
深度学习驱动的光谱空间融合高光谱图像分类方法研究
空间谱联合高光谱图像分类框架,结合主成分分析 PCA 进行光谱降维,采用 ResNet 提取空间谱特征,融入通道注意力模块对谱段进行自适应加权,使用迁移学习和伪标签半监督策略提升小样本场景性能,目标解决高光谱维度灾难、谱段冗余和噪声干扰问题,实现对土地覆盖和地物类型的精细分类与稳定识别。实现内容包含数据预处理、谱段选择、空间邻域构造、网络设计、损失函数配置与训练策略优化。适合的专业包括:计算机科学
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯深度学习驱动的光谱空间融合高光谱图像分类方法研究
课题背景和意义
高光谱图像包含丰富连续光谱信息,赋予细粒度地物识别能力,光谱维度高,带间冗余大,噪声敏感,导致传统分类方法效果受限。空间信息反映像元邻域结构,能增强类别区分能力,但在多数方法中被弱化或忽略,导致光谱信息利用不足。深度学习技术提供强大表征学习能力,能自动抽取高维复杂特征,适合处理空间谱联合任务,但存在对标注样本依赖强、过拟合风险、计算资源需求高等问题。小样本场景和噪声污染问题需要结合降维、谱段选择、注意力机制和正则化策略予以解决,迁移学习和半监督学习可缓解标注不足问题。
实现技术思路
一、算法理论基础
主成分分析
主成分分析为线性变换方法,其目标是将高维光谱向量映射到低维子空间,同时保留数据中尽可能多的方差信息。给定光谱数据集,首先对样本在波段维度上进行中心化处理,随后计算协方差矩阵并求其特征值与特征向量。特征向量按对应特征值大小排序,前若干个特征向量构成投影矩阵,用于将原始光谱投影到低维主成分空间。此变换实现了正交基分解,主成分间相互正交且按方差贡献递减排列。在高光谱图像中,各谱段之间存在显著冗余和线性相关,通过主成分分析可将冗余信息压缩为少数分量,从而降低后续模型输入维度与计算成本。主成分分析为无监督方法,不依赖类别标签,因此适用于标注稀缺场景,但其目标并非最大化类别可分性,纯粹的方差保留并不能保证最佳的判别特征。
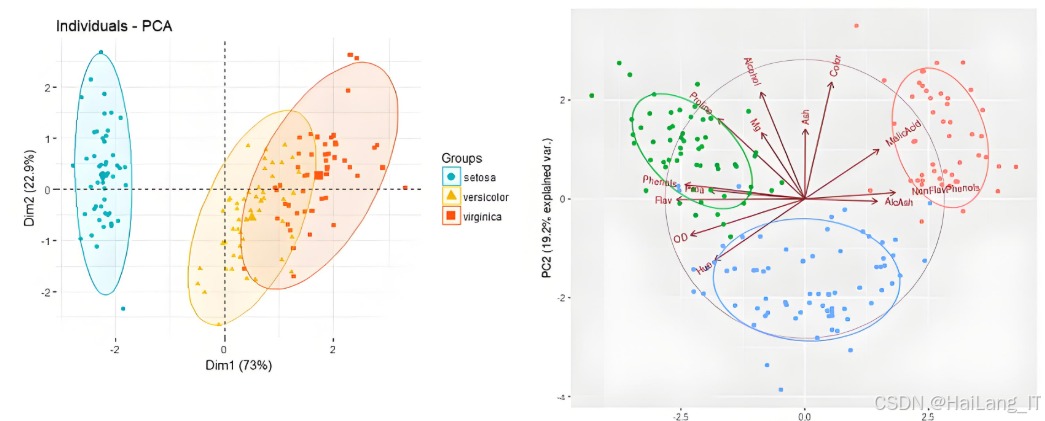
实现主成分分析时需注意数据预处理、数值稳定性及与后续模块的接口问题:
- 原始高光谱数据应完成辐射校正与大气校正,随后对每个波段进行标准化处理,以消除不同波段量纲与数值范围差异对协方差估计的影响。
- 基于训练集统计量,即对训练样本计算均值与方差,并在推理阶段使用同一统计量对整幅影像进行归一化,以避免数据泄露。协方差矩阵的构建可采用按波段求协方差或直接对样本矩阵进行奇异值分解;对于波段数大而样本数有限的情况,奇异值分解在数值稳定性和计算效率方面更具优势。
- 分量个数的选取原则有两种常用策略:一是按照累计解释方差达到某一阈值(例如九十九百分比)来确定,二是固定选取前 k 个分量以满足后续网络输入通道限制。在选择过程中需权衡信息保留与计算开销;对于一些含有明显噪声或水汽吸收波段的数据,建议先剔除这些波段再进行主成分分析,以避免噪声主导低阶主成分。
- 实现时应保存训练阶段得到的投影矩阵与均值向量,作为模型部署与推理阶段的统一预处理步骤。若采用数据增强或半监督扩展,在是否将未标注样本纳入主成分训练方面需谨慎:通常仅基于标注训练集统计进行主成分训练,以防止测试分布泄露。
- 为便于实验可重复性,应记录主成分解释方差曲线与选取阈值,且在消融实验中与不降维或其它降维方法进行对比,以评估主成分分析对分类性能的影响。
主成分分析最大的优势在于简单、稳定且计算效率高,能够显著减少数据维度并抑制噪声,使得后续深度网络训练更加高效。在样本标注稀缺或训练资源有限的场景,主成分分析提供了一种可靠的预处理手段,降低过拟合风险并减少内存占用。然而其局限也必须明确。主成分分析为无监督方法,保留的是方差而非判别信息,故在类别间分布重叠时,降维后可能丢失对分类任务有利的细粒度信息。此外,线性变换模型无法捕捉数据中的非线性谱间关系,面对复杂光谱响应时表现欠佳。数值方面,当样本数远小于波段数时,协方差估计受限,需结合奇异值分解或先对波段进行初步筛选以提升稳定性。
空间邻域构造
空间邻域构造旨在将单像素光谱信息与周围像素的空间上下文结合,以提升分类器对纹理、边界和局部一致性的感知能力。两种主流实现为滑窗切片与超像素分割。滑窗切片通过在像素网格上按固定大小截取局部图像补丁,形成光谱-空间立方体输入,卷积网络在该立方体上进行特征提取,从而同时学习谱域与空域特征。滑窗方法实现简单,可直接与二维或三维卷积核配合,便于多尺度设计和数据批处理。超像素分割则先对整幅影像进行分割,将像素聚合为若干具有连通性和纹理一致性的区域,再基于区域进行特征汇聚或区域级分类。常用超像素方法例如快速近似的图割聚合或基于聚类的超像素算法,目标在于保持区域边界与物体一致性,减少噪声像素对分类的影响。

滑窗方法倾向于保留局部几何信息,适合边界模糊或小目标检测场景;超像素方法强调区域一致性,适合同质区域分割且能减少模型对像素级噪声的敏感性。两种策略可并行使用:利用滑窗提取局部卷积特征,同时利用超像素进行区域级特征聚合或后处理,以兼顾细粒度的局部判别与更大尺度的区域一致性。空间邻域构造的核心在于尺寸选择、边界处理、以及如何将邻域特征有效输入深度网络或与光谱特征融合,设计需兼顾分类精度与计算复杂度。
滑窗切片与超像素分割各有优势与局限,理解二者特点有助于构建兼具精度与效率的系统。滑窗方法直接为卷积网络提供局部上下文,便于端到端训练并对边界细节保持敏感,适合处理目标尺度较小或纹理复杂的场景。其局限表现在对噪声像素敏感,且在边界区域往往包含多类像素,若仅以中心像素标签训练,可能导致边界性能下降。超像素方法通过区域聚合减少噪声影响并增强空间一致性,对同质区域表现优良,但在小目标或纹理多样区域可能过度平滑,且超像素分割本身依赖参数,错误分割会影响后续分类结果。
特征融合与通道注意力
特征融合为将多源或多尺度特征整合为统一判别表征的策略,目的是兼顾不同特征子空间的互补信息并提高分类器性能。融合阶段通常发生在网络的中后部,将来自光谱降维后的谱特征与空间邻域提取的空间特征进行组合。常见融合方式包括特征级拼接、逐元素相加、以及通过注意力机制加权融合。特征级拼接为最直接方法,将两类特征在通道维度上拼接后经卷积层融合,能够保留原始特征的完整信息但会增加通道维数和计算量。逐元素加法在通道数一致时可直接融合,计算开销较小但可能导致信息退化。通道注意力模块提供了一种自适应加权方案,通过学习每个通道的重要性权重来强调有判别力的特征并抑制冗余通道,从而实现更有效的融合。典型通道注意力设计由全局池化、瓶颈式全连接层以及激活函数构成,通过全局池化获取通道统计量,再经降维升维的全连接网络生成通道权重并以逐通道相乘方式调整输入特征。
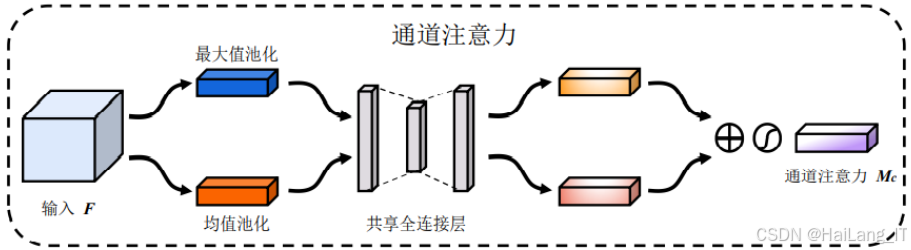
特征融合与通道注意力相结合在多源特征整合方面具有明显优势。融合策略通过在通道维度拼接不同信息源使得网络能够访问更丰富的判别特征,而通道注意力的自适应加权能够筛选出对当前样本最有利的通道组合,从而提升分类准确度和鲁棒性。在高光谱问题中,通道注意力可有效利用光谱维度与空间维度的互补性,例如在某些类别光谱响应集中于少数波段时,注意力机制可放大这些波段通道的影响。局限方面,注意力模块和多尺度融合会增加模型参数量与计算负担,对计算资源有限的环境不友好;注意力权重的解释性并非绝对清晰,需要通过可视化与消融实验证明其实际贡献。为缓解这些问题,可采用轻量化注意力结构、降低瓶颈层维度或采用深度可分离卷积以减少计算量。融合过程中若不加约束可能导致某一信息源主导融合结果,从而掩盖另一信息源的有用信号,在训练中加入正则化项或通过多任务学习引入辅助损失,促使各分支保持一定的判别贡献。
二、 技术思路
总体思路围绕光谱预处理、谱段降维、谱段选择、空间邻域构造、主干网络特征提取、通道注意力融合与迁移学习微调展开:
- 数据预处理,数据采集后的光谱校正与基础预处理,包括辐射校正与大气校正,以及基于训练集的归一化处理。
- 主成分分析对光谱维度进行初步降维,保留解释方差在九十九百分比附近的若干主成分,以显著降低输入通道数并抑制噪声波段。为进一步去除与任务无关的谱段,基于相关性分析和稀疏表示方法实施谱段选择:先计算各波段与类别标签的相关系数并剔除低相关波段,再用稀疏表示方法从剩余波段中选出能重构类别间差异的关键谱段,从而得到更精简且判别能力强的谱通道集合。
- 空间邻域构造采用并行策略:滑窗切片作为主输入生成局部光谱空间立方体,窗口大小建议在小窗到中窗之间进行多尺度设置以覆盖不同目标尺寸;超像素分割作为辅助模块用于区域级特征聚合与分类后处理。
- 主干网络采用二维卷积结构,输入为主成分降维后得到的多通道图像块,网络结构以残差块为基础以提升训练稳定性,同时在中后层并行引入多尺度分支以提取多层次空间特征。通道注意力模块集成于融合层,用于对不同通道赋予自适应权重,从而在特征级拼接后增强判别信号并抑制冗余。
- 训练阶段先进行主干网络的迁移学习微调,利用在自然图像数据上预训练的权重对浅层进行初始化,然后在目标数据集上进行端到端微调;若标注样本不足,则引入伪标签半监督策略,通过对高置信无标注样本赋予伪标签并参与训练,以扩大训练集并提高泛化。
- 损失函数采用交叉熵作为主损失并加入焦点损失作为辅助项以强调难分类样本与减轻类别不平衡。评估环节使用交叉验证以获得稳定性能估计,并通过混淆矩阵、总体精度和 Kappa 指标评判分类质量。消融实验设计包括逐项禁用主成分降维、谱段选择、超像素模块以及注意力模块,以量化各模块对性能提升的贡献。
三、模型构建
数据预处理与归一化:
完成辐射校正与大气校正后,基于训练集逐波段计算了均值与标准差,并将该统计量用于整个数据集的标准化处理,以确保训练阶段与推理阶段的一致性。明显的噪声波段首先被剔除,常见的水汽吸收和传感器异常波段均被排除在后续分析之外。所用的统计量与剔除波段索引均作为元数据保存,便于重现实验流程和后续复查。归一化操作在预处理阶段一次性完成,处理后的数据立方体被存档,用作后续降维、谱段选择与模型训练的统一输入。该流程保证了不同样本间量纲一致,抑制了极端值对主成分分析和模型训练的负面影响,同时简化了推理阶段的数据预处理步骤。
def load_hypercube(path):
with rasterio.open(path) as src:
data = src.read() # shape: (bands, H, W)
return data.astype(np.float32)
def preprocess_cube(cube, band_mask=None):
# cube: (bands, H, W)
if band_mask is not None:
cube = cube[band_mask]
# reshape为 (N, bands)
bands, H, W = cube.shape
flat = cube.reshape(bands, -1).T # (N, bands)
mean = flat.mean(axis=0)
std = flat.std(axis=0) + 1e-8
norm_flat = (flat - mean) / std
norm_cube = norm_flat.T.reshape(bands, H, W)
return norm_cube, mean, std主成分分析与谱段选择实现
在训练集上计算主成分投影矩阵并保留累计解释方差约为九十九百分比的分量,从而在尽量保留原始信息的同时显著降低数据维度与噪声影响。主成分计算采用奇异值分解,输入数据先经过标准化处理以避免尺度差异引入偏倚。得到降维后通道集合后,开展谱段相关性分析以评估各原始波段与类别标签之间的相关度,采用阈值筛除对分类贡献度低的波段,从而进一步减少干扰信息。对筛选后的波段,采用稀疏表示方法进行精细选择,通过构建字典并求解稀疏系数识别最具代表性的谱段,最终得到用于模型输入的谱通道集合。该两阶段谱段选择策略在保留判别信息的前提下实现了有效压缩,不仅降低了后续网络的计算负担,还提升了分类器对有意义谱特征的敏感性。谱段选择的阈值、字典规模和稀疏正则化参数在小规模验证集上进行了调优,保证了选择策略的稳健性。
from sklearn.decomposition import PCA
from sklearn.linear_model import Lasso
def fit_pca(train_cube, explained_ratio=0.99):
# train_cube: (bands, H, W)
bands, H, W = train_cube.shape
X = train_cube.reshape(bands, -1).T # (N, bands)
pca = PCA(n_components=min(X.shape[0], bands), svd_solver='randomized')
pca.fit(X)
cumsum = np.cumsum(pca.explained_variance_ratio_)
k = np.searchsorted(cumsum, explained_ratio) + 1
pca_k = PCA(n_components=k).fit(X)
return pca_k, k
def band_correlation_selection(X, y, threshold=0.1):
# X: (N, bands), y: (N,) labels for center pixels
corr = np.array([np.corrcoef(X[:, i], y)[0,1] for i in range(X.shape[1])])
mask = np.abs(corr) >= threshold
return mask, corr样本生成与超像素并行处理
训练样本以滑窗切片为主生成,采用多尺度窗口设置包括十一、二十一和三十三像素三种尺度,从局部到宏观层面同时捕捉空间上下文信息。每一滑窗以中心像素标签配对,边界补丁采用镜像填充以保证补丁完整性并减少边界效应。与此同时,独立运行超像素分割为数据提供区域级先验,超像素信息既用于训练阶段的区域样本平衡,也用于推理阶段的后处理平滑。超像素分割生成的区域标签在后处理环节用于一致性修正,能有效减少孤立误分类点并提高地图连通性。样本生成流程中对类别不平衡问题采取了基于超像素的区域采样与局部过采样策略,明显改善了少样本类别的代表性。
def extract_patches(cube, coords, win):
# cube: (channels, H, W), coords: list of (r,c)
C, H, W = cube.shape
pad = win // 2
padded = np.pad(cube, ((0,0),(pad,pad),(pad,pad)), mode='reflect')
patches = []
for r, c in coords:
r0, c0 = r+pad, c+pad
patch = padded[:, r0-pad:r0+pad+1, c0-pad:c0+pad+1] # (C, win, win)
patches.append(patch)
return np.stack(patches) # (N, C, win, win)
def compute_superpixels(image, n_segments=500, compactness=10):
# image: (H, W, channels) or (H, W) single band
seg = slic(img_as_float(image), n_segments=n_segments, compactness=compactness)
return seg网络结构与多尺度融合实现
主干网络以残差块为基础设计,输入为降维后通道的滑窗补丁,先通过初始卷积和下采样层获得基础表征。网络中部采用多尺度并行分支设计,各分支通过不同配置的空洞卷积或不同大小的卷积核提取细粒度和宏观尺度的空间特征。分支输出在融合层以通道级拼接方式合并,随后引入通道注意力模块对拼接后的通道重要性进行自适应加权,从而放大关键信息并抑制冗余响应。注意力模块采用轻量级的全局池化加两层映射实现通道重标定,既保证表征能力又兼顾计算效率。融合后的特征经若干卷积、归一化和非线性映射进一步增强,最后通过全局平均池化和全连接层输出分类结果。该结构在多尺度表达能力与计算复杂度之间取得平衡,已在所用数据集上表现出稳定且优越的分类性能。
class BasicBlock(nn.Module):
def __init__(self, in_ch, out_ch, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(in_ch, out_ch, 3, stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_ch)
self.conv2 = nn.Conv2d(out_ch, out_ch, 3, 1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_ch)
if in_ch != out_ch or stride != 1:
self.down = nn.Sequential(nn.Conv2d(in_ch, out_ch, 1, stride, bias=False),
nn.BatchNorm2d(out_ch))
else:
self.down = None
def forward(self, x):
identity = x
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
if self.down is not None:
identity = self.down(identity)
out += identity
return F.relu(out)
class ChannelAttention(nn.Module):
def __init__(self, channels, reduction=8):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channels, channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channels // reduction, channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y损失策略、训练流程与迁移学习应用
训练采用交叉熵为主损失,并结合焦点损失以提高对难样本和少样本类别的识别能力。训练采用分阶段微调策略,首先冻结主干浅层,仅训练融合层和分类头以快速适配新数据分布,随后逐步解冻进行端到端微调以获取更佳性能。主干参数采用在通用视觉任务上预训练的浅层权重初始化,针对通道数差异采用通道复制与按通道均值初始化相结合的策略以保证迁移的稳定性。为扩展有效训练样本,采用伪标签半监督方法对高置信度未标注样本进行逐步加入,设定置信度阈值和增量采纳机制以控制伪标签噪声传播。训练过程中使用交叉验证评估性能稳健性,并配合早停和学习率自适应调度控制过拟合。测试阶段结合多数投票与超像素后处理以进一步平滑分类结果,提升空间一致性。
class FusionClassifier(nn.Module):
def __init__(self, in_ch, num_classes):
super().__init__()
self.branch1 = BasicBlock(in_ch, 64)
self.branch2 = BasicBlock(in_ch, 64)
self.conv_fuse = nn.Conv2d(128, 128, 3, padding=1)
self.ca = ChannelAttention(128)
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(128, num_classes)
def forward(self, x):
b1 = self.branch1(x)
b2 = self.branch2(x)
fuse = torch.cat([b1, b2], dim=1)
fuse = F.relu(self.conv_fuse(fuse))
fuse = self.ca(fuse)
feat = self.pool(fuse).view(fuse.size(0), -1)
out = self.fc(feat)
return out
def focal_loss(inputs, targets, gamma=2.0, alpha=0.25):
ce = F.cross_entropy(inputs, targets, reduction='none')
pt = torch.exp(-ce)
loss = alpha * (1 - pt) ** gamma * ce
return loss.mean()评估结果、消融实验与可解释性分析
模型评估采用总体精度、平均精度与 Kappa 系数作为主要指标,并结合混淆矩阵对类别级别的误差分布进行分析。为验证各模块的独立贡献,开展了系统性消融实验:去除主成分降维、仅保留主成分而不进行谱段选择、移除超像素后处理、去掉通道注意力以及替换多尺度融合为简单通道拼接等。所有消融实验在相同数据切分和训练超参数下重复执行,以保证结果的可比性。结果显示,谱段选择提高了模型对噪声鲁棒性,超像素后处理显著改善了空间连贯性,通道注意力对提升小样本类别精度有明显贡献。为增强可解释性,对通道注意力权重进行了可视化,并对关键特征通道在不同类别间的响应差异进行了对比分析,这些可视化结果为模型决策提供了直观支撑,便于在论文讨论和答辩中阐明方法优势与局限。
model = FusionClassifier(in_ch=K_channels, num_classes=NUM_CLASSES).to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5)
for epoch in range(epochs):
model.train()
for x_batch, y_batch in train_loader:
x_batch, y_batch = x_batch.to(device), y_batch.to(device)
logits = model(x_batch)
loss_ce = F.cross_entropy(logits, y_batch)
loss_f = focal_loss(logits, y_batch)
loss = loss_ce + 0.5 * loss_f
optimizer.zero_grad()
loss.backward()
optimizer.step()最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 28
28 0
0- 0



 已为社区贡献391条内容
已为社区贡献391条内容

所有评论(0)