
多文件上传 前端压缩 解压 大文件上传
多文件上传,前端压缩 大文件切片上传 前端解压
问题描述 :
项目开发过程中,客户要求本地我们一次性要上传1000张图片到后台。上传流程没有问题,但是运行上
传这个功能后,内存被消耗满了甚至达到100%。
问题表现 :
开启文件上传,整个项目卡顿,排查后发现内存已经消耗90%-100%左右。
解决思路:
原来上传方案:上传一张图片就调用一次后端接口,导致前端上传多了,浏览器线程被占满,上传是异
步的,服务器处理的时间如果不及时,前端会一直占用浏览器线程。导致前端开销很大。
解决思路:
- 选取1000张图片后,对所有文件进行压缩打包
- 对压缩包进行切片上传,后台合并切片
- 下载压缩文件,对文件进行解压浏览
页面效果
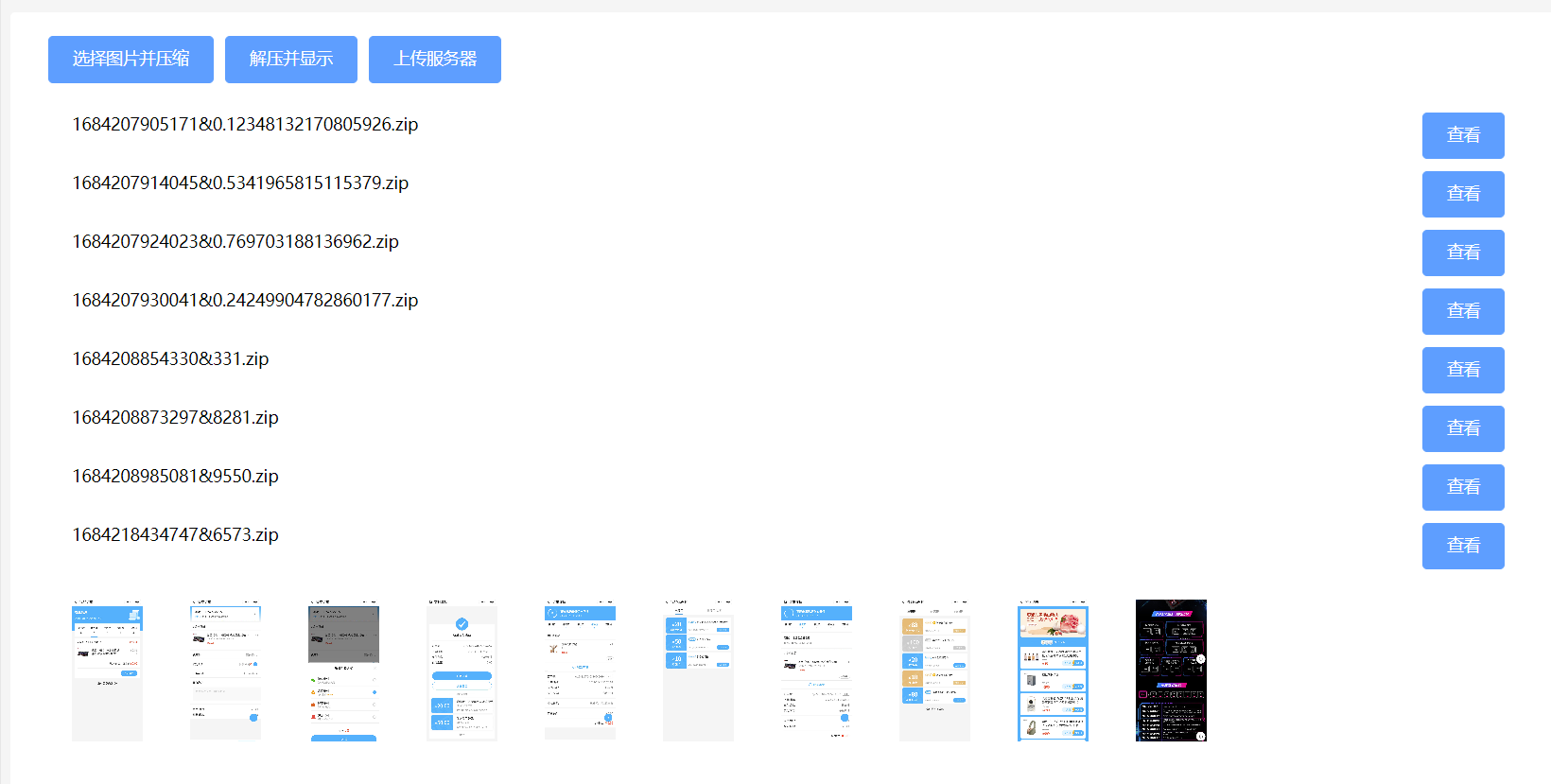
压缩与解压
插件:jszip
https://stuk.github.io/jszip/
安装
npm install jszip
官方示例
var zip = new JSZip();
zip.file("Hello.txt", "Hello World\n");
var img = zip.folder("images");
img.file("smile.gif", imgData, {base64: true});
zip.generateAsync({type:"blob"})
.then(function(content) {
// see FileSaver.js
saveAs(content, "example.zip");
});
对文件进行压缩
async tirggerFile(event) {
const zip = new JSZip();
// 获取的文件列表
var files = event.target.files;
//console.log(files);
// 用于计算文件总大小
let size = 0
for (let item of files) {
size += parseInt(item.size)
// 读取文件
zip.file(item.name, item)
}
// 压缩文件
this.zipFile = await zip.generateAsync({
type: "blob", // 压缩类型
compression: "DEFLATE", // STORE:默认不压缩 DEFLATE:需要压缩
compressionOptions: {
level: 6 // 压缩等级1~9 1压缩速度最快,9最优压缩方式
// [使用一张图片测试之后1和9压缩的力度不大,相差100字节左右]
}
})
console.log(this.zipFile);
console.log('选择文件大小:' + size / 1024 / 1024);
console.log('压缩后大小:' + this.zipFile.size / 1024 / 1024);
// 通过时间戳加上随机数生成文件名
this.zipFileName = new Date().getTime() + '&' + parseInt(Math.random()*10000) + '.zip'
},
对文件解压
//读取文件 api
export const readFile = (url) => axios.get(url, {
headers: { 'Content-Type': 'application/json' },
responseType: 'blob',
withCredentials: true,
})
//解压文件
async decompress(url) {
const zip = new JSZip();
console.log('decompress');
//图片列表重置为空
this.imgArr = []
//获取文件
let file = await readFile(url)
//console.log(file);
//获取解压的文件
zip.loadAsync(file.data).then(zipData => {
console.log(zipData);
zipData.forEach((relativePath, zipEntry) => { // zipEntry 就是压缩文件中的文件实例
// 文件格式转换
zipEntry.async("base64").then((res) => {
// 将转换成base64 的图片 存入图片列表
this.imgArr.push('data:image/jpeg;base64,' + res)
})
})
}).catch(err=>{
console.log(err);
Message.error('解压错误,压缩包损坏')
})
},
大文件上传原理
当我们在做文件上传的功能时,如果上传的文件过大,可能会导致长传时间特别长,且上传失败后需要整个文件全部重新上传。因此,我们需要前后端配合来解决这个问题。
最常用的解决方案就是 —— 切片上传。
这次我们主要从以下三个方面来学习关于“大文件上传”的操作:
- 文件切片上传
- 文件秒传
- 文件断点续传
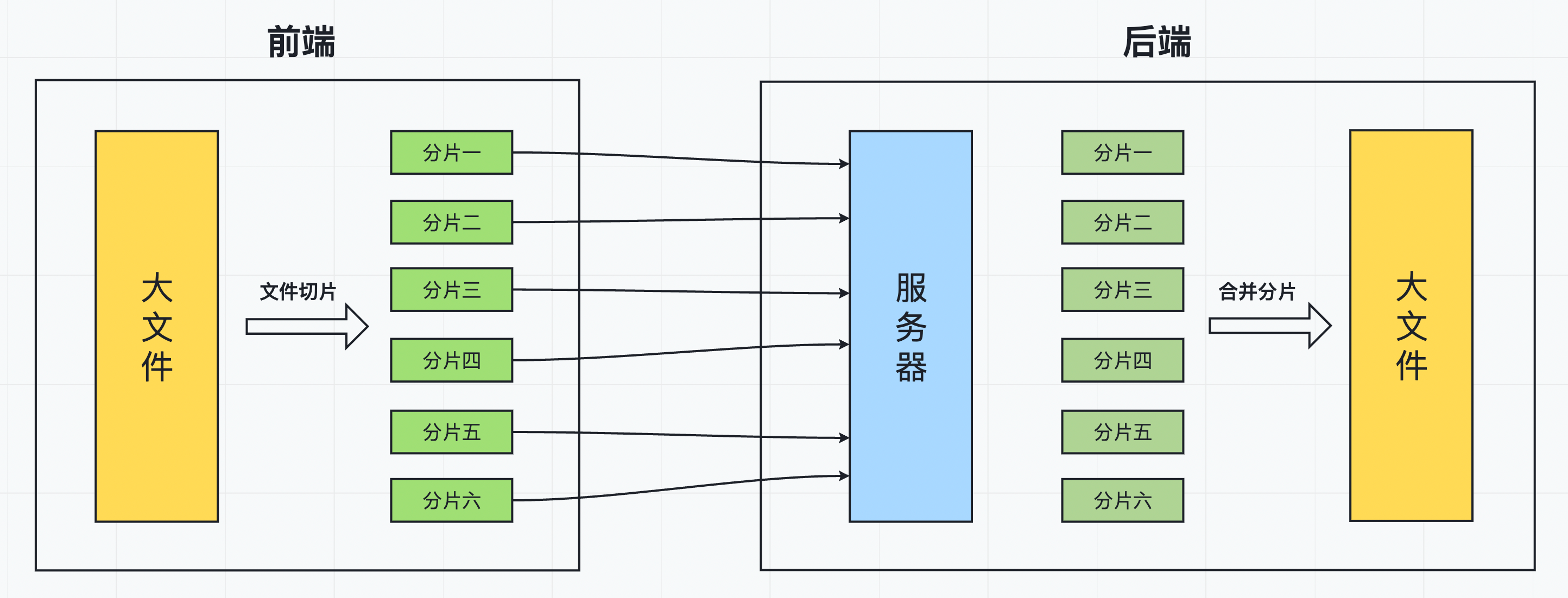
一、切片上传
切片上传,也叫分片上传。工作流程大致如下:
-
前端将一个大文件,拆分成多个小文件(分片);
-
前端将拆分好的小文件依次发送给后端(每一个小文件对应一个请求);
-
后端每接收到一个小文件,就将小文件保存到服务器;
-
当大文件的所有分片都上传完成后,前端再发送一个“合并分片”的请求到后端;
-
后端对服务器中所有的小文件进行合并,还原完整的大文件;
二、文件秒传
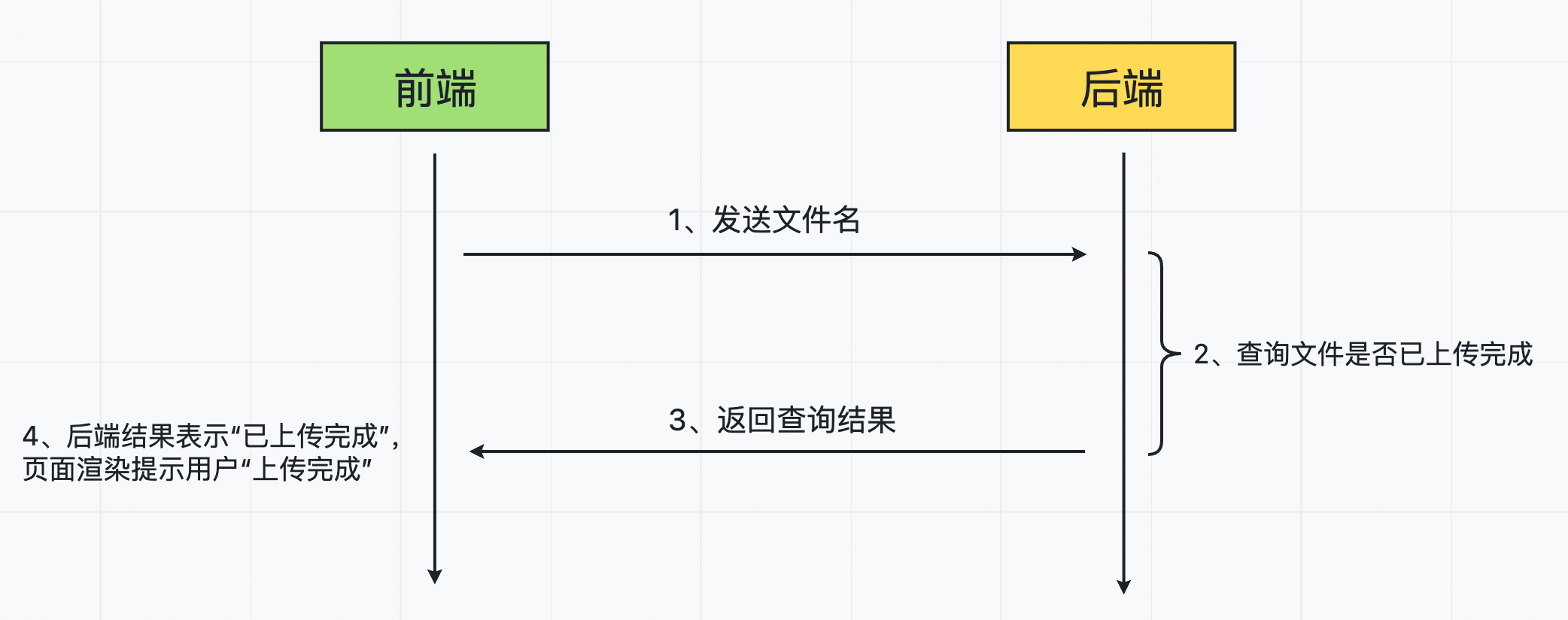
文件秒传,其实指的是文件不用传。如果某一个文件,在之前已经上传成功过,再次上传时,就可以直接提示用户“上传成功”。
工作流程大致如下:
- 上传文件前,将文件名发送到后端,来判断当前文件是否有上传完成过;
- 后端接收到文件名,查询上传成功的文件中是否有该文件,并返回查询结果给前端;
- 前端接收到查询结果,如果是已上传过的文件,则直接提示用户“上传成功”;
三、断点续传
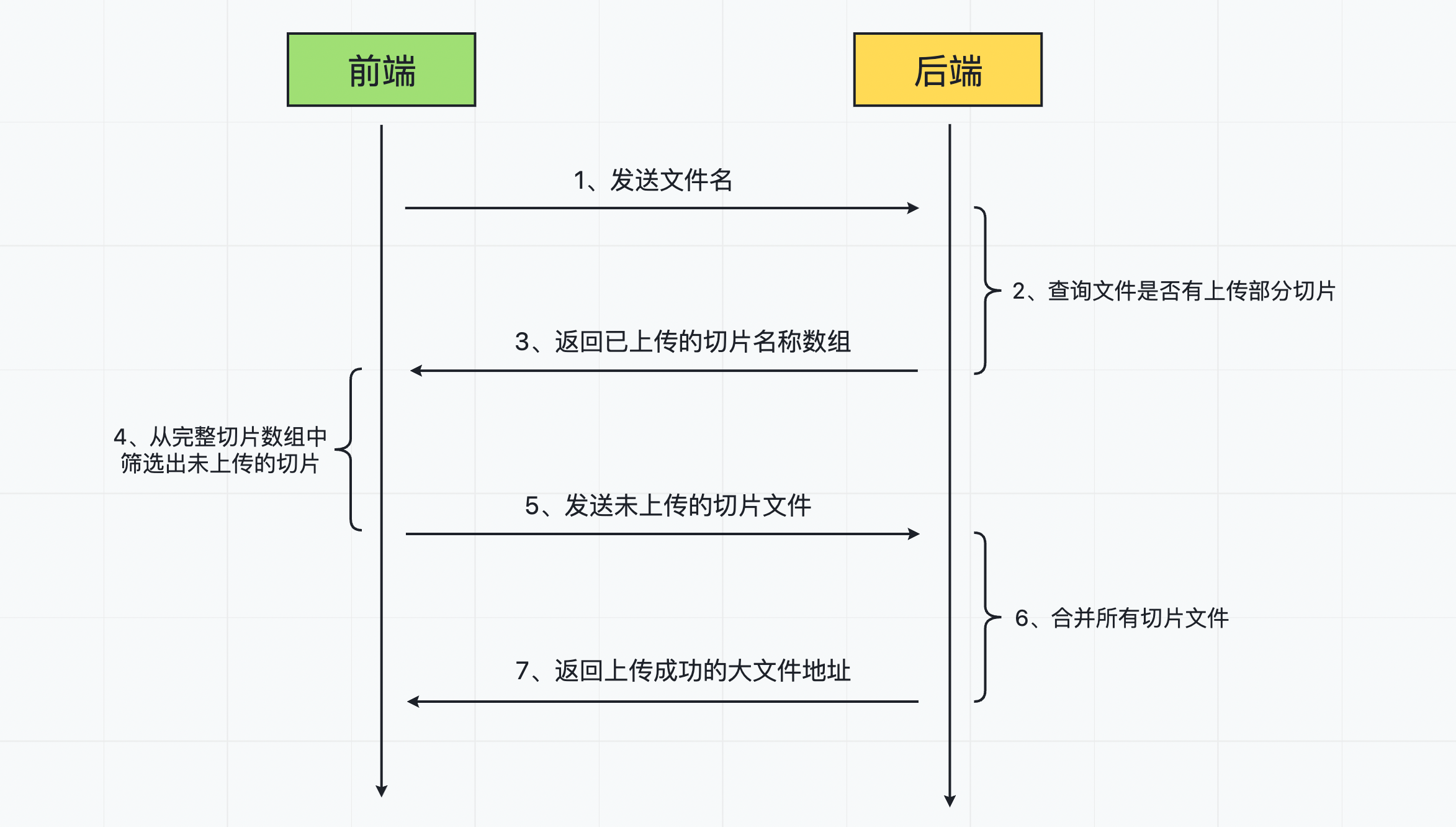
断点续传可以分为两种场景:
-
用户点击“暂停”按钮时,终止文件的上传;再点击“续传”按钮时,继续上传剩下部分;
-
用户在上传文件切片的过程中,由于外部原因(网络等)导致上传失败;后续重新上传时,可以接着上次失败的进度继续上传;
两种场景的处理方式其实和“文件秒传”是一样的,工作流程大致如下:
- 文件上传(续传)前,将文件名发送到后端,来判断当前文件是否有上传成功过的部分切片文件;
- 如果有上传过部分切片,后端将上传成功的切片文件名返回给前端;
- 前端从所有切片中,将已经上传成功的切片筛选出来,再将剩下未上传成功的切片重新发送给后端;
- 后端将所有切片合并,完成整个文件的上传;
大文件上传代码
前端相关API
/**
* 上传大文件
data: formData
*/
export const bigFile = async (data) => ajax('/common/bigFile',data)
/**
* 合并片段
data: {
chunkSize,
fileName: checkedFile.name
}
*/
export const mergeChunks = async (data) => ajax('/common/merge',data)
/**
* 验证文件是否上传过
data: {
fileName: checkedFile.name
}
*/
export const verifyFile = (data) => ajax('/common/verify',data)
// 获取文件列表
export const getFileList = () => ajax('/common/getFile',{},'GET')
前端实现代码
import { bigFile, mergeChunks, verifyFile } from '@/api/commonApi.js'
// 上传文件
async upload() {
// 判断是否有打包文件
if (!this.zipFile) return;
// 验证文件之前是否上传成功过
const res = await verifyFile({ fileName: this.zipFileName }).then(res => {
if (res.code == 1) {
//已经上传
Message.success('上传成功')
} else {
//没有上传
// 对文件进行切片 上传所有切片
this.uploadChunks(this.createChunks());
}
})
},
// 上传切片
uploadChunks(uploaded = []) {
// 处理切片数据格式
let formDataList = this.chunksList.map((chunkItem, index) => {
const formData = new FormData();
formData.append('file', chunkItem); // 切片文件信息
formData.append('fileName', this.zipFileName); // 完整文件名
formData.append('chunkName', index); // 切片名(将 index 作为每一个切片的名字)
return formData;
});
// 将处理好的文件切片 formData 数据中,还未上传的部分筛选出来
formDataList = formDataList.filter((_, index) => uploaded.indexOf(index + '') < 0);
// 依次上传每一个切片文件
const requestList = formDataList.map(formData => {
// console.log(formData.get('chunkName'));
return new Promise(resolve => {
bigFile(formData).then(() => {
resolve()
})
})
});
// 等待所有切片上传完成
Promise.all(requestList).then(() => {
console.log('Promise.all');
//向后台发起合并请求
mergeChunks({
chunkSize: this.chunkSize,
fileName: this.zipFileName
}).then(res => {
Message.success('上传成功')
this.chunksList = []
//重新获取文件列表
this.getData()
})
})
},
// 切片
createChunks() {
if (!this.chunksList.length) {
let start = 0; // 切片文件的起始位置
while (start < this.zipFile.size) {
// 文件切片
const chunkItem = this.zipFile.slice(start, start + this.chunkSize);
// 将切片保存到全局的切片数组中
this.chunksList.push(chunkItem);
start += this.chunkSize;
}
return this.chunksList
// 将文件切片的总数作为进度条的最大值
// progress.max = chunksList.length;
} else {
return this.chunksList
}
},
后端部分
app.js
const express = require('express');
const bodyParser = require('body-parser');
const commonRouter = require('./routes/common');
const app = express();
app.use(bodyParser.json({limit: '10mb'}));
app.use(bodyParser.urlencoded({limit: '10mb', extended: true}));
app.use(express.static(__dirname + '/public'));
app.use(bodyParser.urlencoded({ extended: true }));
app.use(bodyParser.json());
app.use('/common', commonRouter);
router.js
var express = require('express');
var router = express.Router();
const controller = require('../controller/commonController')
router.post('/bigFile', controller.bigFile);
router.post('/merge', controller.merge);
router.post('/verify', controller.verify);
router.get('/getFile', controller.getFile);
module.exports = router;
conttroller.js
const multiparty = require('multiparty');
const path = require('path');
const fse = require('fs-extra');
// 上传的切片文件的存储路径
const ALL_CHUNKS_PATH = path.resolve(__dirname, '../chunks');
// 切片合并完成后的文件存储路径
const UPLOAD_FILE_PATH = path.resolve(__dirname, '../public');
// 上传
module.exports.bigFile = async (req, res, next) => {
console.log('bigFile');
const multipartyForm = new multiparty.Form();
multipartyForm.parse(req, async (err, fields, files) => {
if (err) {
console.log('文件切片上传失败:', err);
res.send({
code: 0,
message: '文件切片上传失败'
});
return;
}
// 前端发送的切片文件信息
const [file] = files.file;
// 前端发送的完整文件名 fileName 和分片名 chunkName
const { fileName: [fileName], chunkName: [chunkName] } = fields;
// 当前文件的切片存储路径(将文件名作为切片的目录名)
const chunksPath = path.resolve(ALL_CHUNKS_PATH, fileName);
// 判断当前文件的切片目录是否存在
if (!fse.existsSync(chunksPath)) {
// 创建切片目录
fse.mkdirSync(chunksPath);
}
// 将前端发送的切片文件移动到切片目录中
await fse.move(file.path, `${chunksPath}/${chunkName}`);
console.log('切片上传成功');
res.send({
code: 1,
message: '切片上传成功'
})
})
}
// 合并文件
module.exports.merge = async (req, res, next) => {
console.log('merge');
// 获取前端发送的参数
const { chunkSize, fileName } = req.body;
// 当前文件切片合并成功后的文件存储路径
const uploadedFile = path.resolve(UPLOAD_FILE_PATH, fileName);
// 找到当前文件所有切片的存储目录路径
const chunksPath = path.resolve(ALL_CHUNKS_PATH, fileName);
// 读取所有的切片文件,获取到文件名
const chunksName = await fse.readdir(chunksPath);
// 对切片文件名按照数字大小排序
chunksName.sort((a, b) => (a - 0) - (b - 0));
// 合并切片
const unlinkResult = chunksName.map((name, index) => {
// 获取每一个切片路径
const chunkPath = path.resolve(chunksPath, name);
// 获取要读取切片文件内容
const readChunk = fse.createReadStream(chunkPath);
// 获取要写入切片文件配置
const writeChunk = fse.createWriteStream(uploadedFile, {
start: index * chunkSize,
end: (index + 1) * chunkSize
})
// 将读取到的 readChunk 内容写入到 writeChunk 对应位置
readChunk.pipe(writeChunk);
return new Promise((resolve) => {
// 文件读取结束后删除切片文件(必须要将文件全部删除后,才能才能外层文件夹)
readChunk.on('end', () => {
fse.unlink(chunkPath).then(() => {
resolve();
})
});
})
})
// 等到所有切片文件合并完成,且每一个切片文件都删除成功
Promise.all(unlinkResult).then(() => {
// 删除切片文件所在目录
fse.rmdir(chunksPath).then(() => {
res.send({
code: 1,
message: '文件上传成功'
})
})
});
}
// 上传前验证
module.exports.verify = async (req, res, next) => {
console.log('verify');
// 获取前端发送的文件名
const { fileName } = req.body;
// 获取当前文件路径(如果上传成功过的保存路径)
const filePath = path.resolve(UPLOAD_FILE_PATH, fileName);
// 判断文件是否存在
if (fse.existsSync(filePath)) {
res.send({
code: 1,
message: '文件已存在,不需要重新上传'
});
return;
}
// 断点续传:判断文件是否有上传的一部分切片内容
// 获取该文件的切片文件的存储目录
const chunksPath = path.resolve(ALL_CHUNKS_PATH, fileName);
// 判断该目录是否存在
if (fse.existsSync(chunksPath)) {
// 目录存在,则说明文件之前有上传过一部分,但是没有完整上传成功
// 读取之前已上传的所有切片文件名
const uploaded = await fse.readdir(chunksPath);
res.send({
code: 0,
message: '该文件有部分上传数据',
uploaded
});
return;
}
res.send({
code: 0,
message: '文件未上传过'
})
}
// 获取上传的文件列表
module.exports.getFile = async (req, res, next) => {
res.send({
data: fse.readdirSync(UPLOAD_FILE_PATH,'utf-8'),
msg: '查询成功',
status: 200,
})
}

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)