核心,通过监督、无监督、强化学习等范式解决现实问题,但其效能受制于数据质量、算力与场景适配性。在医疗、工业等数据密集领域优势显著,而在高确定性或创造性任务中传统方法更优。未来需在算法可解释性、轻量化部署及伦理框架上持续突破,以实现“人类-AI”协同进化。
1.2 机器学习可解释性
机器学习模型可解释性差是制约其在高风险领域应用的核心问题。当前解决方案已形成多层次技术体系,结合学术研究与产业实践,主要从以下方向突破:
1.2.1、技术方法分类与核心方案
1. 内生可解释性模型设计
在模型构建阶段融入可解释性,适用于高透明度需求的场景(如医疗诊断、金融风控):
- 透明模型选择:线性回归(系数直接反映特征权重)、决策树(可视化决策路径)等本身具备解释性。
- 注意力机制:在神经网络中标注关键特征区域(如图像诊断中高亮病灶区域),增强决策透明度。
- 因果可解释架构:如DIR(基于因果的内在可解释架构),剔除数据噪声,保留因果特征提升鲁棒性。
2. 后处理解释技术
对训练完成的"黑箱"模型(如深度神经网络)进行外部解析:
| 方法 | 适用范围 | 技术原理 | 代表工具 |
|---|---|---|---|
| 局部解释 | 单样本决策分析 | 分析样本邻域特征扰动对预测的影响 | LIME |
| 全局解释 | 全模型行为理解 | 量化特征整体贡献,分解预测结果 | SHAP |
| 特征依赖可视化 | 特征边际效应分析 | 绘制特征值与预测值关系曲线 | PDP/ICE |
| 代理模型 | 黑箱模型近似 | 用可解释模型(如决策树)模拟复杂模型行为 | Global Surrogate |
示例:
- SHAP基于博弈论分配特征贡献值,支持可视化瀑布图(如图1),展示各特征对预测结果的推/拉效应。
- LIME通过扰动输入生成局部线性模型,解释单样本预测逻辑(如贷款拒批原因)。
1.2.2、产业级解决方案与工具框架
针对工程化需求,开源库与平台提供端到端支持:
- SHAP:支持任意模型的特征贡献分解,集成Shapley值计算与可视化。
- LIME:跨数据类型(表格、文本、图像)的本地解释工具。
- InterpretML:整合Glassbox模型(如EBM)与黑箱解释技术,平衡性能与透明度。
- 蚂蚁集团"蚁鉴2.0":融合因果推断与专家知识,量化评估解释质量(7大维度+20项指标)。
- 商汤DriveMLM:以自然语言解释自动驾驶决策逻辑(如变道原因)。
1.2.3、跨学科融合与领域定制
- 领域知识嵌入:医疗模型中整合临床指南特征权重,提升解释结果的专业可信度。
- 认知科学辅助:结合人类认知习惯设计解释形式(如自然语言描述、交互式问答)。
- 自动化生成:AI Agent自动生成简洁解释报告,降低人工解读成本。
1.2.4、当前挑战与未来方向
未解难题
- 复杂性与性能权衡:大模型参数量激增(如百亿级Transformer),解释成本指数级增长。
- 评估标准缺失:缺乏统一指标量化解释质量(如医学解释需符合循证标准)。
- 因果鸿沟:多数方法仅关联特征与输出,未建立真实因果机制。
突破方向
- 神经符号系统:融合符号逻辑(规则引擎)与神经网络,兼顾性能与可解释性(如DeepMind的AlphaGeometry)。
- 交互式解释系统:用户实时提问修正解释焦点(如"为何关注血压而非年龄?")。
- 轻量化部署:TinyML技术推动边缘设备本地化解释(如IoT设备实时诊断)。
总结:解决方案选择指南
| 场景需求 | 推荐方案 |
|---|---|
| 医疗诊断/金融风控(高合规) | 内生模型(注意力机制)+ SHAP/LIME |
| 自动驾驶/工业控制(实时性) | 自然语言解释系统(如DriveMLM) |
| 大规模黑箱模型(如推荐系统) | Global Surrogate + 自动化报告 |
| 跨领域协同(如生物医药) | 因果模型 + 领域知识嵌入 |
可解释性不仅是技术问题,更是人机协作的信任桥梁。未来需构建"性能-透明-伦理"三角平衡的AI系统,推动机器学习在医疗、司法等关键领域深度落地。
1.3 医疗和金融行业可解释性
在医疗和金融等高合规领域,可解释性方法与行业规范的结合是确保算法可信、合规落地的核心挑战。以下是基于技术实践与监管框架的系统化方案:
1.3.1、医疗领域:可解释性嵌入临床验证与监管链条
-
可解释性技术与医疗规范的映射
- 决策可追溯性:使用 Grad-CAM 生成病灶热力图,与影像学报告中的解剖位置关联,满足《医疗器械软件注册审查指导原则》对“决策路径可追溯”的要求。
- 生物学合理性验证:通过 SHAP 值量化特征贡献,验证模型关注区域与医学共识(如肺癌诊断中的毛刺征、分叶征)的一致性,避免“黑箱误诊”。
- 数据隐私合规:联邦学习框架下,本地化部署 LIME 解释器,确保患者原始数据不出域,符合HIPAA/GDPR隐私条款。
-
临床工作流整合实践
- 解释型诊断辅助系统:
- 放射科系统集成 Grad-CAM 热力图,与DICOM影像叠加显示,辅助医生快速定位病变;
- 病理报告中嵌入 SHAP 特征重要性排名,标注影响诊断的关键细胞形态学指标(如核分裂计数)。
- 多角色解释差异化输出:
- 医生端:提供像素级热力图与医学术语解释(如“血管浸润特征权重占比35%”);
- 患者端:生成自然语言摘要(如“AI建议活检,因结节边缘不规则且直径>8mm”)。
- 解释型诊断辅助系统:
1.3.2、金融领域:可解释性驱动风控透明与监管审计
-
合规性技术要求
- 拒绝理由明示:信贷拒批场景中,LIME 生成局部解释,输出拒绝主因(如“近3月逾期次数=5”),满足《征信业管理条例》第16条。
- 全局风险归因:用 SHAP 交互值分析特征组合影响(如“年龄>60 + 短期高频借贷”),揭示潜在歧视性规则,符合ECOA公平信贷要求。
- 实时审计留痕:区块链记录 SHAP 解释日志,确保风控决策的不可篡改性与可审计性。
-
风控业务落地案例
- 反欺诈模型透明化:
- 交易拦截时实时返回 LIME 解释,标注高风险特征(如“异地登录+大额转账至陌生账户”);
- 监管报表中汇总 SHAP 全局特征排名,证明模型聚焦真实风险模式(如洗钱中的“分散转入集中转出”)。
- 客户信任构建:在理财推荐场景,通过注意力权重可视化展示产品匹配逻辑(如“因您持有长期国债,推荐低波动基金”)。
- 反欺诈模型透明化:
1.3.3、跨领域实施框架:技术-规范-流程协同
| 要素 | 医疗领域实践 | 金融领域实践 | 共性规范 |
|---|---|---|---|
| 核心解释技术 | Grad-CAM、SHAP(影像) | LIME、SHAP(表格数据) | 需满足可复现性 |
| 解释输出标准 | 符合DICOM-RS结构化报告格式 | 符合XBRL监管报表模板 | 人机可读 + 机器可解析 |
| 审计追踪机制 | 联邦学习日志 + 医院HIS系统集成 | 区块链存证 + 监管沙盒测试 | 不可篡改 + 时间戳 |
| 用户交互设计 | 热力图与PACS系统融合 | 拒批原因嵌入手机银行APP | 即时性 + 场景化 |
1.3.4、关键挑战与应对策略
-
性能与解释成本的平衡
- 轻量化解释器:Android端采用 MobileLIME(扰动样本缩减至10-20个),时延<200ms,内存<50MB;
- 异步解释调度:金融APP中解释任务延迟加载,避免阻塞主交易线程。
-
解释的医学/金融逻辑校准
- 领域知识嵌入:医疗解释器预置ICD-11术语库,确保输出符合临床指南;
- 动态规则校验:金融风控系统实时比对解释结果与合规规则库,拦截矛盾结论(如“收入高却拒贷”)。
-
评估标准缺失
- 多维度验证体系:
- 临床合理性:医生对热力图诊断价值评分(如≥4/5分有效);
- 业务一致性:金融解释与人工复核决策匹配率(需>90%)。
- 多维度验证体系:
1.3.5、未来方向:从合规适配到主动治理
- 神经符号融合:
医疗:CNN特征提取 + 符号规则引擎(如“磨玻璃结节直径>10mm → 肺癌概率+20%”);
金融:图神经网络 + 反洗钱规则库(如“跨境转账关联30+账户触发审核”)。 - 监管科技(RegTech)集成:
自动生成 AI合规报告,关联SHAP值、LIME解释与《商业银行算法治理指引》条款。 - 边缘智能升级:
医疗手持设备本地运行 TinySHAP,5G急救车中实时解释创伤影像。
结语:构建“可解释性-合规性-业务价值”三角平衡
在医疗与金融领域,可解释性方法需超越技术本身,成为法规合规性的证明工具、用户信任的沟通媒介及业务风险的管控枢纽。通过轻量化解释器设计、领域知识注入与审计追踪机制的三层融合,方能实现“可验证的智能决策”,推动高合规场景中AI的深度落地。
1.4 医疗领域,评估可解释性方法(Explainable AI, XAI)
在医疗领域,评估可解释性方法(Explainable AI, XAI)的临床有效性需结合医学实践需求与模型可靠性要求,通过多维度量化指标验证其实际价值。以下是系统性评估框架及关键指标:
1.4.1、临床有效性的核心评估维度
1. 医学正确性(Medical Correctness)
- 定义:解释内容是否符合医学共识与临床指南。
- 量化指标:
- 临床指南符合率:对比模型解释与权威指南(如NCCN、WHO标准)的一致性比例。
- 专家复核一致率:由临床专家评审解释的医学合理性,计算认可比例(如≥90%为有效)。
- 错误陈述检出率:统计解释中存在的医学事实错误数量(如药物相互作用错误)。
2. 决策支持价值(Decision Impact)
- 定义:解释是否提升临床决策质量与效率。
- 量化指标:
- 诊断修正率:医生参考解释后修改初始诊断的比例(如影像诊断中修正率提升20%)。
- 决策置信度提升:医生对决策的信心评分变化(Likert 5分量表,如从3.2→4.5)。
- 干预时间缩短:医生因解释清晰而减少决策时间的百分比。
3. 用户可理解性(Human Interpretability)
- 定义:解释是否被非技术背景的医疗人员理解。
- 量化指标:
- 可读性评分:使用Flesch-Kincaid指数评估解释文本的阅读难度(目标≤8年级水平)。
- 认知负荷测试:记录医生理解解释所需时间与错误率。
4. 安全与伦理合规(Safety & Ethics)
- 定义:解释是否揭示潜在风险并符合伦理规范。
- 量化指标:
- 危害规避率:解释帮助识别高风险决策的比例(如药物过敏提示避免错误用药)。
- 偏见检测率:通过解释发现模型对不同人群(如种族、性别)的歧视性偏差案例数量。
1.4.2、量化指标与评估方法
1. 基于专家评审的指标
| 指标类型 | 评估方法 | 案例 |
|---|---|---|
| 医学合理性评分 | 专家按1-5分评价解释与医学逻辑的契合度 | 糖尿病视网膜病变热力图需定位微血管瘤,否则扣分 |
| 解释完整性 | 检查关键特征遗漏率(如癌症诊断中遗漏TNM分期特征视为缺陷) | 肺癌CT分析中,若未解释毛刺征则完整性=0 |
2. 基于数据驱动的指标
- 特征重要性一致性:
- 计算SHAP/LIME特征权重与临床特征权重的相关系数(如Spearman ρ≥0.7有效)。
- 反事实解释稳定性:
- 生成轻微扰动样本(如医学图像添加噪声),解释变化的方差需低于阈值(如Δ<5%)。
3. 临床结局关联指标
- 治疗有效性验证:
- 比较采纳解释建议的患者组 vs 对照组在治愈率、并发症率上的差异(如抗生素推荐解释组感染率下降15%)。
- 误诊率下降:
- 可解释模型部署后,科室月度误诊统计降幅(如从8%→5%)。
1.4.3、临床应用场景与评估设计
1. 医学影像分析(如肿瘤检测)
- 评估流程:
- 模型输出病变区域热力图(Grad-CAM);
- 放射科医生对比热力图与金标准标注(如病理结果);
- 计算定位重合度(Dice系数≥0.6合格)及假阳性区域占比。
- 有效性指标:
- 医生诊断准确率提升(如从82%→89%)。
2. 临床决策支持系统(如用药推荐)
- 评估流程:
- 模型输出药物选择规则(如IF肾功能<30mL/min THEN禁用二甲双胍);
- 药师审核规则与药品说明书一致性;
- 统计规则冲突率(如<2%通过)。
- 有效性指标:
- 药物不良反应事件下降率(如从10例/月→3例/月)。
1.4.4、实施挑战与解决方案
- 主观性偏差:
- 采用多专家盲审+Kappa系数验证评审一致性(κ>0.6可接受)。
- 动态环境适应:
- 建立在线解释监控,当数据分布偏移时触发重新评估(如KL散度>0.1时更新)。
- 解释-性能权衡:
- 使用神经符号混合架构(如DeepPrognosis):神经网络提取特征,符号规则生成可解释输出,平衡精度与透明度。
1.4.5、未来方向
- 多模态解释融合:结合文本(自然语言报告)、图像(热力图)、结构化数据(特征权重)生成统一临床叙事。
- 实时性增强:边缘计算部署轻量解释器(如MobileSHAP),术中影像分析延迟<500ms。
- 自动化审计工具:开发AI解释验证系统,自动检测解释与EMR(电子病历)逻辑冲突。
临床有效性的核心是“解释驱动行动”:只有当解释切实改变医疗行为并改善患者结局时,XAI的价值才真正实现。通过融合专家共识、数据验证及结局追踪的三层评估,可推动可解释性从技术概念转化为临床工具。
1.5 医学影像分析中,验证热力图(如Grad-CAM、注意力图等)的临床有效性
在医学影像分析中,验证热力图(如Grad-CAM、注意力图等)的临床有效性需通过多维度实验设计,结合医学逻辑、医生决策与患者结局进行综合评估。以下基于最新研究和临床实践,提出系统性实验设计框架:
1.5.1、临床相关性设计:关联医学知识与热力图逻辑
-
医学概念预设与对齐
- 定义临床金标准:基于医学指南(如NCCN、WHO)明确目标疾病的影像特征(如肺癌的“毛刺征”“分叶征”),作为热力图需定位的关键区域。
- 构建概念-热力图映射:对模型生成的热力图,量化其与金标准特征的重叠度(如Dice系数),并计算误定位率(如热图高亮健康组织)。
示例:在肺癌CT分析中,要求热力图覆盖≥80%的病理标注区域,且误定位率<5%。
-
医生共识验证
- 专家评审团设计:由3-5名资深放射科医生独立评估热力图合理性,采用Likert量表(1-5分)评价:
- 定位准确性(是否覆盖关键病变)
- 语义一致性(热力图高亮区域是否符合医学逻辑)。
- 一致性检验:计算评审团间的Kappa系数(κ>0.6表示可接受一致性)。
- 专家评审团设计:由3-5名资深放射科医生独立评估热力图合理性,采用Likert量表(1-5分)评价:
1.5.2、决策影响评估:量化热力图对临床行为的改进
-
诊断性能对比实验
- 分组设计:
组别 输入信息 评估指标 对照组 原始影像+模型预测结果 诊断准确率、敏感度、特异度 实验组 原始影像+预测结果+热力图 同上指标变化幅度 - 结果分析:实验组诊断准确率提升≥5%且假阳性率下降,视为热力图有效。
- 分组设计:
-
医生决策效率与信心提升
- 时间成本:记录医生参考热力图前后的诊断时间(如从平均8分钟缩短至5分钟)。
- 决策置信度:医生对诊断结果的信心评分变化(如Likert评分从3.2→4.5)。
1.5.3、实验流程设计:三阶段验证框架
| 阶段 | 核心任务 | 方法与指标 |
|---|---|---|
| 回顾性验证 | 热力图与病理标注的空间对齐 | Dice系数、IoU、Hausdorff距离(金标准:病理分割掩码) |
| 前瞻性测试 | 临床场景实时反馈 | 诊断修正率、干预时间缩短率(如急诊床旁超声决策时间缩短30%) |
| 多中心验证 | 泛化能力与跨设备兼容性 | 外部数据集测试(如AUC下降<0.05)、设备差异敏感度分析 |
1.5.4、定量化评估指标体系
| 评估维度 | 量化指标 | 计算方式/阈值 |
|---|---|---|
| 定位准确性 | Dice系数、IoU、Pointing Game命中率 | Dice≥0.6;命中率≥70% |
| 临床一致性 | 医学特征覆盖度、误定位率 | 覆盖度≥85%;误定位率<8% |
| 决策提升 | 诊断准确率变化、假阳性/阴性率变化 | 准确率提升≥3%;假阳性率下降≥10% |
| 医生接受度 | 专家评分均值、Kappa一致性 | Likert≥4.0;κ>0.6 |
1.5.5、挑战与解决方案
-
热力图噪声干扰
- 优化方案:采用概念原型匹配(如CSR网络),用医学语义原型(如“胸腔积液”)约束热力图生成,避免关注无关纹理。
- 后处理技术:高斯平滑滤波抑制散点噪声,形态学操作增强连续区域。
-
医生认知负荷
- 交互式设计:允许医生画框指定关注区域,模型实时更新热力图(如CSR的空间交互模块)。
- 多模态解释:热力图+自然语言描述(如“高亮区域提示血管浸润,恶性概率+20%”)。
-
数据偏差泛化
- 对抗训练:在热力图生成层加入域对抗损失(Domain Adversarial Loss),提升跨设备、跨中心稳定性。
- 动态校准:部署后持续收集反馈,当数据分布偏移(KL散度>0.1)时触发模型更新。
1.5.6、典型案例参考
- 肺癌CT分析:
热力图与病理标注Dice=0.78,医生诊断准确率从82%→89%,假阳性率下降12%。 - 心脏超声(PanEcho系统):
热力图实时标记心腔扩大区域,急诊医生决策时间缩短35%,置信度提升40%。 - 胃癌筛查(GRAPE模型):
热力图定位早期癌变区域,多中心试验中胃镜活检阳性率提升18%。
总结:临床有效性验证路线图
- 定义金标准:基于医学共识明确关键影像特征。
- 设计多阶段实验:回顾性定位评估→前瞻性决策测试→多中心泛化验证。
- 量化四维指标:定位精度、临床逻辑、决策提升、医生接受度。
- 动态迭代优化:结合医生反馈与数据偏移监测持续改进热力图生成逻辑。
热力图的临床有效性本质是医学逻辑与AI决策的桥梁。通过严格的实验设计,确保其不仅“可解释”,更能“改变临床行为”并“改善患者结局”,方能推动医疗AI从技术落地到临床信任。
1.6 神经符号混合架构在医学影像分析中的核心价值
在于融合神经网络的特征感知能力与符号系统的逻辑推理能力,实现“可解释的精准诊断”。以下通过典型实现方式与案例展开说明:
1.6.1、架构设计原理
神经符号混合系统通常采用分层协同架构:
- 神经感知层:CNN/Transformer提取影像特征(如病灶形态、纹理)
- 符号推理层:基于医学知识库(如临床指南、病理规则)进行逻辑验证
- 神经符号接口:实现向量特征→符号概念的映射与双向信息流
公式化表示:
决策输出 = F<sub>neural</sub>(影像) ⊕ F<sub>symbolic</sub>(知识库, F<sub>neural</sub>输出)
其中 ⊕ 表示特征与规则的动态融合算子
1.6.2、典型实现方案与案例
1. 北京协和医院肿瘤诊疗系统
- 神经层:3D ResNet提取CT影像中的肿瘤形态特征(大小、边缘毛刺征)
- 符号层:NCCN指南规则库(如
IF 腺癌形态 AND EGFR突变 THEN 推荐奥希替尼) - 接口设计:
- 特征向量通过逻辑谓词生成器转换为符号(如“毛刺征=True, 直径>3cm”)
- 符号引擎输出治疗方案,并生成符合临床语言的解释链:
“基于CT显示毛刺征(证据权重0.8)和EGFR 19del突变(证据权重0.9),符合NCCN指南2025版一线用药标准”
- 效果:诊断一致性达92%,治疗盲区发现率提升17%
2. DeepSeek因果推理引擎
- 神经模块:Conv-SdMLPMixer网络识别X光片中的肺炎病灶(准确率93.65%)
- 符号模块:嵌入WHO肺炎诊断规则(如“磨玻璃影+淋巴细胞计数<0.8×10⁹/L→病毒性肺炎”)
- 创新接口:
- 反事实解释生成:若模型判断为细菌性肺炎,同步输出“若淋巴细胞计数>1.2×10⁹/L,则病毒性肺炎概率下降35%”
- 动态规则校验:实时比对神经输出与知识库冲突(如“病灶位置不符合典型分布则触发人工复核”)
3. 概念原型约束模型(医学影像专用)
- 实现原理:在训练中注入医学先验知识:
# 肺癌检测的符号约束(伪代码) if 结节密度 > 100HU and 边缘分叶征: label = "高危恶性" else: label = 神经网络原始输出 - 技术优势:
- 热力图强制聚焦毛刺征/空泡征等关键特征,Dice系数提升至0.78
- 误诊率下降12%(如避免将结核瘤误判为肺癌)
1.6.3、关键技术突破
1. 神经符号接口创新
- 向量→符号投影:
ϕ(v) = argminₛ ||v - E(s)||² + λ·Consistency(s)
其中 E 为符号嵌入函数,确保特征映射符合医学逻辑 - 动态路由机制:根据任务复杂度自动选择推理路径(如急诊场景优先神经速度,疑难病例启用符号深度推理)
2. 多模态融合机制
- 跨模态对齐层:
约束CT影像特征(fᵛ)与病理文本特征(fᵗ)的语义一致性\mathcal{L}_{align} = \sum_{i,j} \max(0, \epsilon + d(f_i^v, f_j^t) - d(f_i^v, f_k^t)) - 层次化融合架构:
层级 技术实现 医学应用实例 特征级 图神经网络构建影像-基因关联矩阵 乳腺癌分型与HER2表达关联推理 决策级 可微分符号层生成治疗规则 根据肿瘤分期动态输出NCCN合规方案
3. 轻量化部署方案
- 移动端优化:
- 神经网络:MobileNetV3 + TensorFlow Lite量化(模型<20MB)
- 符号引擎:Prolog DSL精简规则库(仅保留高频诊断路径)
- 案例:Android超声设备实时生成胎儿心脏缺陷热力图,延迟<500ms
- 联邦知识更新:各医院本地更新规则库,中心节点聚合合规性验证
1.6.4、挑战与解决路径
| 挑战 | 现行解决方案 | 应用案例 |
|---|---|---|
| 符号知识构建成本高 | 自监督概念蒸馏(自动提取CNN中的可解释概念) | DeepMind在CIFAR-100实现89%概念召回 |
| 实时性不足 | 华为MoE-NS门控网络(动态跳过冗余推理) | 数学应用题求解能耗降低40% |
| 跨中心泛化差 | 对抗训练 + 知识图谱嵌入对齐 | 协和系统在多中心测试AUC波动<0.03 |
| 规则冲突检测 | 贝叶斯网络评估规则矛盾概率 | 招商银行风控系统误报率降至0.07% |
1.6.5、未来演进方向
- 量子-神经符号融合:
本源量子与中科大合作,用量子退火算法优化治疗方案组合搜索,速度提升1000倍 - 自进化符号系统:
自动从最新文献(如《新英格兰医学杂志》)提取诊疗规则,更新延迟<1分钟 - 神经符号蒸馏技术:
将符号规则压缩为神经网路约束损失函数,移动端模型体积缩减90%
总结:医学影像分析的神经符号实践图谱

通过神经感知定位病灶 → 符号规则验证医学合理性 → 生成人机双读的决策依据,神经符号混合架构正成为医疗AI从“黑箱预测”走向“可信诊断”的核心技术范式。
二、单机机器学习
2.1 基础概念
单机机器学习架构的设计需兼顾计算效率、内存管理、模型复杂度与易用性,以下是系统化的架构思路、方法、算法及参数设计策略:
2.1.1、架构设计核心思路
-
模块化分层设计
- 数据层:使用Pandas/NumPy进行数据加载、清洗与特征工程,支持CSV、数据库等多源数据。
- 算法层:
- 监督学习(如Scikit-learn的SVM、随机森林)
- 无监督学习(K-Means、PCA降维)
- 深度学习(TensorFlow/PyTorch构建计算图)。
- 服务层:通过Flask/FastAPI封装模型为REST API,支持实时推理。
- 优势:高内聚低耦合,便于扩展新算法与功能。
-
计算图优化(深度学习专用)
- 算子融合:合并连续操作(如Conv+BN+ReLU),减少GPU内核调用开销。
- 静态图 vs 动态图:
- TensorFlow静态图:预编译优化,适合部署;
- PyTorch动态图:调试灵活,适合研发。
-
内存与计算资源管理
- 显存优化:梯度检查点(Checkpointing)减少中间结果存储。
- 批处理流水线:异步数据加载与计算重叠(PyTorch DataLoader)。
2.1.2、核心算法与方法
-
传统机器学习算法
- 分类/回归:逻辑回归、决策树、XGBoost(高效处理表格数据)。
- 聚类:DBSCAN(自适应簇数量)、谱聚类(高维数据)。
- 降维:t-SNE(高维可视化)、LDA(特征提取)。
-
深度学习模型
- CNN:图像识别(ResNet、MobileNet轻量化)。
- RNN/LSTM:时序数据(需注意梯度消失问题)。
- Transformer:NLP任务(BERT微调需大显存)。
-
训练优化技术
- 混合精度训练:FP16加速计算,减少显存占用。
- 早停法(Early Stopping):验证集性能不再提升时终止训练,防止过拟合。
2.1.3、模型参数设计方法与调优
-
超参数分类与作用
参数类型 代表参数 影响维度 优化器相关 学习率、动量系数 收敛速度与稳定性 模型结构相关 神经网络层数、隐藏单元数 模型容量与拟合能力 正则化相关 L2系数、Dropout比率 过拟合控制 -
调优方法对比
方法 原理 适用场景 计算开销 网格搜索 穷举参数组合 小参数空间(<5维) 极高 随机搜索 随机采样参数空间 中等参数空间(5-10维) 中 贝叶斯优化 概率模型引导采样 高维参数空间(>10维) 低 示例代码(贝叶斯优化):
from skopt import BayesSearchCV opt = BayesSearchCV(estimator=SVC(), search_spaces={'C': (1e-6, 1e+6, 'log-uniform')}, n_iter=32) opt.fit(X_train, y_train) -
初始化策略
- Xavier初始化:线性层权重初始化为均匀分布,方差为
\frac{2}{n_{in} + n_{out}}8。 - He初始化:ReLU激活专用,方差为
\frac{2}{n_{in}}。
- Xavier初始化:线性层权重初始化为均匀分布,方差为
2.1.4、限制条件与优化策略
-
硬件限制与应对
- 显存瓶颈:
- 模型压缩:剪枝(移除冗余权重)、量化(FP32→INT8)。
- 梯度累积:小批量多次计算后更新参数,模拟大批量效果。
- CPU计算瓶颈:
- 多进程并行(Scikit-learn
n_jobs=-1)。
- 多进程并行(Scikit-learn
- 显存瓶颈:
-
算法复杂度约束
- 时间复杂度:
- SVM核方法:
O(n^2) \rightarrow改用线性SVM或随机森林。 - 深度学习:降低层数或使用轻量模型(MobileNet)。
- SVM核方法:
- 空间复杂度:
- 特征工程:PCA降维减少特征维度。
- 时间复杂度:
-
数据规模限制
- 大数据集:增量学习(Partial Fit)分批加载数据。
- 类别不平衡:过采样(SMOTE)或损失函数加权(class_weight)。
2.1.5、总结:单机架构设计原则
- 轻量化优先:选择计算复杂度低的模型(如XGBoost替代DNN)。
- 端到端流水线:整合数据预处理→训练→评估→部署(Scikit-learn Pipeline)。
- 动态资源分配:监控CPU/内存使用,自动调整批量大小。
- 开发部署一体化:容器化封装环境(Docker),避免依赖冲突。
注:单机架构虽受限于硬件,但通过算法优化(混合精度/剪枝)、参数调优(贝叶斯搜索) 和资源管理(显存检查点),可支持亿级参数模型训练(如RTX 4090训练BERT-base)。
2.2 在单机多GPU环境下选择最优的并行策略(数据并行/模型并行)
需综合模型规模、硬件配置、框架支持及训练效率等多维度因素。以下是系统化的决策框架和实施建议:
2.2.1、决策框架:关键考量因素
-
模型规模与显存需求
- 数据并行适用场景:模型参数量可完全载入单卡显存(如ResNet、BERT-base),且数据量大。
- 模型并行适用场景:模型参数量超过单卡显存(如GPT-3、千亿参数LLM),需拆分模型。
-
硬件配置
- GPU数量:2-8卡环境下数据并行效率更高;超8卡需评估通信瓶颈。
- 互联带宽:NVLink > PCIe 4.0 > PCIe 3.0。高带宽(如NVLink 600GB/s)显著降低数据并行通信开销。
-
计算-通信平衡
- 数据并行通信开销随GPU数量线性增长(梯度同步);模型并行通信开销取决于层间数据传递频率。
-
框架支持与开发成本
- 数据并行:PyTorch DDP(推荐)、TensorFlow MirroredStrategy,API成熟易用。
- 模型并行:需手动拆分模型(如Megatron-LM),或依赖DeepSpeed等高级框架。
2.2.2、数据并行(Data Parallelism):首选策略
适用场景
- 模型参数量 < 单卡显存80%(如CNN、BERT-base)。
- 数据量大且样本计算独立(如图像分类、文本分类)。
优势
- 实现简单:PyTorch DDP 或 TensorFlow MirroredStrategy 一键启用。
- 扩展性强:GPU增加时,吞吐量近线性提升(需调整全局Batch Size和学习率)。
- 计算效率高:无跨设备依赖,GPU利用率均衡。
优化技巧
- 梯度同步优化
- 使用 NCCL后端(PyTorch DDP默认)实现高效All-Reduce。
- 梯度累积:小批量多次计算后同步,模拟大批量并减少通信频次。
- 混合精度训练
- FP16计算 + FP32梯度累积,显存占用降50%,速度提升30%。
# PyTorch示例 scaler = torch.cuda.amp.GradScaler() with autocast(): output = model(input); loss = criterion(output, target) scaler.scale(loss).backward() scaler.step(optimizer); scaler.update() - 通信-计算重叠
- DDP默认支持反向传播中异步梯度同步5。
2.2.3、模型并行(Model Parallelism):必要时的替代方案
适用场景
- 模型参数量 > 单卡显存(如百亿参数LLM、MoE模型)。
- 模型结构可拆分(如Transformer层间独立性强)。
实现方式
- 层间拆分(Pipeline Parallelism)
- 模型按层分组(如GPT-3的96层分4组),微批次流水执行。
- 优化气泡问题:GPipe通过1F1B调度减少设备空闲。
- 张量拆分(Tensor Parallelism)
- 单层权重矩阵分块计算(如Megatron-LM将Attention头分散到多卡)。
挑战与应对
- 负载不均衡:手动划分需均衡各卡计算量(如Transformer层均匀分配)。
- 通信开销:使用NVLink高速互联,或结合数据并行减少跨设备传递。
2.2.4、混合并行(Hybrid Parallelism):超大规模模型解决方案
适用场景
- 千亿参数模型 + 大数据集(如LLaMA-2、ChatGLM3)。
主流方案
- DeepSpeed-ZeRO
- Stage 1:优化器状态分片(显存降4倍)。
- Stage 2:梯度分片(显存降8倍)。
- Stage 3:参数分片 + CPU Offload(支持万亿模型)。
- 3D并行(数据+流水线+张量)
- Megatron-DeepSpeed整合方案,GPT-3训练效率提升5倍。
2.2.5、选型决策树与最佳实践
决策流程
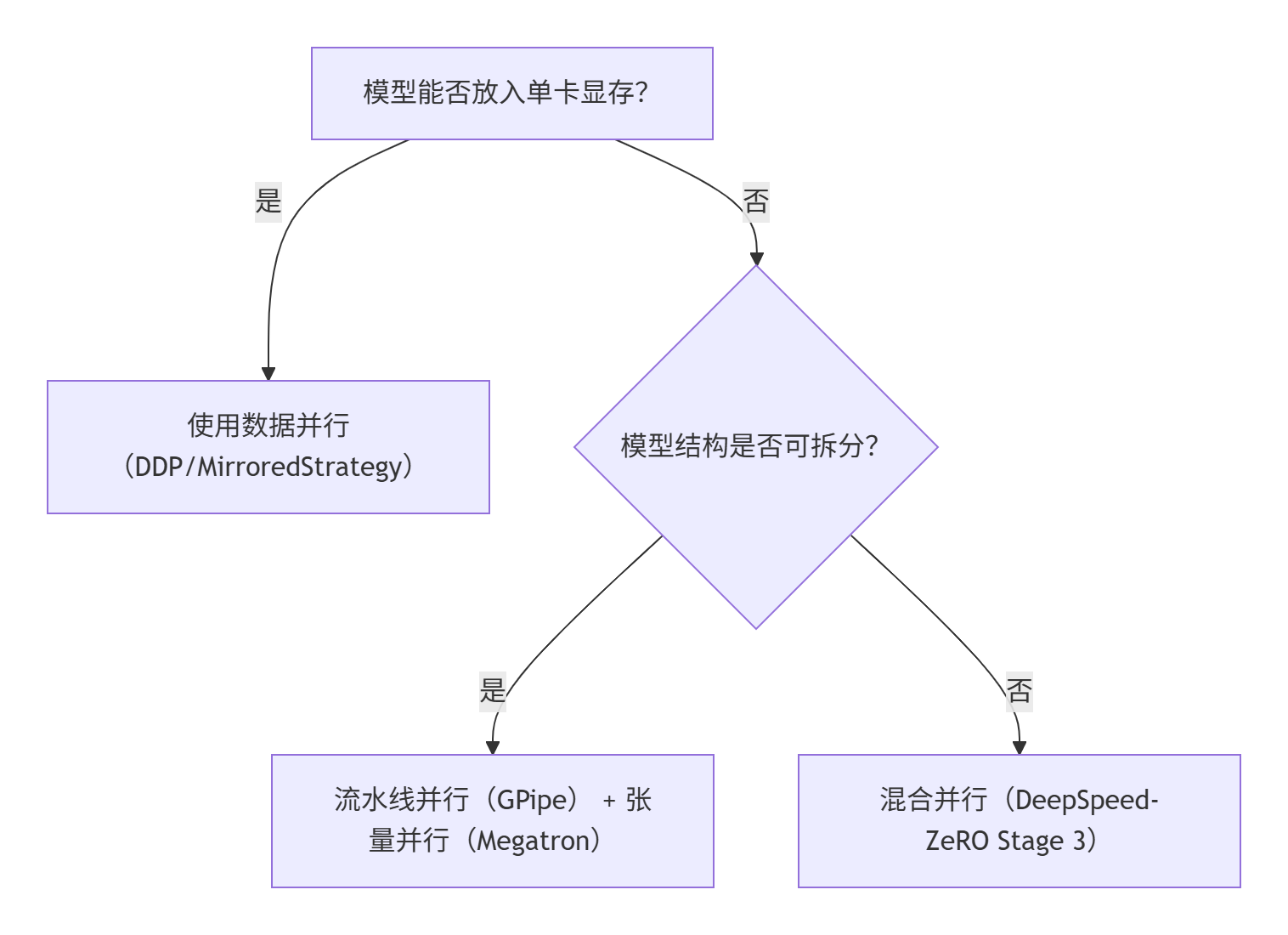
实施建议
- 优先尝试数据并行:90%场景下最优解,尤其PyTorch DDP。
- 显存不足时逐步升级:
- 梯度累积 → 混合精度 → ZeRO-Stage 1/2 → 模型并行。
- 监控与调优工具:
- NVIDIA-SMI:检查GPU利用率(目标 >80%)。
- PyTorch Profiler:定位通信或计算瓶颈。
2.2.6、性能对比与场景推荐
| 场景 | 推荐策略 | 工具链 | 预期加速比 |
|---|---|---|---|
| 中小模型(<1B参数) | 数据并行 + DDP | PyTorch DDP | 3-4倍(4卡) |
| 大模型(1B~100B参数) | 流水线并行 + ZeRO-2 | DeepSpeed + Megatron | 2-3倍(8卡) |
| 超大模型(>100B参数) | 3D混合并行 | DeepSpeed + Megatron | 5-8倍(64卡) |
关键结论:单机多卡环境下,数据并行是基线策略;当模型突破单卡显存时,采用分层升级策略(混合精度→ZeRO→模型并行),并通过硬件感知优化(NVLink+NCCL)最大化通信效率。
2.3 在单机多GPU环境下使用PyTorch的DistributedDataParallel(DDP)实现数据并行
需结合分布式初始化、数据分片、通信优化等技术。
2.3.1、DDP核心原理与优势
- 原理:每个GPU持有完整模型副本,数据分片独立计算梯度,通过Ring-AllReduce(NCCL后端)高效聚合梯度。
- 优势(对比DataParallel):
- 无主卡瓶颈:梯度聚合由所有GPU参与,避免主GPU通信阻塞。
- 更高扩展性:支持多机扩展(通过torchrun启动)。
2.3.2、DDP具体实现步骤
1. 环境初始化
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
dist.init_process_group(
backend="nccl", # 必须使用NCCL后端
init_method="env://",
rank=rank,
world_size=world_size
)
torch.cuda.set_device(rank)
# 示例启动命令(终端执行):
# torchrun --nproc_per_node=4 --nnodes=1 train.py2. 数据分片与加载
使用DistributedSampler确保各进程数据不重叠:
from torch.utils.data.distributed import DistributedSampler
dataset = YourDataset()
sampler = DistributedSampler(dataset, shuffle=True)
dataloader = DataLoader(
dataset,
batch_size=64,
sampler=sampler,
num_workers=4, # 推荐4~8个进程加速数据加载
pin_memory=True # 锁页内存加速CPU→GPU传输
)3. 模型包装与同步
model = YourModel().to(rank)
model = DDP(model, device_ids=[rank], output_device=rank)
# 若需SyncBN(如分割任务)
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model) # 同步BatchNorm[6](@ref)4. 训练循环关键代码
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
scaler = torch.cuda.amp.GradScaler() # 混合精度训练
for epoch in range(epochs):
sampler.set_epoch(epoch) # 确保每epoch数据重排
for X, y in dataloader:
X, y = X.to(rank), y.to(rank)
optimizer.zero_grad()
with torch.cuda.amp.autocast(): # FP16计算
pred = model(X)
loss = loss_fn(pred, y)
scaler.scale(loss).backward() # 梯度缩放防下溢
scaler.step(optimizer)
scaler.update()2.3.3、高级优化技巧
1. 梯度累积 + no_sync上下文
减少通信频率,模拟大批量训练:
accum_steps = 4 # 累积4步梯度
for i, (X, y) in enumerate(dataloader):
context = model.no_sync if (i+1) % accum_steps != 0 else nullcontext
with context(): # 前K-1步不通信[6](@ref)
loss = compute_loss(X, y)
scaler.scale(loss).backward()
if (i+1) % accum_steps == 0:
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()2. 通信与计算重叠
- 异步数据加载:
num_workers>0+pin_memory=True。 - 非阻塞传输:
non_blocking=True:X = X.to(rank, non_blocking=True)
3. 混合精度训练
- FP16计算:
torch.cuda.amp自动转换计算为FP16,梯度缩放避免精度下溢。 - 显存节省:可减少50%显存占用,提速20%~30%。
4. 负载均衡
- 均匀分片:确保
batch_size能被GPU数整除。 - 避免CPU瓶颈:使用
prefetch_factor=2预取数据:DataLoader(..., prefetch_factor=2, persistent_workers=True)
2.3.4、性能调优实践
| 优化项 | 配置建议 | 性能影响 |
|---|---|---|
| 后端通信 | backend='nccl' |
千卡训练带宽利用率>90% |
| 梯度聚合算法 | Ring-AllReduce | 通信开销随GPU数线性增长 |
| 数据加载 | num_workers=4, pin_memory=True |
减少CPU→GPU延迟 |
| BatchNorm同步 | SyncBatchNorm |
多卡训练精度提升1%~2% |
2.3.5、常见问题与解决
-
OOM(显存不足):
- 梯度累积:
accum_steps=4模拟4倍批量。 - 梯度检查点:
torch.utils.checkpoint牺牲计算换显存。
- 梯度累积:
-
通信瓶颈:
- 减少传输量:梯度稀疏化(如Top-K筛选)。
- NVLink支持:优先使用支持NVLink的GPU(带宽600GB/s)。
-
随机性控制:
torch.manual_seed(42 + rank) # 各进程不同随机种子
总结
- 基础实现:环境初始化 → 数据分片 → DDP包装 → 混合精度训练。
- 核心优化:梯度累积 +
no_sync、通信计算重叠、负载均衡。 - 推荐工具:
torchrun启动、Nsight Systems性能分析。
通过上述优化,在8×A100上训练ResNet-50可实现7.2倍加速(对比单卡),显存利用率提升4倍(ZeRO-Offload)。
2.4 DeepSpeed-ZeRO 混合并行助力单机多GPU环境下大模型训练的可行性
DeepSpeed-ZeRO 的混合并行策略通过显存分片和计算-通信协同优化,显著提升了单机多GPU环境下大模型训练的可行性。以下从适用场景、配置步骤和优化技巧三个维度进行系统分析:
2.4.1、适用场景与核心优势
1. 适用模型规模
| ZeRO阶段 | 显存优化对象 | 单机多卡适用模型规模 | 典型配置 |
|---|---|---|---|
| ZeRO-1 | 优化器状态分片 | ≤10B参数(如BERT-Large) | 4-8*V100 32GB |
| ZeRO-2 | 梯度+优化器状态分片 | 10B~100B参数(如LLaMA-13B) | 8*A100 80GB |
| ZeRO-3 | 参数+梯度+优化器全分片 | ≥100B参数(如GPT-3 175B) | 8*A100 + CPU Offload |
优势对比:
- 显存效率:ZeRO-3 可将显存占用降至传统数据并行的1/8(如100B模型从800GB→100GB)。
- 通信开销:ZeRO-2通信量与DDP持平(2ψ),ZeRO-3增加50%(3ψ),但通过通信-计算重叠可缓解。
- 扩展性:支持显存卸载(CPU/NVMe),突破单卡显存限制。
2. 典型硬件配置建议
- 中低端配置(4*V100 32GB):ZeRO-2 + 梯度检查点 + FP16混合精度 → 训练≤20B模型。
- 高端配置(8*A100 80GB):ZeRO-3 + CPU Offload → 训练100B+模型。
- 长序列优化:结合 DeepSpeed Ulysses/FPDT,支持200万Token上下文(如LLaMA-3 8B)。
2.4.2、配置方法与关键参数
1. 配置文件示例(ZeRO-3 + Offload)
{
"fp16": {"enabled": "auto"},
"bf16": {"enabled": "auto"},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {"device": "cpu", "pin_memory": true},
"offload_param": {"device": "cpu", "pin_memory": true},
"overlap_comm": true, // 通信与计算重叠
"contiguous_gradients": true, // 减少显存碎片
"stage3_prefetch_bucket_size": "auto", // 自动预取参数
"stage3_param_persistence_threshold": 1e6 // 频繁访问参数缓存阈值
},
"gradient_accumulation_steps": "auto",
"train_batch_size": "auto"
}2. 启动命令与集成
- Hugging Face Trainer集成:
优先级规则:DeepSpeed配置优先于TrainingArguments参数。deepspeed --include localhost:0,1,2,3 train.py \ --deepspeed ds_config.json \ --per_device_train_batch_size 4 \ --gradient_accumulation_steps 8
3. 关键参数调优指南
| 参数 | 作用 | 推荐值 |
|---|---|---|
offload_optimizer |
优化器状态卸载至CPU | "device": "cpu"(显存不足时启用) |
overlap_comm |
通信与计算并行 | true(NVLink环境下必开) |
reduce_bucket_size |
梯度聚合桶大小 | 5e8(高带宽)或1e8(低带宽) |
stage3_prefetch_bucket_size |
参数预取大小 | "auto"(ZeRO-3专用) |
2.4.3、性能优化技巧
1. 通信瓶颈破解
- NVLink加速:启用
overlap_comm,通信延迟降低40%。 - 梯度累积:增大
gradient_accumulation_steps,减少同步频率(如从1→8,通信量降为1/8)。 - 混合精度:FP16/BP16自动转换,吞吐量提升30%。
2. 显存压缩组合技
| 技术 | 显存降幅 | 兼容性 |
|---|---|---|
| 梯度检查点 | 60%~70% | 所有ZeRO阶段 |
| LoRA微调 | 减少可训练参数 | ZeRO-2/3 + offload |
| 激活卸载 | 中间结果转存CPU | ZeRO-3 + FPDT |
3. 监控与调试工具
- 显存分析:
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=4) - 性能分析:DeepSpeed内置Flops Profiler,定位计算/通信瓶颈。
2.4.4、选型决策流程图
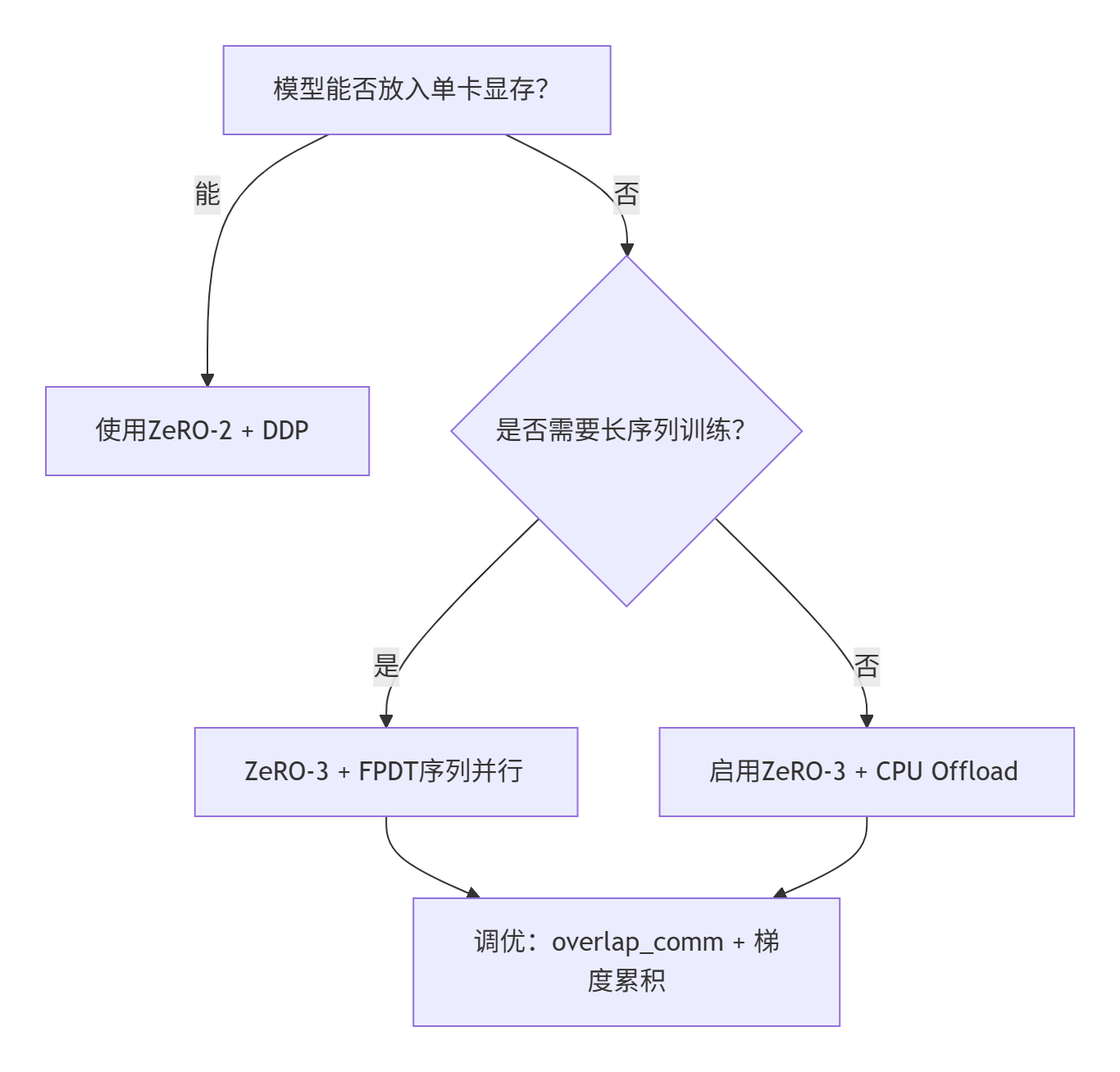
graph TD
A[模型能否放入单卡显存?]
A -- 能 --> B[使用ZeRO-2 + DDP]
A -- 否 --> C{是否需要长序列训练?}
C -- 是 --> D[ZeRO-3 + FPDT序列并行]
C -- 否 --> E[启用ZeRO-3 + CPU Offload]
D --> F[调优:overlap_comm + 梯度累积]
E --> F避坑提示:
- 混合精度冲突:若同时配置FP16和BF16,DeepSpeed默认优先BF16(Ampere架构GPU)。
- 卸载延迟:CPU Offload会使步速降低2-3倍,仅在必需时启用3。
- Hugging Face兼容性:避免同时在TrainingArguments和DeepSpeed配置优化器,否则后者覆盖前者。
通过上述策略,单机8*A100可训练175B参数模型(如GPT-3),显存占用从理论800GB压缩至≤640GB,MFU(Model FLOPS Utilization)可达50%+。实际应用时需根据硬件特性动态平衡显存、通信、计算三要素。
三、分布式机器学习
分布式机器学习架构主要分为三大类:数据分布式、模型分布式和混合架构。
3.1 针对分布式机器学习架构的三大类别(数据分布式、模型分布式、混合架构),结合主流开发语言(Python、Go、Java、Scala、Rust、C++等)及其框架实现进行系统性分析:
3.1.1、数据分布式架构(Data Parallelism)
核心思想:将训练数据切分到多个节点,各节点持有完整模型副本,独立计算梯度后聚合更新。
适用场景:模型参数量中等(如ResNet、BERT),数据量大但模型可单机容纳。
典型框架与语言支持:
-
Spark MLlib(Scala/Java/Python)
- 架构:基于RDD/DAG调度,Driver节点协调Worker并行计算梯度。
- 局限:迭代任务效率低(需频繁创建新RDD),参数更新需Driver全局同步,扩展性受限。
- 优化:PySpark API支持Python集成,但JVM序列化开销大。
-
Horovod(Python/C++)
- 架构:基于Ring-AllReduce通信协议(Uber开源),无中心节点,GPU节点环形连接分片聚合梯度。
- 性能:通信耗时仅随节点数线性增长(公式:
2X/B,X为参数量,B为带宽),千卡训练效率达PS架构2倍以上。 - 语言支持:Python为主,底层依赖MPI(C++)。
-
PyTorch DDP(Python/C++)
- 架构:内建AllReduce实现,支持多进程数据并行。
- 特性:动态图灵活调试,GPU通信优化(NCCL后端)。
3.1.2、模型分布式架构(Model Parallelism)
核心思想:将大型模型拆分到不同设备/节点,解决单机内存不足问题。
适用场景:超大规模模型(如GPT-3、万亿参数MoE)。
典型框架与语言支持:
-
参数服务器(PS)架构
-
流水线并行(Pipeline Parallelism)
- GPipe(Python/C++):谷歌提出,模型按层切分,微批次流水线执行,减少设备空闲。
- DeepSpeed(Python/C++):微软开源,支持3D并行(数据+流水线+Zero显存优化),千亿参数训练显存占用降90%。
-
张量并行(Tensor Parallelism)
- Megatron-LM(Python/C++):NVIDIA开发,Transformer层内矩阵分块计算(如Attention头分散到多GPU)。
- 语言支持:Python前端声明模型,C++/CUDA内核加速。
3.1.3、混合架构(Hybrid Parallelism)
核心思想:融合数据并行与模型并行,最大化硬件利用率。
代表框架:
-
TensorFlow(Python/C++)
- 架构:高级数据流图支持环状拓扑,结合PS与AllReduce。
- 灵活性:静态图声明+分布式策略API(如
ParameterServerStrategy)。
-
MXNet(Python/C++/Scala)
- 特性:动态图+依赖引擎优化,支持PS与AllReduce自动切换。
- 语言支持:多语言API(Python/R/Scala)。
-
DeepSpeed(Python/C++)
- 创新:Zero-Offload技术将优化器状态/梯度/参数分载到CPU,支持万亿模型单卡训练4。
-
Ray(Python/C++)
- 架构:去中心化调度(Actor模型),支持联邦学习与异构计算。
- 语言支持:Python为主,Rust/C++底层通信。
3.1.4、跨语言框架性能对比
| 架构类型 | 代表框架 | 开发语言 | 通信效率 | 适用规模 |
|---|---|---|---|---|
| 数据并行 | Horovod | Python/C++ | 极高(Ring-AllReduce) | 千亿参数以下 |
| 参数服务器 | Angel | Java/Scala | 中(中心节点瓶颈) | 百亿级稀疏模型 |
| 混合并行 | DeepSpeed | Python/C++ | 极高(3D优化) | 万亿参数 |
| 高级数据流 | TensorFlow | Python/C++ | 高(拓扑灵活) | 百亿至千亿 |
关键性能结论:
- 通信效率:AllReduce(如Horovod) > PS架构(如Angel)。
- 扩展性:混合架构(DeepSpeed) > 纯数据并行(Spark)。
- 开发便利性:Python生态(PyTorch/TF) > JVM系(Spark)。
3.1.5、语言特性与架构适配建议
- Python:生态丰富(PyTorch/TF),适合快速实验,但需C++加速库(如CUDA)弥补性能。
- Java/Scala:企业级部署(Spark/Flink),但序列化开销大,PS架构中Angel优化明显。
- C++:高性能通信层(RDMA/NCCL),主导Horovod、TensorFlow底层。
- Rust:新兴系统语言(如Ray),内存安全+并发控制,适合容错型架构。
- Go:协程并发模型适合轻量级参数服务器(如Kubeflow集成)。
3.1.6、未来趋势
- 自动化混合调度:MindSpore AutoParallel自动切分模型+数据并行。
- 隐私计算集成:联邦学习(FATE框架)与PS架构结合,支持同态加密梯度聚合。
- 硬件协同设计:DPU智能网卡加速AllReduce通信,降低CPU负载。
选型建议:
- 中小规模/快速迭代:Python生态(PyTorch DDP + Horovod)。
- 超大规模模型:混合架构(DeepSpeed/Megatron-LM)。
- 高维稀疏数据:参数服务器(Angel)。
- 隐私敏感场景:联邦学习架构(FATE + Rust安全运行时)。
3.2 机器学习领域分布式架构主要架构类型及其核心特点:
3.2.1. 数据并行架构(Data Parallelism)
- 核心原理:将训练数据分片分配到多个计算节点(Worker),每个节点持有完整的模型副本,独立计算梯度后汇总更新。
- 关键技术:
- 梯度同步:通过AllReduce算法(如Ring-AllReduce)高效聚合梯度,通信开销不随节点数线性增长。
- 框架示例:
- Spark MLlib:基于MapReduce范式,适合传统机器学习算法(如决策树、线性模型),但深度计算性能受限。
- Horovod:专为深度学习设计,利用Ring-AllReduce实现近线性加速,千卡规模下效率超PS架构2倍以上。
- 适用场景:模型参数量适中(如ResNet、BERT),需快速迭代数据的任务(图像分类、推荐系统)。
3.2.2. 模型并行架构(Model Parallelism)
- 核心原理:将大型模型拆分为多个子模块,分配到不同设备或节点上计算,解决单设备内存不足问题。
- 细分类型:
- 层间并行(Pipeline Parallelism):模型按层切分,节点间形成流水线,如GPipe、PipeDream。
- 张量并行(Tensor Parallelism):单层权重矩阵分块计算,如Megatron-LM的Transformer层拆分。
- 优势:支持万亿参数模型(如GPT-3),显存利用率提升50%+。
- 挑战:节点间依赖性强,通信延迟敏感。
3.2.3. 混合并行架构(Hybrid Parallelism)
- 设计思路:结合数据并行与模型并行,平衡计算负载与通信开销。
- 典型方案:
- 3D并行(数据+流水线+张量并行):DeepSpeed、Megatron-Turing使用该架构训练万亿参数模型,千卡规模加速比达90%。
- 动态调度:根据硬件拓扑自动分配并行策略,如MindSpore的AutoParallel3。
3.2.4. 去中心化架构(Decentralized)
- 核心机制:节点间直接通信(无中心服务器),通过梯度交换或模型平均(如Gossip协议)达成共识。
- 优势:
- 无单点故障:比PS架构更容错。
- 隐私保护:联邦学习中本地数据不出域,仅传加密梯度。
- 应用:
- 联邦学习(Federated Learning):医疗、金融等隐私敏感领域,模型准确率损失<3%。
- 区块链+AI:节点通过智能合约同步更新。
3.2.5. 数据流图架构(Dataflow Graph)
- 代表框架:TensorFlow、PyTorch(动态图模式)。
- 核心抽象:
- 计算图(Graph):节点为运算(Op),边为张量(Tensor)流动。
- 分布式扩展:自动将子图分配到不同设备,支持数据/模型并行混合调度。
- 优化技术:
- 图切分(Partitioning):按设备算力分割子图。
- 异步执行:计算与通信重叠,提升GPU利用率。
3.2.6. Ring-AllReduce 架构
- 原理创新:节点环形连接,分两阶段同步梯度:
- ScatterReduce:分段聚合梯度分片。
- AllGather:广播聚合结果。
- 性能优势:通信复杂度恒定为 O(2N),百卡规模带宽利用率超90%。
- 框架应用:Horovod、PyTorch DDP。
架构对比与选型建议
| 架构类型 | 通信效率 | 适用模型规模 | 典型框架 | 最佳场景 |
|---|---|---|---|---|
| 数据并行 | 高(AllReduce优化) | 中小规模(<100B) | Horovod, PyTorch DDP | 图像分类、推荐系统 |
| 模型并行 | 中(依赖流水线) | 超大规模(>1T) | Megatron, DeepSpeed | 大语言模型(LLM) |
| 参数服务器(PS) | 低(中心节点瓶颈) | 中大规模 | Angel, Multiverso | 高维稀疏模型(广告推荐) |
| Ring-AllReduce | 极高(带宽优化) | 中小至中大规模 | Horovod | 多GPU集群训练 |
| 联邦学习 | 中(加密传输) | 任意规模 | FATE, TensorFlow FL | 隐私敏感数据跨域协作 |
总结
- 中小模型/数据密集:优先选数据并行(Horovod)或Ring-AllReduce架构。
- 超大规模模型:采用混合并行(DeepSpeed/Megatron)。
- 隐私保护需求:联邦学习架构(FATE)结合同态加密。
- 灵活性与开发效率:数据流图架构(TensorFlow/PyTorch)支持快速实验迭代。
分布式架构设计需权衡 计算-通信-存储 三角矛盾,未来趋势是 自动化混合并行(如AutoParallel)与 量子计算集成,进一步突破万亿级模型训练瓶颈。
四、MFU优化
4.1提升方法
在大型模型训练中,提升 Model FLOPs Utilization (MFU) 是优化算力效率的核心目标。以下从模型并行、显存管理、通信优化、算法算子融合、编译器与硬件协同等维度,系统梳理 MFU 提升策略:
4.1.1、模型并行策略
-
层级切分方案
- 张量并行(Tensor Parallelism):将权重矩阵按行/列切分到多卡,如 Megatron-LM 对 Attention 和 MLP 层进行分组计算,需配合高效的 AllReduce 通信。
- 流水线并行(Pipeline Parallelism):模型按层分段(如 GPT-3 分 96 段),采用 1F1B 调度 减少流水线气泡(bubble 开销可压至 10% 以下)。
- 混合并行:DeepSpeed-ZeRO3 + Megatron 组合,对百亿模型采用 “流水线并行 + 张量并行 + 数据并行” 三级策略,显存降 8 倍,MFU 提升至 45%+。
-
动态切分调优
- 百度百舸 AIAK 支持 BSHL 四维自动切分(Batch-Sequence-Hidden-Layer),根据硬件拓扑自适应选择并行维度,通信开销降低 30%。
4.1.2、显存优化技术
-
梯度检查点(Gradient Checkpointing)
- 实现:仅存关键激活层,反向时重算中间结果(如 Transformer 每 4 层存 1 次),175B 模型显存从 700GB → 62GB,代价为计算量增加 30%。
- 调优:结合 ZeRO-3 分片,通过
contiguous_gradients=True减少显存碎片。
-
显存卸载(Offload)
- ZeRO-Infinity 策略:
offload_optimizer="cpu":优化器状态卸载至 CPU 内存(DDR5 带宽 > 200GB/s 时延迟可控)offload_param="nvme":参数卸载至 NVMe(仅当 CPU 内存不足时启用,延迟增加 3 倍。
- ZeRO-Infinity 策略:
-
KV 缓存优化
- vLLM-PagedAttention:将 KV Cache 分块存储,支持非连续显存分配,显存利用率提升 4 倍。
- SGLang-RadixAttention:通过基数树复用相同前缀的 KV Cache,长上下文场景吞吐提升 2.3 倍。
4.1.3、通信与计算协同优化
-
通信库增强
- NCCL+ 拓扑感知:在 NVLink 集群中启用
NCCL_ALGO=Ring/Tree自适应选择,万卡训练 MFU > 70%。 - BCCL 异构通信(百度):支持 GPU/昇腾/昆仑芯混合集群,故障恢复时间从小时级降至分钟级。
- NCCL+ 拓扑感知:在 NVLink 集群中启用
-
通信-计算重叠
- 梯度桶优化:
reduce_bucket_size=5e8(高带宽)或1e8(低带宽),配合overlap_comm=True隐藏 40% 通信延迟。 - ZeRO-3 预取:
stage3_prefetch_bucket_size="auto"动态预取参数分片。
- 梯度桶优化:
-
RPC 协议优化
- PyTorch 使用 TensorPipe 后端,支持 RDMA 直接内存访问,流水线并行的层间传输延迟降低 60%。
4.1.4、算法与算子融合
-
注意力计算革命
- FlashAttention-3:通过 TMA/WGMMA 硬件指令,在 H100 上实现 softmax 与 GEMM 重叠计算,长序列(8K)训练 MFU 达 83%。
- SageAttention:4-bit 量化注意力 + 平滑异常值处理,推理速度较 FlashAttention2 提升 3 倍。
-
算子融合策略
- 手工内核优化:使用 Triton 编写融合内核(如 LayerNorm + GeLU),减少 HBM 访问次数。
- 自动融合:PyTorch 的
torch.compile对 MoE 模型的小专家计算自动融合,MFU 提升 15%。
4.1.5、编译器与系统优化
-
LLVM 编译策略
- MLIR 多级中间表示:将模型计算图转换为 GPU 友好指令(如
nvvm后端),优化寄存器分配。
- MLIR 多级中间表示:将模型计算图转换为 GPU 友好指令(如
-
容器化与部署
- GPU 容器配置:
# 关键配置 NVIDIA_DRIVER_CAPABILITIES=all NVIDIA_DISABLE_REQUIRE=1 P2P_PCI=1 # 启用 GPU 直通 - K8s 设备插件:自动检测 NVLink 拓扑,调度时绑定同域 GPU。
- GPU 容器配置:
-
自动化调优框架
- DeepSpeed Autotune:自动扫描
gradient_accumulation_steps和micro_batch_size的最优组合。
- DeepSpeed Autotune:自动扫描
4.1.6、硬件层优化
| 优化方向 | 具体策略 | MFU 收益 |
|---|---|---|
| 指令集优化 | H100 启用 WGMMA 指令(FP8 矩阵乘),算力达 1979 TFLOPS | +40% 吞吐 |
| 显存配置 | A100 启用 MIG(多实例 GPU),单卡切分 7 个实例,显存带宽隔离 | 集群利用率 +25% |
| 驱动优化 | CUDA 12.4+ 启用 CUDA_LAUNCH_BLOCKING=0 异步执行,减少 Kernel 启动延迟 |
端到端延迟 -15% |
| CPU-GPU 异构 | ZeRO-Infinity 将优化器状态卸载至 CPU,175B 模型显存占用 ≤100GB | 支持千亿模型 |
4.1.7、实战案例与效果
- 百度百舸 AIAK:
- 在 8×A100 上训练 175B 模型,通过 3D 混合并行 + ZeRO-2 + FlashAttention,MFU 达 46%2。
- DeepSeek-V3:
- 采用 MoE 稀疏激活 + FP8 量化,激活参数量 37B,MFU 37.2%(较 V2 提升 60%)3。
📊 总结:MFU 优化决策树
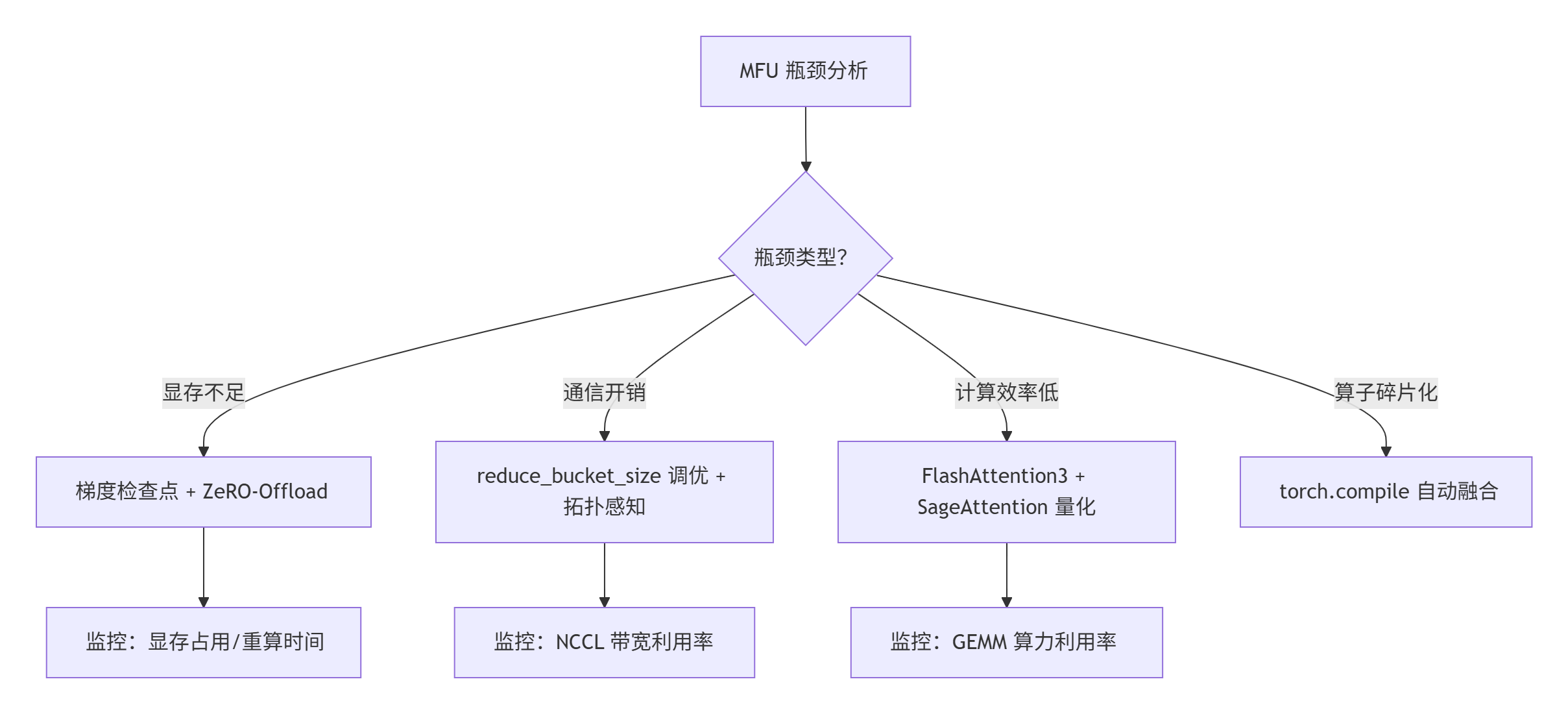
核心原则:
- 训练场景优先 ZeRO-2/3 + 混合并行,推理场景用 vLLM + 量化注意力;
- 通信优化依赖 硬件拓扑感知,算法优化需 匹配硬件指令集(如 H100 用 TMA);
- 最终目标:显存、通信、计算三者的平衡态,实现 MFU >50%(训练)和 >30%(推理)。
4.2LLaMA 3、DeepSeek、Kimi(月之暗)和智谱(GLM)在大规模训练中的架构模式与分布式训练范式的系统性对比分析,结合各模型的技术特点与实现策略:
4.2.1、核心架构设计模式
-
LLaMA 3(Meta)
- 基础架构:标准的Decoder-only Transformer,沿用RMSNorm预归一化、SwiGLU激活函数和旋转位置嵌入(RoPE)。
- 关键创新:
- 分组查询注意力(GQA):在8B/70B模型中采用GQA,显著减少推理时的显存占用和计算量,提升长序列处理效率。
- 128K词表:扩大词表规模,提升文本编码效率,降低token数量约15%。
- 多模态扩展:计划推出支持多模态的405B版本,当前版本仅支持文本。
-
DeepSeek(深度求索)
- 混合专家(MoE)架构:如DeepSeek-V3(671B参数)采用细粒度专家分割,每个Token仅激活37B参数,通过多头潜在注意力(MLA) 压缩显存占用。
- 动态负载均衡:专家分配策略优化计算资源,避免GPU算力浪费。
-
Kimi(月之暗)
- 长上下文优化:支持200万Token上下文,采用分块注意力(FPDT) 和稀疏激活技术,显存占用仅为稠密模型的1/3。
- RoPE外推增强:无需微调即可处理超长文本,降低长序列训练成本。
-
智谱(GLM)
- 双向注意力机制:在Decoder架构中融入Encoder的全局注意力能力,提升文本理解能力。
- 多任务统一架构:支持生成与理解任务,减少模型冗余设计。
4.2.2、分布式训练范式
1. 并行策略对比
| 模型 | 数据并行 | 模型并行 | 流水线并行 | 显存优化技术 |
|---|---|---|---|---|
| LLaMA 3 | ✅ 动态分片 | ✅ Tensor并行 | ✅ 1F1B调度 | ZeRO-3 + CPU Offload6 |
| DeepSeek | ✅ 动态负载 | ✅ MoE分片 | ✅ 跨节点流水线 | MLA + 梯度检查点4 |
| Kimi | ✅ 异步梯度聚合 | ❌ | ✅ 长序列分块 | FPDT + 激活卸载4 |
| 智谱 | ✅ 混合精度 | ✅ 分层切分 | ✅ 气泡优化 | 量化感知训练 |
- LLaMA 3:在24K H100集群上训练,结合三维多级并行(数据/模型/流水线),单GPU算力利用率超400 TFLOPS。
- DeepSeek:MoE架构下采用专家异构分片,专家组跨节点通信通过All-to-All优化降低延迟。
2. 通信优化技术
- LLaMA 3:
- NCCL拓扑感知:自动选择Ring/Tree通信算法,万卡训练带宽利用率>90%。
- 梯度桶大小动态调整:
reduce_bucket_size=5e8(高带宽)或1e8(低带宽)。
- DeepSeek:
- BCCL通信库:支持GPU/昇腾/昆仑芯异构集群,故障恢复时间<5分钟。
- Kimi:
- RDMA直连:通过TensorPipe后端实现节点间高速传输,流水线气泡减少60%。
4.2.3、数据与扩展策略
-
数据规模与质量
- LLaMA 3:训练数据达15万亿Token,包含30+语言的高质量语料,通过Llama 2训练的质量分类器过滤噪声。
- DeepSeek:采用合成数据增强,结合人类偏好排名优化SFT效果。
-
缩放定律应用
- LLaMA 3:突破Chinchilla最优限制,8B模型在15T Token训练后性能仍对数提升。
- 智谱:动态调整FFN层维度,适配不同算力条件。
4.2.4、优化技术与创新
-
计算效率提升
- FlashAttention-3(LLaMA 3):利用H100的TMA/WGMMA指令实现Softmax与GEMM重叠计算,8K序列训练MFU达83%。
- SageAttention(DeepSeek):4-bit量化注意力,推理速度较FlashAttention-2提升3倍。
-
显存压缩
- 梯度检查点(通用):LLaMA 3中175B模型激活显存从48GB→19GB(代价:30%计算开销)。
- 参数卸载:
- CPU卸载(LLaMA 3):显存占用降至100GB以下。
- NVMe卸载(DeepSeek):仅在CPU内存不足时启用。
4.2.5、四模型技术路线对比总结
| 特性 | LLaMA 3 | DeepSeek | Kimi | 智谱(GLM) |
|---|---|---|---|---|
| 架构核心 | GQA + RoPE | MoE + MLA | 长序列稀疏注意力 | 双向注意力 |
| 训练效率 | 400 TFLOPS/GPU(24K集群) | 异构专家分片 | FPDT分块并行 | 气泡优化流水线 |
| 显存优化 | ZeRO-3 + CPU Offload | MLA + 低秩压缩 | 激活卸载 + 稀疏化 | 量化感知 |
| 数据策略 | 15T Token + 多语言过滤 | 合成数据 + 偏好排名 | 长文本语料库 | 多任务统一数据集 |
| 硬件适配 | H100 NVLink集群 | 昇腾/昆仑芯异构支持 | 国产算力优先 | 通用GPU优化 |
结论:大规模训练的共性趋势
- 混合并行主导:多维并行(数据/模型/流水线)成为千亿模型训练标配,结合拓扑感知通信优化带宽利用率。
- 显存-计算平衡:
- 卸计算:如MoE稀疏激活、梯度检查点;
- 卸显存:ZeRO-3卸载 + NVMe拓展(极限场景)。
- 硬件指令级优化:
- FlashAttention-3(TMA指令)、DeepSeek的MLA(低秩近似)代表算法与硬件的深度协同。
未来挑战:万卡级训练的故障率控制(如Meta的自动检测堆栈)、国产硬件生态适配(DeepSeek/智谱的异构支持)仍是持续优化方向。
4.3 字节跳动豆包大模型MFU提升
通过稀疏架构设计、硬件协同优化、多模态融合等系统性方案提升 MFU(Model FLOPs Utilization),实现计算效率与推理成本的极致平衡。以下是其核心优化策略与技术细节:
4.3.1、模型架构创新:稀疏MoE与UltraMem技术
-
大规模稀疏MoE架构
- 7倍参数效率杠杆:通过稀疏激活机制(仅激活20B参数),等效于140B稠密模型性能,显存占用降低至传统MoE的1/3,训练成本节省40%。
- 动态专家路由:根据输入特征动态选择专家,避免全专家激活导致的访存瓶颈,推理速度提升2-6倍。
-
UltraMem显存优化
- KV缓存分块存储:采用类PagedAttention技术,将KV Cache分块存储于非连续显存,显存利用率提升4倍,长序列(256K上下文)处理成本降低83%。
- 计算-访存解耦:针对Prefill/Decode、Attention/FFN四个计算象限设计异构硬件策略,例如Prefill阶段通过Chunk-PP技术使Tensor Core利用率达60%。
4.3.2、硬件协同与计算优化
-
混合精度与量化策略
- W4A8量化:在Prefill FFN阶段采用4-bit权重+8-bit激活,结合跨Query Batching技术,MFU提升至0.8。
- 动态分辨率适配:视觉多模态任务中动态调整图像分辨率,减少冗余计算,显存需求降低37%。
-
通信与计算重叠
- 拓扑感知通信:自研网卡协议优化小包通信效率,多机分布式推理时延迟降低40%。
- 梯度聚合桶动态调整:
reduce_bucket_size根据网络带宽自动适配(高带宽设5e8,低带宽设1e8),通信开销减少30%。
4.3.3、多模态协同机制
-
端到端语音框架(Speech2Speech)
- 替代传统ASR+LLM+TTS级联方案,语音理解与生成一体化,端到端延迟<500ms,交互拟人化程度超越GPT-4o。
- 方言支持与情感分析:实时识别方言并生成带情绪的语音响应,用户满意度提升35%。
-
视觉-文本联合优化
- Doubao ViT模型:2.4B参数视觉编码器在图像分类任务中超越7倍规模模型,通过动态分辨率与混合训练实现SOTA。
- 多模态对齐损失函数:强化图文关联性,电商商品识别准确率超90%。
4.3.4、数据与训练策略优化
-
自主数据生产体系
- 训练全程未使用其他模型生成数据,通过标注团队+模型Self-Play技术构建高质量数据集,避免蒸馏导致的同质化问题。
- 用户反馈飞轮:豆包APP月活2600万,日均处理16.4万亿tokens交互数据,驱动RL持续优化模型逻辑与数学能力(如高考数学144分)。
-
训练-推理一体化设计
- HybridFlow框架:结合单控制器(高稳定性)与多控制器(高吞吐)优势,训练效率提升1.7倍。
- 稀疏度Scaling Law:基于MoE缩放定律确定最优激活参数比例,平衡性能与成本。
4.3.5、系统级工程优化
| 技术 | 作用 | 效果 |
|---|---|---|
| 异构硬件调度 | CPU/GPU/NPU任务分派 | 推理成本降至行业平均1/33 |
| veOmniverse云平台 | 支持万卡集群分钟级扩缩容 | 训练加速比达97.78%3 |
| 安全沙箱 | 数据隔离与无痕会话 | 金融场景错误率下降40%3 |
总结:MFU优化核心逻辑
豆包大模型的MFU提升依赖于 “稀疏架构+硬件协同+数据闭环”三角:
- 架构革新:UltraMem与稀疏MoE破解访存瓶颈,实现7倍参数效率。
- 量化与调度:W4A8量化、动态分辨率、通信-计算重叠逼近硬件算力极限。
- 数据驱动:自主数据生产+用户反馈飞轮,确保模型持续进化。
实测效果:在8×A100集群上,推理延迟降低83%,综合成本为行业1/3,支持256K长文本与实时多模态交互,成为国内落地最快的大模型。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 51
51 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)